RoR Read-over-Read for Long Document Machine Reading Comprehension
RoR: Read-over-Read for Long Document Machine Reading Comprehension
论文:https://arxiv.org/abs/2109.04780
代码:https://github.com/jd-ai-research-nlp/ror
会议:EMNLP2021
任务
基于Transformer的预训练语言模型,例如BERT,由于编码长度的限制(如512个WordPiece tokens),一个长文档通常被分割成多个独立阅读的块。这导致阅读领域被限制在个别的块上,没有信息协作的长文档机器阅读理解。为了解决这个问题,本文提出了RoR,一种read-over-read的方法,它将阅读领域从块扩展到文档。
为了处理超过长度限制的长文件,一个常用的方法是将文件分成多个独立的块,然后分别从每个块中预测答案。这些答案中得分最高的跨度被选为最终答案。这种方法很直接,但会导致两个问题:
- 阅读领域被限制在区域块中,而不是完整的文件。
- 答案的分数不具有可比性,因为它们没有在块中进行全局标准化。
方法(模型)
具体来说,RoR包括一个块阅读器和一个文档阅读器(两者都基于预训练模型)。分块阅读器首先预测每个分块中的区域答案。然后通过最小跨度覆盖算法将这些答案压缩成一个新的文件,保证其序列长度短于限制(即512)。通过这种方式,所有的区域性答案都可以在一个文件中被规范化,保证只需编码一次。这个文件作为原始文件的高度压缩版本,由文档阅读器进一步读取,以预测一组全局答案。由于块阅读器和全局阅读器从不同的角度提供了高置信度的答案,本文充分地利用这两者来预测最终的答案。具体来说,在预测了区域和全局答案的跨度后,本文提出了一个投票策略,并利用它来重新排序。这个投票策略是基于这样的想法:一个候选的区域或全局答案跨度与其他答案跨度重叠得更多,就更可能是正确的。
模型结构:
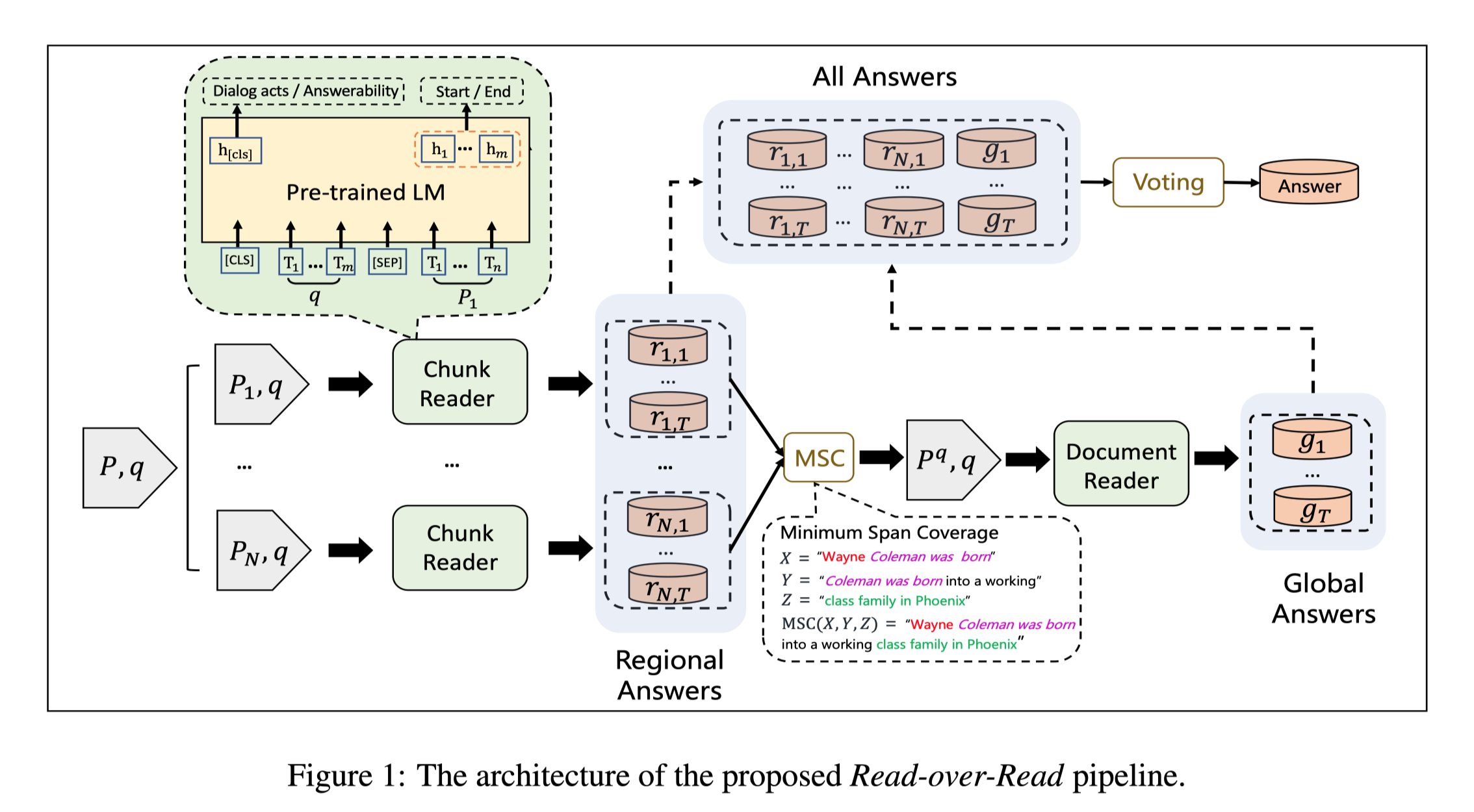
Framework Overview
文本对:$(P, q)$
分块:${(P_1, q), …, (P_N, q)}$
regional answers,块阅读器预测的答案: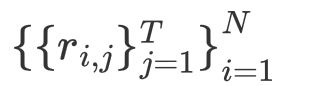
