

使用TensorFlow实现GRU
使用TensorFlow实现GRU使用Cell实现123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125# 以Cell方式实现GRU# %%import osimport numpy as npimport tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layers, losses, optimizers, Sequential# 指定GPUos.environ["CUDA_VISIBLE_DEVICES& ...

智能小车开发文档
MQTT主题:小程序——-硬件:jm_y2m
硬件——-小程序:jm_m2y
引脚uno r3 引脚定义 直流电机驱动板:5 6 10 11 蜂鸣器 5v:8 超声波传感器 5v:A0 A1 LED 5v:7 光线传感器 5v:A3 人体红外传感器 3.3v:A2 软串口:3, 4
wifi d1 引脚定义 DHT11 5v :D7 触摸按键 3.3v :D8 OLED 5v :D15—SCL D14—SDA 软串口:RX=D8,TX=D9
指令esp8266——->uno r3串口方向:
前:w
后:s
左:a
右:d
刹车: q
蜂鸣器:
设置(1声):1
消息(3声):3
设置小夜灯模型:
小夜灯开:n
小夜灯关:l
设置避障模式:
开启避障:o
关闭避障:p
初始化完成提示:
消息(3声):3
车速设置:
1 2 3档
z x c
小程序———->esp8266消息
小程序发送
1234567{ "source": "app", "type": ...
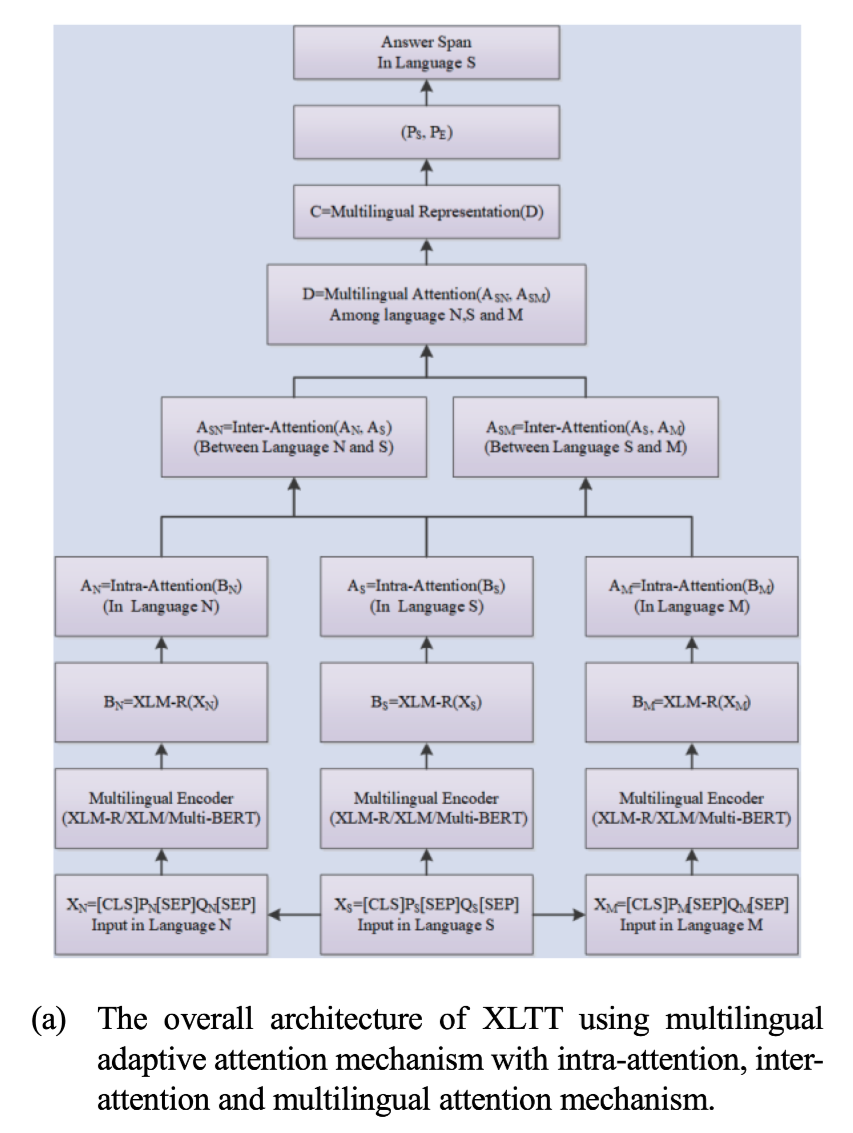
Improving Low-resource Reading Comprehension via Cross-lingual Transposition Rethinking
Improving Low-resource Reading Comprehension via Cross-lingual Transposition Rethinking
