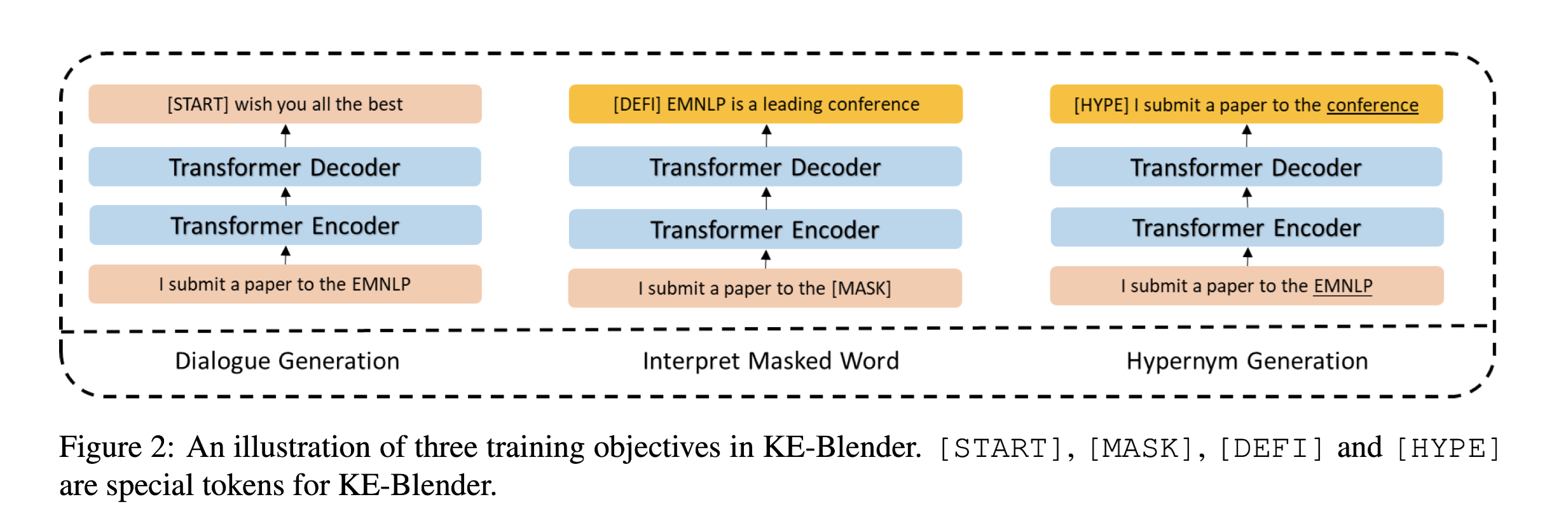
SEQUENTIAL LATENT KNOWLEDGE SELECTION FOR KNOWLEDGE-GROUNDED DIALOGUE
SEQUENTIAL LATENT KNOWLEDGE SELECTION FOR KNOWLEDGE-GROUNDED DIALOGUE
论文:https://arxiv.org/abs/2002.07510
代码:https://github.com/bckim92/sequential-knowledge-transformer
任务
以知识为基础的对话是一项基于话语背景和外部知识产生信息性反应的任务。
提出sequential latent variable model(sequential knowledge transformer (SKT))更好地模拟多轮知识为基础的对话中的知识选择,该模型可以跟踪知识的先验和后验分布;因此,不仅可以减少对话中知识选择的多样性造成的模糊性,还可以更好地利用响应信息来正确选择知识。
方法(模型)
主要贡献:
本文提出了sequential knowledge transformer (SKT)模型。该模型是第一次尝试利用顺序潜变量模型进行知识选择,随后改善以知识为基础的对话。
