
Generalizing to the Future Mitigating Entity Bias in Fake News Detection
Generalizing to the Future Mitigating Entity Bias in Fake News Detection
论文:Generalizing to the Future:Mitigating Entity Bias in Fake News Detection代码:https://github.com/ictmcg/endef-sigir2022会议:SIGIR 2022飞书:https://zlc6vppbrn.feishu.cn/docx/doxcnGnsfAAZXGYBUlKaqWYX4mg
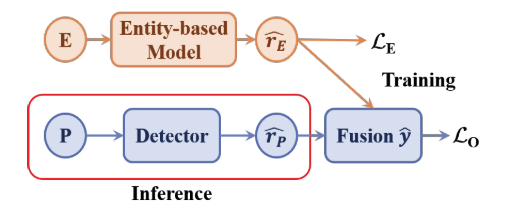
任务现有的假新闻检测方法忽略了真实数据中的非预期实体偏差,严重影响了模型对未来数据的泛化能力。 例如,2010-2017年,包含“唐纳德·特朗普”实体的97%的新闻在我们的数据中是真实的,但这一比例在2018年降至仅33%。 这将导致在前一个场景中训练的模型很难推广到后一个场景,因为它倾向于预测关于唐纳德·特朗普的新闻是真实的,以降低训练损失。
本文提出了一个实体去偏框架(ENDEF),该框架从因果角度出发,通过减轻实体偏差,虚假新闻检测模型推广到未来数 ...
Multi-span Style Extraction for Generative Reading Comprehension
Multi-span Style Extraction for Generative Reading Comprehension
论文:https://arxiv.org/abs/2009.07382 代码:https://github.com/chunchiehy/musst 会议:AAAI-2021 飞书:https://zlc6vppbrn.feishu.cn/docx/doxcnnIj90LvJt2BV33MMNyEKbh
任务生成式机器阅读理解(MRC)的答案通常分布在输入问题和文档中,正确答案由单个或多个片段组成。对于答案为单个片段的MRC任务通常称为抽取式MRC,并且已有大量性能优异的single-span抽取模型,但当场景切换到生成式任务时通常会产生不完整的答案或引入多余的词,因此本文的目标是将single-span提取方法扩展到multi-span,使用生成式MRC的方法解决multi-span的QA问题。
方法(模型)MUSST for MUlti-Span STyle extraction由3个模块组成:passage ranker, multi-span a ...
Optimal Partial Transport Based Sentence Selection for Long-form Document Matching
Optimal Partial Transport Based Sentence Selection for Long-form Document Matching
论文:Optimal Partial Transport Based Sentence Selection for Long-form Document Matching 代码:https://github.com/ruc-wjyu/OPT-Match (暂未开源) 会议:COLING 2022 飞书:https://zlc6vppbrn.feishu.cn/docx/HIyLd9808oq3yvxzz3BcTJEUn1g
任务传统的长文档匹配方法首先在跨文档句子对之间进行对齐,然后聚合所有句子级的匹配信号。但是,这种方法可能会出现问题,尽管两个文档整体上匹配良好,但大多数句子仍然可能不同,因为文档之间的对齐是部分的。那些不同的句子会导致虚假的句子级匹配信号,可能会掩盖真实的句子,从而增加学习匹配功能的难度。因此,准确选择文档匹配的关键句子是以一个关键问题。
本文提出了一种新颖的匹配方法OPT-Match,该组件选择在 ...
组会报告
1. RocketQA系列搜索技术相关论文https://zlc6vppbrn.feishu.cn/docx/doxcnzGc77PTCEGzCqLWt3onTph
2. 长文本https://zlc6vppbrn.feishu.cn/docx/ZL9fdzLeIoYUhyxnO7hcNFPlnZc
Read before Generate! Faithful Long Form Question Answering with Machine Reading
Read before Generate! Faithful Long Form Question Answering with Machine Reading
论文:https://aclanthology.org/2022.findings-acl.61.pdf 会议:ACL2021 飞书:https://zlc6vppbrn.feishu.cn/docx/P45VdH0vmosFNMxwMyxc3R5Anif
任务长文本问答 (LFQA) 旨在为给定问题生成段落长度的答案。当前使用大型预训练模型生成的LFQA工作可以有效地产生流畅且较为相关的内容,但对长文本问答来说,不同的文档可能包含冗余,互补或矛盾的信息,主要的挑战在于如何生成具有较少空洞内容的高置信度(faithful)答案。
关键思想:本文提出了一个新的端到端框架,该框架对答案生成和机器阅读进行联合建模,使用与答案相关的细粒度的显著信息来增强生成模型,这些信息可以被视为对事实的强调。
a fluent and relevant but unfaithful answer:
unfaithful answer 会误导读 ...
