
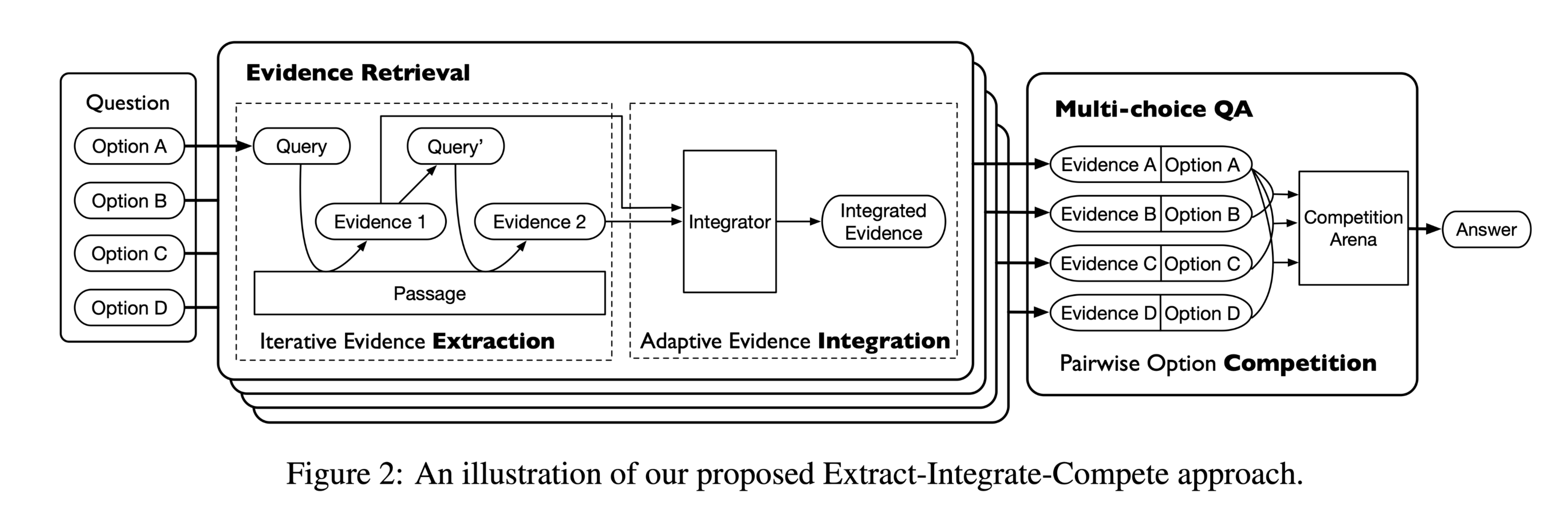
Extract Integrate Compete Towards Verification Style Reading Comprehension
Extract, Integrate, Compete:Towards Verification Style Reading Comprehension
论文:https://arxiv.org/abs/2109.05149
代码:https://github.com/luciusssss/VGaokao
会议:EMNLP 2021
任务 本文提出了一个新的验证式阅读理解数据集,名为VGaokao。与现有的研究不同,新的数据集最初是为母语人士的评估而设计的,因此需要更高级的语言理解技能。为了应对高考中的挑战,我们提出了一种新的Extract-Integrate-Compete方法,该方法通过一种新的查询更新机制迭代选择补充证据,并自适应地提取支持证据,然后通过两两竞争来推动模型学习相似文本片段之间的细微差异。 高考涉及更多的词汇和更复杂的句子结构。此外,高考中近一半的陈述需要多重证据来证实。但是高考中的大多数陈述既不是绝对正确的,也不是绝对错误的,这需要模型仔细比较一种陈述与另一种陈述,根据给定的段落选择最合适的答案。
根本目的:
从文章中提取 ...
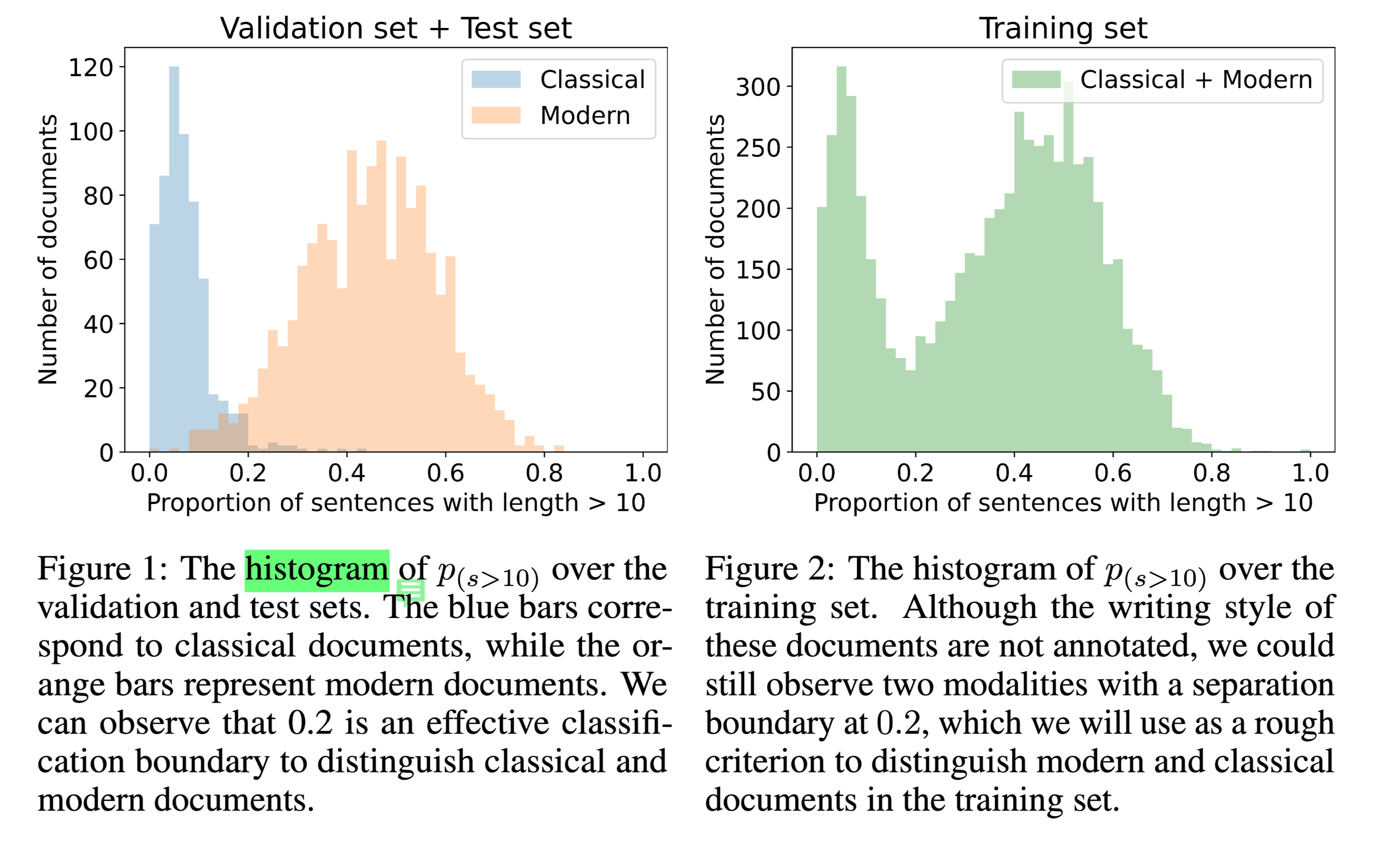
Native Chinese Reader A Dataset Towards Native-Level Chinese Machine Reading Comprehension