论文:https://arxiv.org/abs/2107.05002
任务解决抽取式阅读理解中低资源语言训练数据不足的问题。 通过在多语言环境中对现有的高质量提取式阅读理解数据集进行建模,提出了一个跨语言转置再思考(XLTT)模型(Cross-Lingual Transposition ReThinking)。
方法(模型)提出了多语言适应性注意(multilingual adaptive attention MAA),将intra-attention,inter-attention结合起来,从每一对语言家族中学习更普遍的可归纳的语义和词法知识。为了充分利用现有的数据集,本文采用了一个新的训练框架,通过计算每个现有数据集和目标数据集之间的任务级相似度来训练模型。
模型结构
首先,对于现有的抽取式阅读理解数据集,首先利用GNMT构建了多个语系的多语言平行语料,如(英语、日语、韩语……)。
其次,利用多语言自 ...
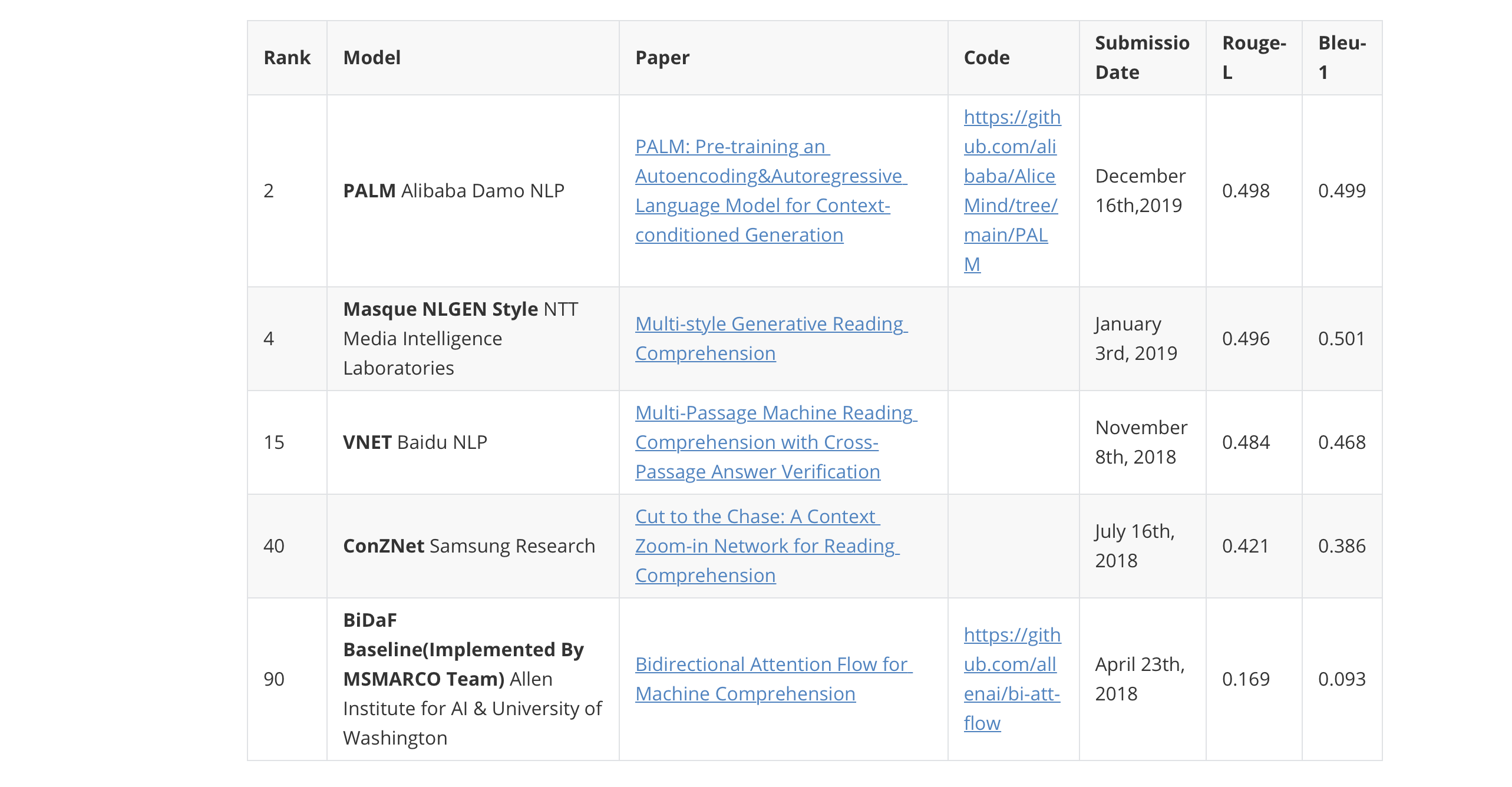
MS MARCO NLG任务调研
MS MARCO NLG任务调研
NLG——自然语言生成
MS MARCO:https://microsoft.github.io/msmarco/
Natural Language Generation Task:RETIRED(03/01/2018-10/30/2020)
参考论文
Rank
Model
Paper
Code
Submissio Date
Rouge-L
Bleu-1
2
PALM Alibaba Damo NLP
PALM: Pre-training an Autoencoding&Autoregressive Language Model for Context-conditioned Generation
https://github.com/alibaba/AliceMind/tree/main/PALM
December 16th,2019
0.498
0.499
4
Masque NLGEN Style NTT Media Intelligence Laboratories
Multi-style Generative Rea ...

