Giving BERT a Calculator Finding Operations and Arguments with Reading Comprehension.pdf
Giving BERT a Calculator Finding Operations and Arguments with Reading Comprehension.pdf
论文:https://arxiv.org/abs/1909.00109
IJCNLP 2019
任务
阅读理解模型已经成功地应用于抽取式文本答案,但目前还不清楚如何最好地将这些模型推广到抽象的数字答案。本文提出一个基于BERT的阅读理解模型,能够进行轻量级的数字推理。用一组预定义的可执行 “程序 “来增强该模型,这些程序包括简单的算术和提取。该模型不需要直接学习操作数字,而是可以选择一个程序并执行它。在最近为挑战阅读理解模型而设计的Discrete Reasoning Over Passages(DROP)数据集上,实验显示通过增加shallow programs,性能提升33%,该模型在训练的例子很少的情况下,在数学单词问题的设置中,学习在适当的时候预测新的运算。

从上面的例子可以看出,正确答案需要通过数值计算得到。
方法(模型)
在这项工作中,扩展了一个具有数字推理能力的抽取式MRC系统,该模型在$Operation(args, …)$形式的简单程序中进行挑选,其中可能的操作包括跨度提取、回答是或不是以及算术运算。对于数学运算,参数是指向文本中的数字的指针。通过这种方式,实际进行计算的负担从神经网络转移到计算器工具上。该程序还提供了浅层次的可解释性,反映了答案所需的一些推理。例如,在上表中,该模型预测了段落中两个数字的减法(Diff),并执行它以产生最终的答案。
模型通过选择得分最高的推导(programe)并执行它来预测答案。
Derivations: We define the space of possible derivations D as follows:

Literals
当作多分类问题处理:
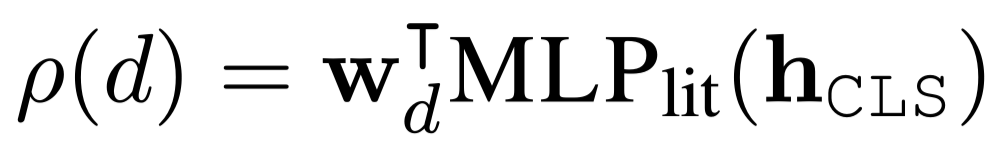
Numeric operations
二元运算:

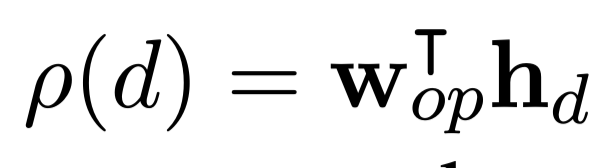
$h_i$:每个numeric argument第一个token的向量表示。
$h_d$:二元运算参数。
op:运算类型。
一元运算:
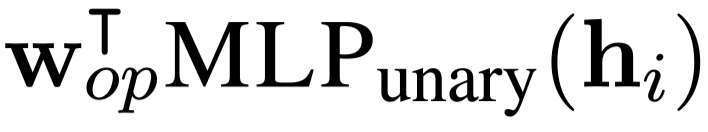
Text spans
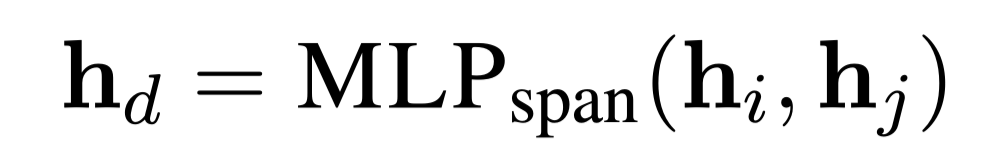
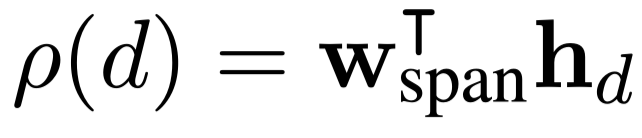
$i,j$:表示span开始和结束位置。
Compositions of compositions
对于组合类型,为其子集打分。
