
Cheap and Good Simple and Effective Data Augmentation for Low Resource Machine Reading
Cheap and Good Simple and Effective Data Augmentation for Low Resource Machine Reading
任务
为低资源机器阅读理解提出了一个简单而有效的数据增强策略。首先在包含正确答案的近似上下文的增强数据上对MRC系统的答案提取组件进行预训练,然后再对准确答案的跨度进行训练。
方法(模型)
不是直接在训练期间提供的答案跨度上训练神经网络,而是先对其进行预训练,以确定答案出现的大致范围。然后,以两种不同的方式使用这个预训练的神经模型。首先,在训练之前,用这个模型的权重来初始化答案提取模型,而不是从头开始。第二,在推理时,将预训练的模型作为一个额外的文档检索组件来使用:只关注那些包含被确定为可能包含答案的文档。
主要贡献:
- 为MRC QA引入了一种简单而有效的数据增强方法。通过人为地移动训练分区中答案跨度的边界来产生额外的训练数据,并在这些数据上预训练一个模型,以确定答案可能出现的大致范围。
- 使用两种不同的策略来利用预训练模型,首先,将其知识转移到答案提取模型中,用其学到的权重进行初始化;其次,在推理时,使用预训练模型根据文档包含答案上下文的可能性进行排序,并在得分最高的文档中提取答案。
- 将近似的RC知识用于文档检索和答案提取,可以大大改善在低资源RC任务上的性能。
模型结构:
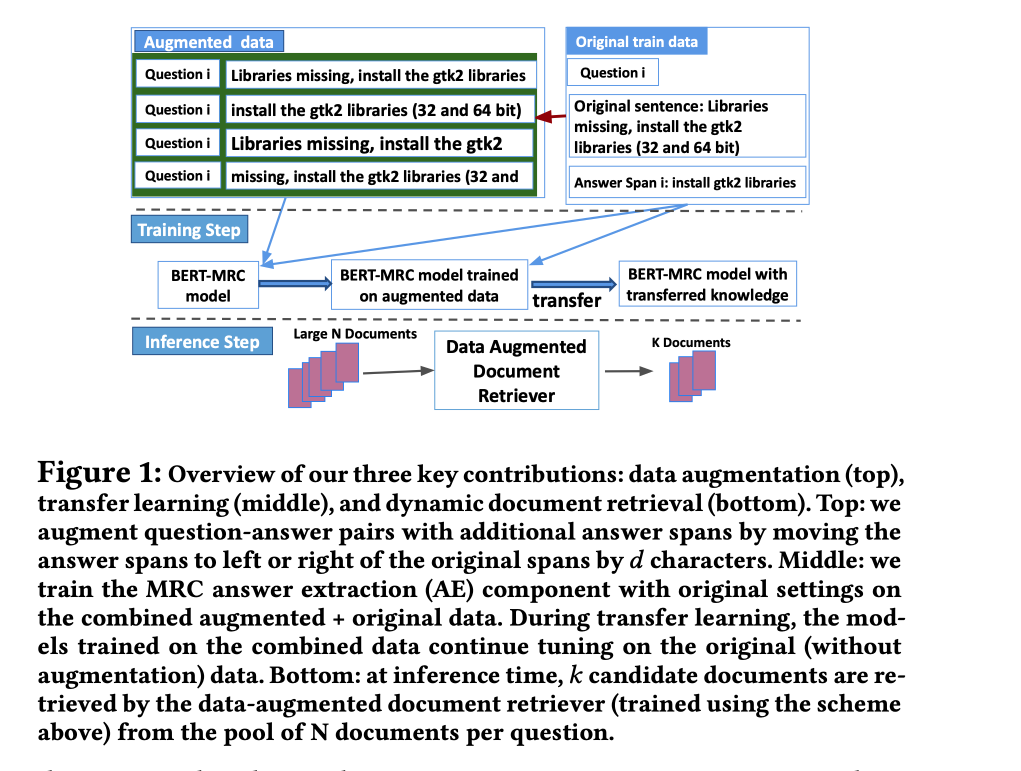
Data Augmentation
预训练 the BERT-MRC model
- 首先用概率对答案进行抽样,抽取出需要用来数据增强的片段。