简版-翻译、摘要、会话、文本生成任务顶会论文
简版-翻译、摘要、会话、文本生成任务顶会论文机器翻译ACL
序号
会议/期刊
论文
主要技术
代码
论文下载地址
1
ACL2019
Latent Variable Model for Multi-modal Translation
https://github.com/iacercalixto/variational_mmt
https://arxiv.org/pdf/1811.00357
2
ACL2021
Rewriter-Evaluator Architecture for Neural Machine Translation
https://arxiv.org/pdf/2012.05414
3
ACL2021
Consistency Regularization for Cross-Lingual Fine-Tuning
https://github.com/bozheng-hit/xTune
https://arxiv.org/pdf/2106.08226
4
ACL2021
Improving Pretrained Cross-Lingu ...

完整版-翻译、摘要、会话、文本生成任务顶会论文
完整版-翻译、摘要、会话、文本生成任务顶会论文机器翻译ACL
序号
会议/期刊
论文
主要技术
代码
论文下载地址
摘要
摘要翻译
作者
1
ACL2019
Latent Variable Model for Multi-modal Translation
https://github.com/iacercalixto/variational_mmt
https://arxiv.org/pdf/1811.00357
In this work, we propose to model the interaction between visual and textual features for multi-modal neural machine translation (MMT) through a latent variable model. This latent variable can be seen as a multi-modal stochastic embedding of an image and its description in a foreig ...