实验结果表明,所提出的模型不仅提高了知识选择的准确性,而且还提高了语料生成的性能。在Wizard of Wikipedia和Holl-E数据集的知识注释版本上取得了新的最先进的性能。
APPROACH
模型结构:
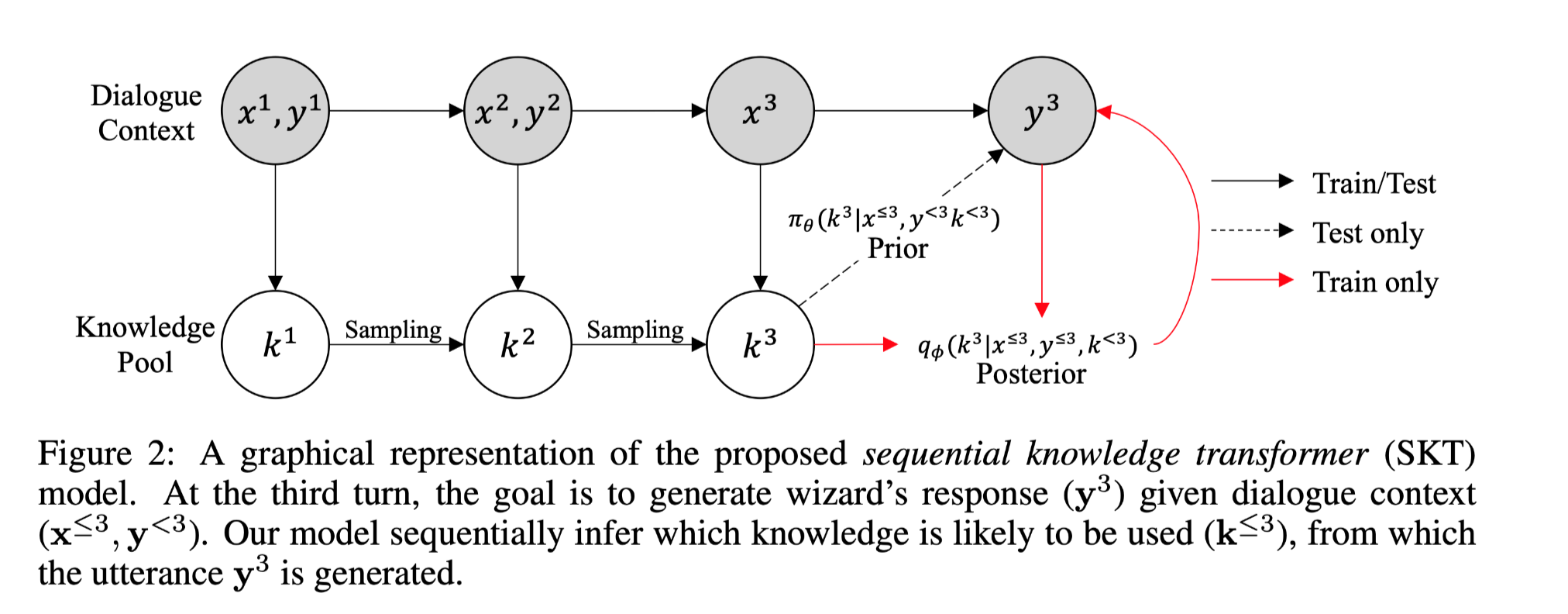
SKT依次对以前选择的知识进行处理,以产生反应。
模型第t轮的输入是之前的对话回合,包含apprentice的话语$x1, …, x_t$, wizard的话语 $y_1, …, y{t−1}$,knowledge pool $k_1, …, k_t$,输出为selected knowledge $k_s^t$ and the wizard’s response $y_t$。
Sentence Encoding
apprentice utterance $x^t$:
使用BERT编码为embedding $h_x^t$,每个时间步使用average pooling。
同样,Wizard utterance $y^{t-1}$编码为$hy^{t-1}$,knowledge sentences编码为${h^{t,l} k} = h^{t,1} k, …, h^{t,L} k$。
