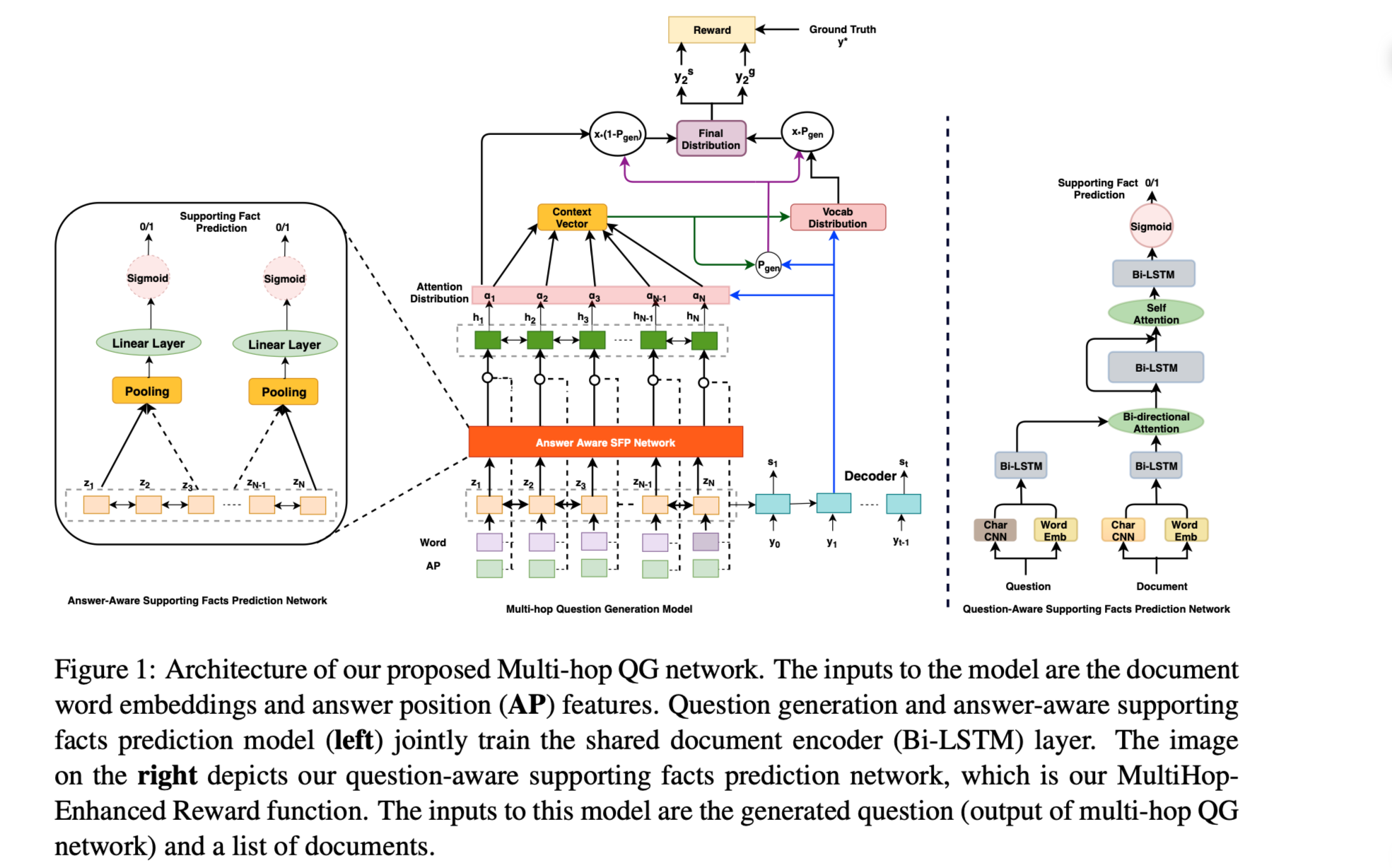
Iterative GNN-based Decoder for Question Generation
Iterative GNN-based Decoder for Question Generation
论文:https://aclanthology.org/2021.emnlp-main.201/
代码:https://github.com/sion-zcfei/IGND/issues/1 但仓库目前(2022-4-25)是空的
会议:EMNLP 2021
任务
自然问题生成(Natural question generation,QG)旨在从文章中生成问题,生成的问题从文章中得到回答。大多数具有最先进性能的模型在每个解码步骤都会建模先前生成的文本。但是先前的工作存在两个问题:
- 他们忽略了隐藏在先前生成的文本中的丰富结构信息。
- 他们忽略了拷贝的单词对文章的影响。
