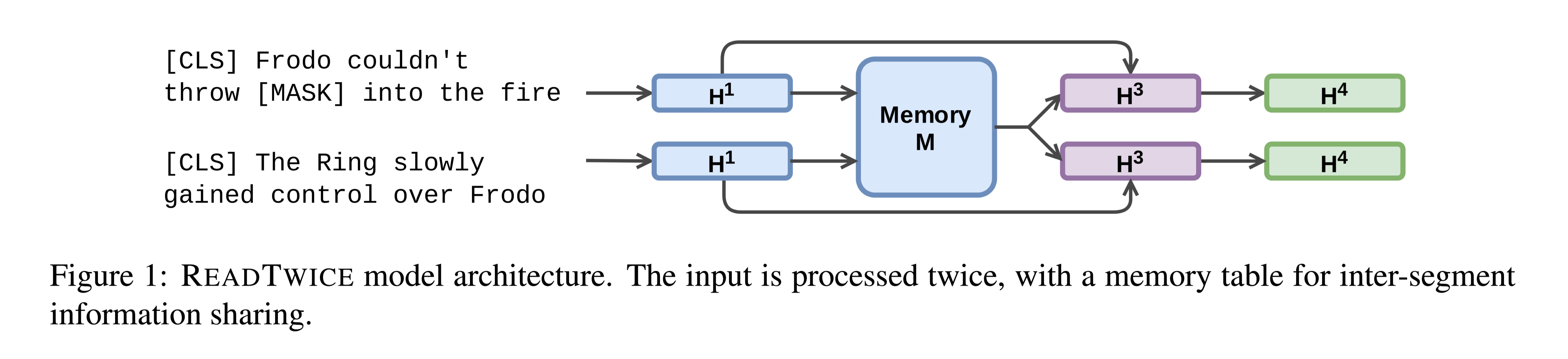
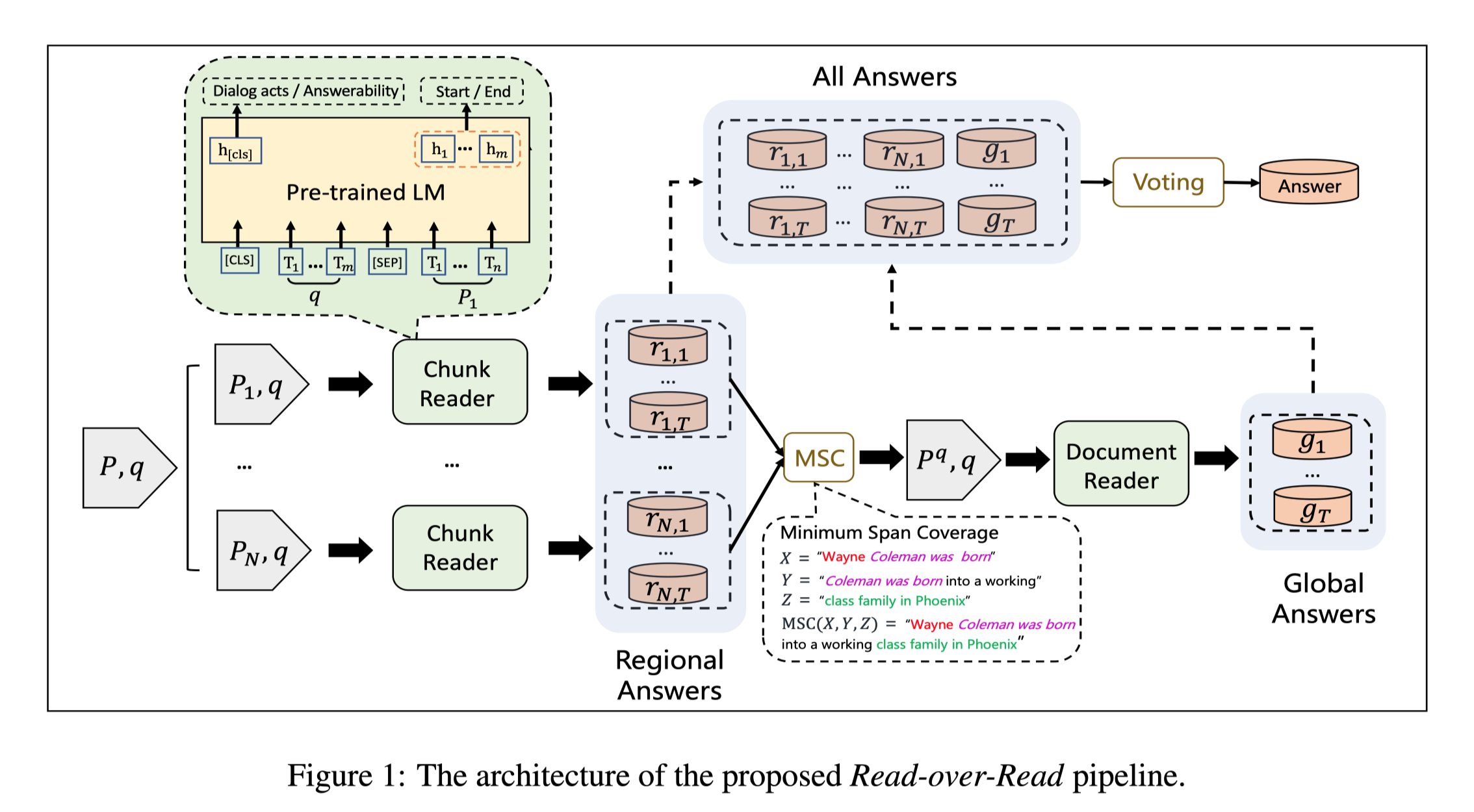
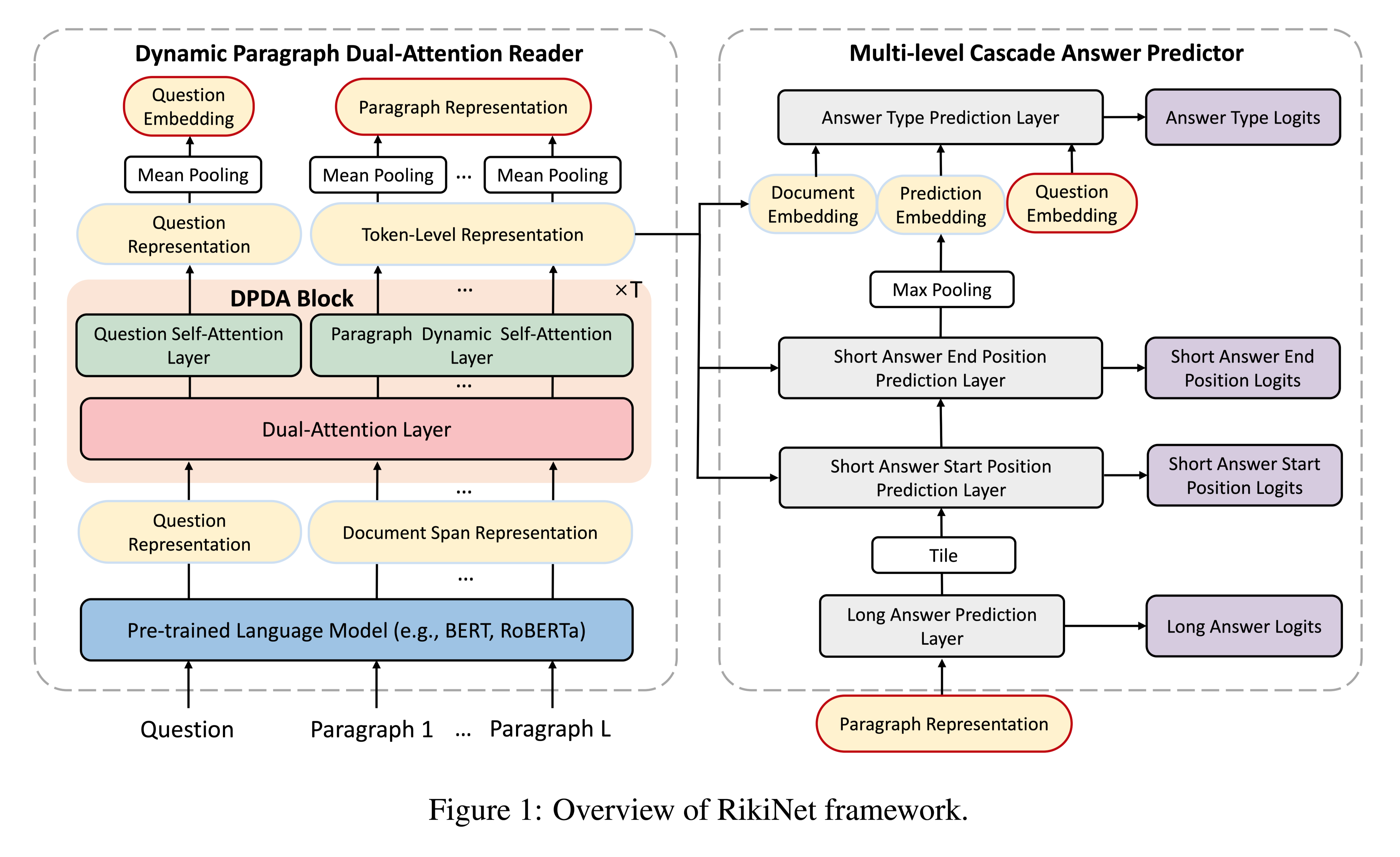
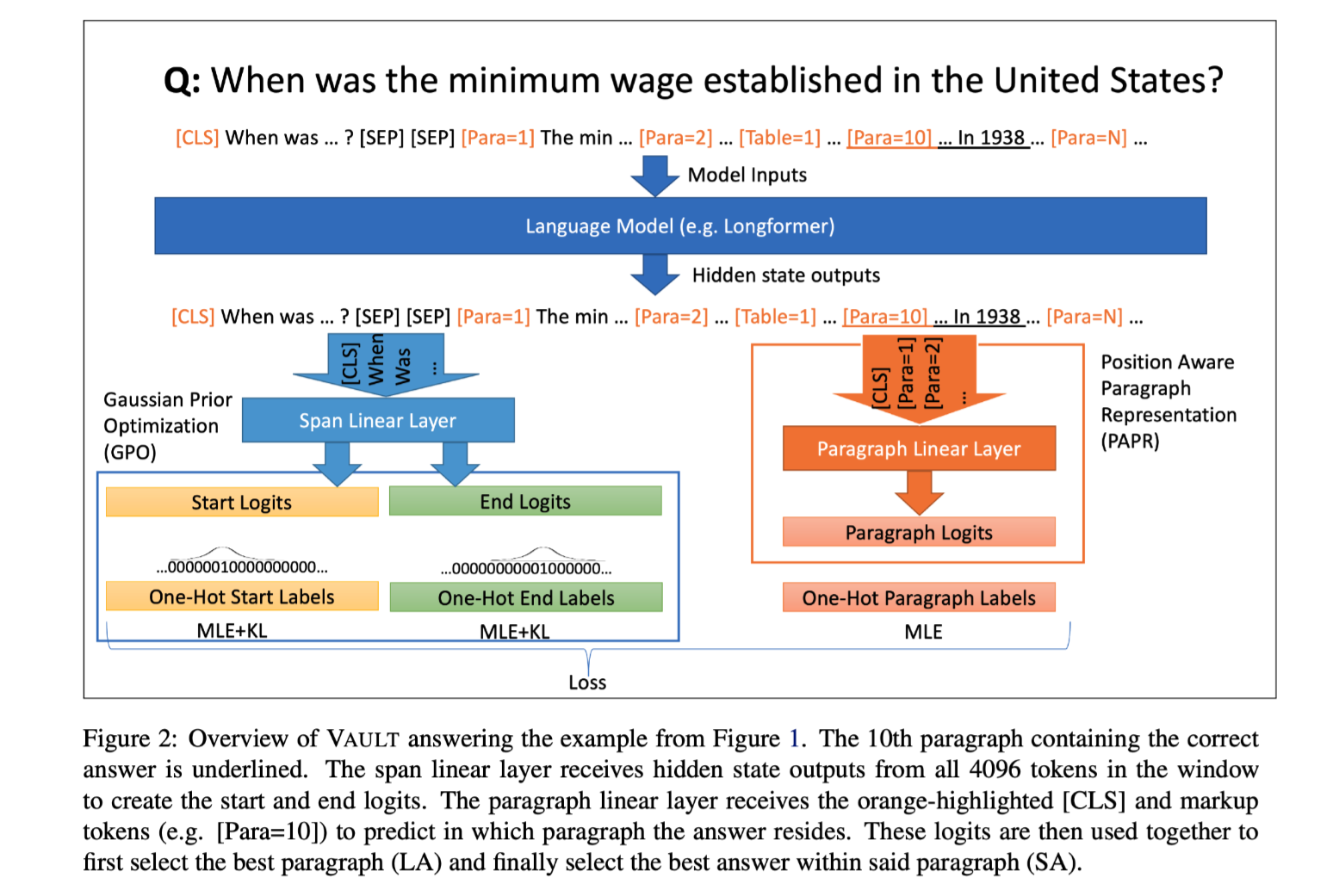
Optimal Partial Transport Based Sentence Selection for Long-form Document Matching
Optimal Partial Transport Based Sentence Selection for Long-form Document Matching
论文:Optimal Partial Transport Based Sentence Selection for Long-form Document Matching
代码:https://github.com/ruc-wjyu/OPT-Match (暂未开源)
会议:COLING 2022
飞书:https://zlc6vppbrn.feishu.cn/docx/HIyLd9808oq3yvxzz3BcTJEUn1g
任务
传统的长文档匹配方法首先在跨文档句子对之间进行对齐,然后聚合所有句子级的匹配信号。但是,这种方法可能会出现问题,尽管两个文档整体上匹配良好,但大多数句子仍然可能不同,因为文档之间的对齐是部分的。那些不同的句子会导致虚假的句子级匹配信号,可能会掩盖真实的句子,从而增加学习匹配功能的难度。因此,准确选择文档匹配的关键句子是以一个关键问题。