apprentice-wizard utterance pair $h{xy}^t=[h_x^t,h_y^t]$在第t轮对话使用GRU联合表示为:$d^t{xy}=GRU{dialog}(d^{t-1}{xy},h^t_{xy})∈ R^{768}$
1 ≤ t ≤ T:代表对话的轮次
1 ≤ m ≤ M and 1 ≤ n ≤ N :分别表示 apprentice 和 wizard 对话中的单词
1 ≤ l ≤ L:表示knowledge sentences in the pool
T是对话长度,M和N是apprentice 和 wizard的每个话语的长度,L是知识池的大小
Sequential Knowledge Selection
两个调整:
将知识选择视为一个连续的决策过程,而不是一个单步决策过程
由于对话中知识选择的多样性,将其建模为潜在的变量。
因此,可以对多轮知识选择和反应生成进行联合推理,而不是逐轮进行单独推理。
prior distribution of knowledge :$π_θ$
posterior distribution :$q_φ$
Decoding with Copy Mechanism
wizard在第$t$轮的回应由当前context $x^t$,和选择的knowledge sentence $k^t_s$生成。
Copy Mechanism使用Transformer作为解码器。
Training
在有无真实标签的训练中,知识选择的准确性存在很大差距。因此使用knowledge loss(即预测和真实知识句子之间的交叉熵损失)作为潜变量的辅助损失。
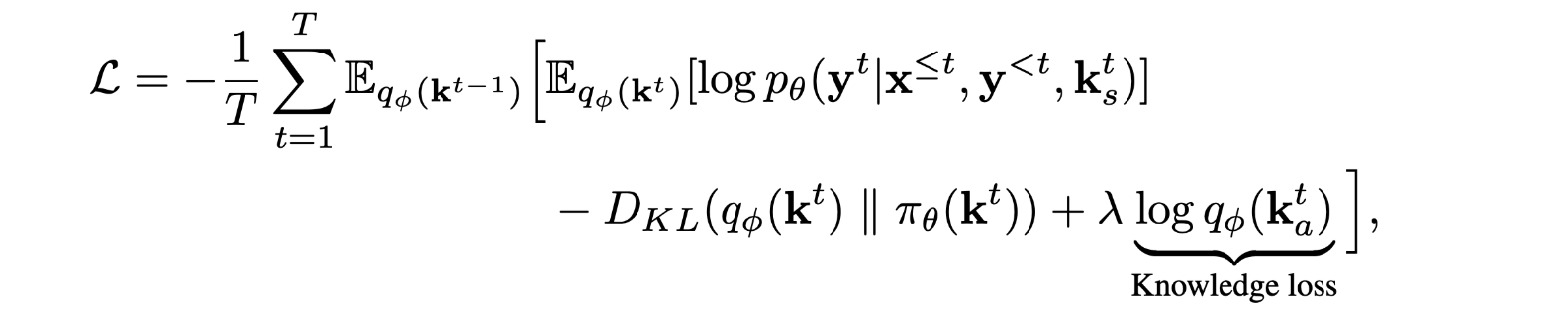
数据集
- Wizard of Wikipedia (WoW)
- Holl-E
性能水平
- Wizard of Wikipedia数据集
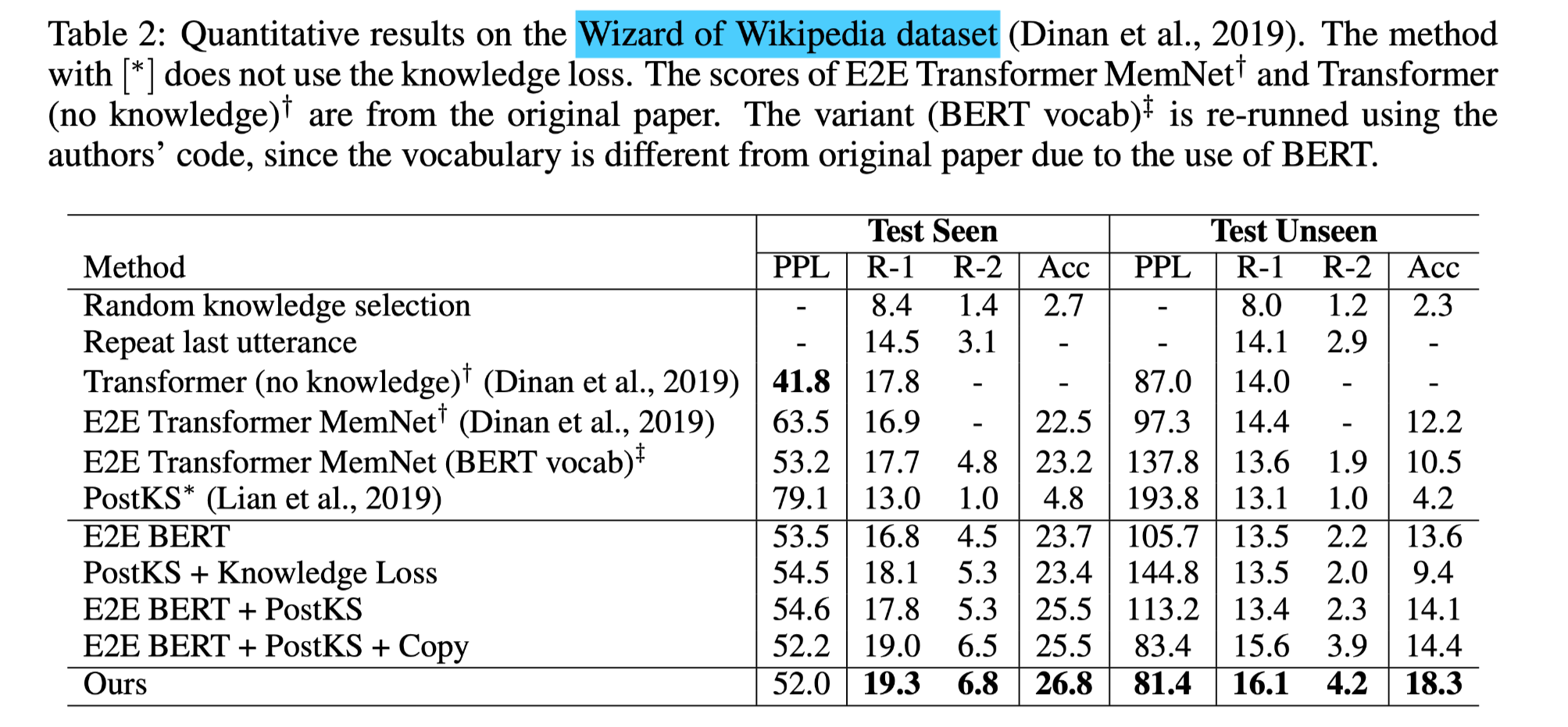
- 本文模型在知识选择(准确率)和语篇生成(unigram F1,bigram F1)的所有指标上都优于最先进的以知识为基础的对话模型。
- 在没有知识标签的情况下训练的PostKS在知识选择方面显示出较低的准确率,比随机猜测略好。而在WoW Test Seen中,它达到了比E2E Transformer MemNet更好的性能,这表明利用先验和后验知识分布对知识基础的对话是有效的,
- BERT提高了知识选择的准确性,但由于对话知识选择的多样性,其提高幅度并不像TextQA那样大。