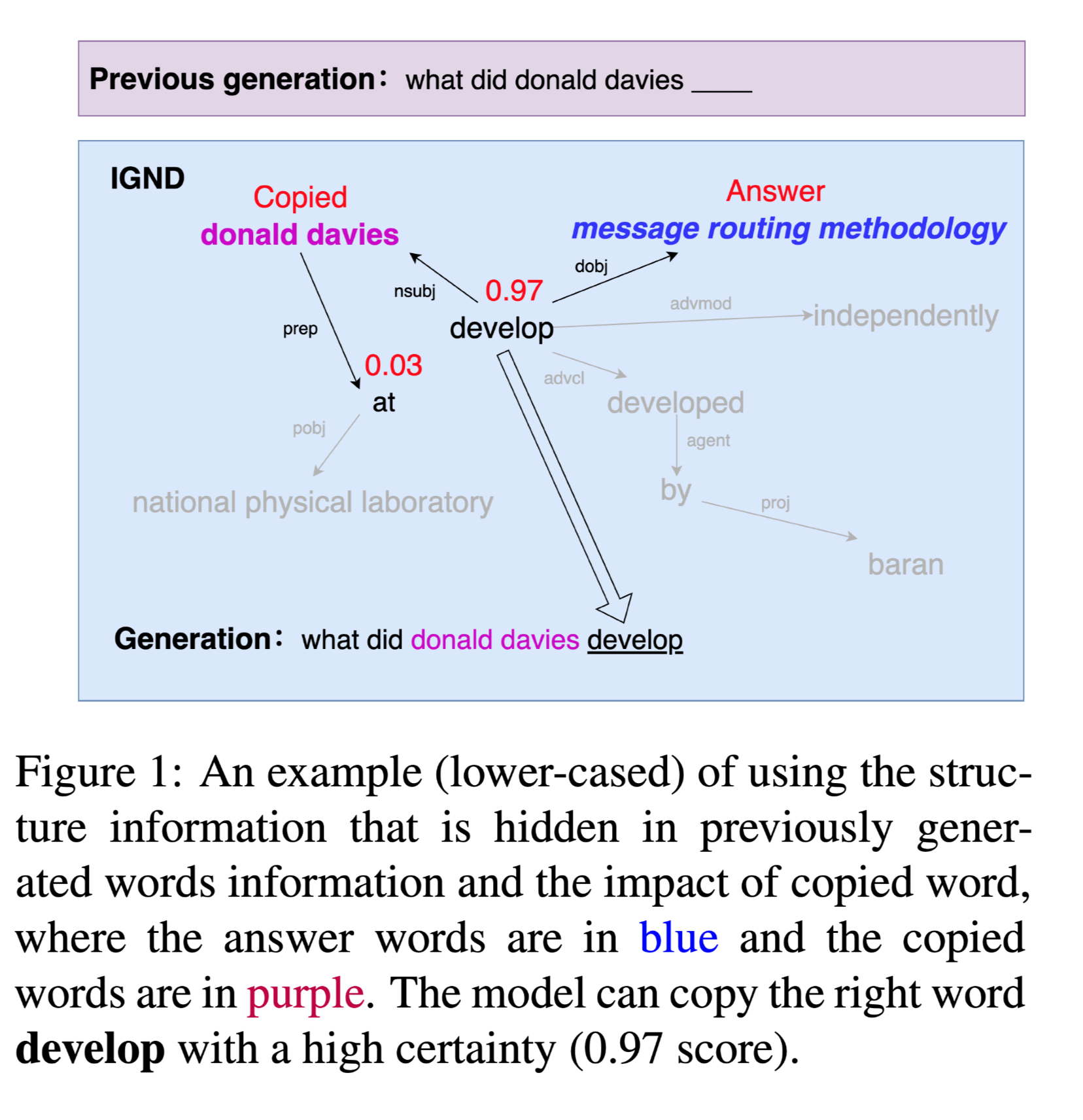
从上图中可以看到,拷贝的单词 donald davies 对下一个拷贝的单词 develop 有较大的贡献。复制的单词donald davies是文章的主体,而答案routing methodology 是本文的客体,他们之间包含结构信息。
方法(模型)
为了解决上述两个问题,在本文中,设计了一个基于迭代图网络的解码器(IGND),使用图神经网络在每个解码步骤对上一代的结构信息进行建模。观察到,从一篇文章中抄袭的单词在整个问题的语义中起着决定性的作用,因此对复制的单词信息进行建模,以获取结构信息,并利用它们对文章的影响。将角色标签引入到段落图中,其中所有单词都有角色标签 no-copy,只有答案单词有标签 answer。IGND在每个解码步骤更新角色标签。例如,当此节点中的单词在此解码步骤复制到问题时,角色标记将更改为 copied。然后,通过一种新的双向门控图神经网络(Bi-GGNN)对信息进行聚合。