Native Chinese Reader: A Dataset Towards Native-Level Chinese Machine Reading Comprehension
论文:https://arxiv.org/abs/2112.06494
数据集官网:https://sites.google.com/ view/native-chinese-reader/
会议:NeurIPS 2021
任务 本文介绍了一个新的机器阅读理解(MRC)数据集,即Native Chinese Reader(NCR),其中包含大量现代汉语和古典汉语的文章。NCR是从中国高中语文课程的试题中收集的,该试题旨在评估中国本土年轻人的语言能力。现有的中文MRC数据集要么是特定领域的,要么只关注现代汉语中几百个字符的短上下文。相比之下,NCR包含8390份文本,平均长度为1024个字符,涵盖了广泛的中国写作风格,包括现代文章、古典文学和古典诗歌。这些文本中总共有20477个问题需要很强的推理能力和常识才能找到正确答案。
现有数据集为构建与母语为汉语的人具有相同语言水平的MRC模 ...
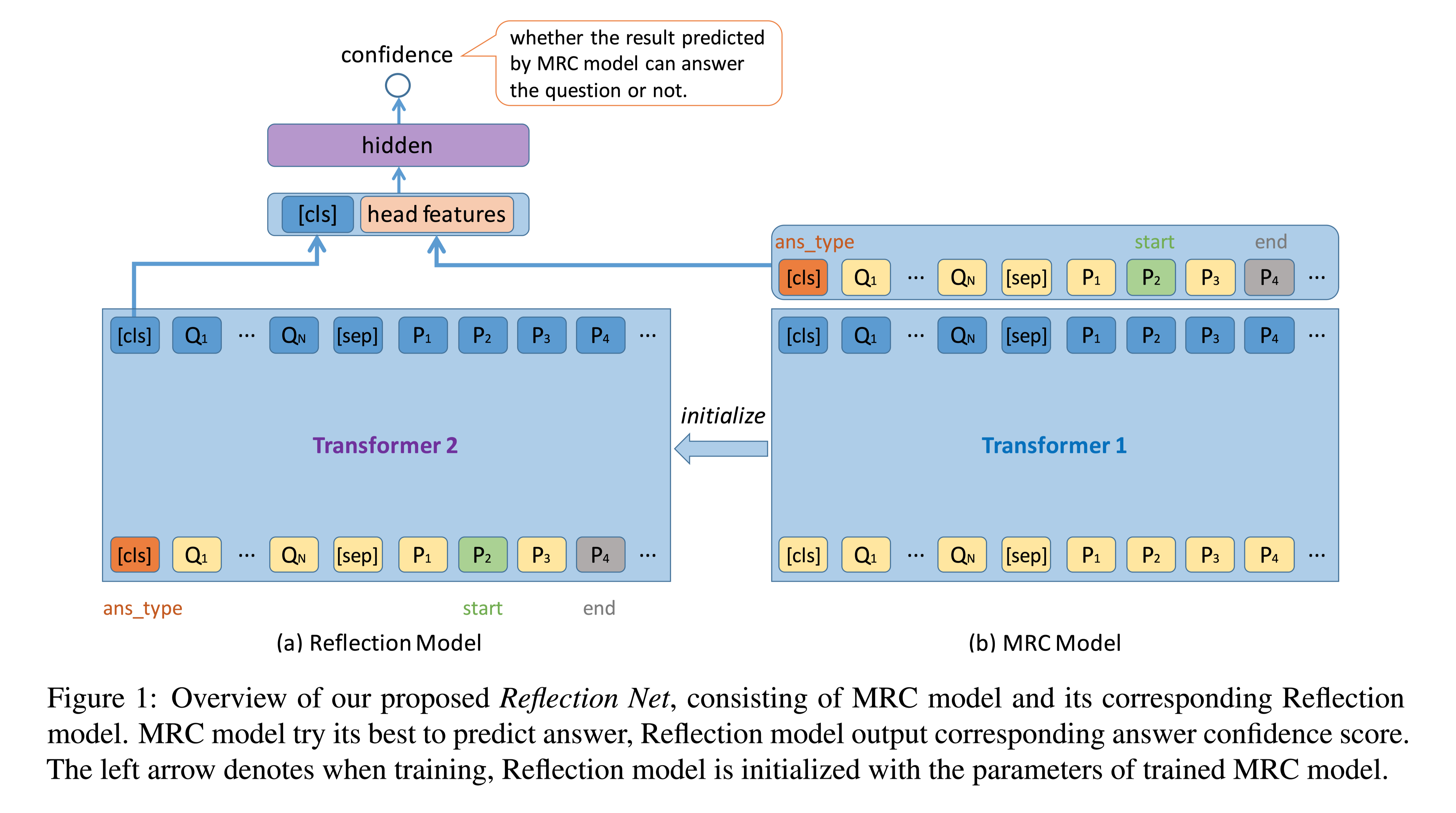
No Answer is Better Than Wrong Answer A Reflection Model for Document Level Machine Reading Comprehension
No Answer is Better Than Wrong Answer: A Reflection Model for Document Level Machine Reading Comprehension
论文:https://arxiv.org/abs/2009.12056
