Retrieval-Free Knowledge-Grounded Dialogue Response Generation
Retrieval-Free Knowledge-Grounded Dialogue Response Generation
论文:https://arxiv.org/abs/2105.06232
AAAI 2021
任务
为了使产生的对话响应多样化和丰富,近年来对基于知识的对话研究,现有的方法通过检索大量语料库中的相关句子,并使用显式的额外信息增强对话来解决基于知识对话任务的挑战。尽管取得了成功,但是现有的工作在推理效率上存在缺陷。本文提出了一种端到端的框架KnowExpert,它绕过显式检索过程,通过轻量级适配器将知识注入预训练语言模型,并适应基于知识的对话任务。
本文对话生成模型与以往增强对话生成方法的区别:
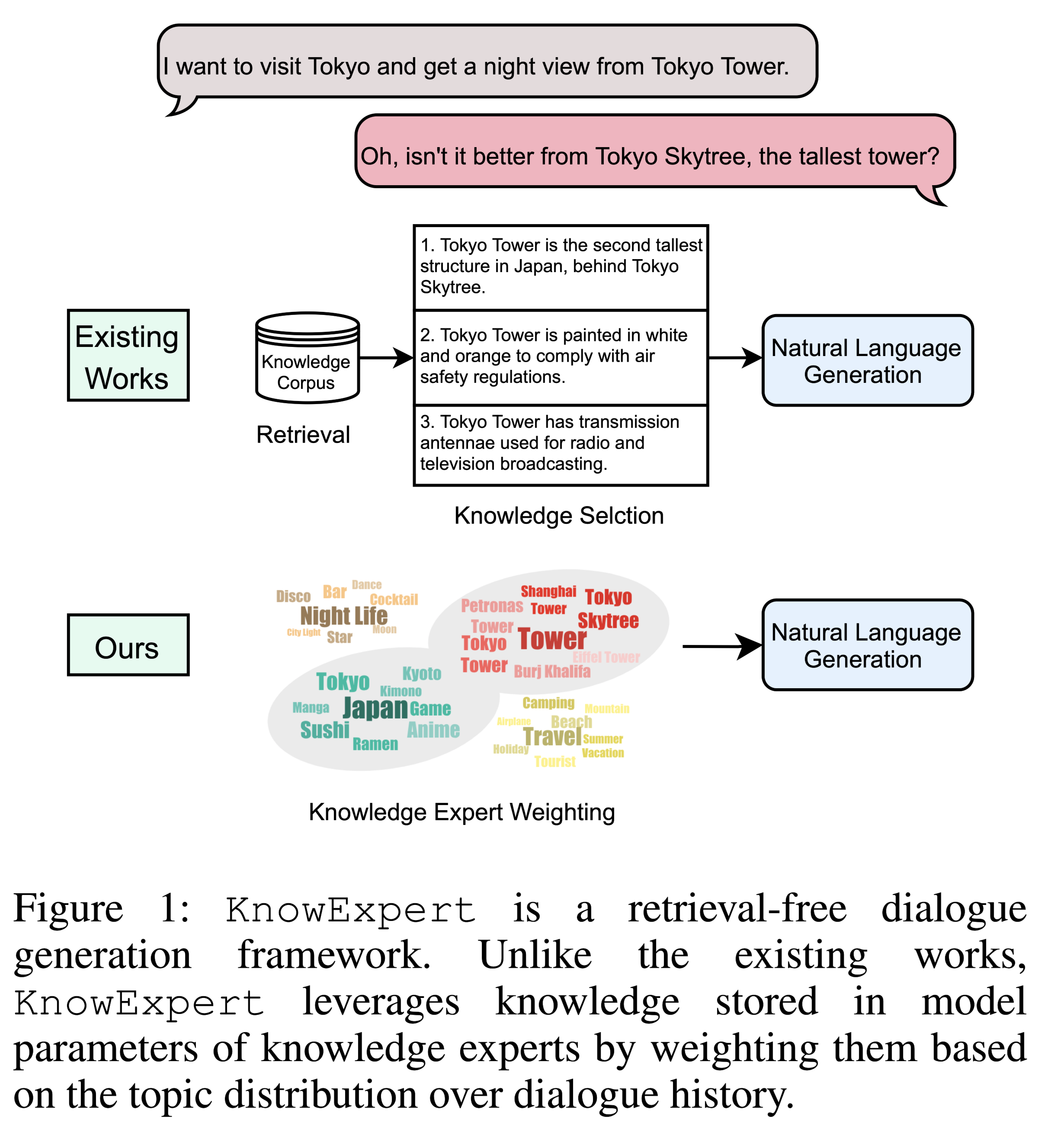
以往的解决方案包括:
在该方案中,知识检索和知识选择被认为构成了知识概念化的过程。
- 知识检索,用于从大型语料库(如维基百科)检索相关知识句子;
- 知识选择,用于选择最相关的知识句子进行生成;
- 知识增强生成,用于增强检索到的知识和对话历史,以生成更知识化的响应。
传统基于检索的方法有很明显的缺陷:
- 首先,语料库中的知识检索需要一个模型来搜索大量数据,这需要大量的内存资源来存储整个知识库,并需要额外的处理时间来检索知识和进行进一步的知识选择;
- 第二,向语言生成模型添加知识作为附加上下文也会导致大量计算开销,这会减慢语言生成过程。
对话生成的过程,其实跟日常对话中的场景类似,不会有人愿意花很长时间等一个人回复吧,所以生成效率很重要!!!
