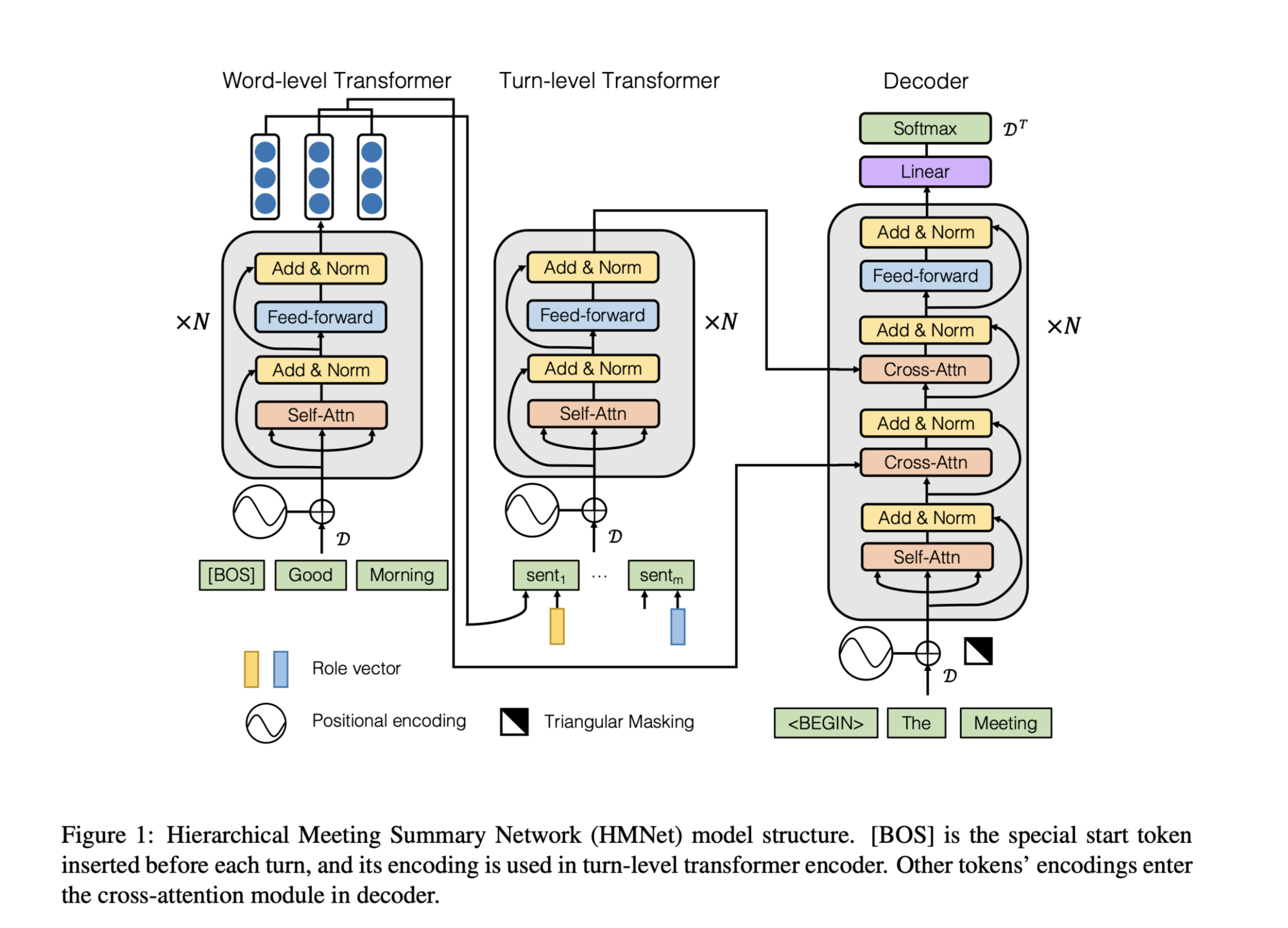
TDEER An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations
指针网
- Bowen Yu, Zhenyu Zhang, Xiaobo Shu, Tingwen Liu, Yubin Wang, Bin Wang, and Sujian Li. 2020. Joint extraction of entities and relations based on a novel decomposition strategy. In Proceedings of the 24th European Conference on Artificial Intelligence, pages 2282–2289.
- https://zhuanlan.zhihu.com/p/34499027
- Zhepei Wei, Jianlin Su, Yue Wang, Yuan Tian, and Yi Chang. 2020. A novel cascade binary tagging framework for relational triple extraction. In Pro- ceedings of the 58th Annual Meeting of the Asso- ciation for Computational Linguistics, pages 1476– 1488.
TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations
任务
在实体关系抽取中,通用的方法是通过预测实体对来获得相应的关系,进而得到关系三元组。然后如何有效地处理这一任务仍然具有挑战性,尤其是对于重叠三元组问题。因此,为了解决这个问题,作者提出了基于翻译解码机制的实体关系联合抽取模型(TDEER: Translating Decoding Schema for Joint Extraction of Entities and Relations)。
该模型代表翻译解码模式,用于实体和关系的联合抽取。与常用的翻译解码模式不同,本文提出的翻译解码模式将这种关系视为从主体实体到客体实体的翻译操作,即TDEER将三元组解码为subject + relation → objects。TDEER可以自然地处理重叠三元组问题,因为翻译解码模式可以识别所有可能的三元组,包括重叠和非重叠三元组。为了增强模型的鲁棒性,引入了负样本,以减少不同阶段的误差积累。
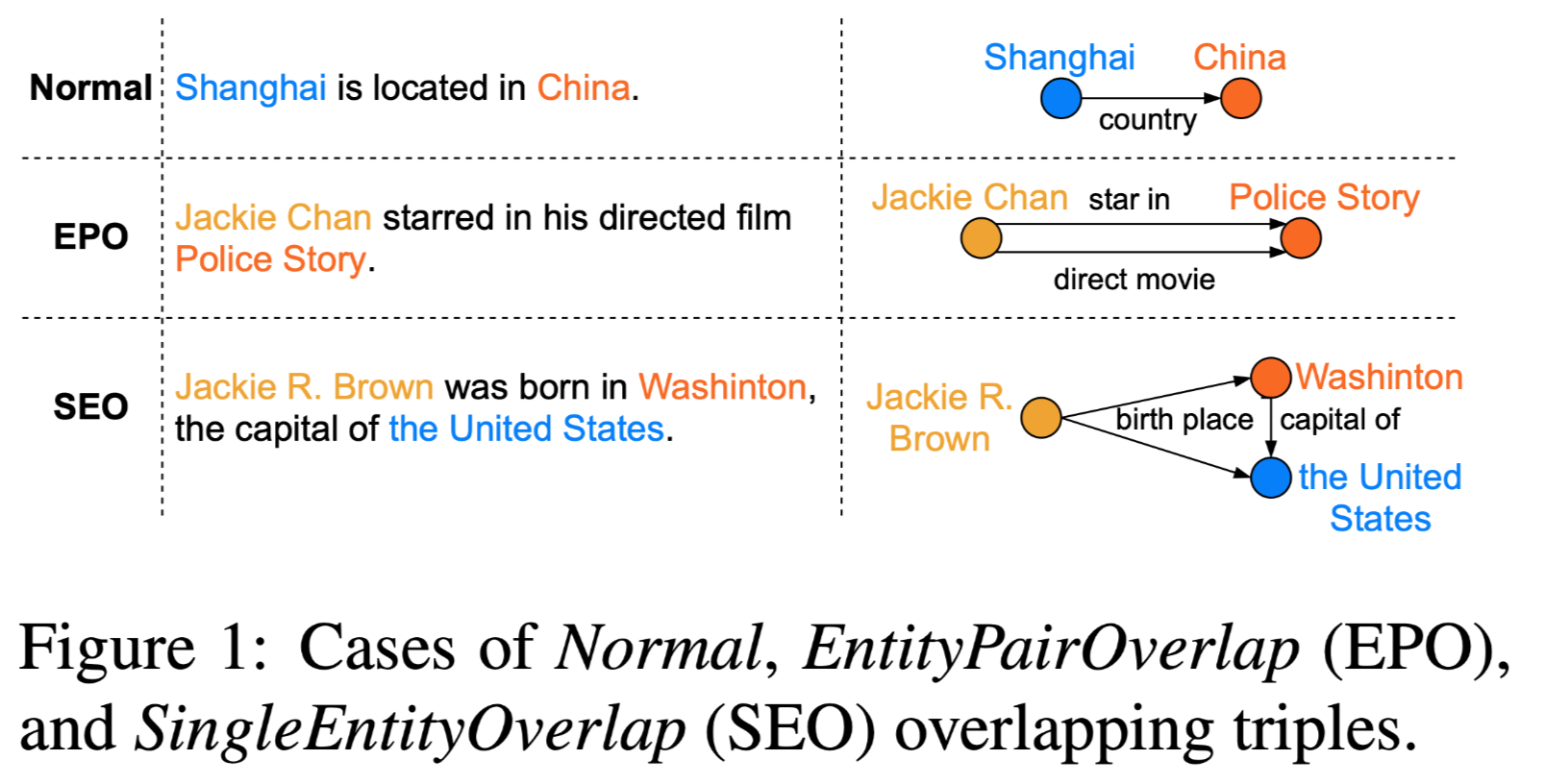
实体对的几种情况:
方法(模型)
本文提出了一个三阶段模型,TDEER。
- 在第一阶段,TDEER使用基于跨度的实体标记模型来提取所有主体实体和客体实体。
- 在第二阶段,TDEER采用多标签分类策略来检测所有相关关系。在第三阶段,TDEER通过提出的翻译-解码模式,迭代主体实体和关系对,以识别各自的客体实体。
TDEER主体结构:
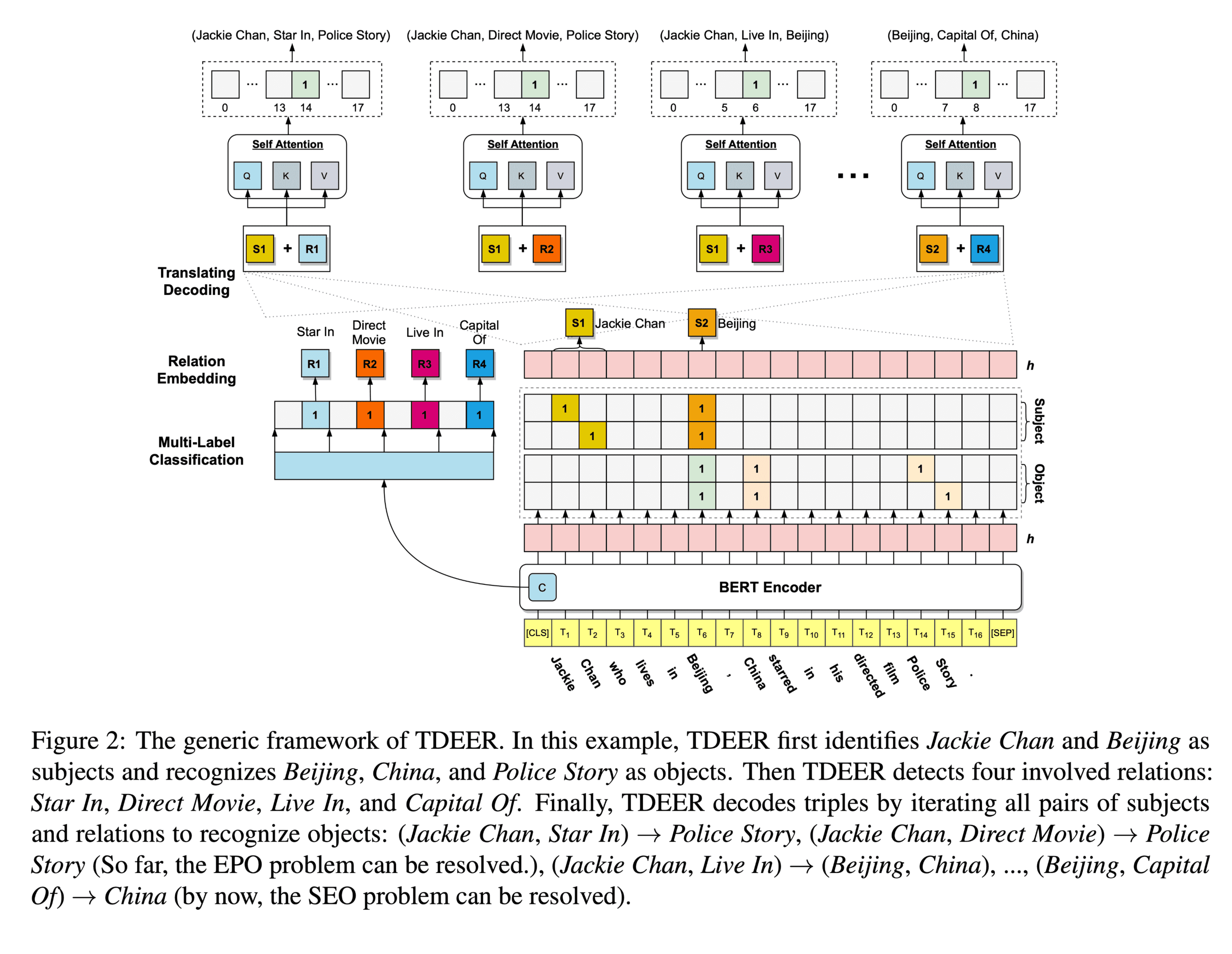