此外,我们还提出了一种关系图编码器,该编码器使用类似的bi-GGNN来捕获一段文章的依赖关系,从而提高生成效率。此外,本文的图模型捕捉到了文章中促进生成的依赖关系。
问题定义
文章:
答案:$X^a=$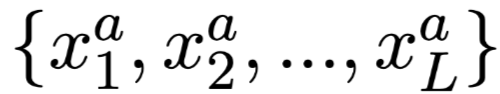
生成问题序列:$\hat Y = $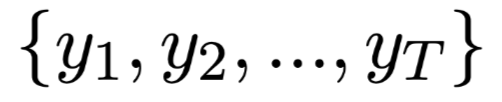
极大似然估计: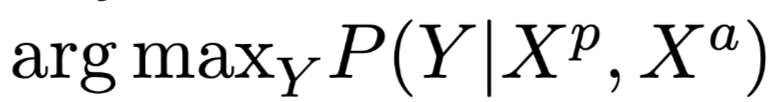
模型结构:
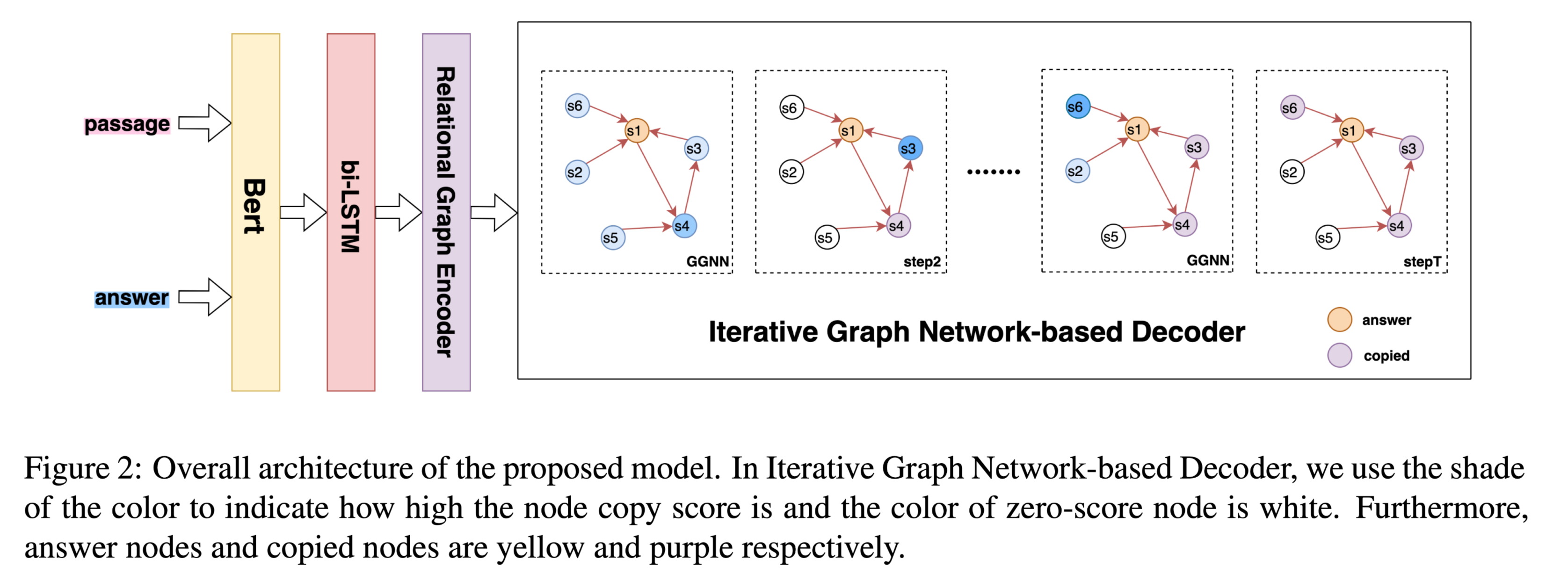
Graph2Seq Model with Iterative Graph Network-based Decoder
与RNN相比,GNN可以有效地利用丰富的隐藏文本结构信息,如语法信息。此外,还可以对序列词之间的全局关系进行建模,以改进表示。本文构造了一个基于依赖树的有向加权文本图G。在段落图中,每个段落词被视为一个节点,两个词之间的依赖关系被视为一条边。
