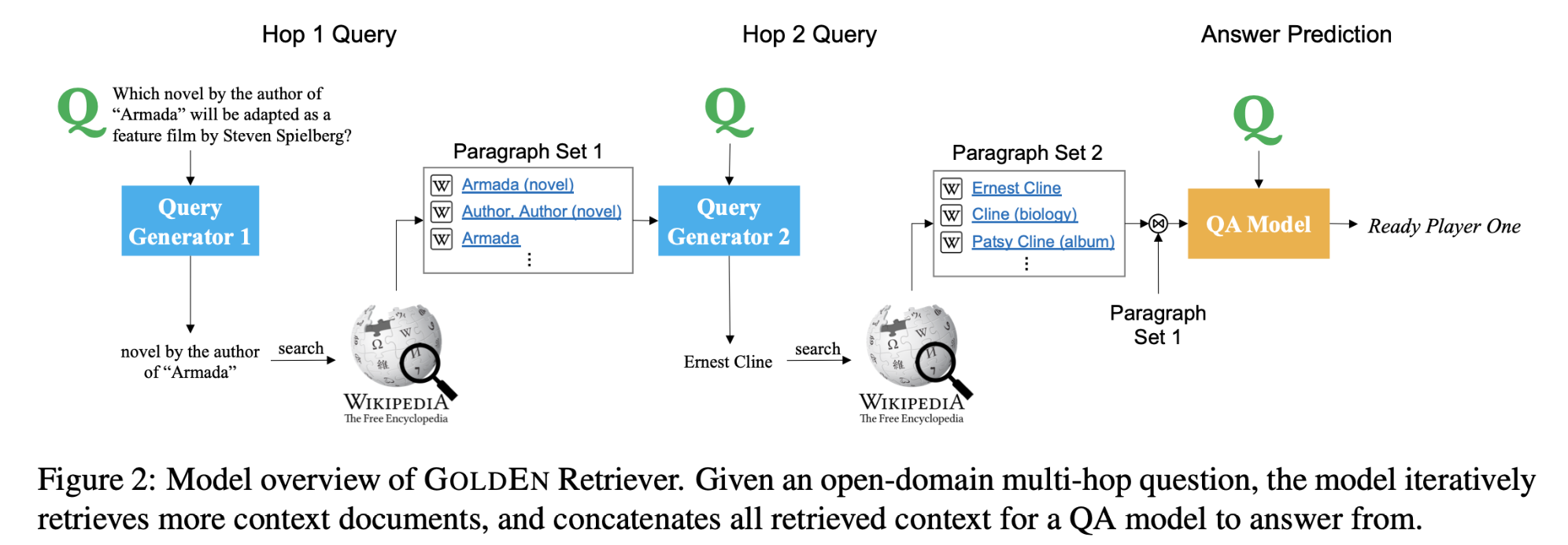
Block-Skim Efficient Question Answering for Transformer
Block-Skim: Efficient Question Answering for Transformer
论文:https://arxiv.org/abs/2112.08560
会议:AAAI 2022
任务
NLP任务中使用的公共Transformer编码器处理所有层中上下文段落中所有输入tokens的隐藏状态。然而,与序列分类等其他任务不同,回答提出的问题不一定需要上下文段落中的所有tokens。基于这个动机,本文提出了Block-Skim,它学习在更高的隐藏层中跳过不必要的上下文,以提高和加速Transformer的性能。Block-Skim的关键思想是确定必须进一步处理的上下文,以及在推理过程中可以在早期安全地丢弃的上下文。关键的是,作者发现这样的信息可以从Transformer模型中的self-attention weights中得到。作者早期在较低层进一步修剪与不必要位置相对应的隐藏状态,显著节省了推理时间。