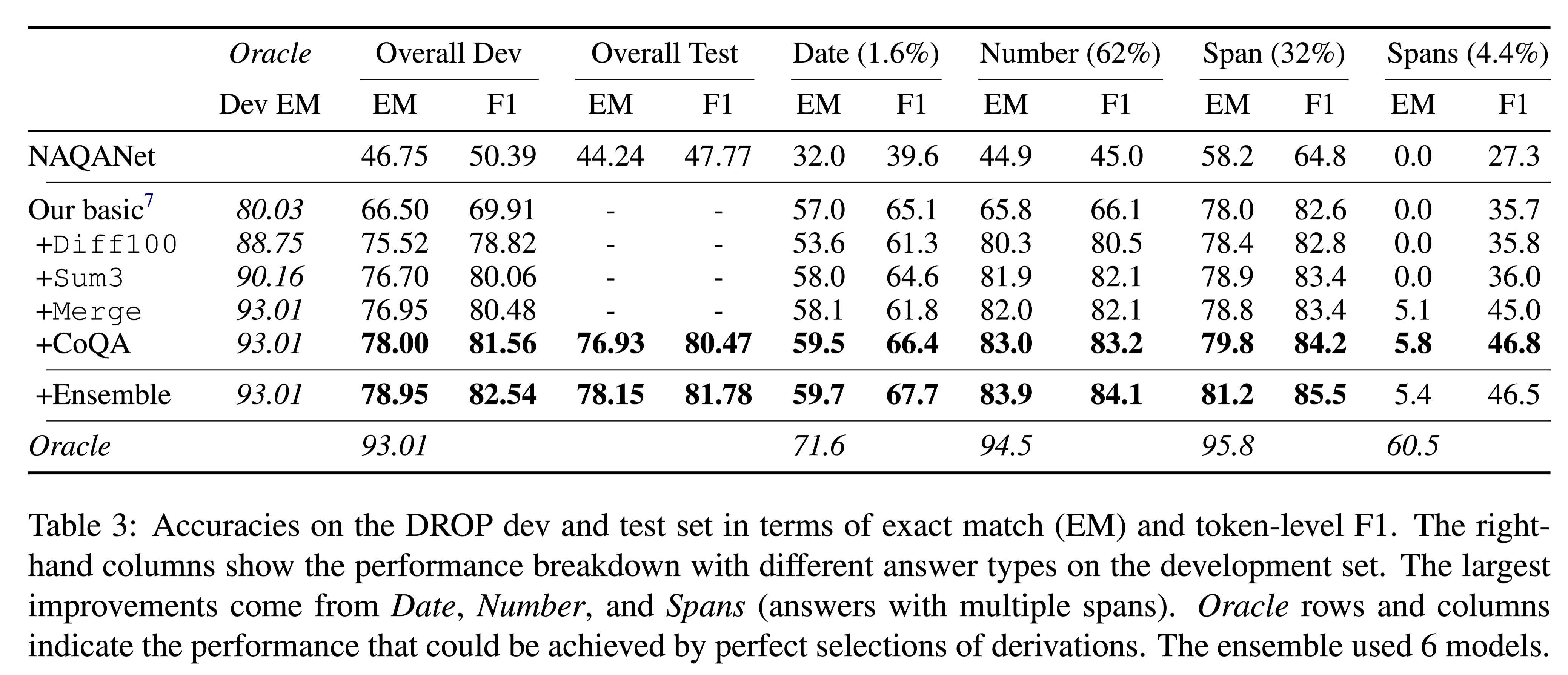
数据集
DROP:(Discrete Reasoning over Paragraphs),是一项需要离散推理的阅读理解任务。
类型分布:
- Date (1.6%)
- Number (62%)
- Span (32%)
- Spans (4.4%)
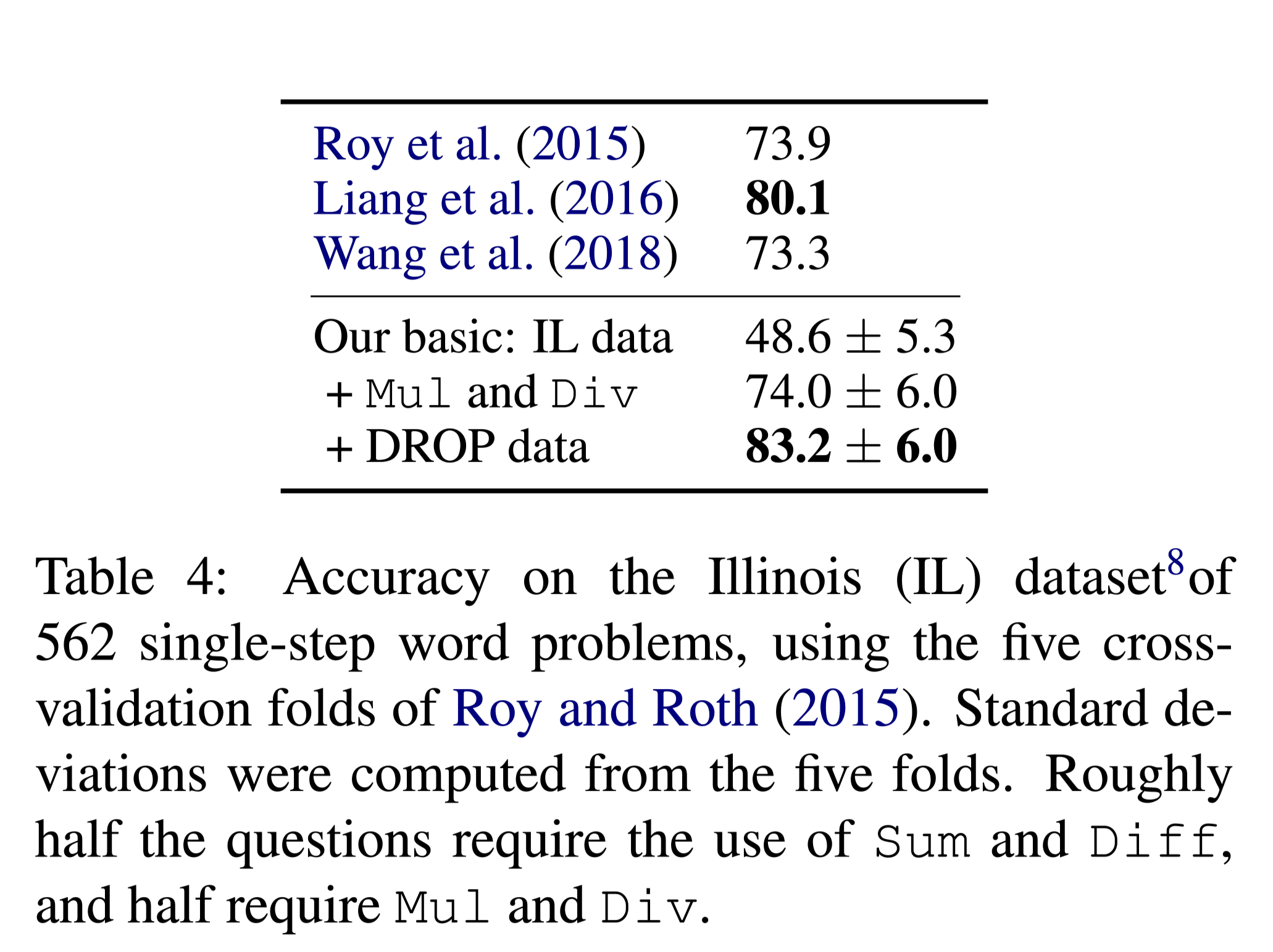
Illinois math word problems dataset
其中包含需要乘法和除法(DROP中没有的运算)以及加法和减法的答案,比例大致相同。
性能水平
在Illinois math word problems数据集上,处理乘除法问题。
结论
基于BERT的抽取式模型:
- 预测带参数的一元和二元数学运算,在DROP数据集上有了明显的改善。
- 该模型可以顺利地处理更传统的阅读理解输入,以及具有新操作的数学问题。与CoQA数据集的协同训练提高了DROP的性能。DROP+CoQA训练的模型从未见过乘法或除法的例子,但在数学单词问题的设置中,可以学习在适当的时候预测这两种操作(Roy和Roth,2015),但训练的例子非常少。
该模型能够在一个统一的模型中处理传统的事实性问题和需要符号推理的问题。可以在DROP数据集上,解答阅读理解和数字推理的混合问题,还可以在CoQA上做标准的阅读理解,并在数学单词问题上做重点数字推理。