Graph2Seq通过dependency relations编码段落图,使用IGND解码问题序列。
Relational Encoder
答案信息对于生成高质量的答案和回答相关问题至关重要。依赖关系将答案和文章单词联系起来。为了使用依赖关系,本文提出了关系嵌入,为每个单词聚合全局依赖关系。
使用双向LSTM得到隐藏状态$H$:
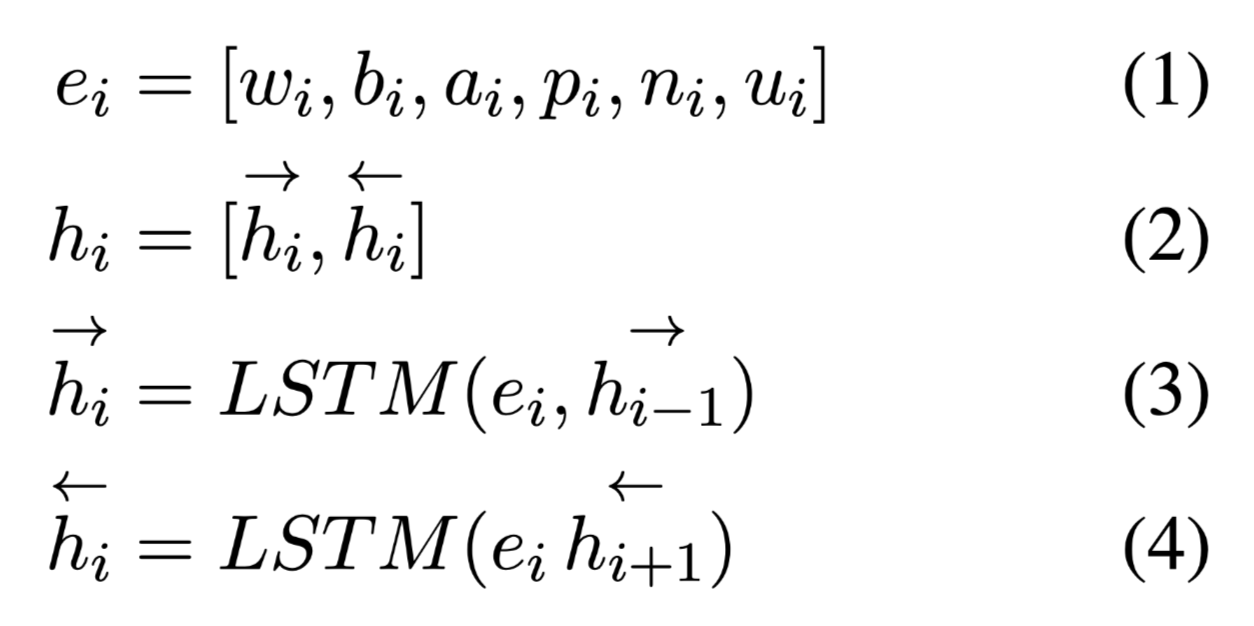
解释:

answer-aware weighted context hidden states $H^p$:
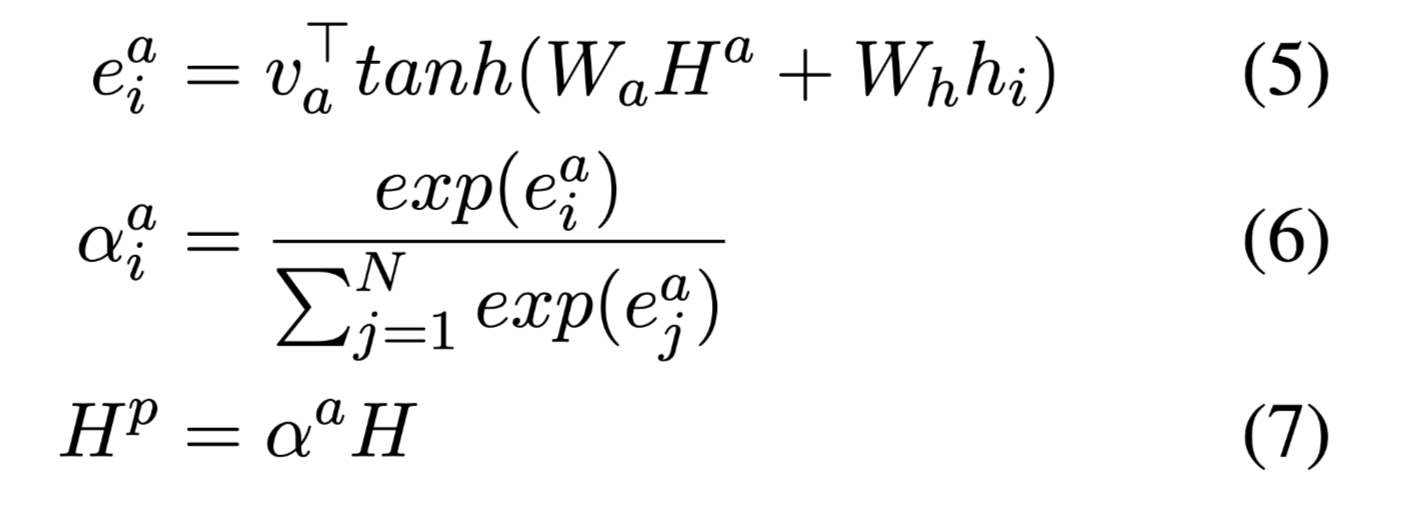
使用GGNN从文本图学习 graph embedding。它在每次迭代中融合来自传入和传出方向的中间节点嵌入(出度和入度)。在bi-GGNN中,每个节点的passage embeddings被初始化为passage embeddings $H^p$,关系嵌入被随机初始化。