方法(模型)
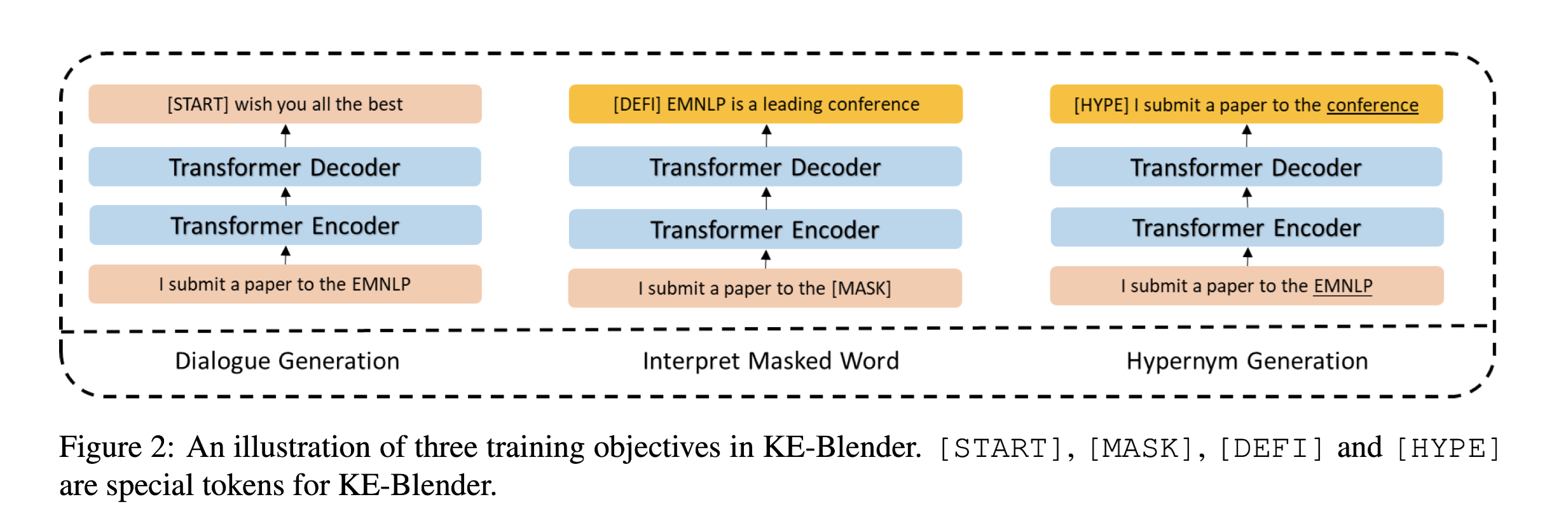
本文通过使用与训练语言模型中的隐性知识来解决基于知识的对话挑战,作为开放领域聊天场景下的知识概念化过程。与图1所示的现有工作方案相比,绕过了检索步骤,提出了一个端到端的框架KnowExpert,将知识库注入预先训练的LMs(language models)的内存中,并利用潜在主题整合所学知识,以生成基于知识的对话。在该模型中,轻量级适配器连接在预训练的GPT-2中,充当知识专家。
模型结构:
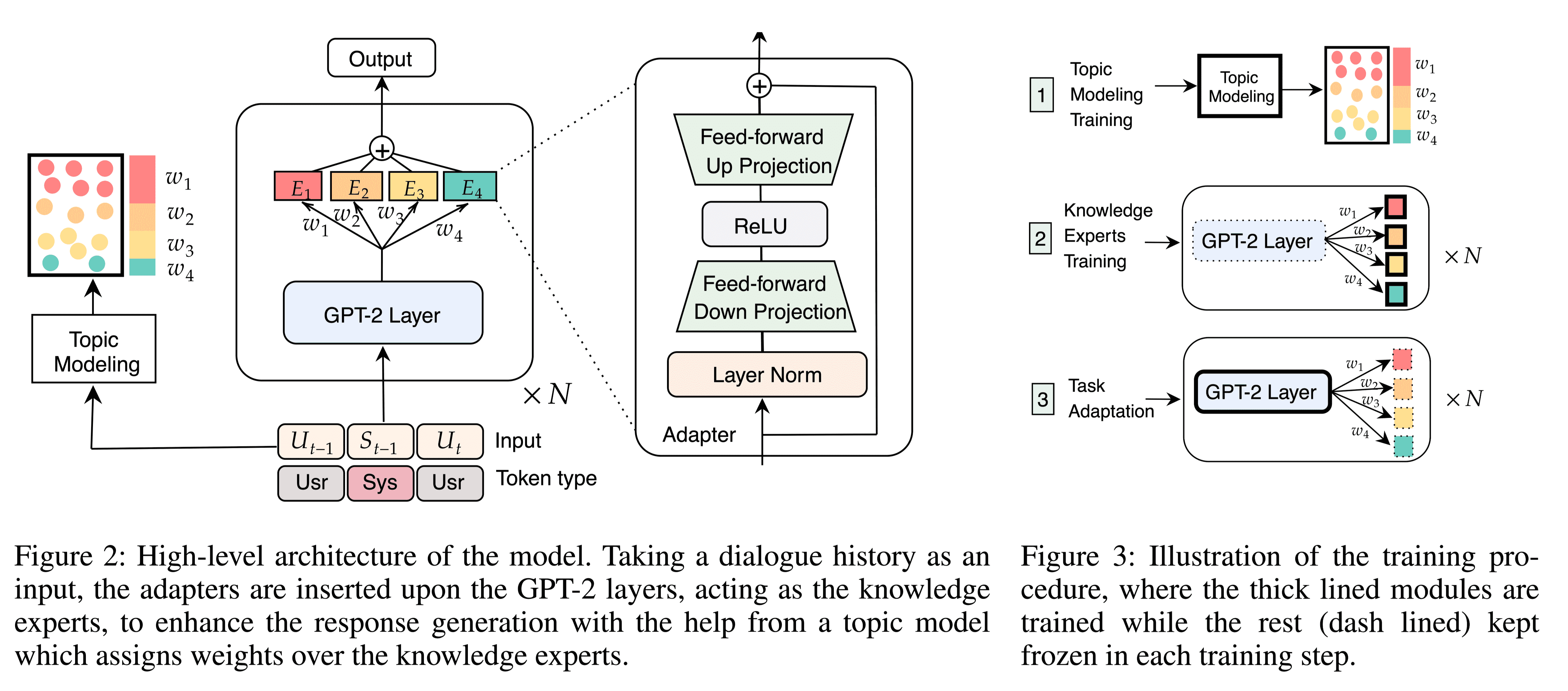
任务定义
对话数据集:${D^n}^N_{n=1}$
第$t$轮对话历史:$Dt = {(U_i, S_i)}^t{i=1}$,其中$U_t$表示用户对话,$S_t$表示系统响应。
语料库:${K_m}^M-{m=1}$,其中$K_m$表示知识片。
输入:$Xt= (D{t−1}, U_t)$
通过向模型参数$Θ$中注入知识来绕过检索过程,以仅基于对话历史生成响应:$\tilde st= fΘ(X_t)$