会议:EMNLP 2020
任务 自然问题(Natural Questions,NQ)基准集(benchmark set)给机器阅读理解带来了新的挑战:答案不仅具有不同的粒度(长和短),而且具有更丰富的类型(包括无答案、是/否、单跨度和多跨度)。本文通过系统地处理所有答案类型,提出了一种称为反射网(Reflection Net)的新方法,该方法利用两步训练过程来识别无答案和错误答案情况。
谷歌提出的这个新数据集为MRC带来的挑战有两个方面:
答案是以两级粒度提供的,即长答案(例如,文档中的一段)和短答案(例如,一段中的一个或多个实体)。该任务要求模型在文档级和文章级搜索答案。
在NQ任务中有更丰富的答案类型(包括无答案、是/否、单跨度和多跨度)。
从给的case看,划分答案类型的 ...
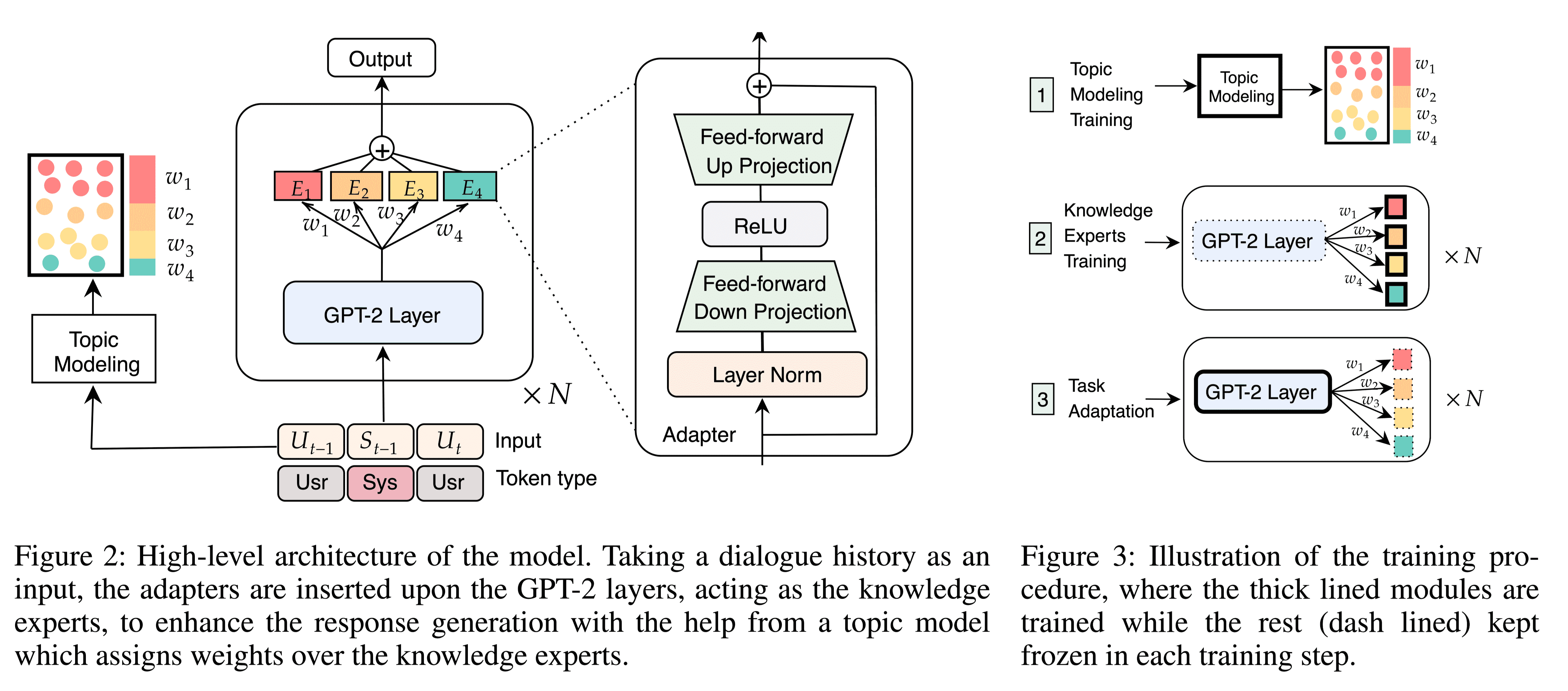
Retrieval-Free Knowledge-Grounded Dialogue Response Generation
Retrieval-Free Knowledge-Grounded Dialogue Response Generation
论文:https://arxiv.org/abs/2105.06232
AAAI 2021
任务 为了使产生的对话响应多样化和丰富,近年来对基于知识的对话研究,现有的方法通过检索大量语料库中的相关句子,并使用显式的额外信息增强对话来解决基于知识对话任务的挑战。尽管取得了成功,但是现有的工作在推理效率上存在缺陷。本文提出了一种端到端的框架KnowExpert,它绕过显式检索过程,通过轻量级适配器将知识注入预训练语言模型,并适应基于知识的对话任务。
本文对话生成模型与以往增强对话生成方法的区别:
以往的解决方案包括:
在该方案中,知识检索和知识选择被认为构成了知识概念化的过程。
知识检索,用于从大型语料库(如维基百科)检索相关知识句子;
知识选择,用于选择最相关的知识句子进行生成;
知识增强生成,用于增强检索到的知识和对话历史,以生成更知识化的响应。
传统基于检索的方法有很明显的缺陷:
首先,语料库中的知识检索需要一个模型来搜索大量 ...
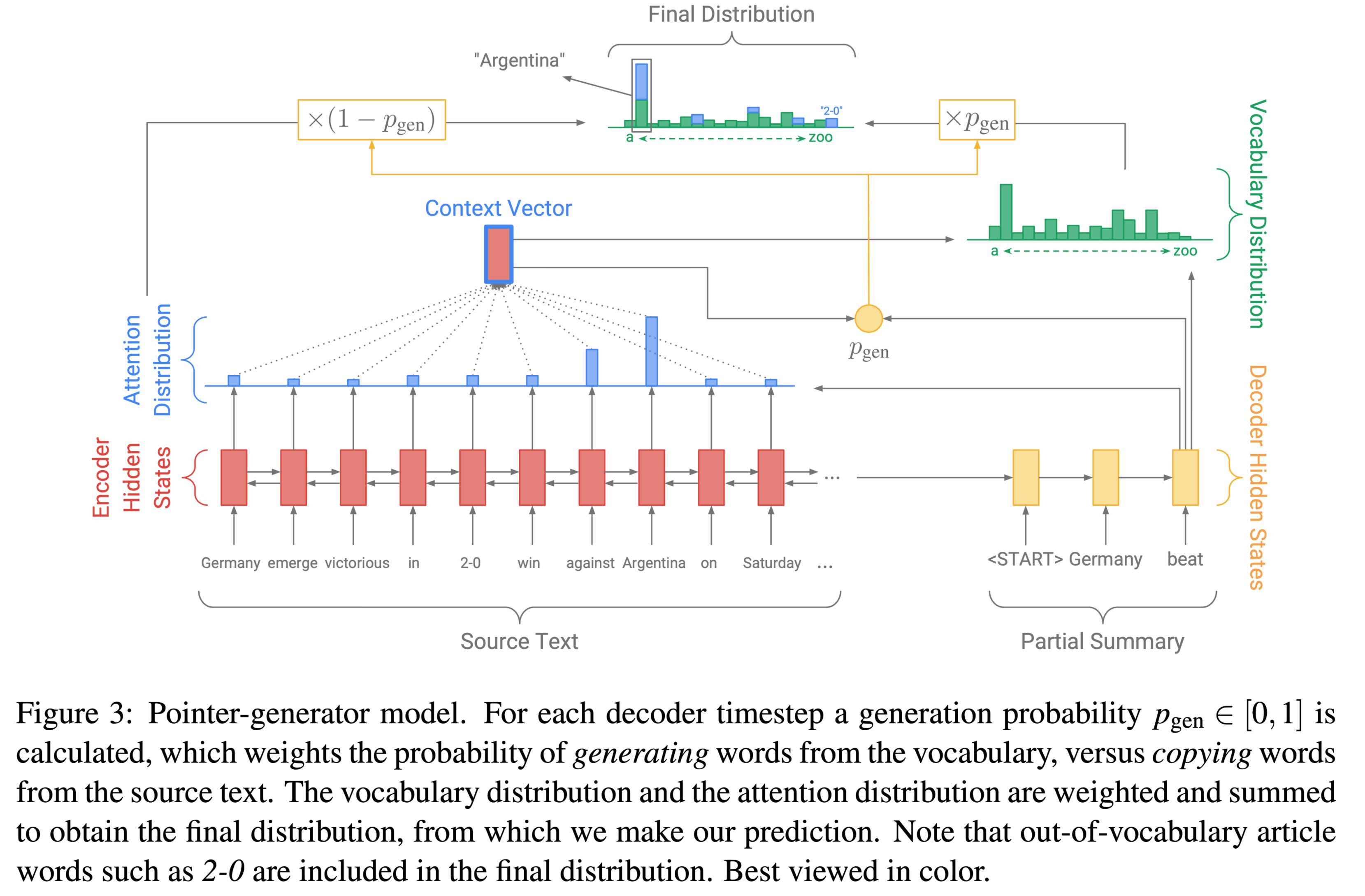
Get To The Point Summarization with Pointer-Generator Networks
Get To The Point: Summarization with Pointer-Generator Networks
论文:https://arxiv.org/abs/1704.04368
代码:https://github.com/abisee/pointer-generator
背景摘要技术整体分为两种:
抽取式extractive
生成式astractive 。
抽取式比较简单,目前的performance也一般比较高,因为它是直接从原文抽取一些段落。但是想要生成高质量的摘要,必须具备一些复杂的摘要能力(如释义(paraphasing), 概括(generalization), 与现实世界知识的融合(incorporation of real-world knowledge),这些只有通过生成式模型才可能得以实现。 鉴于生成式摘要任务的困难性,早期的摘要技术一般都是抽取式的,然而随着seq2sq架构的出现(Sutskever et al., 2014),使用这种架构来读取与自由地生成文本就变得可行了。虽然这种模型很 ...