图参数在计算的每一跳都是共享的。在图中的每个节点上,我们使用平均聚合器聚合相邻节点的passage embedding,得到聚合向量。
聚合向量:
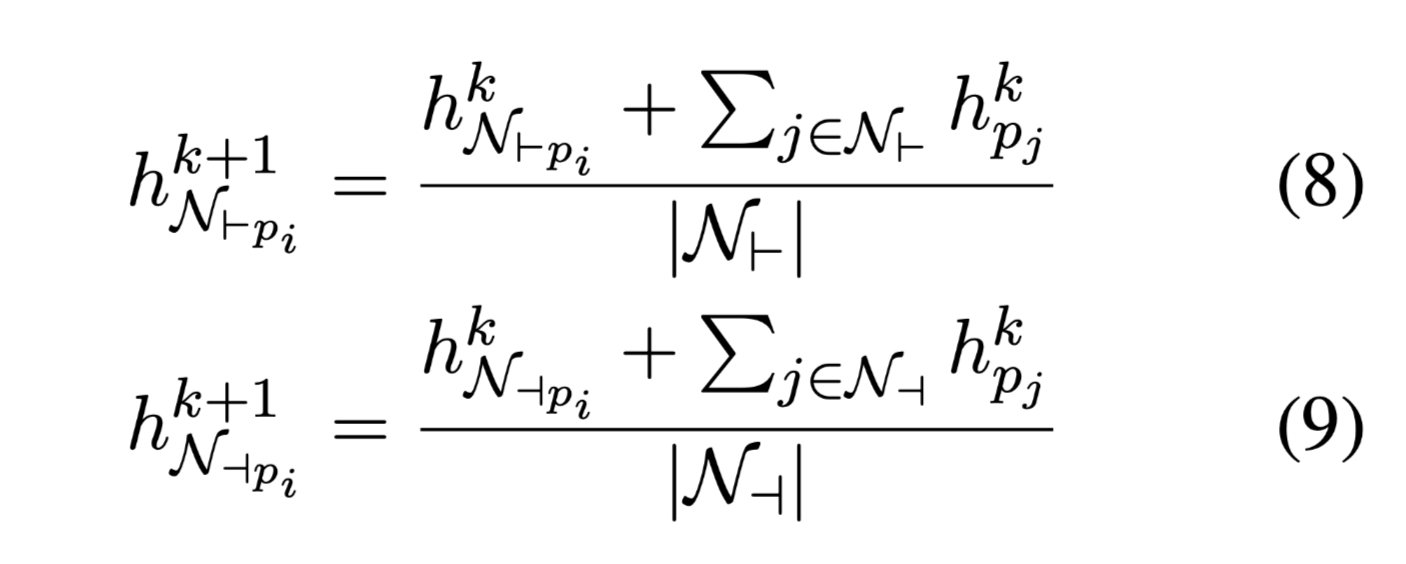
同样的方式可以得到relation embedding的聚合向量:
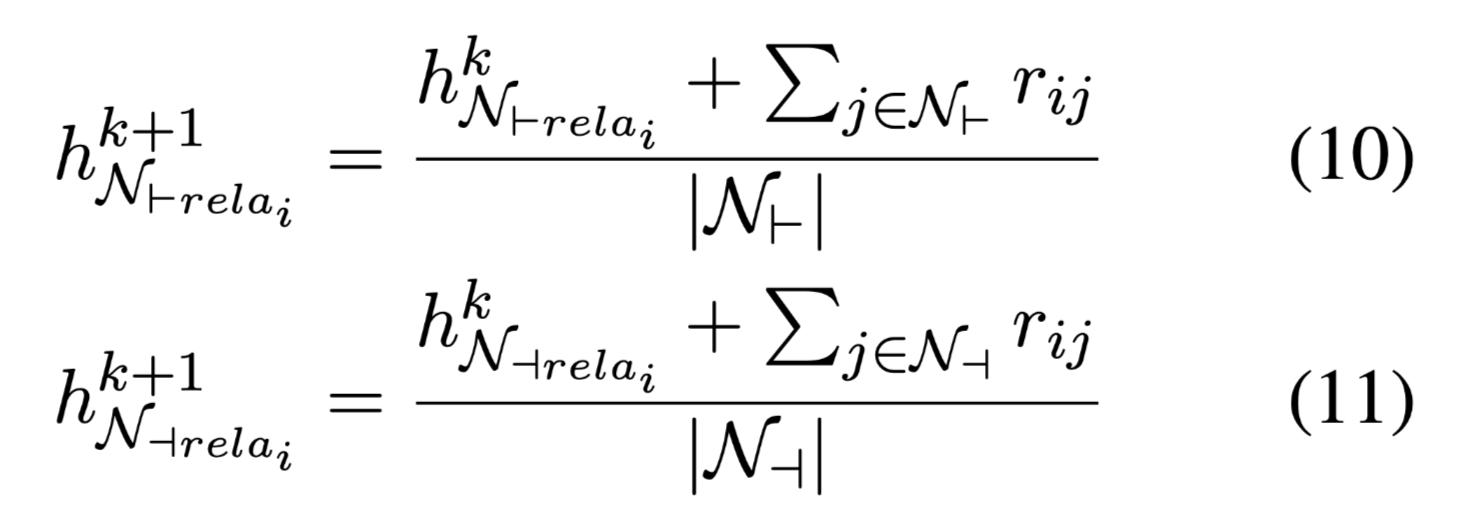
在每一跳将聚和在两个方向上的信息融合在一起:
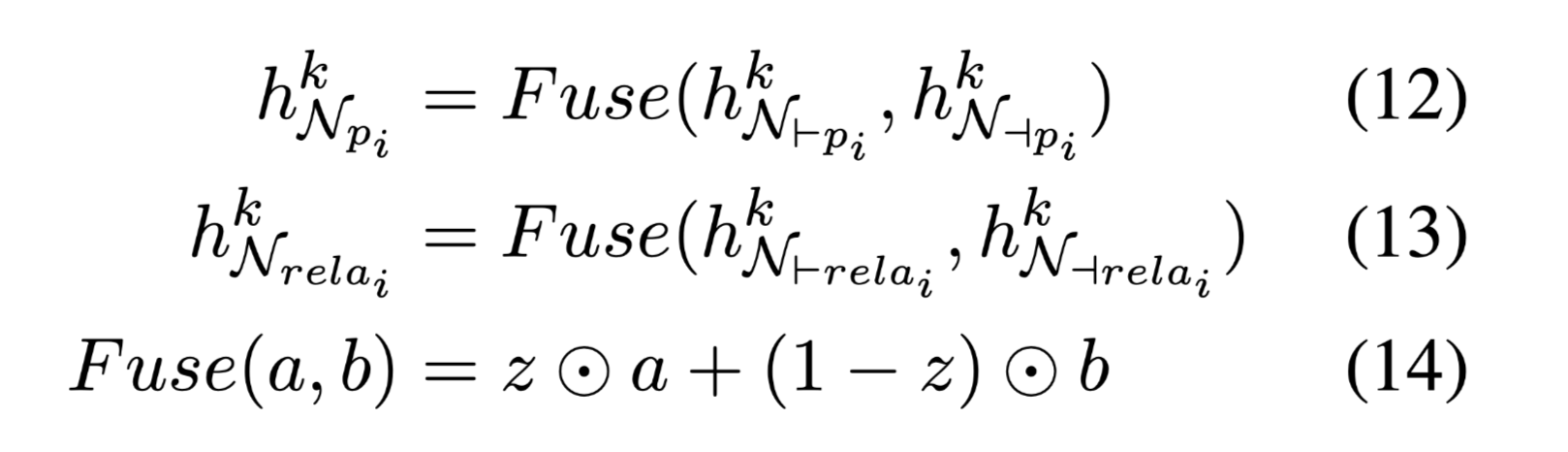
使用GRU更新节点嵌入,合并聚合信息:
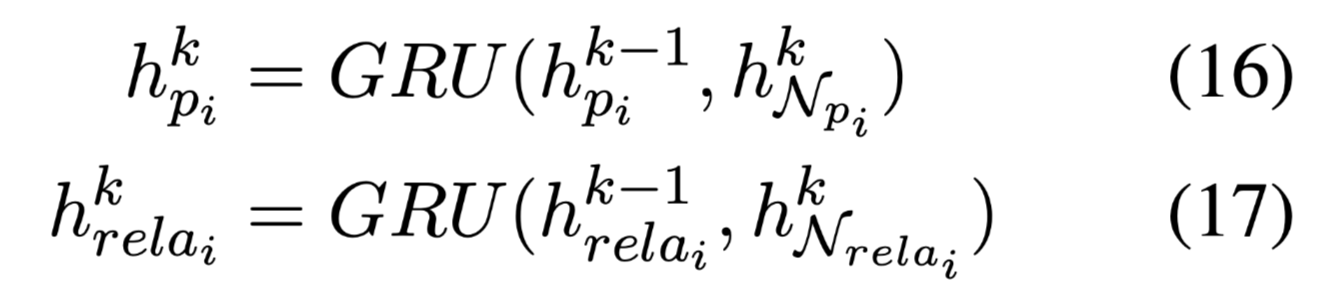
经过n跳的计算,获得最终的上下文嵌入,关系嵌入,结合文本信息和语法信息的节点嵌入计算如下:

最终通过最大池化,可以得到一个图级嵌入:
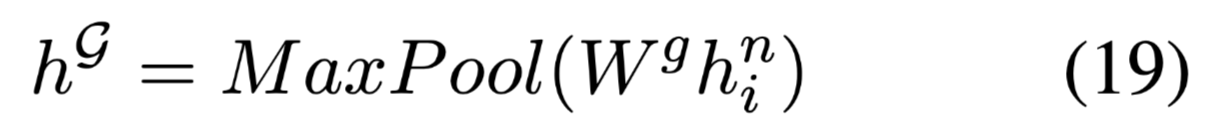