目标效果示例:

方法(模型)
Layer 4 和 Layer 9的答案相关和不相关tokens权重比较:
箱型图:上面的是答案相关的tokens所占权重,中间线条为中位数。
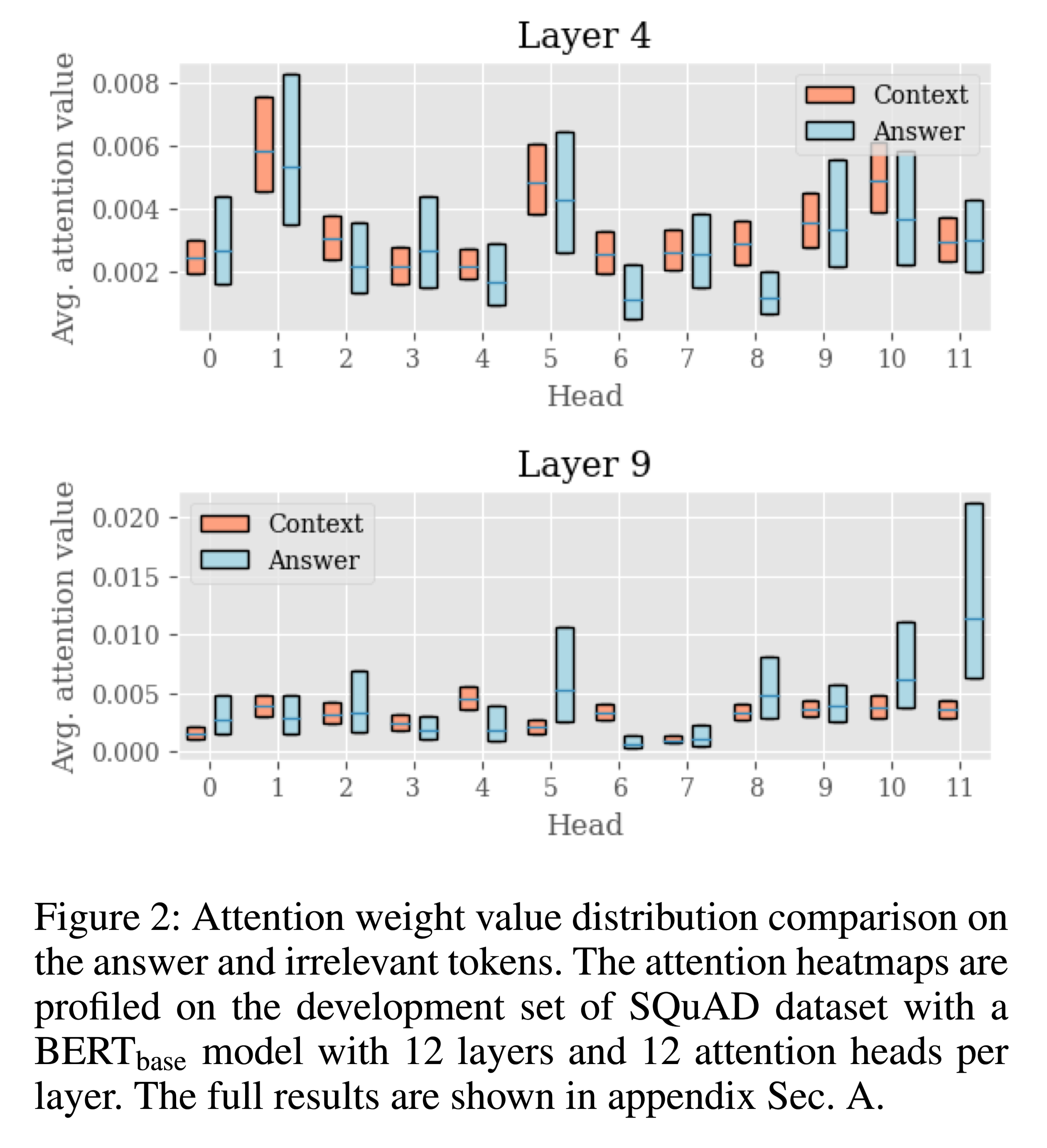
在较后面的层,答案相关的tokens注意力权重显著大于答案不相关tokens的注意力权重。
在早期的层,如第4层,答案相关的tokens和无关的tokens注意力权重强度是无法区分的。
所以在早期阶段,使用注意权重值作为答案相关性标准可能会有问题。
使用CNN预测块与答案的相关性:
目的是为了找到与答案相关的块,并跳过不相关的块。
模型结构:
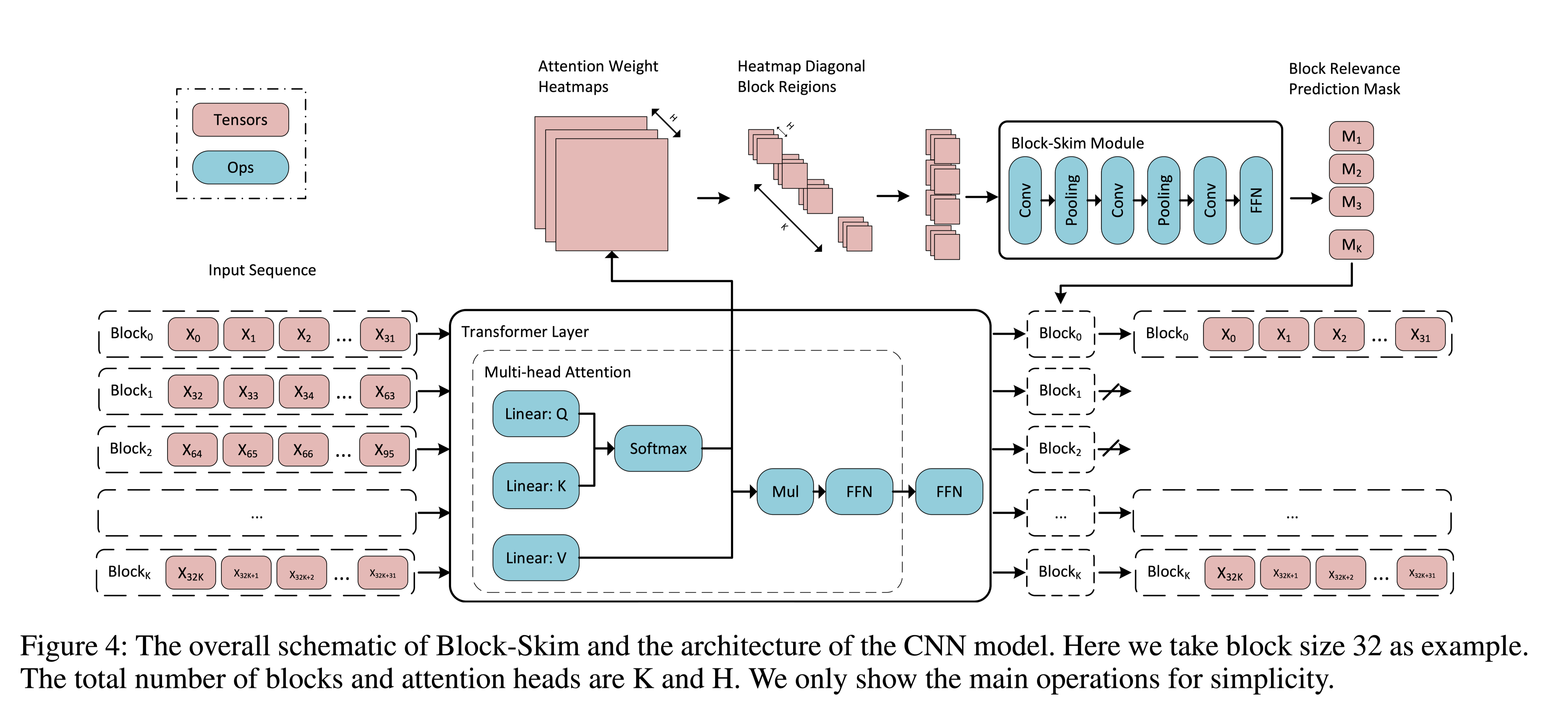
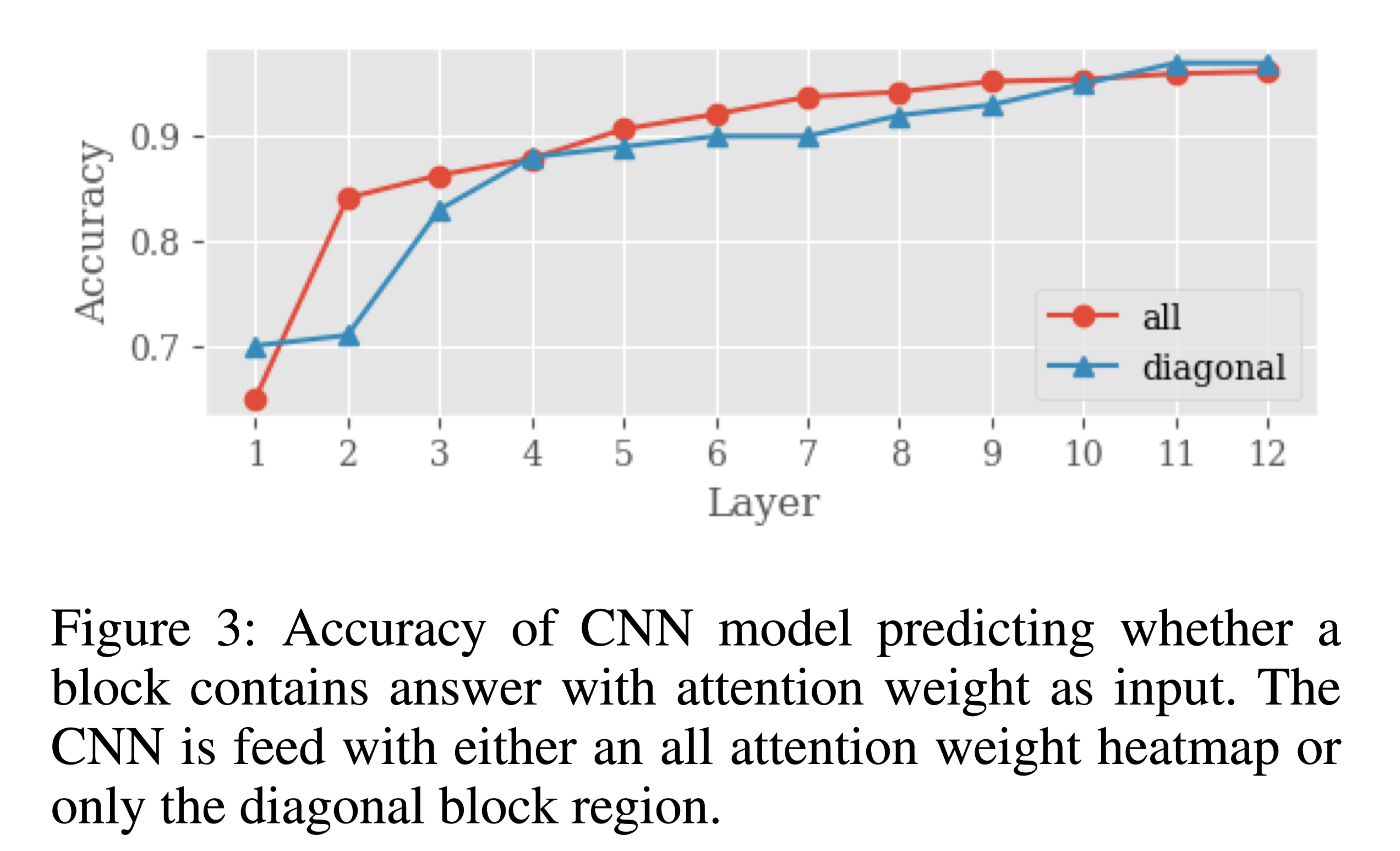