Markdown不常用数学符号语法
Markdown不常用数学符号语法
参考资料:
https://blog.csdn.net/LB_yifeng/article/details/83302697
https://blog.csdn.net/qq_18150255/article/details/88040858?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_title~default-0.pc_relevant_baidujshouduan&spm=1001.2101.3001.4242
运算符
符号
语法
符号
语法
符号
语法
±
\pm
⋅
\cdot
≈
\approx
∓
\mp
≠
\nep
$\ldots$
\ldots
$\bigotimes$
\bigotimes
$\bigoplus$
\bigoplus
$\prod$
\prod
希腊字母
符号
语法
符号
语法
符号
语法
α
\alphaα
β
\beta
γ
\gammaγ
...
arxiv论文整理工具
arxiv论文整理工具可以自动从arxiv获取各大顶会论文
自动下载论文
摘要提取
摘要翻译
代码获取
整理导出pdf
代码
必须修改变量 file_name = ‘papers.txt’
papers.txt为需要整理的论文名
papers.txt标准格式
第一列为论文分类 第二列为论文名 其余可空
1234567891011| --------- | ------------------------------------------------------------ | -------- | ---- | -------- || | | | | || | | | | || ACL202 ...
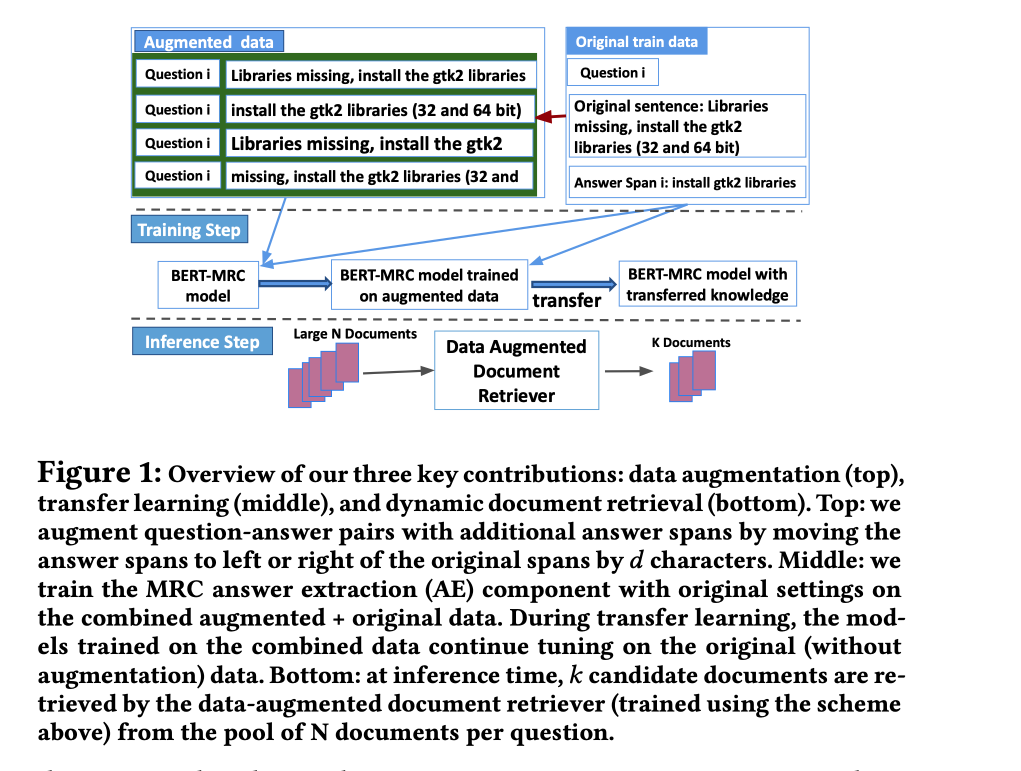
Cheap and Good Simple and Effective Data Augmentation for Low Resource Machine Reading
Cheap and Good Simple and Effective Data Augmentation for Low Resource Machine Reading
论文:https://arxiv.org/abs/2106.04134
代码:https://github.com/vanh17/techqa
任务为低资源机器阅读理解提出了一个简单而有效的数据增强策略。首先在包含正确答案的近似上下文的增强数据上对MRC系统的答案提取组件进行预训练,然后再对准确答案的跨度进行训练。
方法(模型)不是直接在训练期间提供的答案跨度上训练神经网络,而是先对其进行预训练,以确定答案出现的大致范围。然后,以两种不同的方式使用这个预训练的神经模型。首先,在训练之前,用这个模型的权重来初始化答案提取模型,而不是从头开始。第二,在推理时,将预训练的模型作为一个额外的文档检索组件来使用:只关注那些包含被确定为可能包含答案的文档。
主要贡献:
为MRC QA引入了一种简单而有效的数据增强方法。通过人为地移动训练分区中答案跨度的边界来产生额外的训练数据,并在这些数据上预训练一个模型,以确定答案可 ...

Tensorflow模型保存与加载
Tensorflow模型保存与加载123456import osos.environ['TF_CPP_MIN_LOG_LEVEL']='2'import tensorflow as tffrom tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
123456789def preprocess(x, y): """ x is a simple image, not a batch """ x = tf.cast(x, dtype=tf.float32) / 255. x = tf.reshape(x, [28*28]) y = tf.cast(y, dtype=tf.int32) y = tf.one_hot(y, depth=10) return x,y
12345678910111213batchsz = 128(x, y), (x ...