Pointer Networks - 指针网
Pointer Networks - 指针网
参考资料:
https://blog.csdn.net/qq_38556984/article/details/107574587
https://www.cnblogs.com/zingp/p/11571593.html
指针生成网络属于生成式模型。
为什么会提出指针网
Pointer network 主要用在解决组合优化类问题(TSP, Convex Hull等等),实际上是Sequence to Sequence learning中encoder RNN和decoder RNN的扩展。
传统的seq2seq模型是无法解决输出序列的词汇表会随着输入序列长度的改变而改变的问题的,如寻找凸包等。因为对于这类问题,输出往往是输入集合的子集。
重点是seq2seq模型的输出序列长度不会变!
因此,PN就被提出来了!
传统带有注意力机制的seq2seq模型输出的是针对输出词汇表的一个概率分布,而Pointer Networks输出的则是针对输入文本序列的概率分布。其实我们可以发现,因为输出元素来自输入元素的特点,Po ...
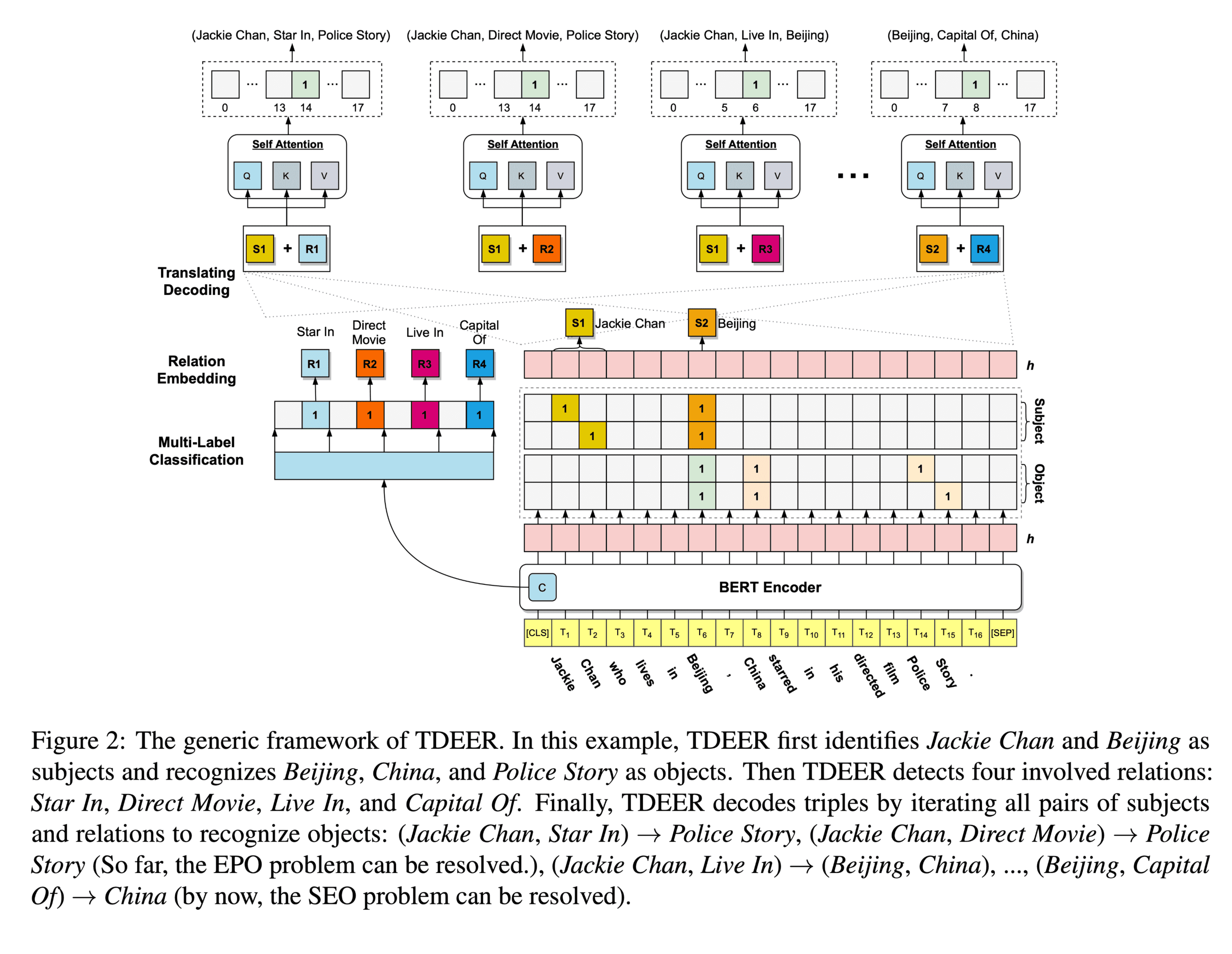
TDEER An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations
指针网
Bowen Yu, Zhenyu Zhang, Xiaobo Shu, Tingwen Liu, Yubin Wang, Bin Wang, and Sujian Li. 2020. Joint extraction of entities and relations based on a novel decomposition strategy. In Proceedings of the 24th European Conference on Artificial Intelligence, pages 2282–2289.
