不连续MRC实验
不连续MRC实验
环境配置
1 | conda create -n drop python=3.7 |
idea
数据集:DROP https://huggingface.co/datasets/drop
数据预处理:参考NAQAnet,将文档中的word num转为int num,转换目前只支持整数。
NAQAnet 中对数字的处理可以借鉴。
TDEER中 对span的提取思路可以借鉴,特别是 In the second stage 对 start 和 end 的分类预测。
代码结构
tool
log
加入 emit,print不会受到 tqdm 进度表的影响。
使用偏函数也可以重写logger,但是定制化程度不高,这里使用自定义的get_logger类,今后在其他项目中也可以直接使用。
dataset_readers
踩坑记录:
- tokenizer
使用 Transformers 的 tokenizer分词并做embedding,当padding=’max_length’时,padding才会补充到指定长度。
在使用tokenizer的时候也可以指定参数,return_tensors=’pt’,这样就不用手动将list转tensor了。
tokenizer(sent, max_length=max_length, padding=’max_length’, truncation=True)
- tensor
torch.stack() 每次都在新的指定的维度上进行拼接,迭代使用的时候需要注意。
torch.cat() 在已有的维度上连接,需要注意的是,连接后不会扩充维度,需要手动的reshape。
- TensorDataset
TensorDataset 可以将tensor序列化保存,避免多次重复预处理,同样使用torch.save()保存,当然,list,dict,都可以使用torch.save()保存,方便下次在该节点继续操作。
torch.save({“dataset”: TensorDataset, “examples”: _examples}, temp_file_path)
- 位置匹配
最开始使用spacy,简单的使用空格分词,并查找答案 span 的位置,但在后面使用transformers的tokenizer做embedding的时候意识到,拆词方式不同,预处理阶段生成的answer span也会有偏差,所以一致使用tokenizer分词。
除了eval_examples中的span是以char为单位,其余span都是以word为单位。
数据集封装格式:
1 | _dataset = TensorDataset( |
修改后的Dataloader:
1 | input_ids, input_mask, segment_ids, number_indices, start_indices, end_indices, number_of_answers, input_counts, add_sub_expressions, negations |
1 | feature = { |
查阅DROP相关论文 确定对不同anser_type的处理方式