Iterative Graph Network-based Decoder
传统QG任务的解码部分,使用一种具有copy机制的基于注意的LSTM解码器。为了解决这个问题,我们设计了基于迭代图网络的解码器(IGND)。
给节点添加role tag信息,每个节点都有一个角色标签,该标签在每个解码步骤都会更新,包括 answer, copied and no-copy。
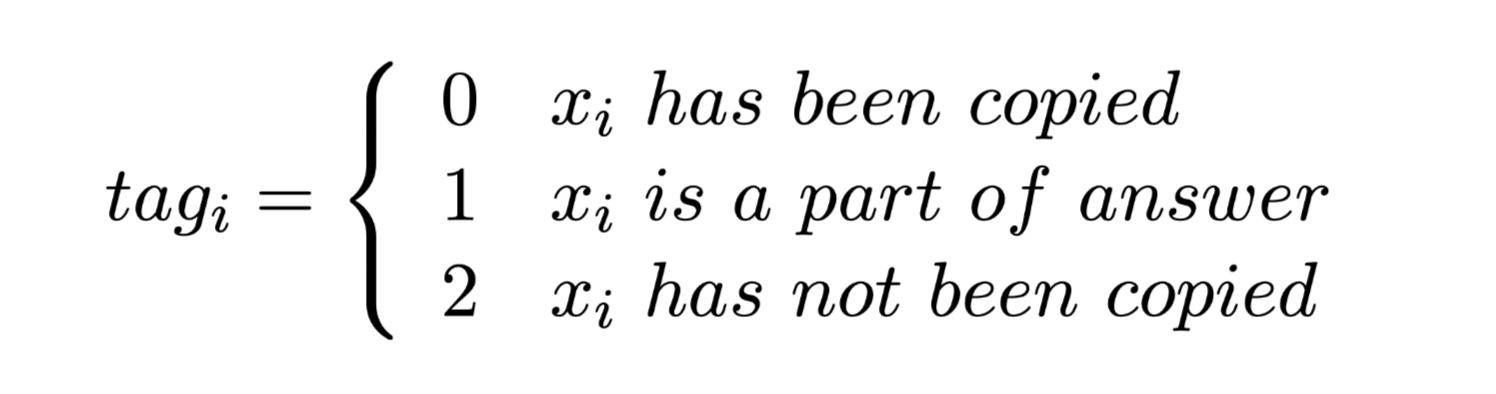
角色标签可以引导模型合并依赖关系,以生成答案相关问题。
在解码的每个时间步 t,节点嵌入会被重新初始化:

其中,$h^n_i$是通过等式(18)计算的passage graph的节点嵌入,$r_i^t$是步骤$t$中节点$i$的角色标签嵌入。
此外,采用bi-GGNN和平均聚合器来聚合节点嵌入。经过n跳计算,得到了最终的节点嵌入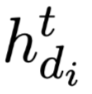 。
。