本文提出了一种新颖的匹配方法OPT-Match,该组件选择在匹配中起主要作用的句子。利用OPT的部分传输特性,选择的关键句子不仅可以有效地提高匹配精度,还可以解释匹配结果的合理性。
文档1重点介绍了药用和芳香植物行业的未来机会。文档2研究了spicata的外部储存。大多数句子都不相似,但文件1引用了文件2,因为它们都以药用和芳香植物为例。传统的,基于句子的匹配策略无法识别相关关系。
动机
现有匹配策略
- 基于句子的短文本匹配
- 映射到语义空间后进行层次匹配(词,句子,文章)
但是,这些方法忽略了长文档通常包含多个段落和句子,这些段落和句子包含复杂的语义。对长文档匹配来说,文档对之间的对齐是局部的,关键句子之间的一些匹配信号可以确定文档级别的匹配结果。
方法(模型)
模型结构:
方法特性
- OPT-Match通过限制要传输的块来建模文档对齐的部分性质
- OPT-Match允许源域和目标域不一定具有相同的块,这与两个文档的长度可能相差很大的现象非常吻合。但是,基于OT的方法无法考虑这一点
- OPT-Match是一种与模型无关的方法,可以轻松地将其插入各种文档匹配模型中
Proposed OPT-Match Method
Problem Statement
分别代表源文档,目标文档,标签(表示二者语义关系)
$X_i,Y_i$由连续的句子组成
学习目标:
将输入文档中的所有句子作为输入,输出它们之间关系的预测
主要思想:
从源文档中选择出关键句进行匹配,而不是所有句子。
The Principle of Our Method
sentence selection method:
定义源文档和目标文档概率分布的最小传输距离为:
$T$:表示 $\mu\ v$ 的联合分布
$C$:句子级的损失矩阵
$c(s^X_ m,s^Y _n )$: 表示两个句子之间的差异
Optimal Transport缺陷
- 需要µ,ν分布大小相同,因此很难适应不同句子数量的文档匹配,并且通常情况下,文档中的句子数量可能会有很大差异,并且冗长的文档通常包含更多的语义。
- OT要求源点必须精确映射到目标。但是,在文档匹配中,只有来自源文档的一些关键句子与来自目标文档的关键句子对齐,因此应该只有一部分来自源的块被传输到目标。
- OT聚合所有句子级对齐信号,这些信号会在匹配的过程中引入噪声。
OPT-based Sentence-level Alignment
目标:解决OT的三个缺陷
缺陷1
OT中要求 $\mu v$具有相同的维度,因此首先要解决维度限制,设 $µ = 1_M\ ν = 1_N$其中 $1_M$表示维度为M的全1向量
缺陷2
OT要求源点必须精确映射到目标。因此设置了需要传输的比例 $ϵ$,以控制文档对齐的程度。直观地说,使用较低的$ϵ$,OPT-Match 会更多地关注强对齐的句子对,同时过滤掉更多的虚假对齐信号。cost matrix C
