RikiNet Reading Wikipedia Pages for Natural Question Answering
RikiNet: Reading Wikipedia Pages for Natural Question Answering
论文:https://arxiv.org/abs/2004.14560
会议:ACL 2020
任务
阅读长文档来回答open-domain问题在自然语言理解中仍然具有挑战性。本文介绍了一种新的模型,称为RikiNet,它通过阅读维基百科页面来自然地回答问题。
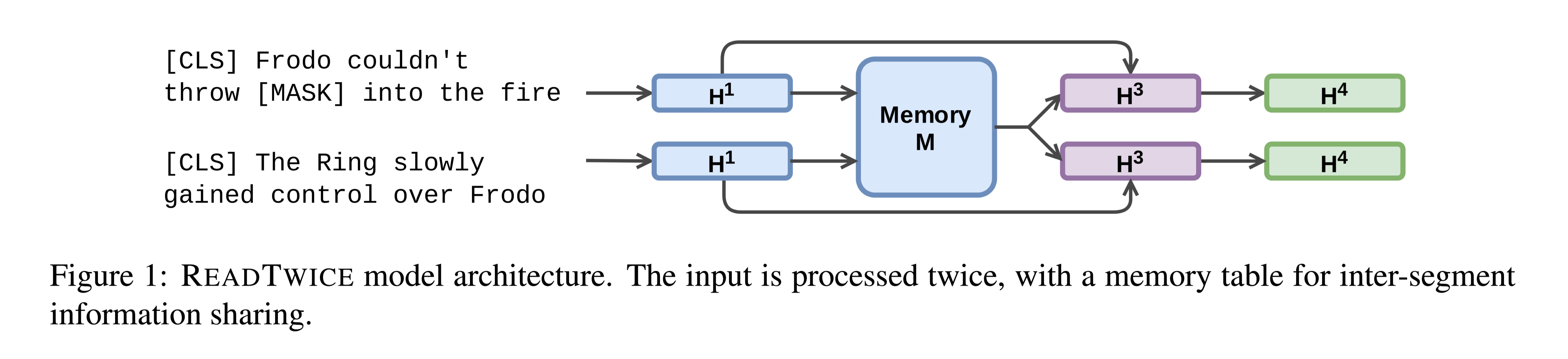
RikiNet包含一个dynamic paragraph dual-attention reader和一个multi-level cascaded(级联) answer predictor。阅读器通过一套互补的注意机制动态地表达文档和问题。然后将这些表示输入预测器,以级联方式获得短答案的范围、长答案的段落和答案类型。
NQ数据集相对于之前阅读理解任务数据集的两个挑战:
- 首先,NQ没有为每个问答(QA)对提供一个相对较短的段落,而是提供了一个完整的维基百科页面,与其他数据集相比,该页面要长得多。
- 其次,NQ任务不仅要求模型像以前的MRC任务一样找到问题的答案跨度(称为短答案),还要求模型找到包含回答问题所需信息的段落(称为长答案)。
方法(模型)
RikiNet采用了动态段落双注意力(DPDA)阅读器,该阅读器包含多个DPDA块。在每个DPDA块中,迭代地执行dual-attention来表示文档和问题,并使用带有动态注意力掩码的段落自注意来融合每个段落中的关键标记。生成的上下文感知问题表示、question-aware token-level和段落级别表示被输入预测器以获得答案。
设计DPDA的动机:
- 尽管整个维基百科页面包含大量文本,但大多数答案只与一段中的几个单词相关。
- 最后的段落表示法可以自然地用于预测长答案(对应段落)。
任务定义:
给定一个自然问题q,一个相关的Wikipedia页面p(在谷歌搜索引擎返回的前5个搜索结果中),该模型输出Wikipedia页面p中的一个段落作为长答案,其中包含足够的信息来推断问题的答案,以及长答案中的一个实体跨度作为短答案回答问题。
5种答案类型:
1 | “NULL” (no answer) |
问题定义:
将NQ data pair (q, p)转换为6元组: (q, d, c, s, e, t)
q:wordpiece IDs of question
d:wordpiece IDs of document span
c:长答案所在段落索引
s,e:短答案的起止位置
t:问题类型
RikiNet takes d and q as inputs, and jointly predicts c, s, e, t.