KnowExpert
在响应生成过程中,通过主题信息的引导,引入主题模型来唤起存储在GPT-2中的知识。
KnowExpert有两部分组成:
- a GPT-2 with lightweight adapters
- a contextual topic model
GPT-2 with Adapters
为了与知识相结合,将轻型适配器插入每个GPT-2层。适配器具有两层线性结构,能够快速适应目标。给定GPT-2 第$i$层的隐藏表示,表示为$H_i∈ R^{j×h}$,其中$h$和j分别是隐藏维度和当前生成步骤,适配器可以表示为:
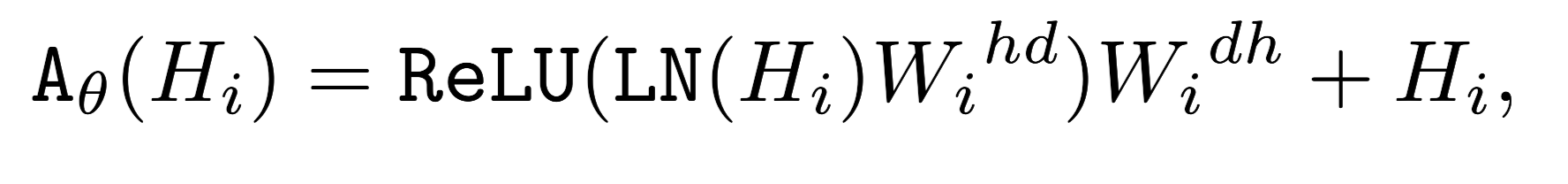
LN(·) is layer normalization
插入L个knowledge adapters,充当不同主题领域的知识专家
Topic Modeling
在KnowExpert中,主题模型用于在响应生成过程中向GPT-2通知更相关的“主题”,从而归纳出更适合上下文的知识。