由于attention feature map大小是动态变化的,将完整的 attention feature map 输入到CNN是比较困难的,本文采用一个比较简单的办法,直接将attention feature map的对角阵(diagonal region)作为输入。从图3也可以看出来,和完整的 attention feature map 作为输入相比,性能几乎一致,所以对角线上的注意力权重能够包含足够的信息。这样做之后,输入变得很小,计算效率自然显著提升。
以句子为单位,或通过依存句法树分析语义关系,再去分割块。直接按固定token分割,必然会出现语义不连贯的问题。
Transformer with Block-Skim
遇到的问题:
用正确答案训练块相关性预测器,对于多跳问题可能会出问题,因为解答多跳问题需要答案标签意外的信息,为了解决这个问题,本文提出了一个端到端的多目标联合训练范式(joint training paradigm)。
在推理阶段,Block-Skim模型的预测被增强,以过滤输入序列中不相关信息进行加速。这导致了训练和推理模型之间的不匹配。在训练过程中skimming blocks使联合训练不稳定。
解决办法:
1. Single-Task Multi-Objective Joint Training
在用Block-Skim模块增强的模型中,有两种类型的分类器:
- QA classifier at the last layer
- block-level relevance classifier at each layer
只计算passage中的tokens。

总的损失是两个分类器的和:
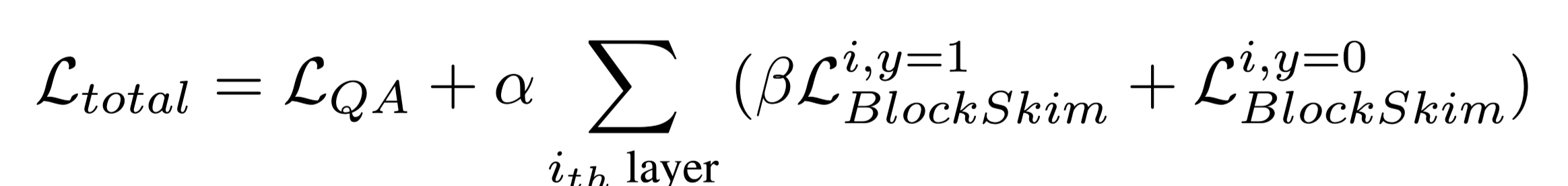
$\alpha $:是和谐系数,超参数可调。
β:平衡系数β来调整正负相关区块的损失,因为通常没有答案标记的区块(即负区块)比包含答案标记的区块多得多。
Block-Skim is a convenient plugin module:
- 首先,它不影响骨干模型的计算,因为它只是用额外的参数对骨干模型的注意值分布进行规范化。换句话说,用BlockSkim训练的模型可以在去掉它后使用。
- 其次,引入的Block-Skim目标既不需要额外的训练信号,也不会降低QA的准确性。