Graph Convolutional Networks for Text Classification
Graph Convolutional Networks for Text Classification
论文:https://arxiv.org/abs/1809.05679
代码:https://github.com/yao8839836/text_gcn
https://github.com/codeKgu/text-gcn
https://github.com/chengsen/pytorch_textgcn
会议:AAAI 2019
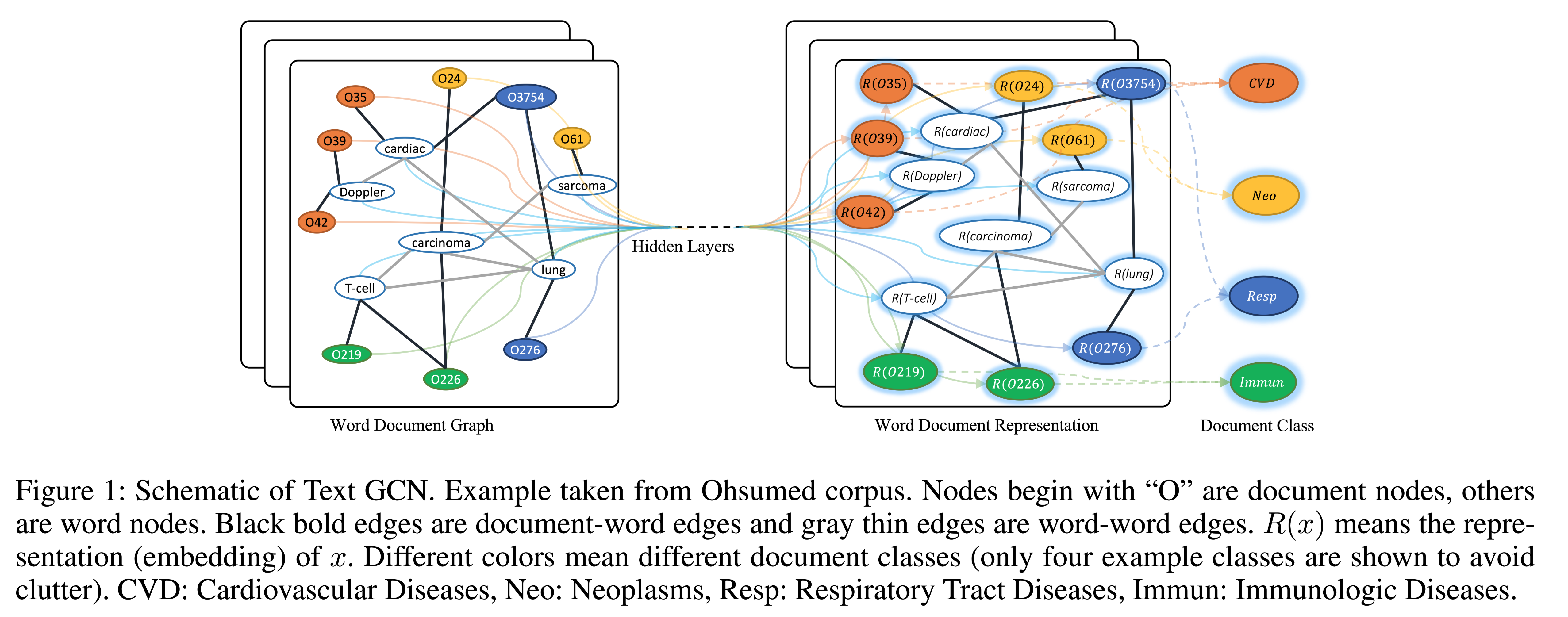
任务文本分类是自然语言处理中一个重要的经典问题。有许多研究将卷积神经网络应用于分类。然而,只有有限的研究探索了更灵活的图卷积神经网络来完成这项任务。在这项工作中,使用图卷积网络进行文本分类。
方法(模型)基于单词共现和文档-单词关系为语料库构建单个文本图,然后为语料库训练文本图卷积网络(Text-GCN)。Text-GCN使用word和document的独热表示进行初始化,然后在文档的已知类标签的监督下,联合学习word和document的嵌入。
Graph Convolutional Networks (GCN)GCN是一个多层神经 ...
Iterative GNN-based Decoder for Question Generation
Iterative GNN-based Decoder for Question Generation
论文:https://aclanthology.org/2021.emnlp-main.201/
代码:https://github.com/sion-zcfei/IGND/issues/1 但仓库目前(2022-4-25)是空的
会议:EMNLP 2021
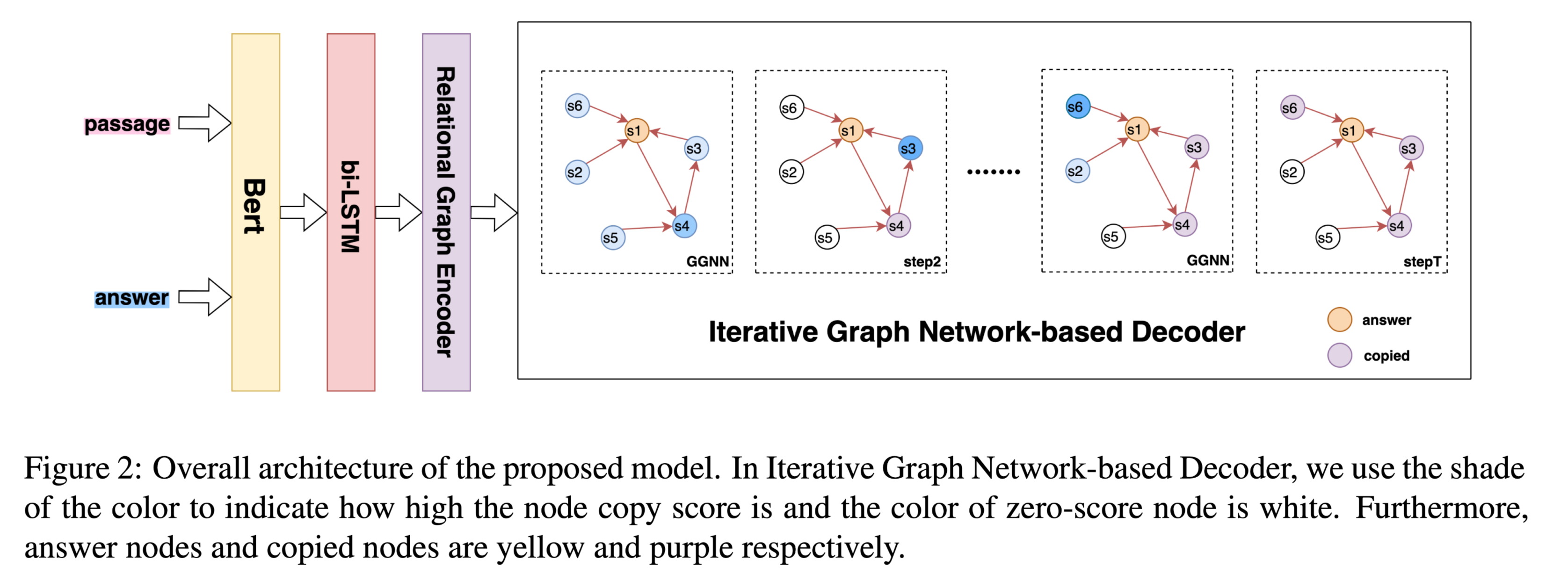
任务自然问题生成(Natural question generation,QG)旨在从文章中生成问题,生成的问题从文章中得到回答。大多数具有最先进性能的模型在每个解码步骤都会建模先前生成的文本。但是先前的工作存在两个问题:
他们忽略了隐藏在先前生成的文本中的丰富结构信息。
他们忽略了拷贝的单词对文章的影响。
从上图中可以看到,拷贝的单词 donald davies 对下一个拷贝的单词 develop 有较大的贡献。复制的单词donald davies是文章的主体,而答案routing methodology 是本文的客体,他们之间包含结构信息。
方法(模型)为了解决上述两个问题,在本文中,设计了一个基于迭代图网络的 ...