https://zhuanlan.zhihu.com/p/34499027
Zhepei Wei, Jianlin Su, Yue Wang, Yuan Tian, and Yi Chang. 2020. A novel cascade binary tagging framework for relational triple extraction. In Pro- ceedings of the 58th Annual Meeting of th ...
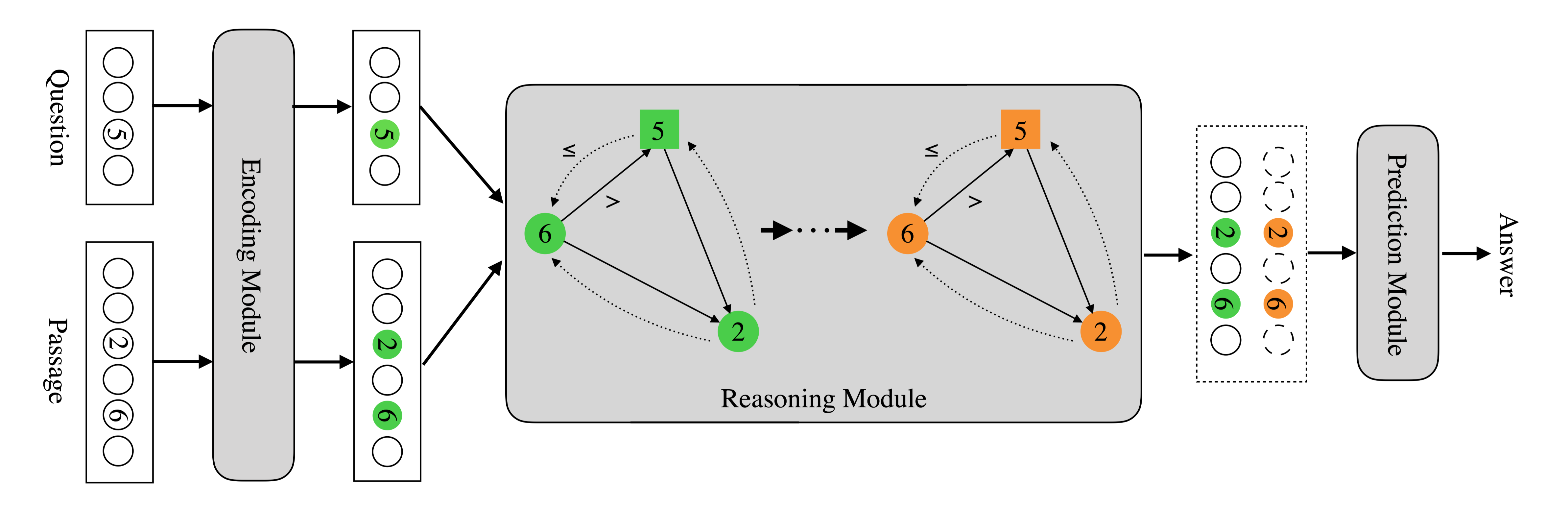
NumNet Machine Reading Comprehension with Numerical Reasoning
NumNet Machine Reading Comprehension with Numerical Reasoning
论文:https://arxiv.org/abs/1910.06701
代码:https://github.com/ranqiu92/NumNet
任务 MRC不可避免的要涉及到数值推理的问题,机器不仅要能够比较数字相对的大小,还要能够知道和哪些数字做比较并进行推理,这就需要把数字相对的大小等等知识注入模型。但在之前大多数机器阅读理解模型中,基本上都将数字与非数字单词同等对待,无法获知数字的大小关系,也不能完成诸如计数、加减法等数学运算。正是基于这一原因,微信AI团队提出了一种数字感知的图神经网络(numerically-aware graph neural network,NumGNN),并基于此提出NumNet。
将数值推理集成到机器阅读理解模型中。两个关键因素:
数值比较:问题的答案可以通过在文档中进行数值比较,如排序和比较,直接获得。例如,在表1中,对于第一个问题,如果MRC系统知道“49 > 47 > 36 > ...