https://paperswithcode.com/sota/question-answering-on-drop-test
https://paperswithcode.com/dataset/drop
排行榜
DROP数据集性能排行榜:https://paperswithcode.com/sota/question-answering-on-drop-test
paperswithcode与DROP相关论文:https://paperswithcode.com/dataset/drop
新工具
Adapter Transformers
介绍:https://zhuanlan.zhihu.com/p/373424011
源码:https://github.com/Adapter-Hub/adapter-transformers
预训练模型:https://huggingface.co/AdapterHub/bert-base-uncased-pf-drop
参考
- TASE-(paper) - A Simple and Effective Model for Answering Multi-span Questions EMNLP 2020
GitHub:https://github.com/llamazing/numnet_plus

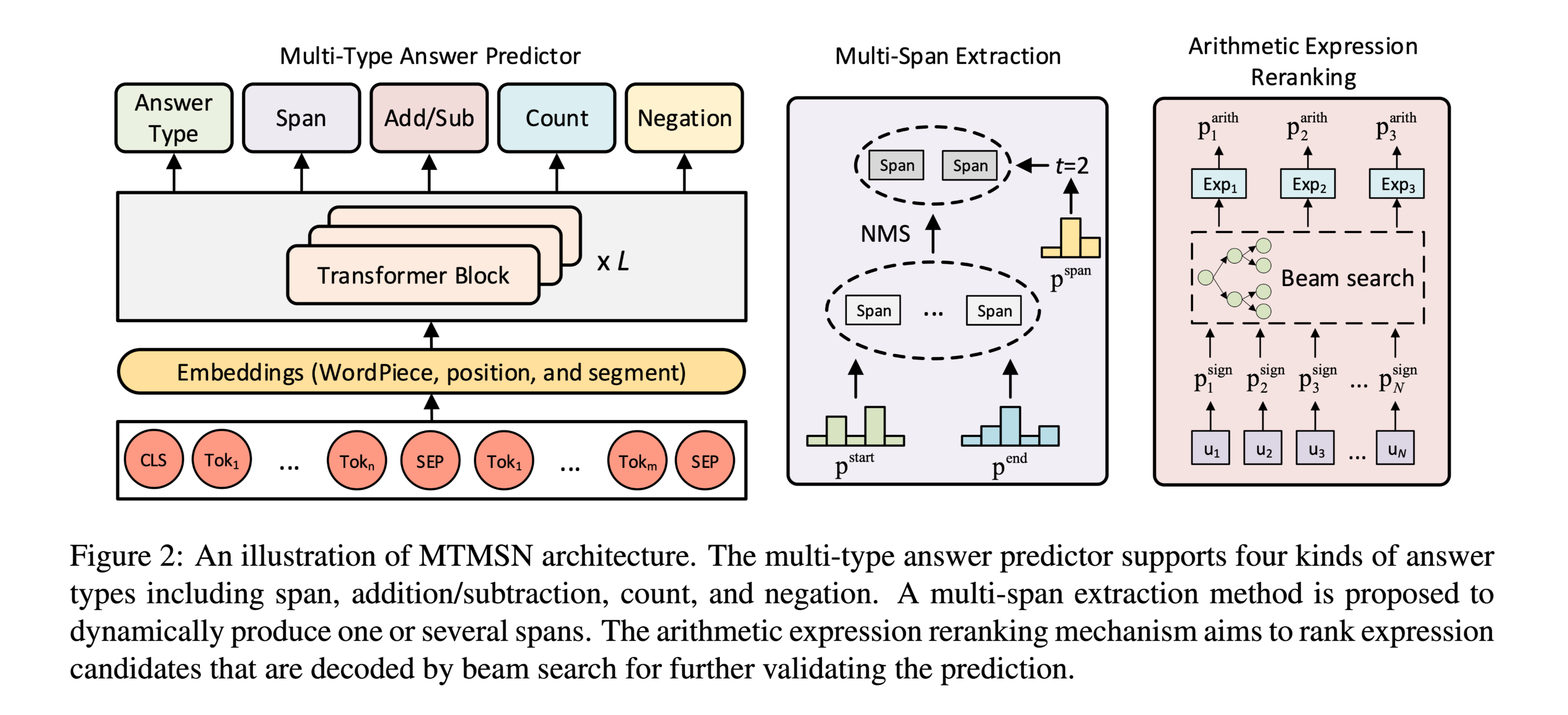
- MTMSN-(paper) - A Multi-Type Multi-Span Network for Reading Comprehension that Requires Discrete Reasoning EMNLP 2019
GitHub:https://github.com/huminghao16/MTMSN

- MetaQA-(paper) - MetaQA: Combining Expert Agents for Multi-Skill Question Answering Submitted on 3 Dec 2021比较新 且 代码结构类似
GitHub: https://github.com/ukplab/metaqa

NAQANet 性能较低 但代码实现可参考
GitHub:https://github.com/francescomontagna/NAQANet-PyTorch
原始数据使用的是 drop_dataset_train_standardized.json 和 drop_dataset_dev_standardized.json
探索
QA SOTA
https://paperswithcode.com/task/question-answering
https://paperswithcode.com/paper/quality-question-answering-with-long-input
Current models perform poorly on this task (55.4%) and significantly lag behind human performance (93.5%).