RikiNet Reading Wikipedia Pages for Natural Question Answering
RikiNet: Reading Wikipedia Pages for Natural Question Answering
论文:https://arxiv.org/abs/2004.14560
会议:ACL 2020
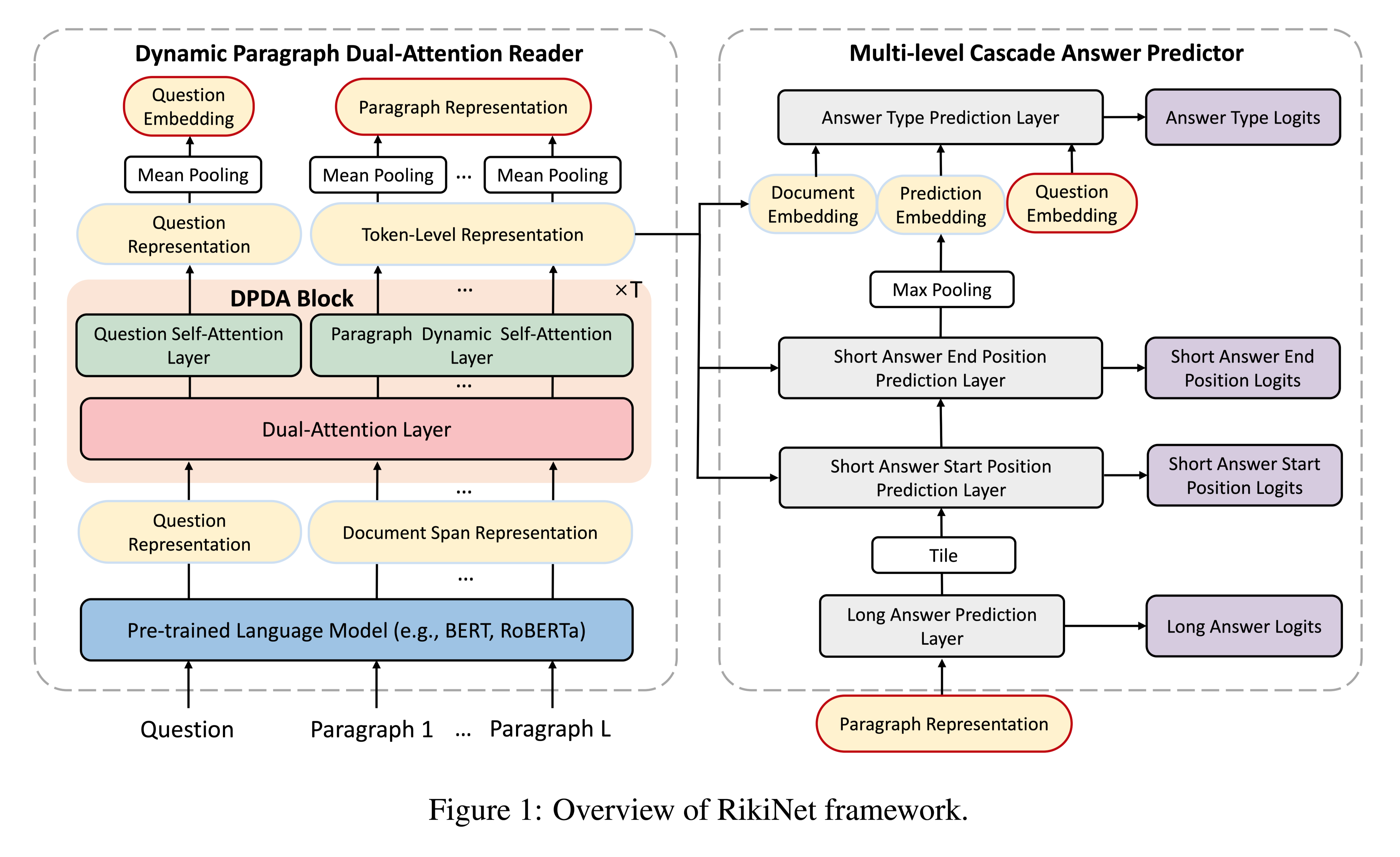
任务阅读长文档来回答open-domain问题在自然语言理解中仍然具有挑战性。本文介绍了一种新的模型,称为RikiNet,它通过阅读维基百科页面来自然地回答问题。RikiNet包含一个dynamic paragraph dual-attention reader和一个multi-level cascaded(级联) answer predictor。阅读器通过一套互补的注意机制动态地表达文档和问题。然后将这些表示输入预测器,以级联方式获得短答案的范围、长答案的段落和答案类型。
NQ数据集相对于之前阅读理解任务数据集的两个挑战:
首先,NQ没有为每个问答(QA)对提供一个相对较短的段落,而是提供了一个完整的维基百科页面,与其他数据集相比,该页面要长得多。
其次,NQ任务不仅要求模型像以前的MRC任务一样找到问题的答案跨度(称为短答案),还要求模型找到包含回答问 ...