- 对于选中的答案片段,通过将正确的答案跨度向左或向右移动d个字符来产生n个额外的模糊答案跨度。每个生成的答案跨度都成为一个新的positive training data point。
- 用增加的训练数据构建新的训练数据artificial data,训练模型以抽取答案近似范围。
Transfer Learning
继续在原始答案跨度(没有增强的数据集)上进一步训练的BERT-MRC模型来转移这种近似答案边界的知识。由此产生训练的模型是用于完整任务中答案跨度预测的最终模型。
Document Retrieval
采用在增强的数据上训练的模型来top-k score答案跨度,并只保留与这些答案跨度相关的文档。提供一个更小但更相关的候选文档集,可以大大改善AE的性能。
数据集
TechQA 一个复杂的、低资源的MRC任务。
PolicyQA 一个实用但规模适中的QA数据集,也包含长的答案跨度。
性能水平
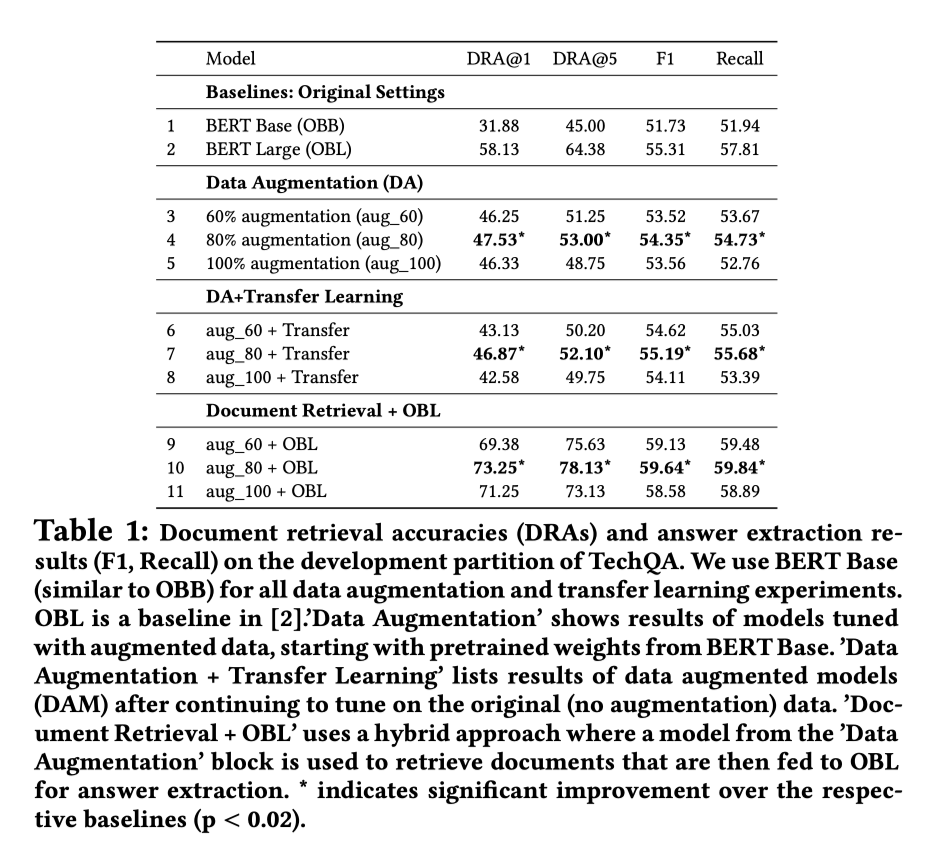
- 数据增强有助于TechQA的文档检索任务。
- 与基线模型(OBB)相比,”数据增强 “模型,”数据增强+迁移学习 “模型的DRA分数大幅提高。
- 为了进一步分析数据增强对文档检索的影响,把 “数据增强 “模型检索到的文档作为输入到BERT Large的OBL基线中。证明由数据增强模型检索的候选文档可以提高外部独立模型的文档检索性能。
结论
- 答案检索阶段:数据增强策略能够捕捉到答案出现的更大范围。
- 答案提取阶段:额外的训练数据,帮助提取模型缩小其搜索空间。
实验证明,通过提供更大的答案范围和额外的训练数据(即生成人工训练数据点),可以改善文档检索和答案提取的性能。特别是,大大改善了基于BERT的检索器和答案提取器在TechQA上的表现。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 没有胡子的猫Asimok!
相关推荐


评论