Question Answering
Question Answering on HotpotQA
Leaderboard : https://paperswithcode.com/sota/question-answering-on-hotpotqa
BigBird-etc NeurIPS 2020
Big Bird: Transformers for Longer Sequences
https://paperswithcode.com/paper/big-bird-transformers-for-longer-sequences
AISO EMNLP 2021
Adaptive Information Seeking for Open-Domain Question Answering
https://paperswithcode.com/paper/adaptive-information-seeking-for-open-domain
IRRR+ EMNLP 2021
Answering Open-Domain Questions of Varying Reasoning Steps from Text
https://paperswithcode.com/paper/retrieve-rerank-read-then-iterate-answering
Construct a new benchmark, called BeerQA : https://beerqa.github.io/
Recursive Dense Retriever ICLR 2021
Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval
https://paperswithcode.com/paper/answering-complex-open-domain-questions-with
Transformer-XH-final ICLR2020
Transformer-XH: Multi-Evidence Reasoning with eXtra Hop Attention
https://paperswithcode.com/paper/transformer-xh-multi-evidence-reasoning-with
Generative Question Answering on CoQA
ERNIE-GEN
ERNIE-GEN: An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation
https://paperswithcode.com/paper/ernie-gen-an-enhanced-multi-flow-pre-training
span-by-span generation flow
Mathematical Question Answering on Geometry3K
Geometry problem
Inter-GPS ACL2021
Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning
https://paperswithcode.com/paper/inter-gps-interpretable-geometry-problem
Open-Domain Question Answering on SearchQA
Locality-Sensitive Hashing ICLR2020
Reformer: The Efficient Transformer
https://paperswithcode.com/paper/reformer-the-efficient-transformer-1
much more memory-efficient and much faster on long sequences
Open-Domain Question Answering on Natural Questions
https://paperswithcode.com/sota/open-domain-question-answering-on-natural
R2-D2
Pruning the Index Contents for Memory Efficient Open-Domain QA
https://paperswithcode.com/paper/pruning-the-index-contents-for-memory
R2-D2 \w HN-DPR EMNLP2021
R2-D2: A Modular Baseline for Open-Domain Question Answering
https://paperswithcode.com/paper/r2-d2-a-modular-baseline-for-open-domain
BPR ACL2021
Efficient Passage Retrieval with Hashing for Open-domain Question Answering
https://paperswithcode.com/paper/efficient-passage-retrieval-with-hashing-for
同等性能下大幅减小内存开销
Open-Domain Question Answering on KILT: ELI5
knowledge-intensive language tasks (KILT)
arxiv.org/abs/2103.06332 NAACL2021
Hurdles to Progress in Long-form Question Answering
https://paperswithcode.com/paper/hurdles-to-progress-in-long-form-question
The task of long-form question answering (LFQA)
T5-base NAACL2021
KILT: a Benchmark for Knowledge Intensive Language Tasks
https://paperswithcode.com/paper/kilt-a-benchmark-for-knowledge-intensive
长文本处理
Big Bird: Transformers for Longer Sequences
https://paperswithcode.com/paper/big-bird-transformers-for-longer-sequences
QuALITY: Question Answering with Long Input Texts, Yes!
Reading Comprehension
LeaderBoards : https://paperswithcode.com/task/reading-comprehension
Reading Comprehension on ReClor
logical reasoning QA datasets, ReClor and LogiQA
LeaderBoard:https://paperswithcode.com/sota/reading-comprehension-on-reclor
RoBERTa-single NeurIPS2021
Fact-driven Logical Reasoning
https://paperswithcode.com/paper/fact-driven-logical-reasoning
covering both global and local knowledge pieces
DAGN NAACL2020
DAGN: Discourse-Aware Graph Network for Logical Reasoning
https://paperswithcode.com/paper/dagn-discourse-aware-graph-network-for
Recent QA with logical reasoning questions requires passage-level relations among the sentences.
for solving logical reasoning QA
discourse-aware graph network (DAGN)
ReClor ICLR2020
ReClor: A Reading Comprehension Dataset Requiring Logical Reasoning
https://paperswithcode.com/paper/reclor-a-reading-comprehension-dataset-1
introduce a new Reading Comprehension dataset requiring logical reasoning (ReClor)
Reading Comprehension on AdversarialQA
AdversarialQA
Beat the AI: Investigating Adversarial Human Annotation for Reading Comprehension
https://paperswithcode.com/paper/beat-the-ai-investigating-adversarial-human