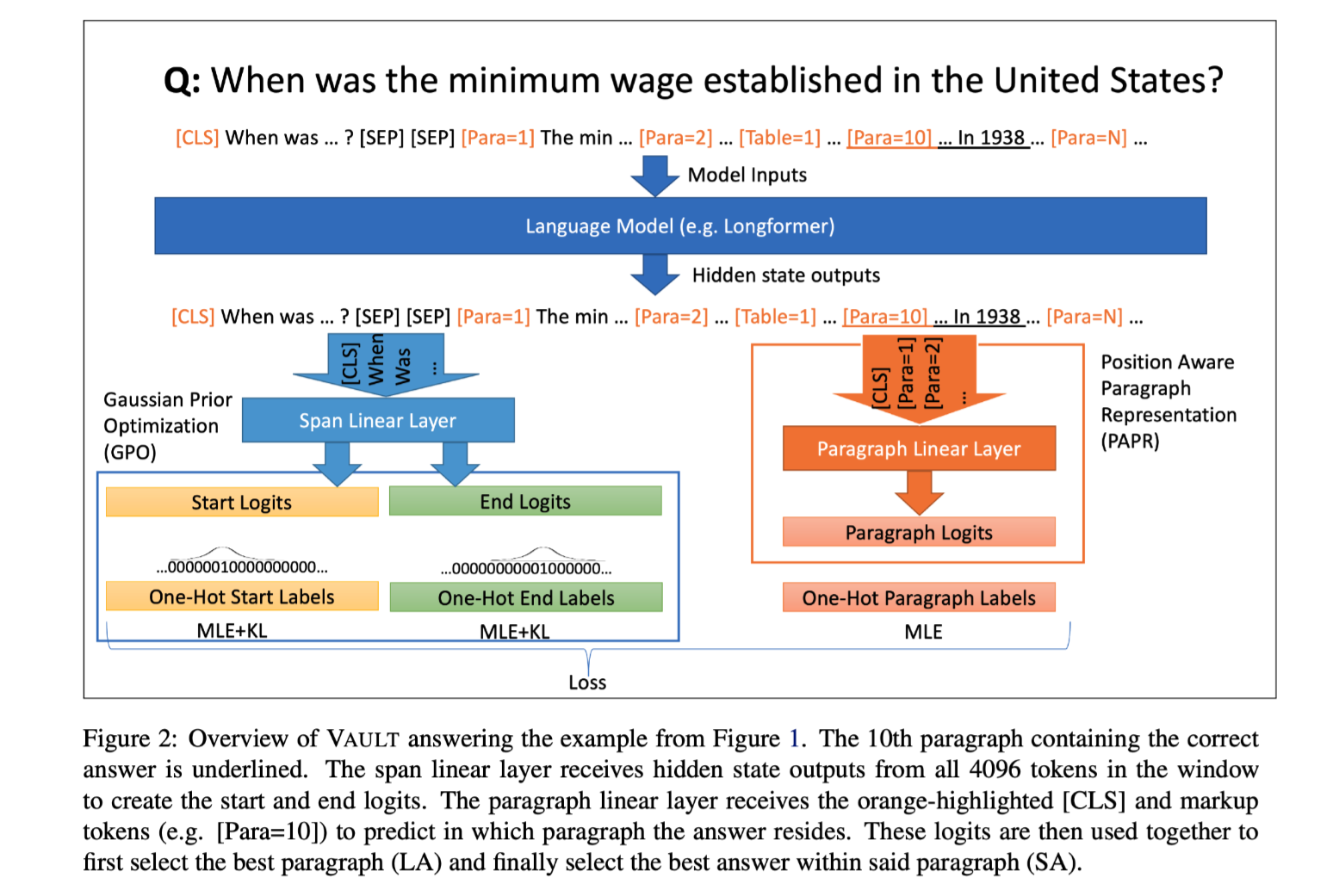
VAULT VAriable Unified Long Text Representation for Machine Reading Comprehension
VAULT: VAriable Unified Long Text Representation for Machine Reading Comprehension
论文:https://arxiv.org/abs/2105.03229
会议:ACL 2021
任务 现有的机器阅读理解(MRC)模型需要复杂的模型体系结构,才能有效地对具有段落表示和分类的长文本进行建模,从而使推理的计算效率不高。在这项工作中,本文提出了VAULT:一种轻量级、并行高效的MRC段落表示方法,基于长文档输入的上下文表示,使用一种新的基于高斯分布的目标进行训练,该目标密切关注ground-truth的部分正确实例。
方法(模型)传统的QA,模型训练时,答案范围的标注非对即错,过于绝对。实际上,与真实答案重叠的跨度应被视为部分正确。基于此,本文将真实答案跨度的起始和结束位置视为类高斯分布,而不是单点,并使用统计距离优化模型。
模型:VAULT((VAriable Unified Long Text representation),因为它可以在任何位置处理可变数量和长度的段落,使用相同的统一 ...