使用minimum span coverage (MSC)算法将regional answers压缩,得到$P^q$,TriviaQA数据集中的大多数答案都是无法反映足够上下文信息的命名实体。因此,对于TriviaQA数据集,本文使用区域答案所在的句子压缩到$P^q$。
document reader使用$P^q$,预测得到全局答案:${gi}^T{i=1}$
T:每个块预测答案数的上限。
Chunk Reader
Text-Encoder
输入:$X = [[CLS]; q; [SEP]; P]$
Answer Prediction
- 预测答案的span只需要token level feature。
计算span开始和结束位置的概率:
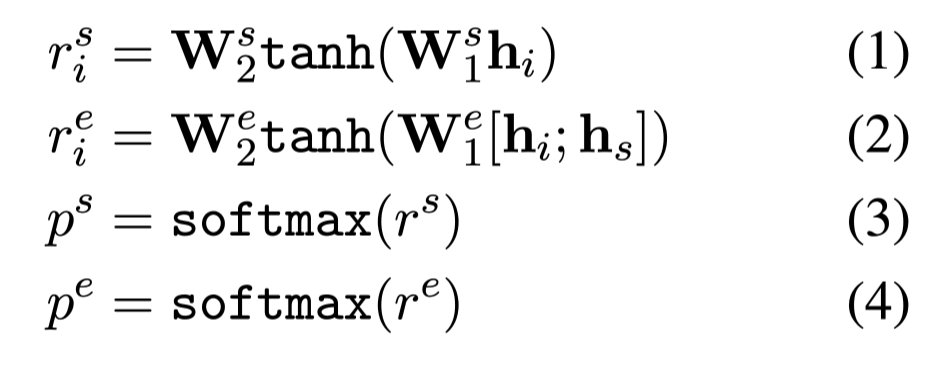
$h_s$:span开始位置的token表示
从公式(2)可以看到,开始和结束位置的预测过程并不独立,结束位置的概率分布计算取决于起始位置。
使用交叉熵损失函数:
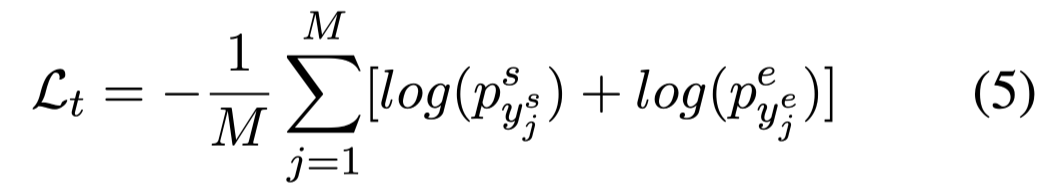
$y^s_j\ y^e_j$:表示真实答案的范围。
- Sentence level answer