Giving BERT a Calculator Finding Operations and Arguments with Reading Comprehension.pdf
Giving BERT a Calculator Finding Operations and Arguments with Reading Comprehension.pdf
论文:https://arxiv.org/abs/1909.00109
IJCNLP 2019
任务 阅读理解模型已经成功地应用于抽取式文本答案,但目前还不清楚如何最好地将这些模型推广到抽象的数字答案。本文提出一个基于BERT的阅读理解模型,能够进行轻量级的数字推理。用一组预定义的可执行 “程序 “来增强该模型,这些程序包括简单的算术和提取。该模型不需要直接学习操作数字,而是可以选择一个程序并执行它。在最近为挑战阅读理解模型而设计的Discrete Reasoning Over Passages(DROP)数据集上,实验显示通过增加shallow programs,性能提升33%,该模型在训练的例子很少的情况下,在数学单词问题的设置中,学习在适当的时候预测新的运算。
从上面的例子可以看出,正确答案需要通过数值计算得到。
方法(模型) 在这项工作中,扩展了一个具有数字推理能 ...
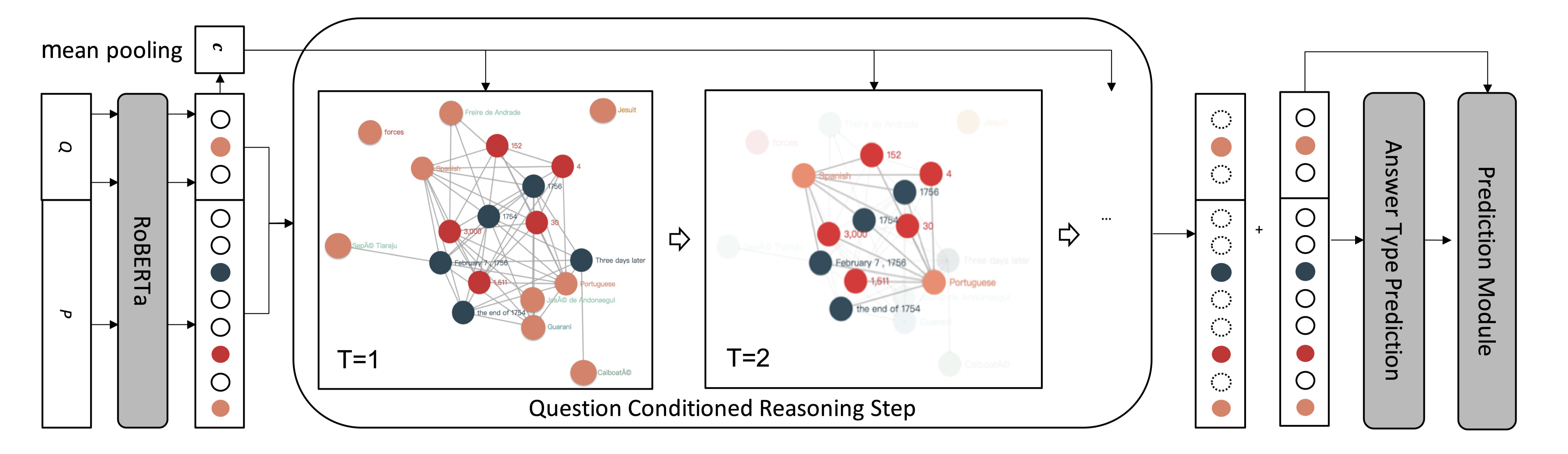
Question Directed Graph Attention Network for Numerical Reasoning over Text
Question Directed Graph Attention Network for Numerical Reasoning over Text
论文:https://arxiv.org/abs/2009.07448
EMNLP2020
任务对文本进行数字推理,如加法、减法、排序和计数,是一项具有挑战性的机器阅读理解任务,因为它需要自然语言理解和算术计算。为了应对这一挑战,本文提出了一种异构图表示,用于这种推理所需的文章和问题的上下文,并设计了一个问题导向图注意网络来驱动该上下文图上的多步数值推理。
方法(模型)本文认为QANET和NumNet对于复杂的数值推理是不够的,因为它们缺少数值推理的两个关键要素:
Number Type and Entity Mention:NumNet中的数字比较图无法识别不同的数字类型,缺少文档中提到的连接数字节点的实体信息。
Direct Interaction with Question:NumNet中的图推理模块忽略了直接的问题表示形式,这在定位问题所指向的重要数字作为数字推理的枢纽时可能会遇到困难。
数字和实体之间的关联是学习数字 ...