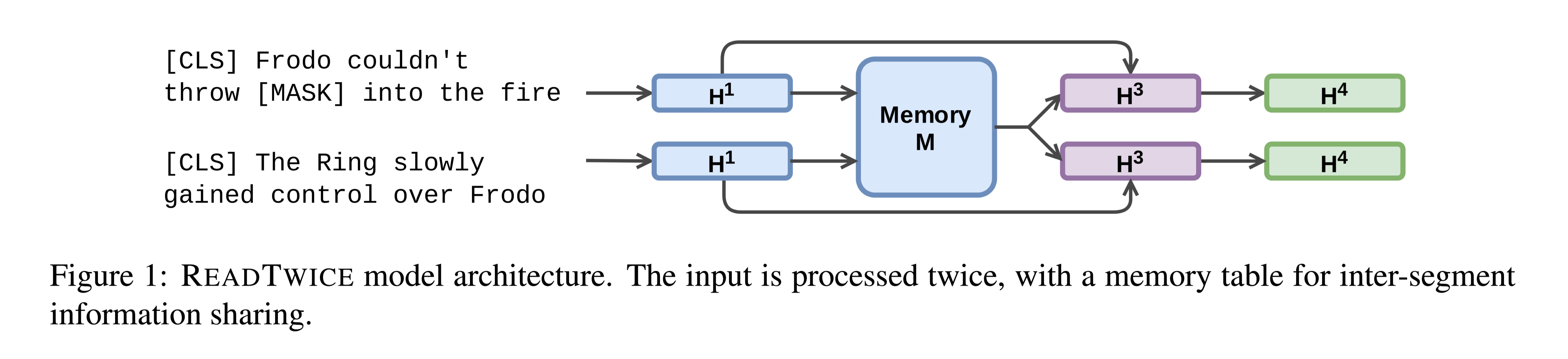
READTWICE Reading Very Large Documents with Memories
READTWICE: Reading Very Large Documents with Memories
论文:https://arxiv.org/abs/2105.04241
会议:NAACL 2021
任务知识密集型任务(如问答)通常需要吸收大量输入(如书籍或文章集)不同部分的信息。本文提出READTWICE,它结合了以前的几种方法的优点,用Transformers建模long-range dependencies。其主要思想是以小段并行方式阅读文本,将每个段汇总到一个内存表中,以便在第二次阅读文本时使用。
方法(模型)主要思想:
将一个长文本输入当作一个较短的文本片段的集合,独立地、并行地读取。然后,编码器再次读取每个片段,使用其他片段的压缩信息做增强。
模型结构:
memory module that holds compressed information from all segments. That compressed information is used only once: in the second pass.
在第一次读取中,每个段都用标准的B ...
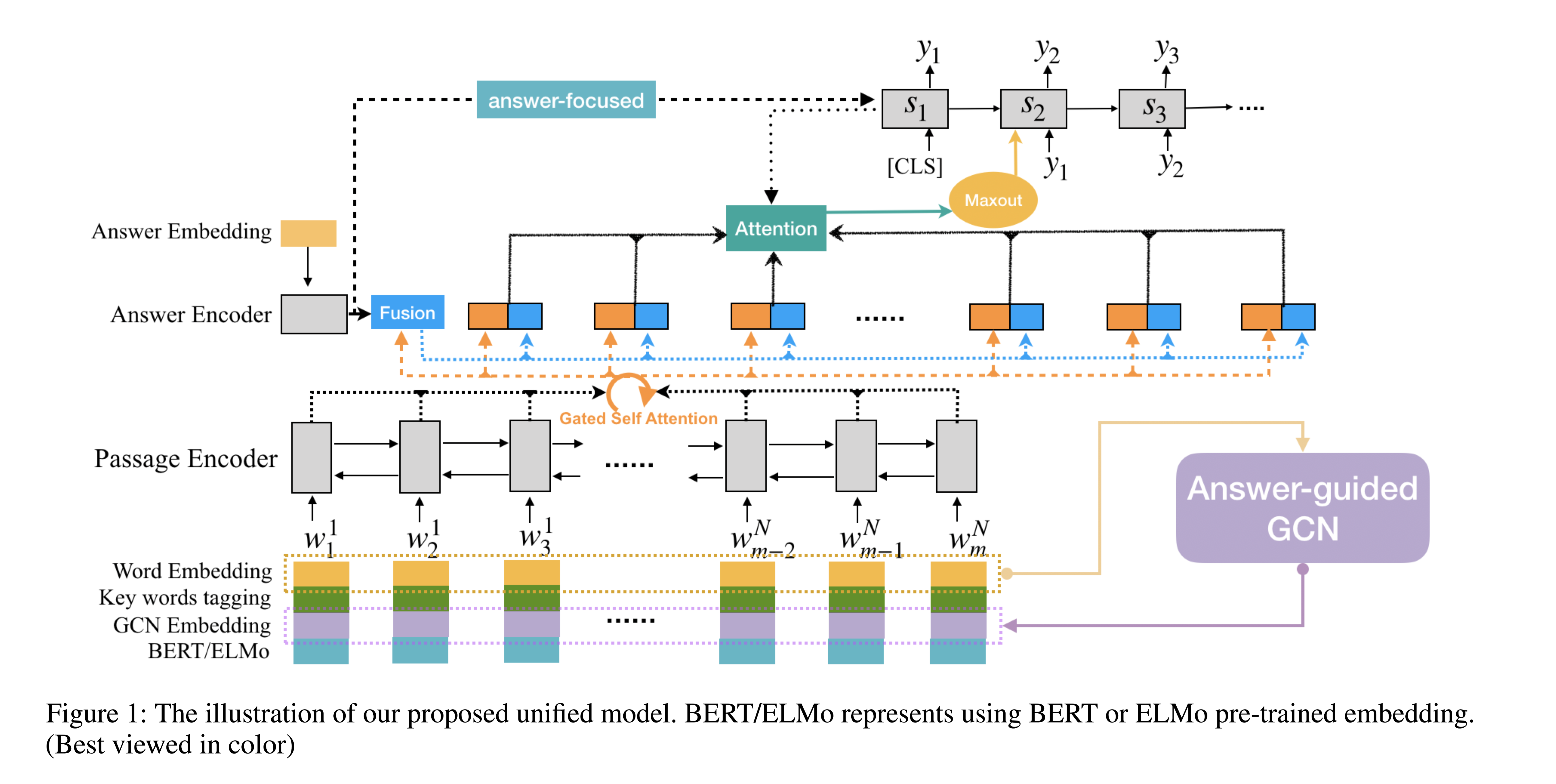
EQG-RACE Examination-Type Question Generation
EQG-RACE: Examination-Type Question Generation
论文:https://arxiv.org/abs/2012.06106
代码:https://github.com/jemmryx/EQG-RACE