RikiNet:Reads the Wikipedia pages for natural question answering.
模型结构:
两个模块:
- dynamic paragraph dual-attention reader
- the multi-level cascaded answer predictor
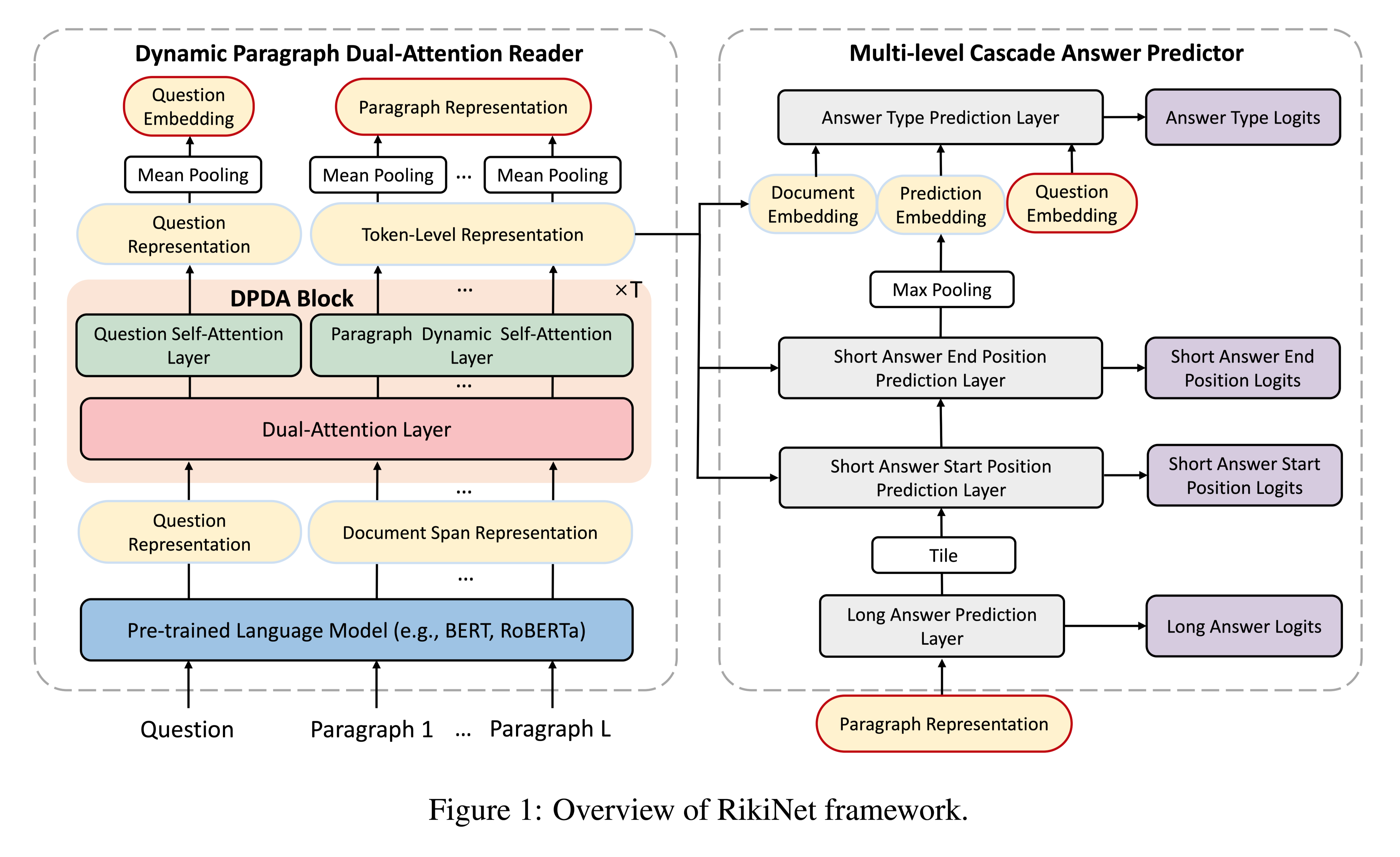
Dynamic Paragraph Dual-Attention Reader
动态段落双重注意力(DPDA)阅读器旨在表示文档跨度d和问题q。它输出上下文感知的问题表示、token-level的问题感知的文档表示和段落级文档表示,所有这些都将被输入预测器以获得长答案和短答案。
Encoding Question and Document Span
使用BERT做Encoding,长段落用滑动窗口切分成document span.