采用了上下文主题模型(CTM),其性能优于传统的主题模型。CTM将预先训练好的Sentence-Transformers嵌入表示与神经主题模型Neural-ProdLDA相结合,后者利用词袋(BoW)实现更连贯的表示。在给定知识库的情况下,以L个主题簇的数目训练主题模型。
一旦训练完成,话题模型将用于获得对话历史中pre-clustered topics的概率分布。这些概率被用作知识专家的相似性权重$w=(w_1,w_2,…,w_L)$,以计算其隐藏状态的加权和,如图2所示。
W在两个不同的设置,在这两种设置下训练的模型分别表示为$KE_w \ KE_o$。
- Weighted-sum setting,将每一个知识专家的输出权重加和,通过隐藏状态传递给下一个GPT-2层。
- One-hot setting,只考虑知识专家输出的最大权重。
Learning Procedure
如图三所示,分为独立的三个步骤训练。
Topic Modeling Training
- 微调Sentence-Transformer
- 使用MSE loss评估两个句子嵌入之间的差异,为模型提供监督信号
Knowledge Experts Training
用知识库训练一组插入到GPT-2(frozen backbone)中的L个主题特定的知识适配器,以生成知识句子。
- 使用negative log-likelihood训练
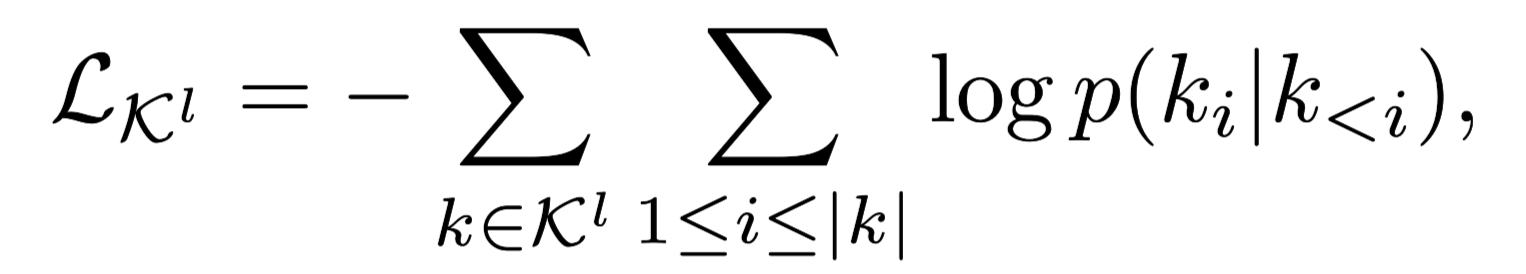
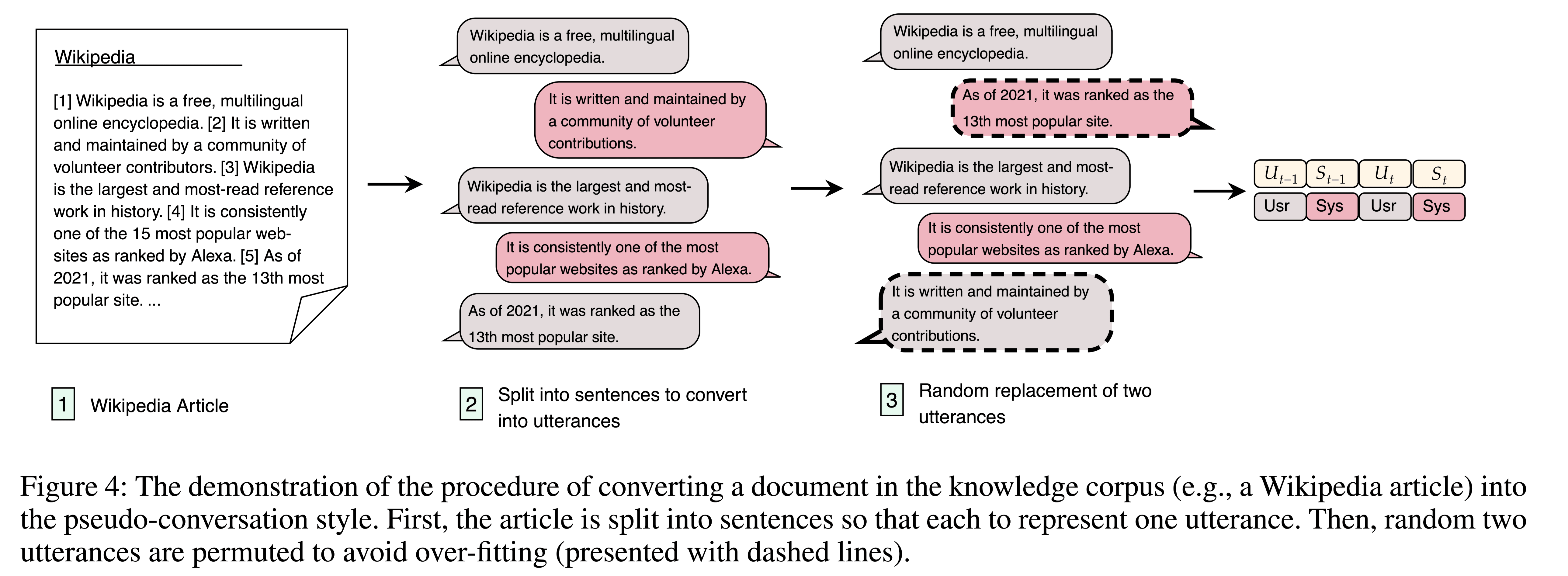
- 将知识嵌入到经过训练的知识专家中,并从基于知识的对话任务中获益。在这种情况下,需要进行以对话为导向(dialogue-oriented)的训练。基于此,本文将知识句子的格式从纯文本转换为伪会话风格,以缩小知识专家培训和任务适应之间的差距。转换过程如图4所示。
Task Adaptation
- 插入知识专家
- 微调GPT-2
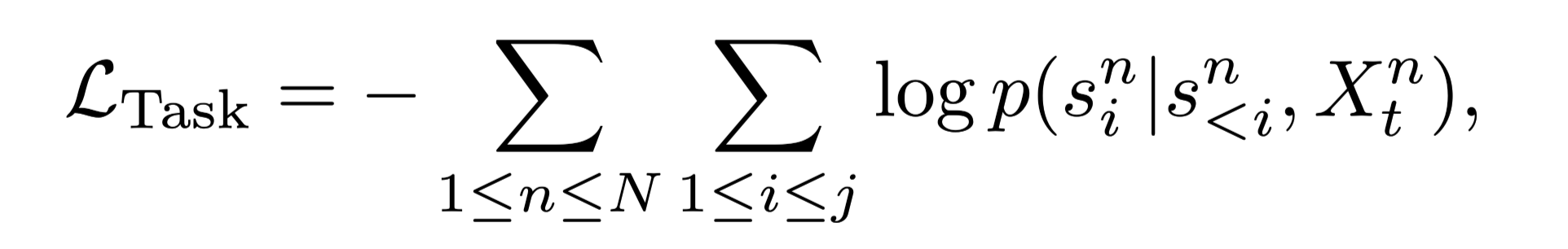
数据集
knowledgegrounded dialogue datasets:
- Wizard of Wikipedia (WoW)