可以根据$[CLS]$预测对话任务的下一步动作,由于当前任务不涉及对话,详细实现可以再去看原文对应部分。
Answer Calibration
由于区域答案中得分最高的跨度有时不是F1得分最高的跨度,因此通过answer calibration mechanism提高区域答案准确度。
首先计算候选答案的跨度表示,这是一个加权自对准向量:
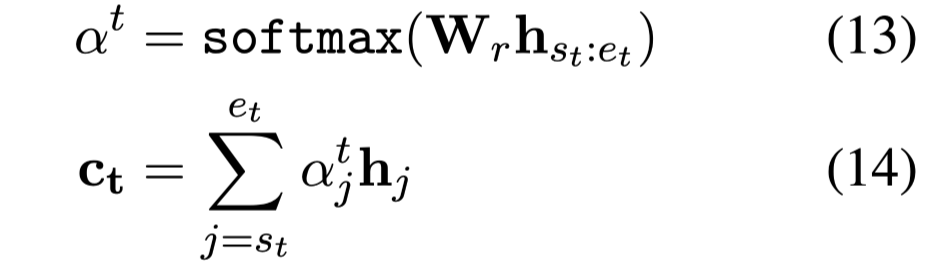
$[s_t:e_t]$表示候选答案的范围。
$C_t$是候选答案的跨度表示。
候选答案集合:$c = [c_1, …, c_T]$
通过multi-SelfAtt捕捉候选答案之间的相似性和差异:
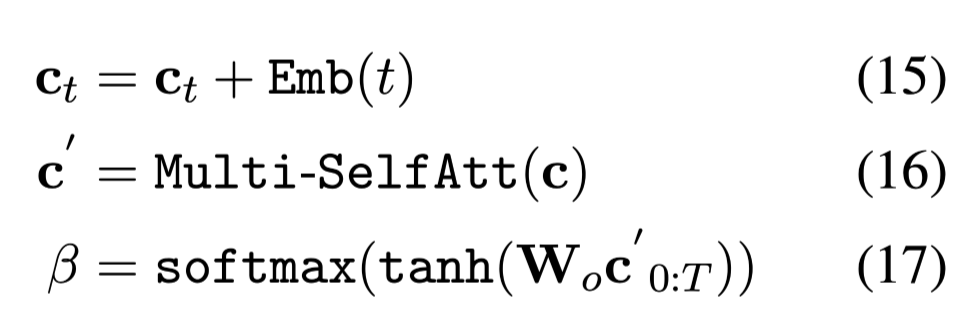
t是预测候选答案的位置编码,t值越小,原始预测分数越高,可帮助模型识别候选答案的重要性。
使用交叉熵损失函数:
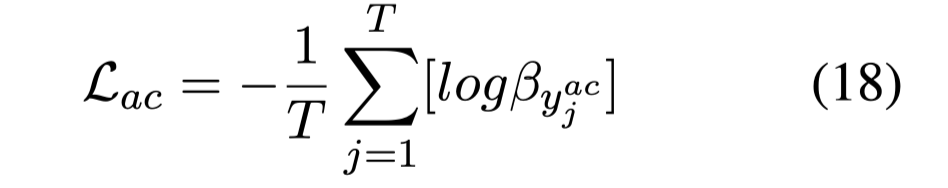
$y_j^{ac}$:人工指定为,在候选答案中F1分属最高的span。
如果F1的最高分是0,而相应的问题是可以回答的,就随机地用gold span替换一个候选答案。
Document Reader