该联合训练方法也可以解决多跳QA任务中的挑战。
2. Inference with Block-Skim
在联合训练过程中加入了块级相关性分类损失,但实际上并没有丢弃任何块,因为它可能会skip答案块而使QA任务训练变得不稳定。所以只在推理过程中用Block-Skim模块来减少不相关信息,以节省计算量并避免对底层Transformer的严重改变。
在推理计算过程中,通过块的粒度来分割输入序列,根据skimming module的结果选择跳过的块。
数据集
- SQuAD 1.1
性能水平
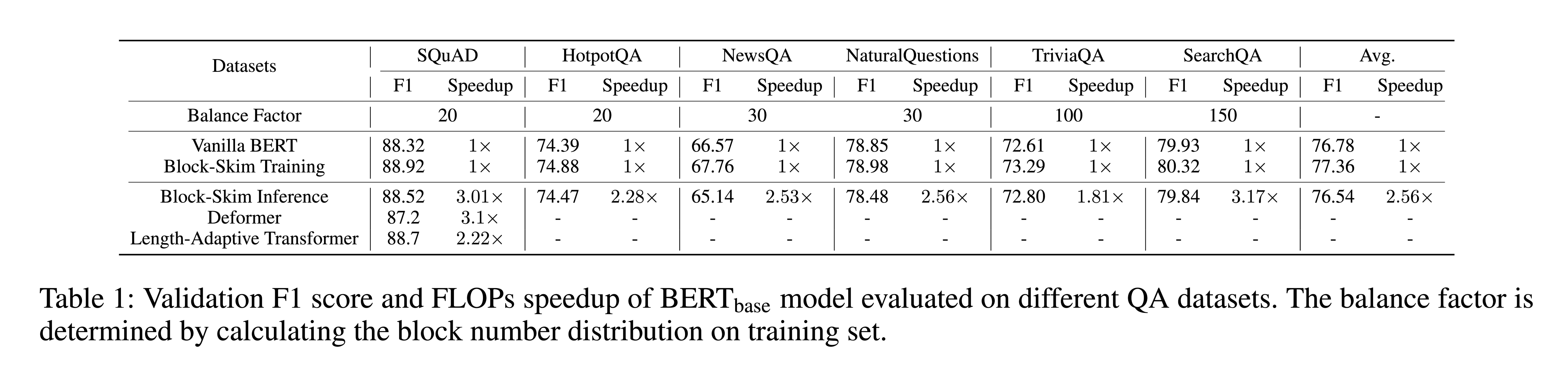
结论
本文贡献:
- 第一次证明了注意力图对于确定答案在输入中的位置是有效的。
- 提出了Block-Skim,它利用注意机制改进和加速QA任务中的Transformer模型。关键是在处理过程中从注意机制中提取信息,并智能地预测要skim哪些块。
- 在几种基于Transformer的模型架构和QA数据集上评估了Block-Skim,并证明了其效率和通用性。