Input Layer
在BERT模型的基础上,模型首先编码句子文本,在BERT模型的输出得到,CLS以及句子中每个词的对应的上下文向量表示。
Entity Tagging Model
采用基于跨度的标记模型(span-based tagging model)去获得句子中的实体以及它们的位置。使用了两个二元分类器分别预测主体实体的起始位置和结束位置以及客体实体的起始位置和结束位置。使用的激活函数为sigmoid。
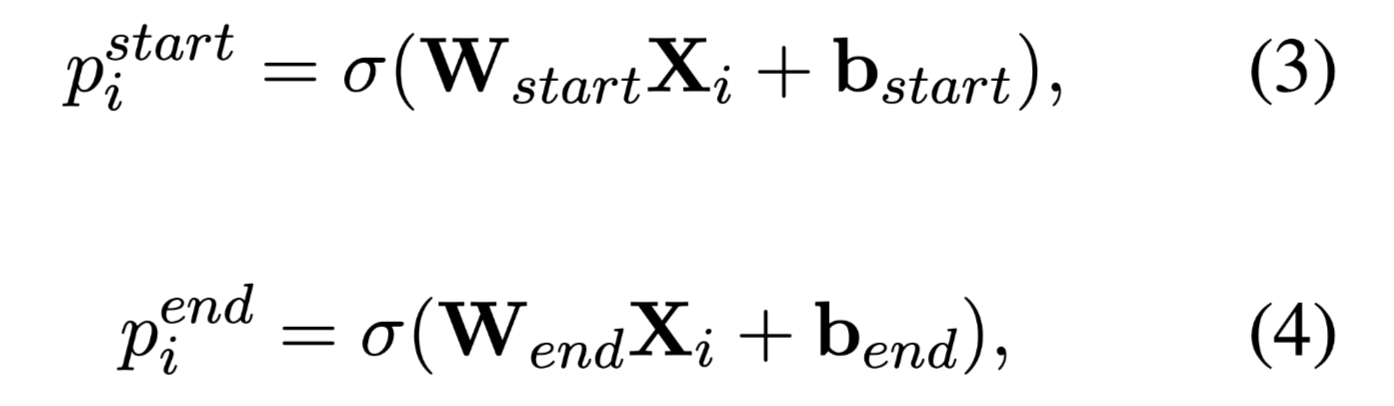
通过最小化如下损失函数训练:
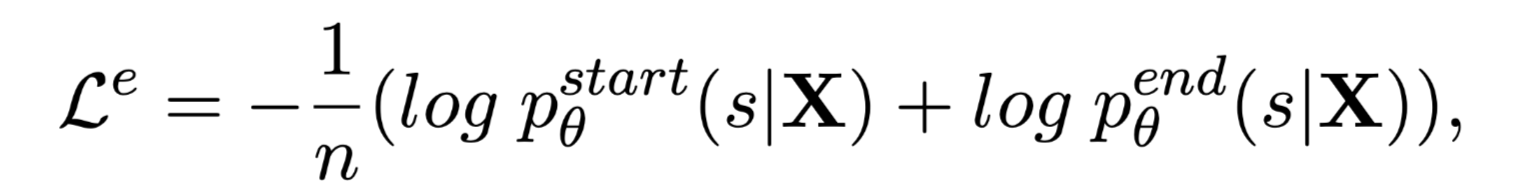
其中:
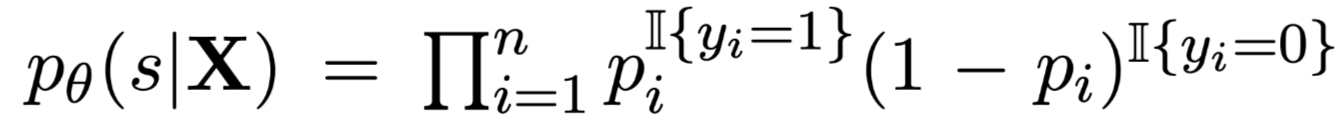