会议:AAAI-2021
任务 本文提出了一种创新的考试型问题生成方法(EQG-RACE),基于从RACE提取的数据集生成类似考试的问题。EQG-RACE中采用了两个主要的策略来处理离散的答案信息和长语境中的推理:
一个粗略的答案和关键句子标签方案被用来加强输入的表述。
一个答案引导的图卷积网络(AG-GCN)被设计用来捕捉揭示句子间和句子内关系的结构信息。
方法(模型)构建数据集的两个挑战:
首先,答案往往是完整的句子(或长短语),而不是包含在输入序列中的短文本跨度,这使得之前的答案标签方法失效。
其次,上下文段落较长,问题是通过多个句子的深度推理而产生的,这使得像LSTM这样的顺序编码方法无法发挥作用。
解决方案:
为了解决第一个问题,本文采用了一种远距离监督的方法来寻找关键的答案词和关键的句子,然后将它们融 ...
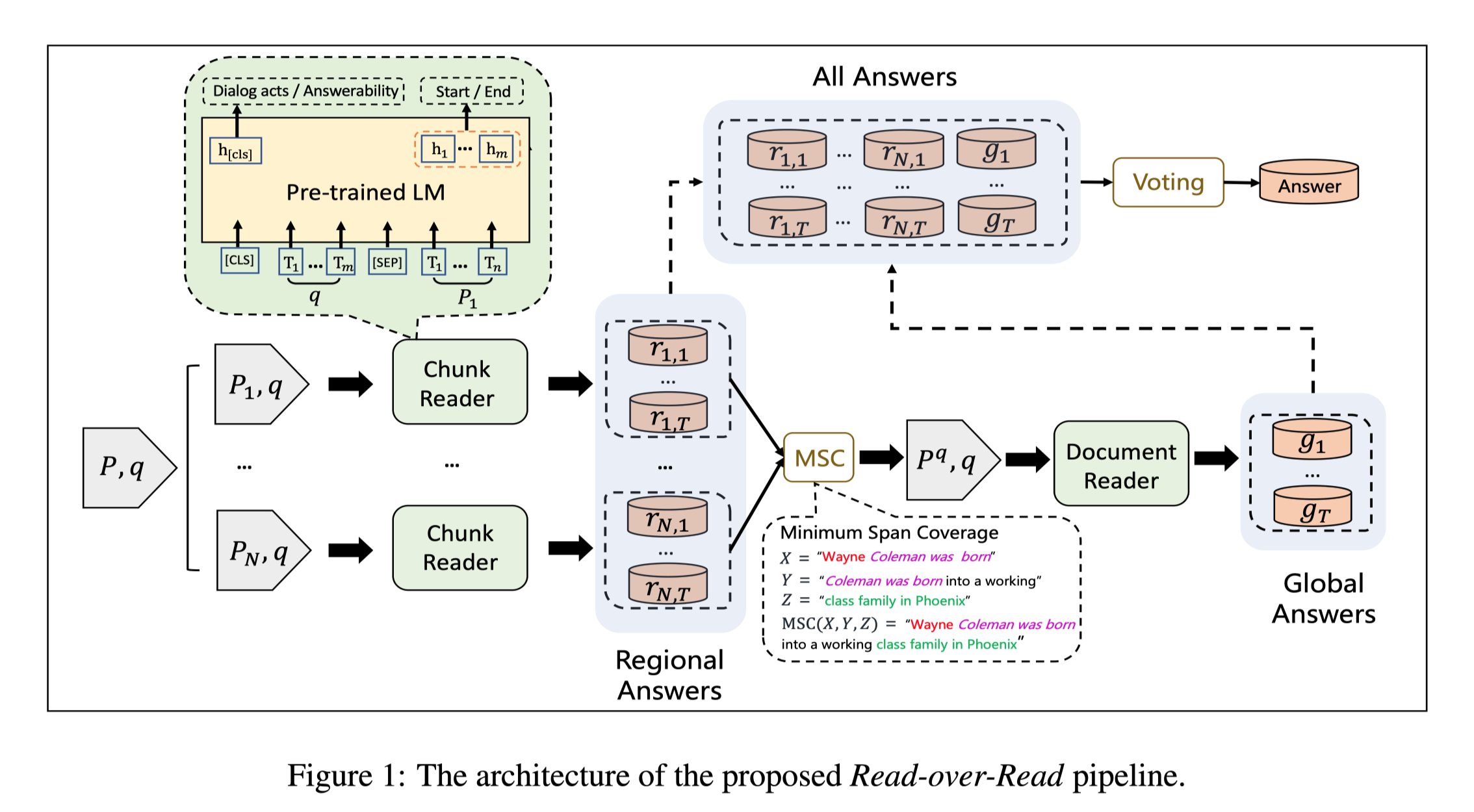
RoR Read-over-Read for Long Document Machine Reading Comprehension
RoR: Read-over-Read for Long Document Machine Reading Comprehension
论文:https://arxiv.org/abs/2109.04780
代码:https://github.com/jd-ai-research-nlp/ror
会议:EMNLP2021
任务 基于Transformer的预训练语言模型,例如BERT,由于编码长度的限制(如512个WordPiece tokens),一个长文档通常被分割成多个独立阅读的块。这导致阅读领域被限制在个别的块上,没有信息协作的长文档机器阅读理解。为了解决这个问题,本文提出了RoR,一种read-over-read的方法,它将阅读领域从块扩展到文档。