长文本通过Minimum Span Coverage (MSC) 算法压缩到512个token以内,得到$P^q$,MSC保证$P^q$覆盖所有regional span,并充分压缩,确保只需要一次编码。
encoder输入:$X = [[CLS]; q; [SEP]; P^q]$
因为输入的文本经过了聚合,所以答案标签也要有所变化,定义为 $P^q$ and the original gold span的最长公共子序列。
Voting Strategy
假设:块读器和文档阅读器共同预测到的跨度更可能是正确的。
投票策略:
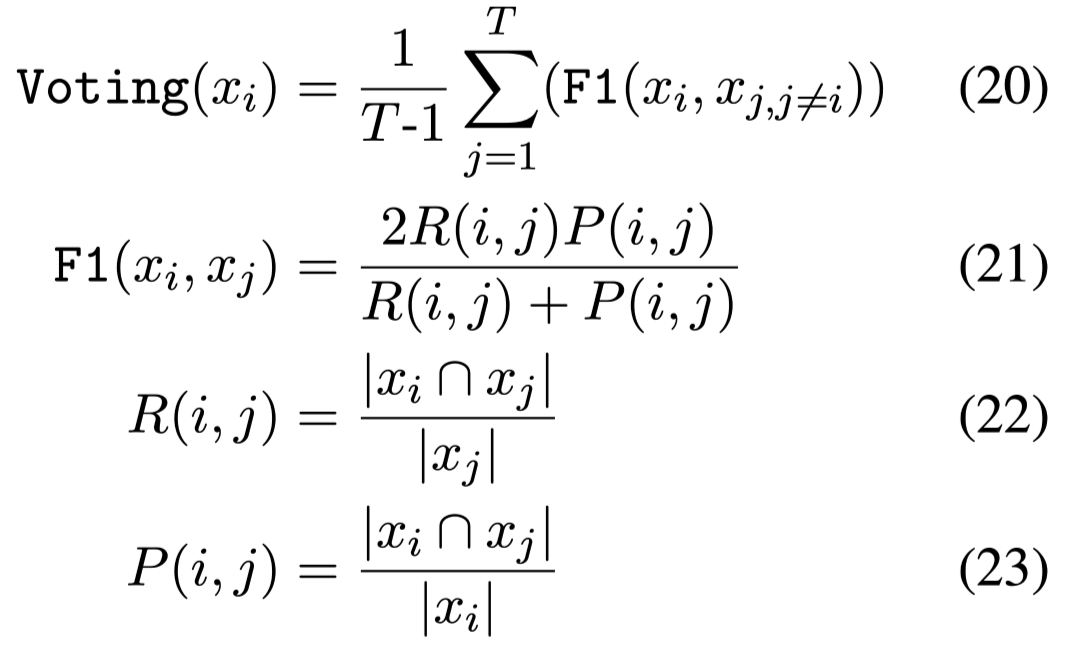
$|x_i∩ x_j|$:表示两个答案span的共有单词。
F1值可以理解为两个答案的相似度。
根据得分重排序:
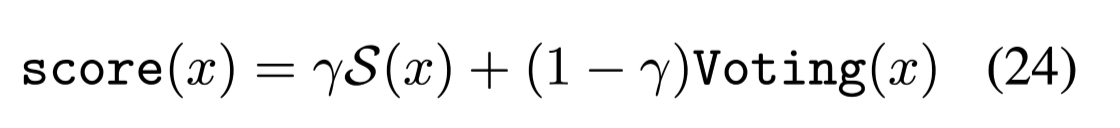
$S(X)$:表示原始的预测分数。
$\gamma$:;两个得分的权重。
Training and Inference
联合学习:
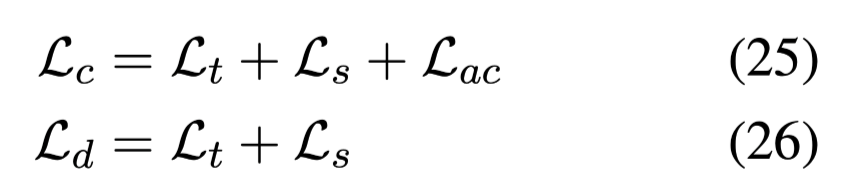
$L_c$:块阅读器的损失,其中$L_s$是用来做对话任务的。