对于每个解码步骤$m$,LSTM读取前一个单词$w{t-1}$的嵌入、先前的previous attentional context vector $c{t−1}$和之前的隐藏状态$s_{t−1}$,计算其当前隐藏状态。
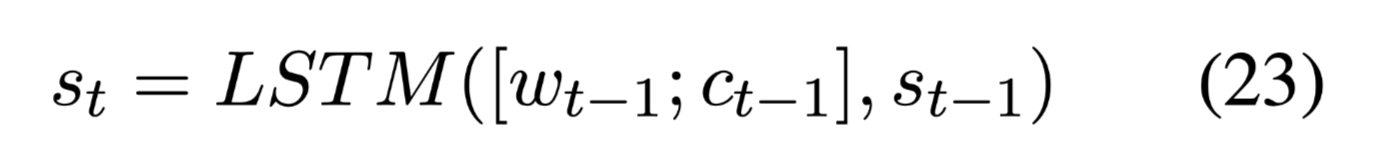
在时间步t,注意力权重和上下文向量计算如下:
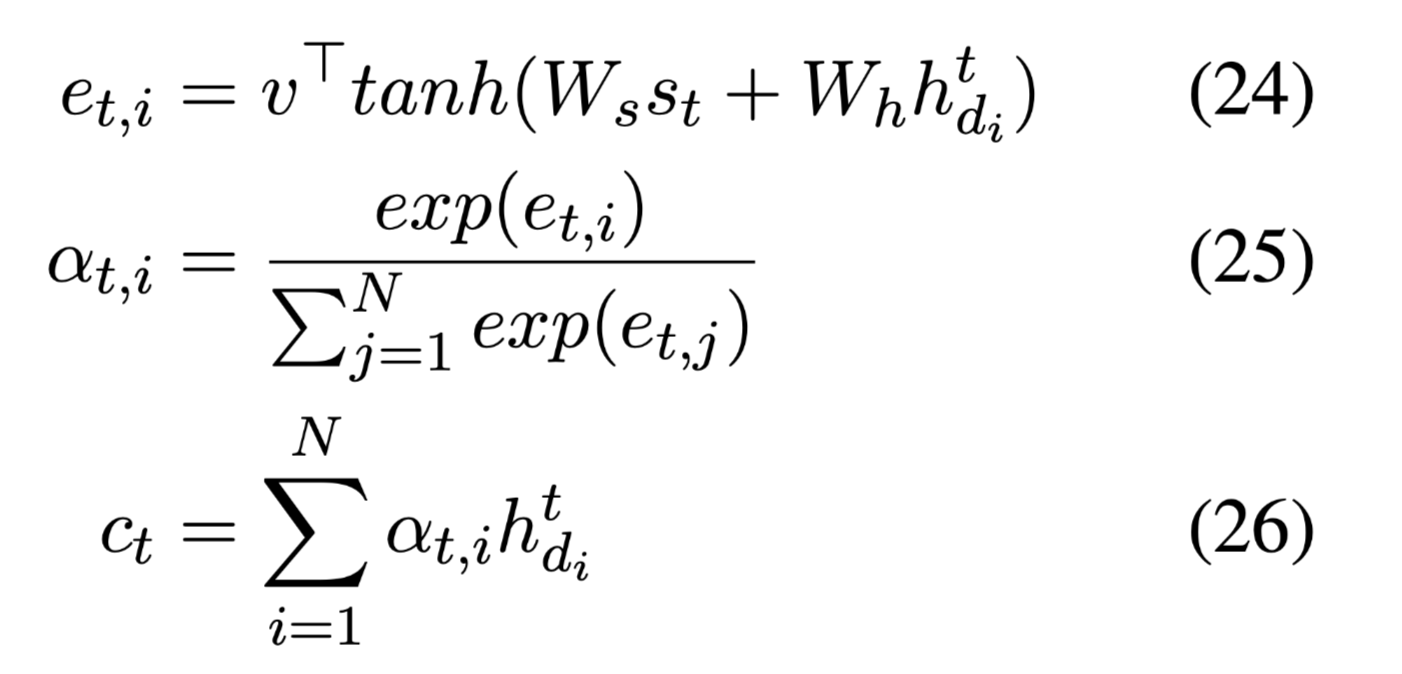
由于注意权重衡量每个输入单词与部分解码状态的相关性,并结合生成的单词信息,将$α_t$视为复制概率:
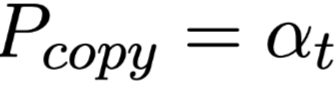
最终的单词预测概率:
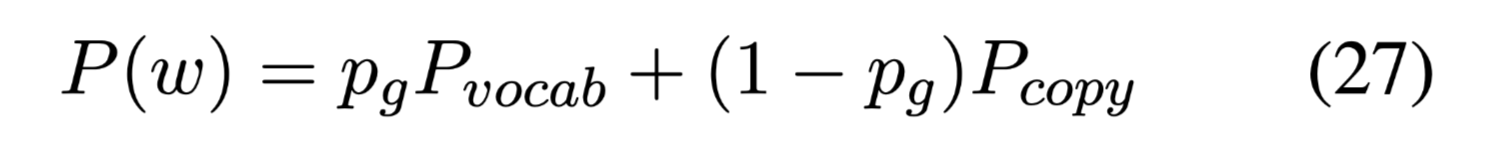
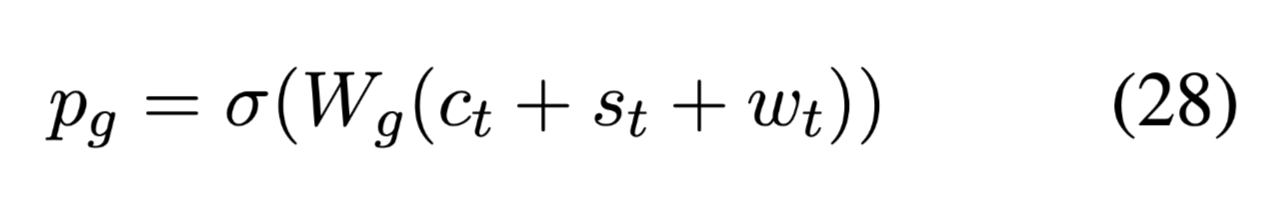
损失函数,negative log likelihood:
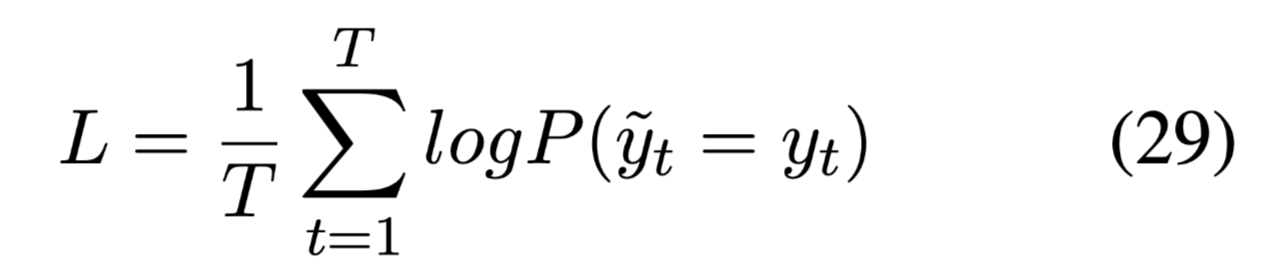