- E2E BERT + PostKS + Copy在基线中表现最好,这验证了顺序潜变量建模对于提高知识选择和随后的语篇生成的准确性至关重要。
- 和基线之间的性能差距在 Test Unseen 中更大。可以理解为,顺序潜变量可以更好地进行泛化。
- 在基线中加入复制机制,大幅提高了语料生成的准确性,但几乎没有改善知识选择,这也证明了顺序潜变量的有效性。
- Transformer(no knowledge)在WoW Test Seen 中显示出最低的困惑,这主要是由于它可能只生成一般和简单的语料,因为没有知识基础。这种行为对困惑度是有利的,而其他基于知识的模型则有预测错误知识的风险,这对困惑度是不利的。
- Holl-E
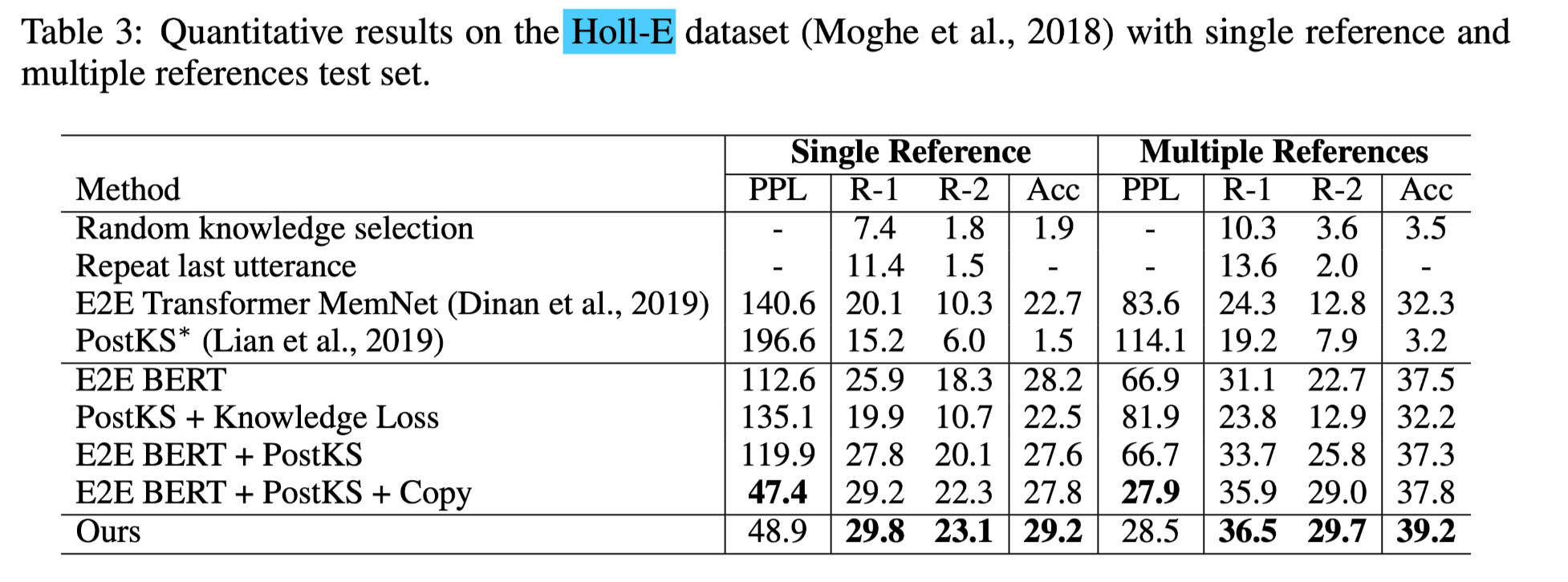
本文的模型在所有指标上都优于所有基线
一个值得注意的趋势是,BERT大大降低了所有模型的困惑度,这可能是由于Holl-E的数据集规模比WoW小得多,BERT可以防止过拟合。
结论
本文研究了多轮知识为基础的对话中的知识选择问题,并首次提出了一个顺序潜变量模型SKT。模型在Wizard of Wikipedia和Holl-E数据集的知识注释版本上取得了新的最先进的性能。所提出的模型提高了知识选择的准确性,从而提高了语篇生成的性能。