为了衡量两个交叉文档句子之间的差异,定义了代价矩阵$C$。
目标:期望将以更低的成本运输更多相似的句子对,因此也具有更强的对齐关系。
解决方法:
最优化转移策略中引入entropic regularizer E(T),实现两个分布的快速近似
λ:权重系数
使用Bregman-Dykstra算法迭代计算 $T^*$
初始化
$T^$表示在约束条件下,转移的概率,在句子对齐方案中 $T^$可以视为源句和目标句之间的对齐程度,该方案下仅突出显示强对齐的句子。
Sentence Selection
- 缺陷3
OT聚合所有句子级对齐信号,这些信号会在匹配的过程中引入噪声,因此设计两个算法选择与 $T^*$相关的 $S^X, S^Y$做匹配。
Hard Selection
encoding前
从源文档和目标文档中分别选择了最佳传输策略中对齐度最高的k个句子,并丢弃其余句子,其中k是一个超参数,代表关键句子的理想数量。选择源文档中与 $T^*1_N$相关的top-k句子,放置到 $S^X$。类似地,对于目标文档,选择 $1^⊤_MT^*$top-k句子放置到 $S^Y$。
Soft Selection
encoding后
将 $T^*$作为采样概率,使用Gumbel softmax对关键句子采样,可微
$U(0,1)$:表示0,1之间的均匀分布
$prob_i$:句子选中的概率
得到每个句子的权重系数,用于选择关键句
Loss
OPT-Match只作为句子选择模块,训练目标与原模型相同, 一般损失函数为交叉熵:
M:表示匹配组件
$z_i$:真实标签
数据集
Long-Form文档匹配数据集:
Citation recommendations
任务:预测一篇论文是否引用另一篇论文。
相关数据集:Plagiarism detection
任务:检测源文档中的span是否抄袭目标文档中的span(查重?)
相关数据集:
PAN
性能水平
- 硬匹配效果普遍偏好,原因在于,soft-selection本质上计算每个句子的权重系数,不能完全过滤掉文档中的噪声。
- BERT及其变体以token为单位建模,因此只选择了硬匹配的方式
- BERT及其变体 (例如Transformer-XL和Longformer) 在PAN上的性能要差得多,原因在于,PAN文档较长(> 1500 words),直接截断会带入大量噪音,但OPT-Match模块不受文档长度的影响。并且OPT-Match通过选择关键句子进行匹配可以成功滤除文档中的噪声。
- 文档越长性能越好
使用acc和F1作为评估指标,因为所有数据集都有用于文档匹配的二分类标签。
使用MRR作为句子选择的评估指标,因为句子选择被视为排名任务。
结论
主要贡献:
- 强调了长格式文档匹配中关键句子选择的重要性
- 提出了一个广泛适用的组件,称为OPT-Match,该组件通过进行部分文档对齐来选择用于文档匹配的关键句子
- 实验结果表明,在四个公开数据集上,OPT-Match改进了现有的文档匹配模型,并且OPT-Match选择的句子与人工一致