数据集
SQuAD
MS MARCO
包含100000个带有相应答案和段落的查询。所有问题都是从真实的匿名用户查询中抽取的,上下文段落是从真实的web文档中提取的。
本文选取了MARCO数据集的一个子集,其中答案是段落中的子跨度,以构建句子级数据集。其中包含46109、4539和4539个sentence-question-answer triples,分别用于训练、验证和测试。
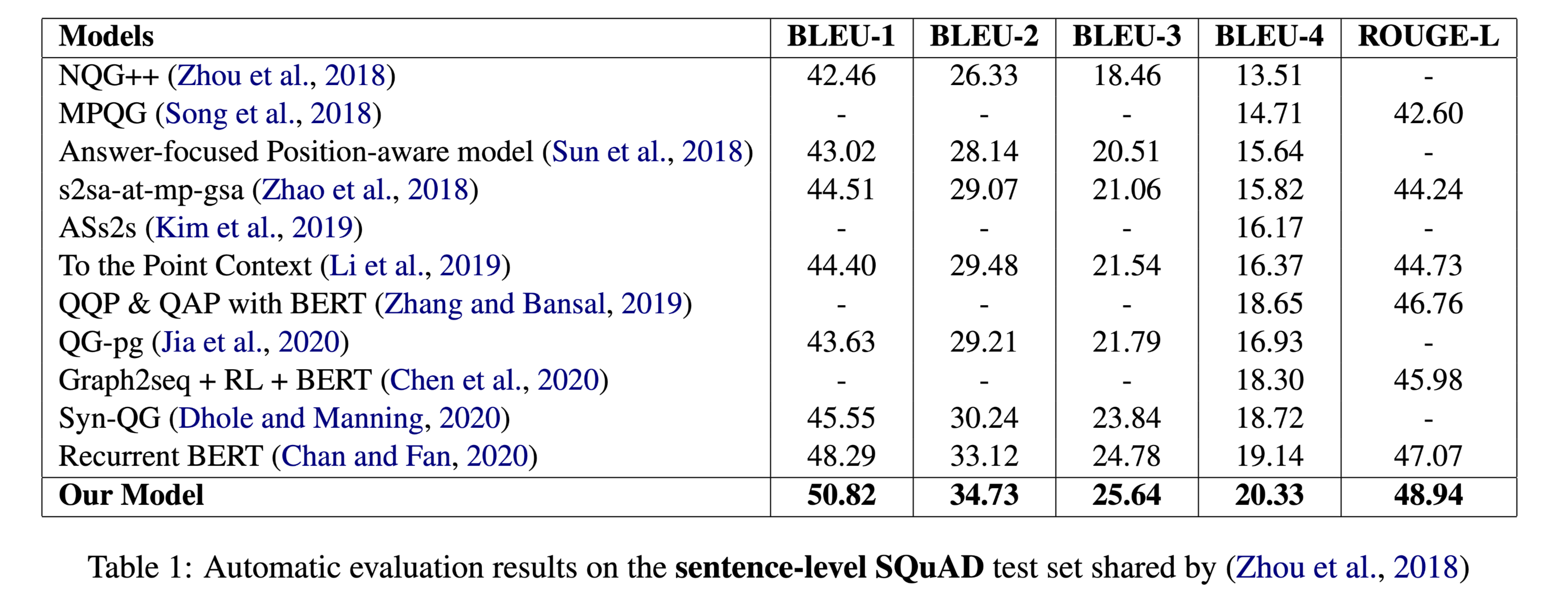
性能水平
结论
本文贡献:
- 设计了一个基于迭代图网络的解码器(IGND)来捕获生成中的结构信息,并在每个解码步骤对复制的词进行建模。
- 我们提出了一个关系图编码器来编码段落中的依赖关系,并建立答案和段落之间的联系。
- 提出的模型专注于句子级QG任务,获得了最优的分数,并且在 standard SQuAD and MARCO benchmarks for QG 上优于现有方法。