Relation Detector
在关系探测阶段,为了识别句子中的相关关系,在CLS向量表示的基础上采用了一种多标签分类策略来分类得到句子中的关系。使用的激活函数为sigmoid。
多标签分类:(关系)
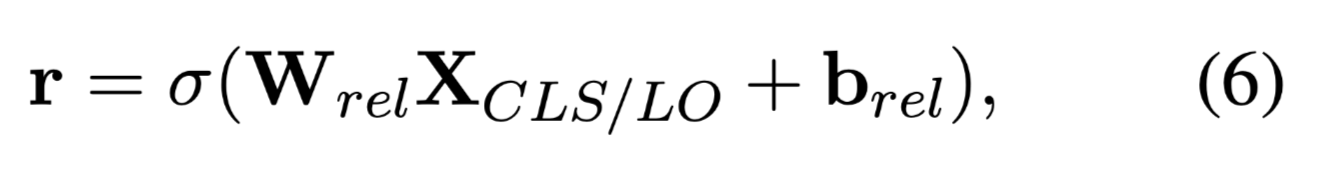
$σ(·)$ denotes sigmoid function
二元交叉熵损失函数:
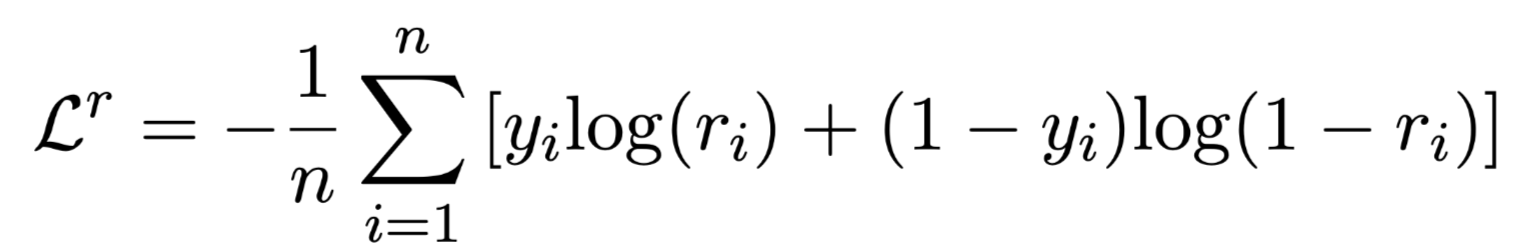
$y_i\in{0, 1}$ indicates the ground truth label of relations.
Translating Decoding Schema