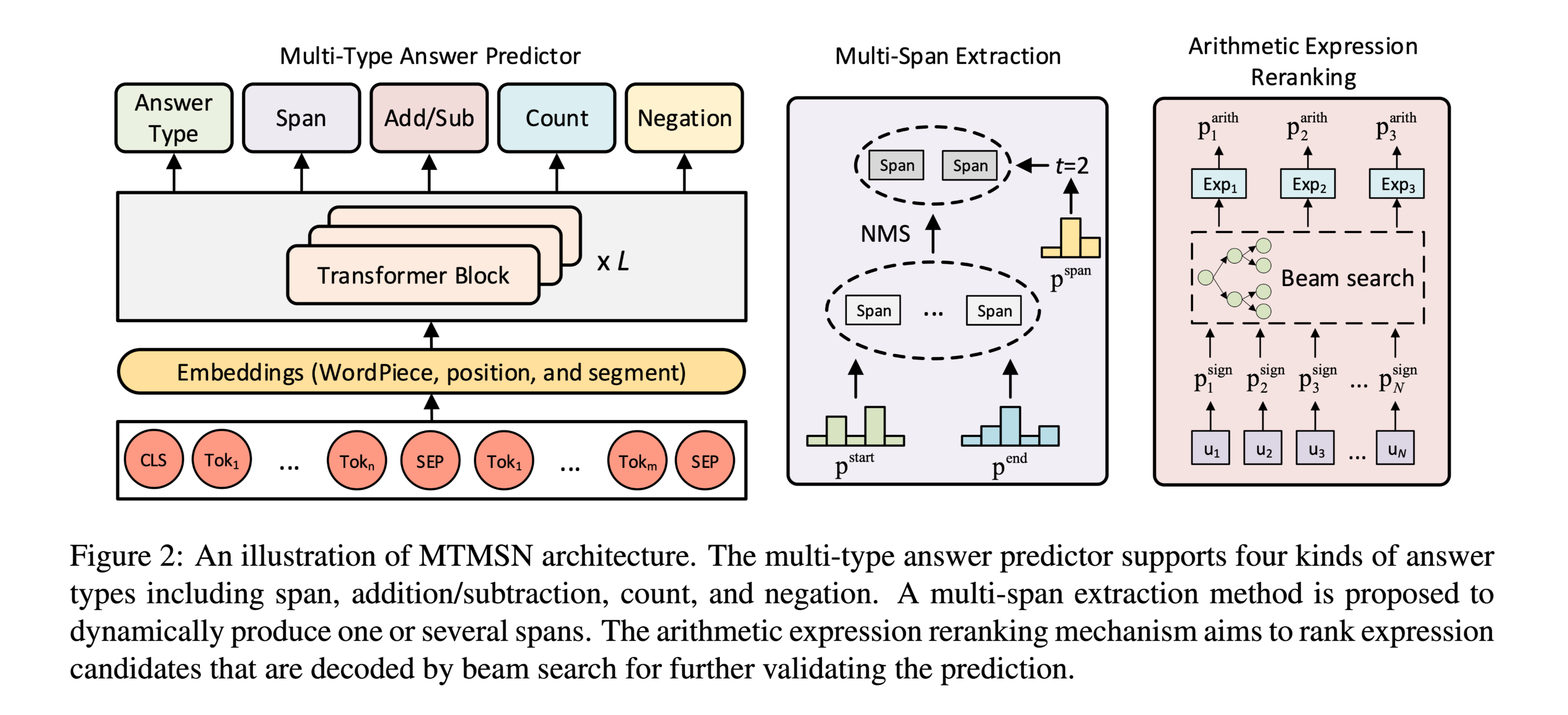
A Multi-Type Multi-Span Network for Reading Comprehension that Requires Discrete Reasoning
A Multi-Type Multi-Span Network forReading Comprehension that Requires Discrete Reasoning
论文:https://arxiv.org/abs/1908.05514
代码:https://github.com/huminghao16/MTMSN
复现:https://github.com/Asimok/DROP
由于学校VPN暂时禁用,无法继续做实验,复现的实验只做了2/3
任务 在QA场景中,当答案涉及各种类型,或离散(多个span为正确答案)时,模型需要更高的推理能力,本文提出了多类型多跨度网络(MTMSN),包含多种答案类型(如跨度、计数、否定和算术表达)的多类型答案预测器,与一个动态产生一个或多个span的多跨度提取模块。
此外,还提出了一种算术表达式重排机制,对表达式候选者进行排序,以进一步确认预测结果。
方法(模型)
使用BERT做解码器,使用Transformer Block将word embedding映射到contextual enmbed ...
不连续MRC实验
不连续MRC实验环境配置123conda create -n drop python=3.7pip3 install torch torchvision torchaudiopip3 install transformers
idea
数据集:DROP https://huggingface.co/datasets/drop
数据预处理:参考NAQAnet,将文档中的word num转为int num,转换目前只支持整数。
NAQAnet 中对数字的处理可以借鉴。
TDEER中 对span的提取思路可以借鉴,特别是 In the second stage 对 start 和 end 的分类预测。
代码结构toollog
加入 emit,print不会受到 tqdm 进度表的影响。
使用偏函数也可以重写logger,但是定制化程度不高,这里使用自定义的get_logger类,今后在其他项目中也可以直接使用。
dataset_readers踩坑记录:
tokenizer
使用 Transformers 的 tokenizer分词并做embedding,当padding=’max_ ...
leetcode每日一题(更新中)
简单剑指 Offer 10- I. 斐波那契数列
不能使用简单递归 会超时
使用动态规划求解
由于 F(n) 只和 F(n−1) 与 F(n−2) 有关,因此可以使用「滚动数组思想」把空间复杂度优化成 O(1)。
1234567891011121314151617181920212223242526class Solution: def fib(self, n: int) -> int: # 计算过程中,答案需要取模 1e9+7 MOD = 10 ** 9 + 7 if n < 2: return n else: # 使用滚动数组减小空间复杂度 # f0=0 f1=1 p = 0 q = 0 r = 1 for i in range(2, n + 1): p = q q = r ...
hexo配置
hexo配置正确的package.json
主要解决 mathjax 公式显示bug
123456789101112131415161718192021222324252627282930{ "name": "hexo-site", "version": "0.0.0", "private": true, "scripts": { "build": "hexo generate", "clean": "hexo clean", "deploy": "hexo deploy", "server": "hexo server" }, "hexo": { "version": "6.0 ...