tensorflow.keras.layers keras.Model 自定义层应用
tensorflow.keras.layers keras.Model 自定义层应用123import tensorflow as tffrom tensorflow.keras import datasets, layers, optimizers, Sequential, metricsfrom tensorflow import keras
数据预处理
123456789def preprocess(x, y): """ x is a simple image, not a batch """ x = tf.cast(x, dtype=tf.float32) / 255. x = tf.reshape(x, [28*28]) y = tf.cast(y, dtype=tf.int32) y = tf.one_hot(y, depth=10) return x,y
1自定义Layer
1234567891011121314class MyDense(layers ...

tensorflow.keras.Model compile fit evaluate应用
tensorflow.keras.Model compile fit evaluate应用12import tensorflow as tffrom tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
数据预处理
123456789def preprocess(x, y): """ x is a simple image, not a batch """ x = tf.cast(x, dtype=tf.float32) / 255. x = tf.reshape(x, [28*28]) y = tf.cast(y, dtype=tf.int32) y = tf.one_hot(y, depth=10) return x,y
1234567891011121314batchsz = 128(x, y), (x_val, y_val) = datasets.mnist.load_d ...

tensorflow.keras metrics应用
tensorflow.keras metrics应用
不使用metrics实现的博客参考:
12import tensorflow as tffrom tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
更改数据类型并归一化
123456def preprocess(x, y): x = tf.cast(x, dtype=tf.float32) / 255. y = tf.cast(y, dtype=tf.int32) return x,y
加载数据集并进行预处理
12345678910batchsz = 128(x, y), (x_val, y_val) = datasets.mnist.load_data()print('datasets:', x.shape, y.shape, x.min(), x.max())db = tf.data.Dataset.from_tensor_slices((x,y))db = db.map(prepr ...
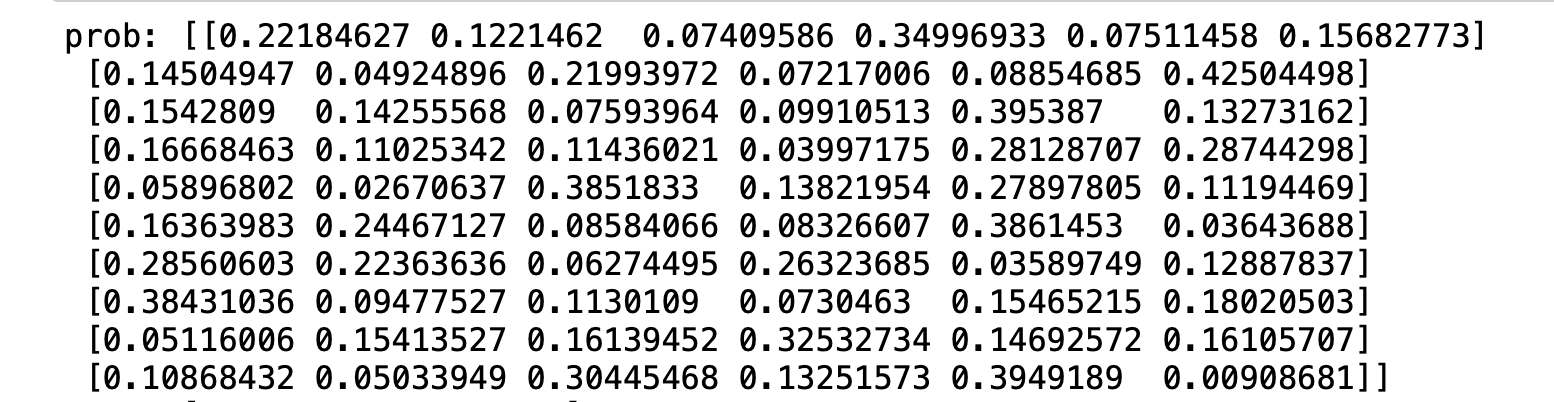
Top-k准确率
Top-k准确率12345import tensorflow as tfimport osos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' #限制控制台打印日志级别tf.random.set_seed(2467)
1234567891011121314151617181920212223242526def accuracy(output, target, topk=(1,)): # output [10,6] maxk = max(topk) batch_size = target.shape[0] pred = tf.math.top_k(output, maxk).indices # 前K个最大值的索引 [10,maxk]# print('每行top-6 最大值',tf.math.top_k(output, maxk).values) print('每行top-6 最大值下标',tf.math.top_k(output, ...