在基于翻译机制的解码模式阶段,本文提出的方法对探测到的主体实体集合和关系集合进行迭代配对,然后去预测客体实体的开始位置。对于每个主体实体和关系对,首先将主体实体和关系的表示结合起来。接下来,使用注意力机制来获得一个选择性的表示,这会给客体实体的可能位置分配更高的权重。最后,将选择性表示传递给一个全连接层来获得输出,即得到的客体实体的位置。
使用一个全连接层编码关系:
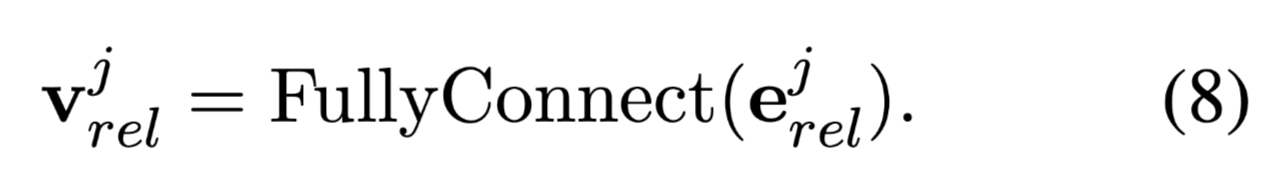
这里主体实体和关系的匹配规则:第i个主体实体依次和所有关系组合。
TDEER通过加法操作将主体实体的表示和关系表示连接起来:
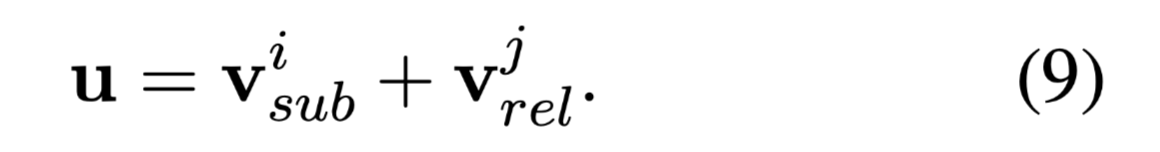
注意力机制:
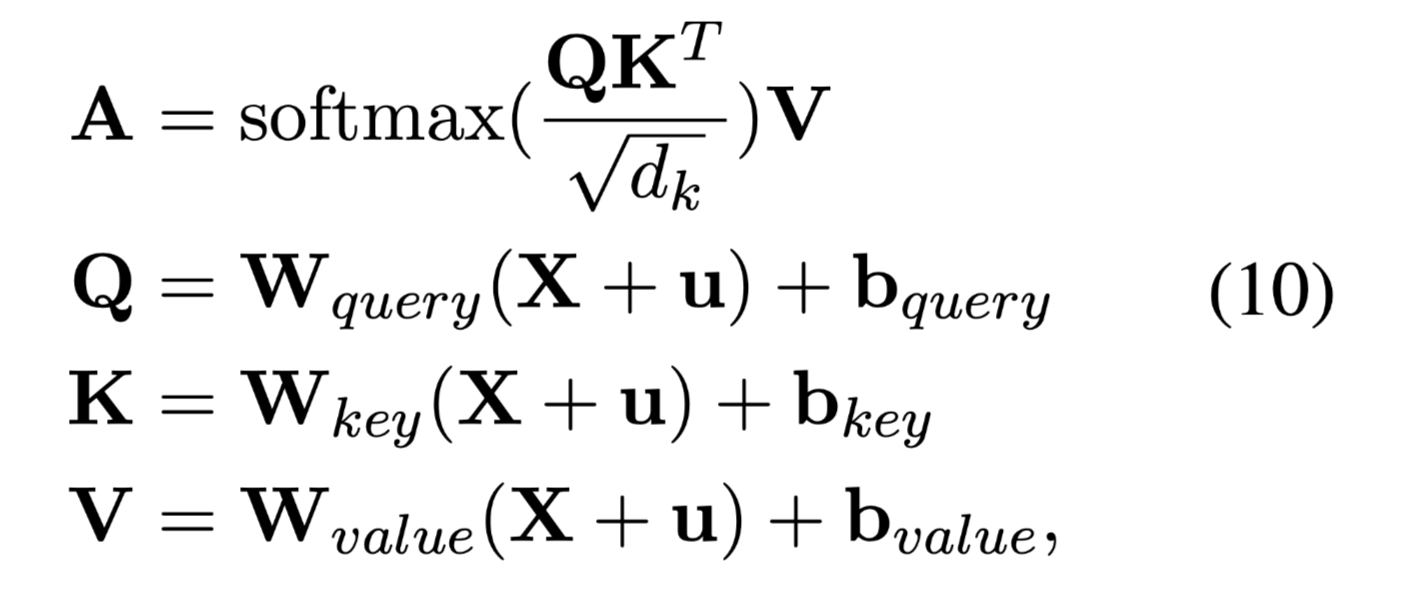
$d_k$ is the dimension of the attention key
TDEER采用二元分类器来识别给定当前主体实体和关系的客体实体的起始位置:
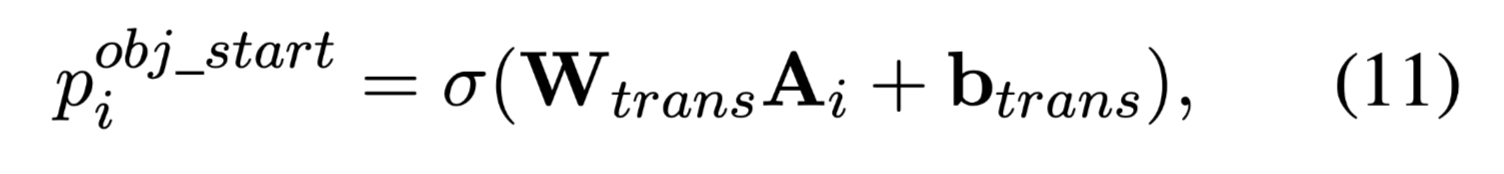
对应的损失函数:
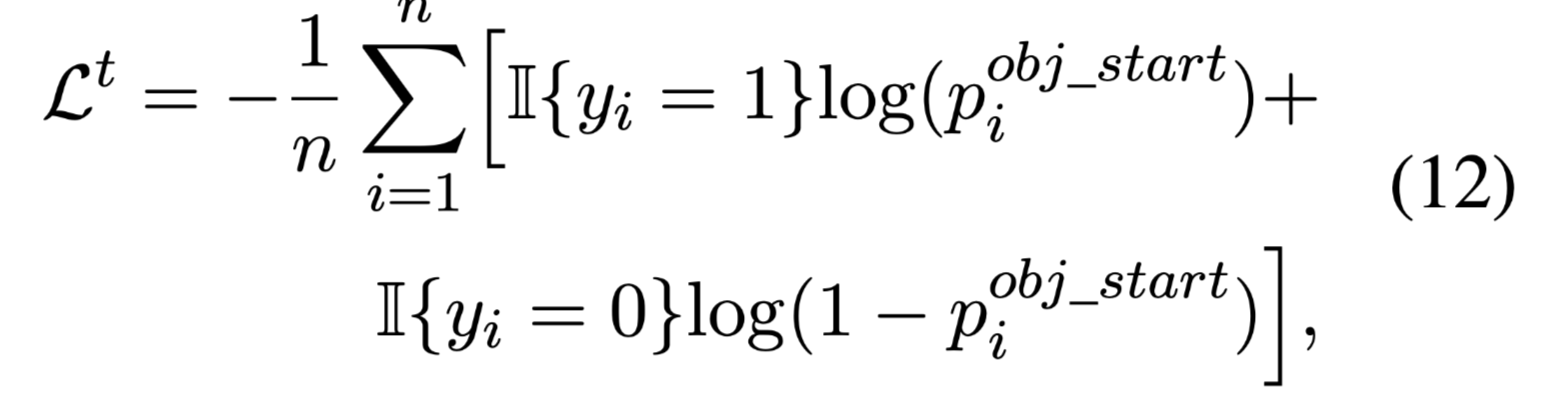
如果没有起始位置匹配上,则当前主体实体和关系没有三元组。
Negative Sample Strategy
在TDEER中,翻译解码器依赖于实体标记和关系检测器,因此翻译检测器可能从上游组件接收错误实体或关系。因此,本文引入了一种负采样策略来检测和减轻来自上游组件的误差。
Joint Training