[CLS],q,[SEP],d,[SEP]
Dynamic Paragraph Dual-Attention Block
DPDA reader包含多个DPDA blocks,每个DPDA block包括三部分:the dual-attention layer, the paragraph dynamic self-attention layer, and the question self-attention layer。
最后一层DPDA输出问题和文档的表示。
Dual-Attention Layer
使用dual-attention mechanism加强从问题到段落以及从段落到问题的信息融合。
通过增加注意力的深度来进一步调整它,然后再进行残差连接和层的归一化。
Question Self-Attention Layer
This layer uses a transformer self-attention block to further enrich the question representation.
Paragraph Dynamic Self-Attention Layer
This layer is responsible for gathering information on the key tokens in each paragraph.
Multi-level Cascaded Answer Predictor
由于NQ任务的性质,短答案总是包含在长答案中,因此使用长答案的预测来促进获得短答案的过程是有意义的。
该预测器将token representation,$D(T)$、paragraph representation $L$ 和question embedding $q$ 作为输入,以级联方式预测四个输出:(1)长答案→ (2) 短答案范围的起始位置→ (3) 短答案跨度的结束位置→ (4) 答案类型。也就是说,前面的结果将用于下一个任务,如符号所示“→”。
Long Answer Prediction
采用了一个全连接层F,使用TANH激活函数,作为长答案预测层。
输入:paragraph representation
Short Answer Prediction
预测短答案的起止位置。
输入:long-answer prediction representation 和 token representation
Answer Type Prediction
输入:question embedding $q$ ,token representation,short-answer prediction representation
将question embedding $q$ 作为答案类型预测的辅助信息。
交叉熵损失函数
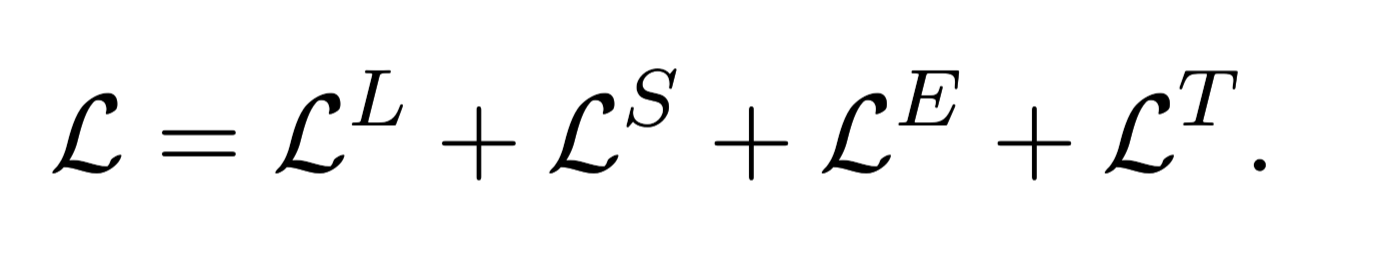
数据集
- Natural Questions (NQ)
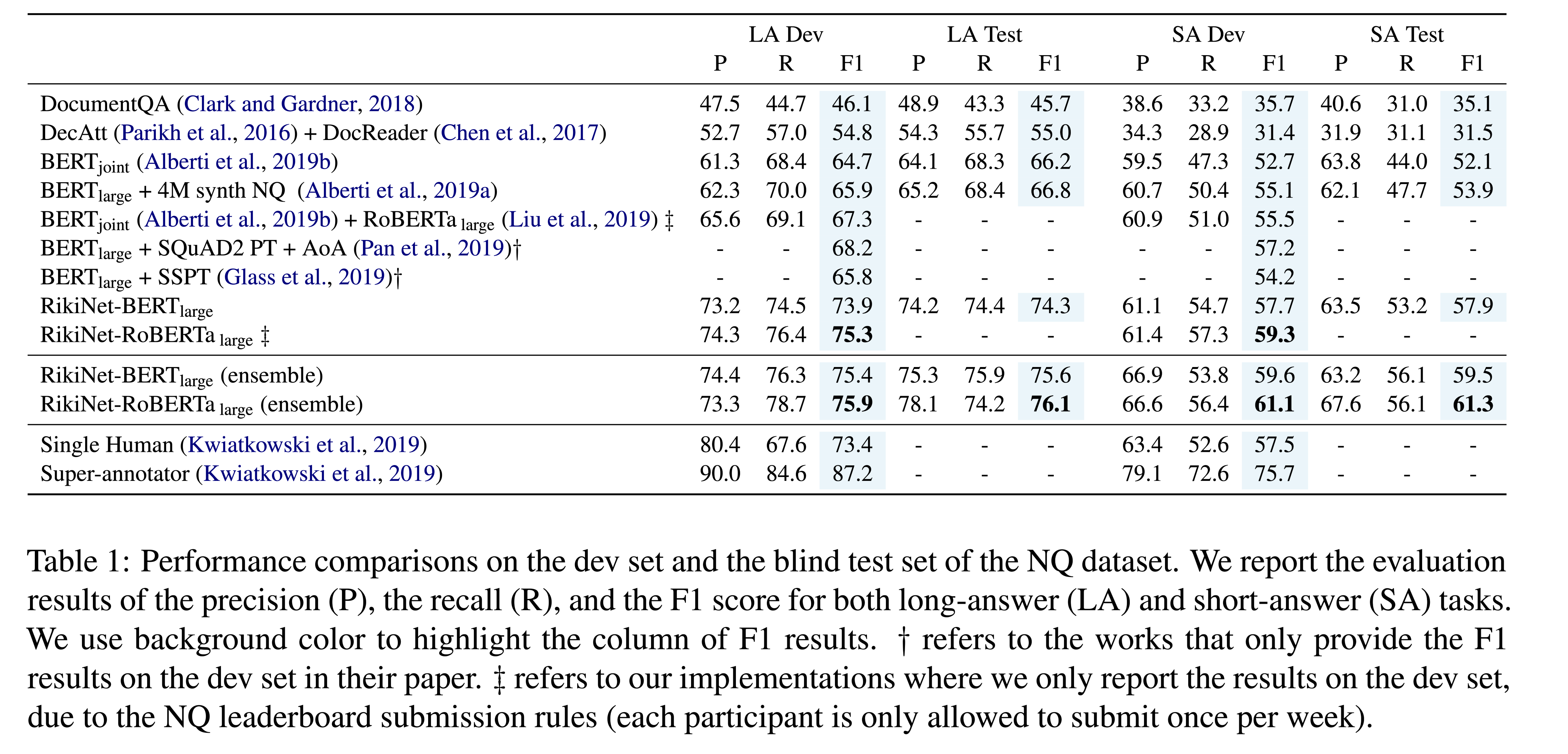
NQ数据集的公开发布包括307373个训练示例和7830个验证集数据示例(dev)。NQ提供了一个包含7842个示例的blind test set,只能通过公共排行榜提交来访问。
性能水平
结论
RikiNet由一个动态段落双注意阅读器和一个多级级联答案预测器组成,前者学习标记级、段落级和问题表示,后者以级联方式联合预测长答案和短答案。在自然问题(NQ)数据集上,RikiNet是第一个超越单一人类得分的单一模型。