为了处理超过长度限制的长文件,一个常用的方法是将文件分成多个独立的块,然后分别从每个块中预测答案。这些答案中得分最高的跨度被选为最终答案。这种方法很直接,但会导致两个问题:
阅读领域被限制在区域块中,而不是完整的文件。
答案的分数不具有可比性,因为它们没有在块中进行全局标准化。
方法( ...
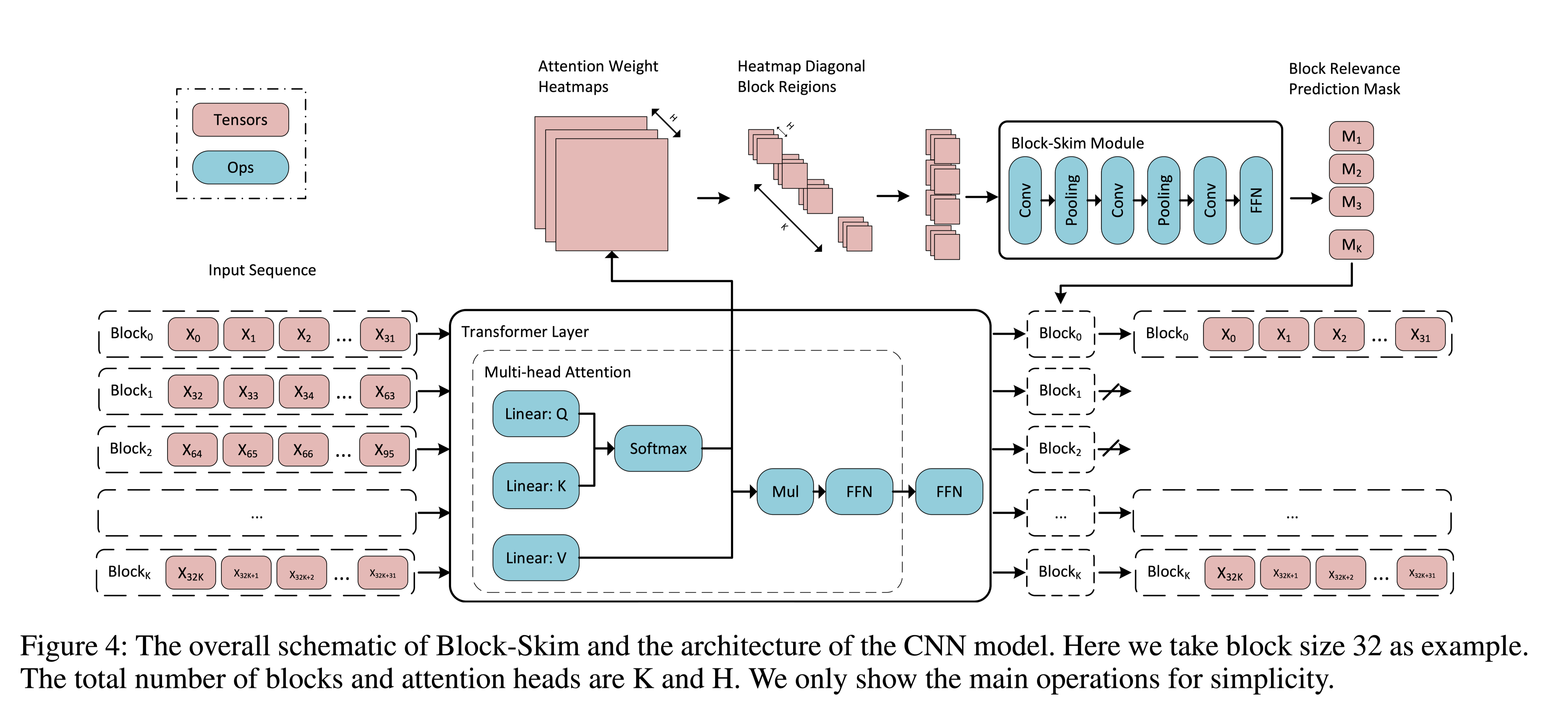
Block-Skim Efficient Question Answering for Transformer
Block-Skim: Efficient Question Answering for Transformer
论文:https://arxiv.org/abs/2112.08560
会议:AAAI 2022
任务 NLP任务中使用的公共Transformer编码器处理所有层中上下文段落中所有输入tokens的隐藏状态。然而,与序列分类等其他任务不同,回答提出的问题不一定需要上下文段落中的所有tokens。基于这个动机,本文提出了Block-Skim,它学习在更高的隐藏层中跳过不必要的上下文,以提高和加速Transformer的性能。Block-Skim的关键思想是确定必须进一步处理的上下文,以及在推理过程中可以在早期安全地丢弃的上下文。关键的是,作者发现这样的信息可以从Transformer模型中的self-attention weights中得到。作者早期在较低层进一步修剪与不必要位置相对应的隐藏状态,显著节省了推理时间。
目标效果示例:
方法(模型)Layer 4 和 Layer 9的答案相关和不相关tokens权重比较:
箱型图:上面的是答案相关的t ...