$L_d$:文档阅读器的损失。
训练流程:

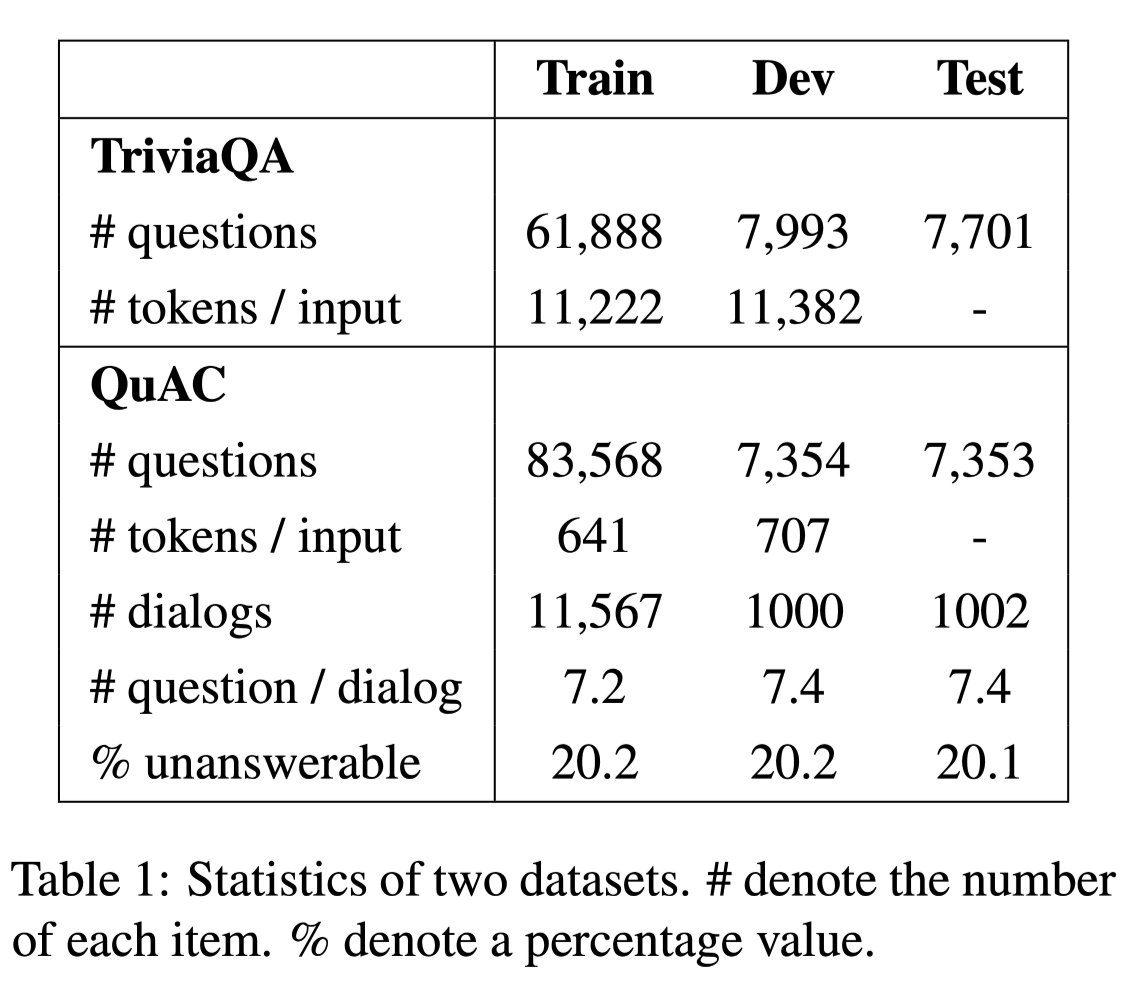
数据集
两个长文本数据集
- QuAC (Question Answering in Context)
QuAC是一个大型数据集,用于模拟寻求信息的对话。它的问题往往更加开放、无法回答,或者只有在对话环境中才有意义。
- TriviaQA
TriviaQA是一个大规模的开放域MRC数据集,需要跨句推理才能找到答案。它包含来自维基百科和Web域的数据,在本文的工作中使用了维基百科子集。
数据集分析:
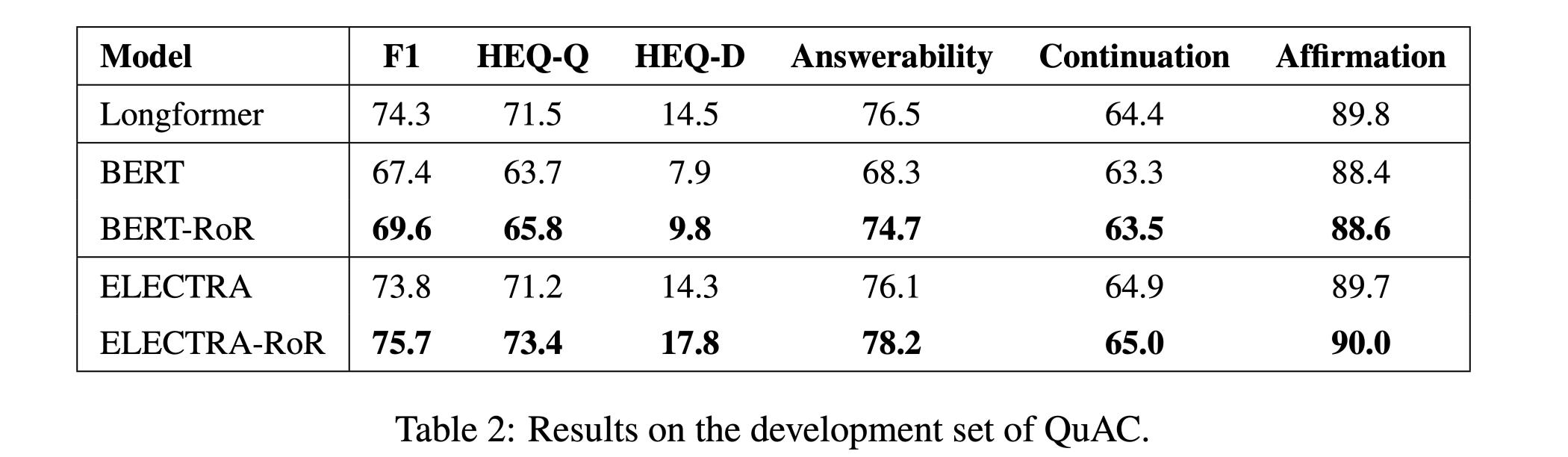
性能水平
在QuAC数据集上的性能:
结论
本文贡献:
提出了一个包含增强型块阅读器和文档阅读器的read-over-read pipeline,它能够解决现有模型中长文档阅读限制的问题。
提出了一种投票策略,对来自区域块和浓缩文档的答案进行排序,克服了从不同来源汇总答案的主要缺点(不能全局标准化的缺点)。
- 对长文档基准进行了广泛的实验以验证本文模型的有效性。特别是在QuAC数据集上,本文的模型在排行榜的所有评估指标上都取得了最先进的结果。