- CMU Document Grounded Conversations (CMU DoG)
数据集处理:
我们随机选择20%的话语,并在每个对话中用最近的选择话语替换它们,以避免适配器过度匹配句子的顺序。
每个句子都要作为 system utterance 和 user utterance参与训练,确保所有句子都被训练为系统语料。
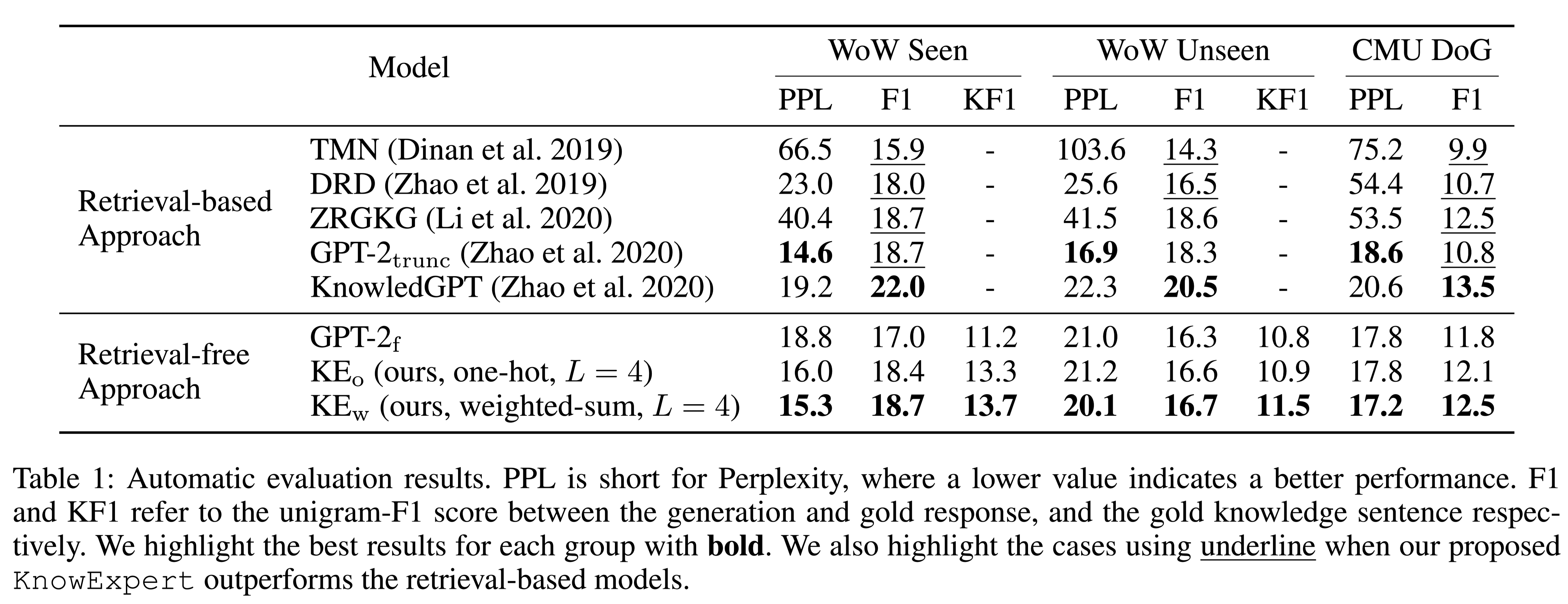
性能水平
生成响应的示例:

结论
这是在开放域聊天场景下首次尝试在不使用检索的情况下解决基于知识的对话生成任务。
KnowExperty的推理过程效率更高的原因:不需要额外的知识句子作为输入的一个组成部分,从大规模语料库中检索额外的知识是一个耗时的过程。
本文的贡献有三个方面:
- 率先探索了在开放领域聊天场景下,将先验知识注入到基于知识的对话生成任务的生成模型中;
- 本文模型进行知识概念化,没有显式的知识检索过程,无论知识库的大小,该过程都有恒定的推理时间;
- 模型的性能与一些强基线相当,并显示了纯生成方法在任务中的潜力。