联合训练了基于跨度的实体标记模型、关系检测器和翻译解码器。联合损失函数的定义如下:
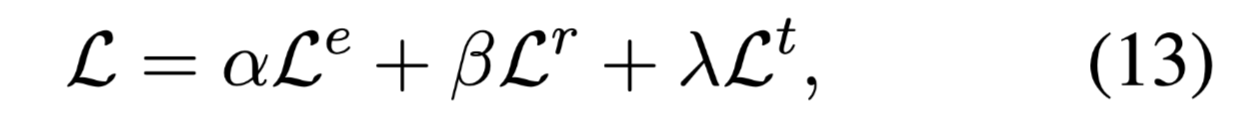
三个系数都为常量。
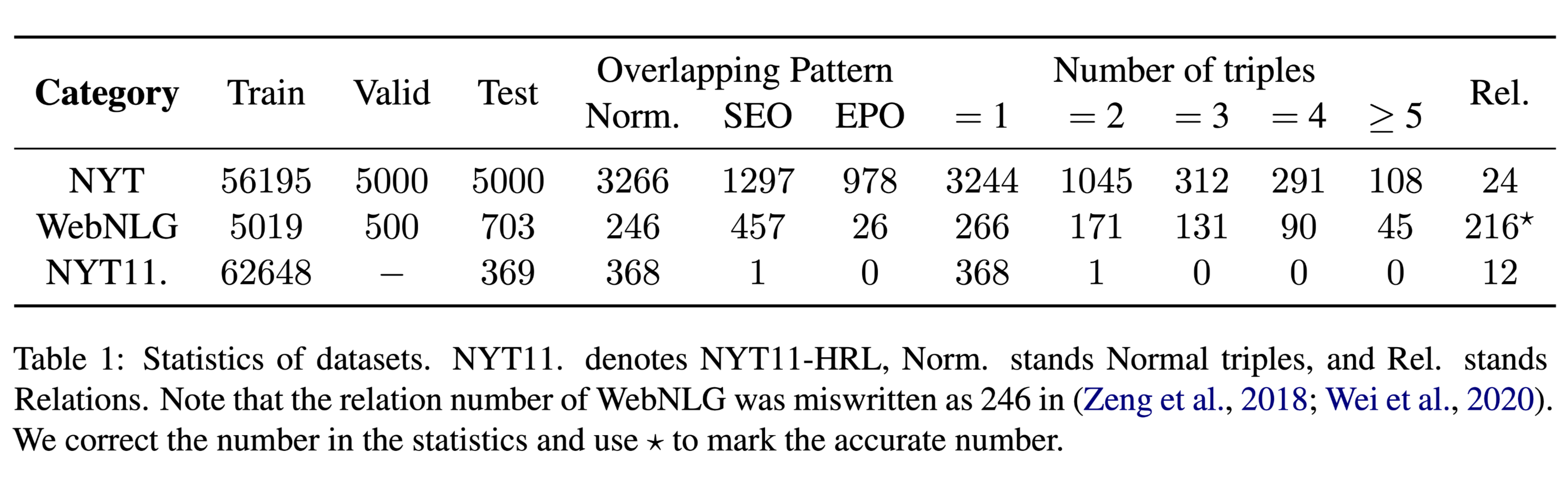
数据集
- NYT
- WebNLG
- NYT11
性能水平
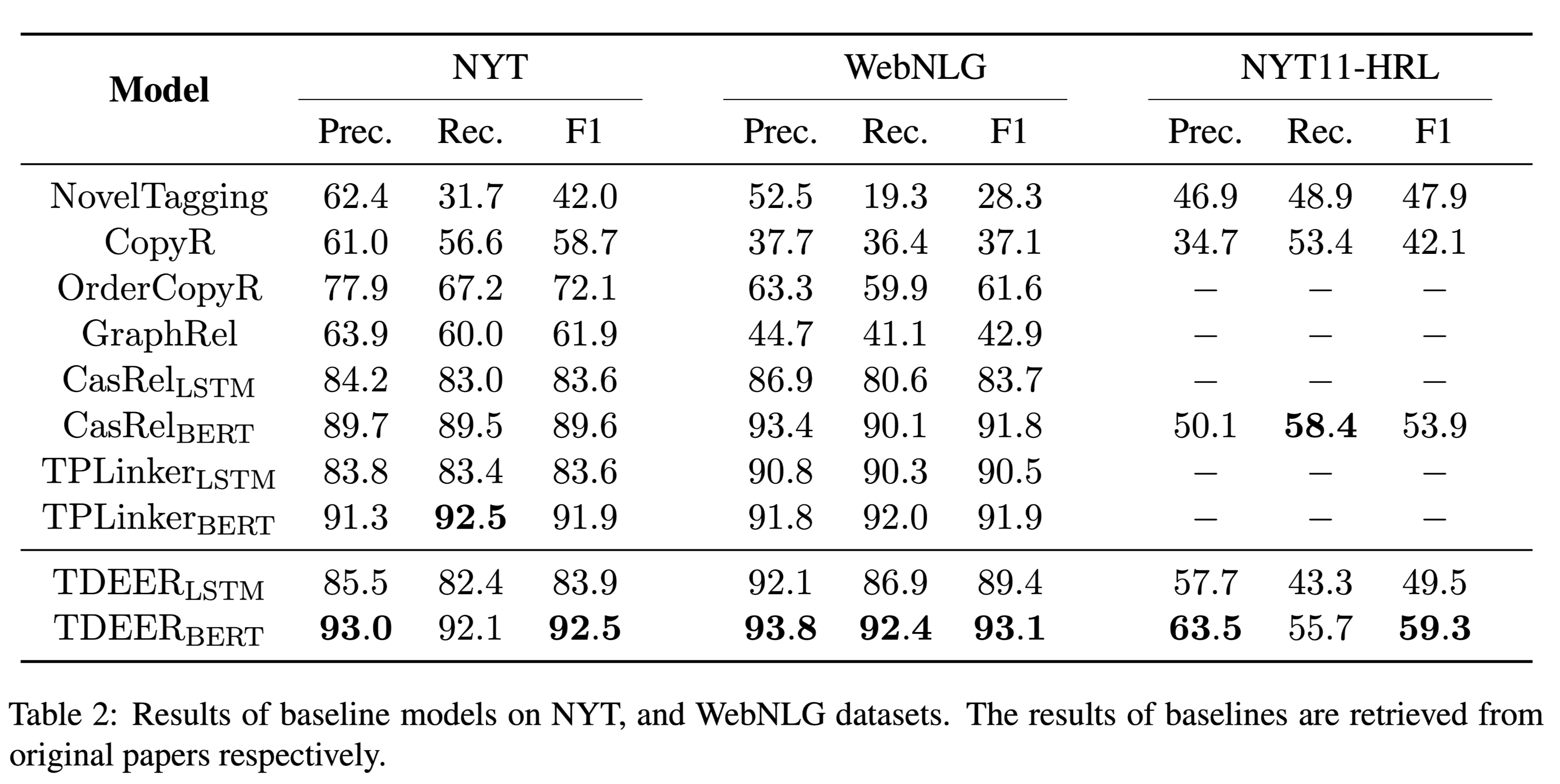
结论
主要贡献:
- 本文提出了一种新的翻译-解码模式,用于从非结构化文本中联合提取实体和关系。
- TDEER可以有效地处理棘手的重叠三元组问题。
- TDEER的速度大约是当前SOTA型号的2倍。
所提出的负样本策略用于缓解误差累积问题,虽然有效的,但它可能会增加训练时间。