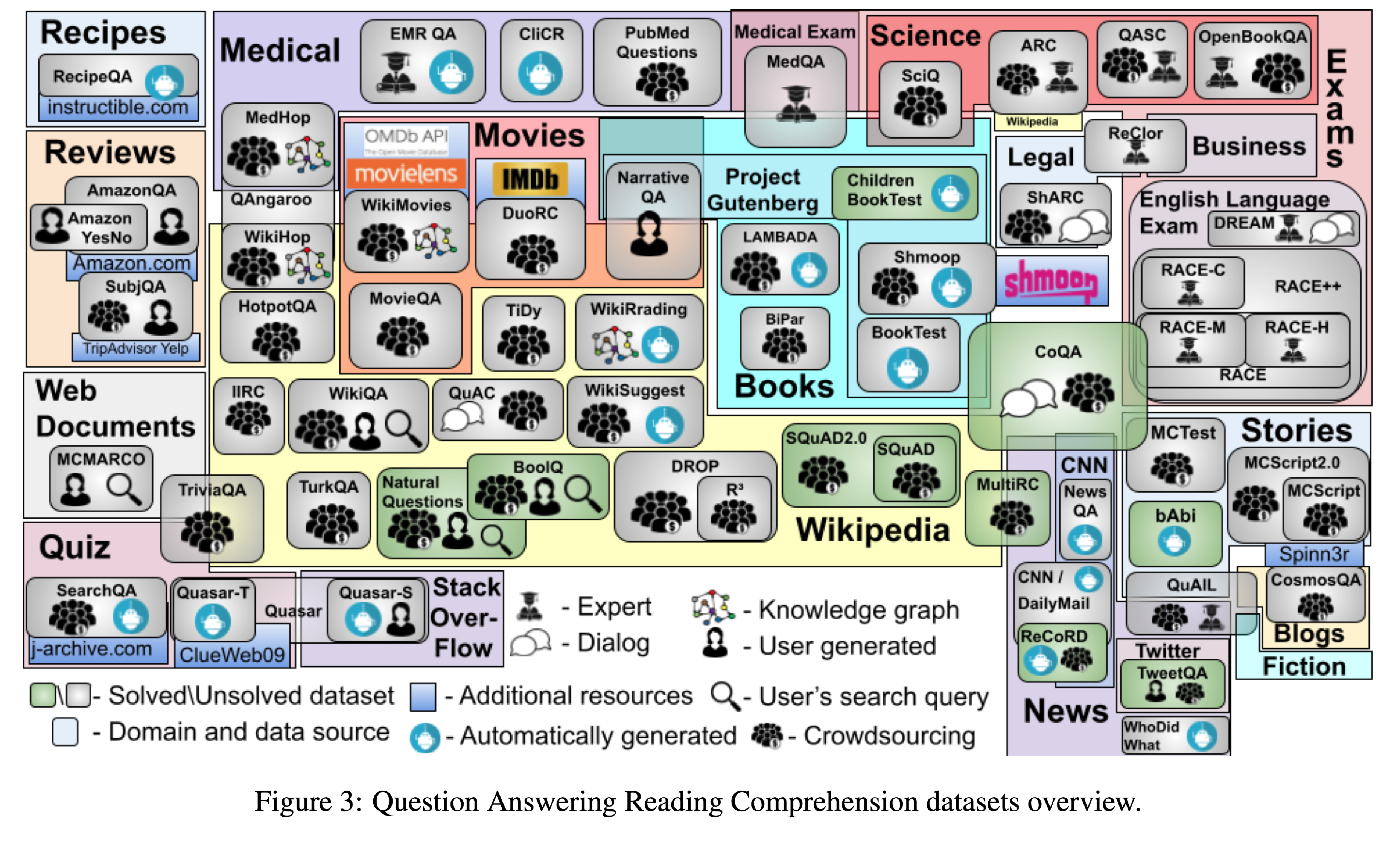
English Machine Reading Comprehension Datasets A Survey
English Machine Reading Comprehension Datasets: A Survey
论文:https://arxiv.org/abs/2101.10421
代码:https://github.com/dariad/rczoo
任务本文调查了60个英语机器阅读理解数据集,以期为其他对此问题感兴趣的研究人员提供一个方便的资源。本文根据问答形式对数据集进行分类,并在不同维度上进行比较,包括规模、数据源、创建方法、人类评估水平、数据集是否已“解决”、排行榜的可用性、最常见的第一个问题token,以及数据集是否公开可用。
数据集使用的领域以及数据集之间的交集
数据集以英文MRC数据集发布时间线;
Question, Answer, and Passage Types
问题类型分为:Statement, Query, and Question
答案类型分为:Cloze, Multiple Choice,Boolean, Extractive, Generative
现有数据集的详细分类在下文的表1。
问题和答案之间的层次结构和关系:
Answer ...

