A Hierarchical Network for Abstractive Meeting Summarization with Cross- Domain Pretraining
A Hierarchical Network for Abstractive Meeting Summarization with Cross- Domain Pretraining
论文:A Hierarchical Network for Abstractive Meeting Summarization with Cross- Domain Pretraining
代码:https://github.com/JudeLee19/HMNet-End-to-End-Abstractive-Summarization-for-Meetings
- 非官方但比较简洁易懂的代码
任务
传统的会议总结方法依赖于复杂的multi-step pipelines,使得联合优化难以实现,并且会议记录的语义结构和风格与文章和对话有很大不同。本文提出了一个新颖的abstractive summary network,以适应会议的场景。
传统模型需要复杂的多阶段机器学习管道,如模板生成、句子聚类、多句子压缩、候选句子生成和排名。由于这些方法不是端到端的可优化的,因此很难联合改进管道中的各个部分以提高整体性能。此外,一些组件,例如模板生成,需要大量的人力参与,使解决方案无法扩展或转移。
目标
根据输入的会议记录输出会议总结。
效果展示:

方法(模型)
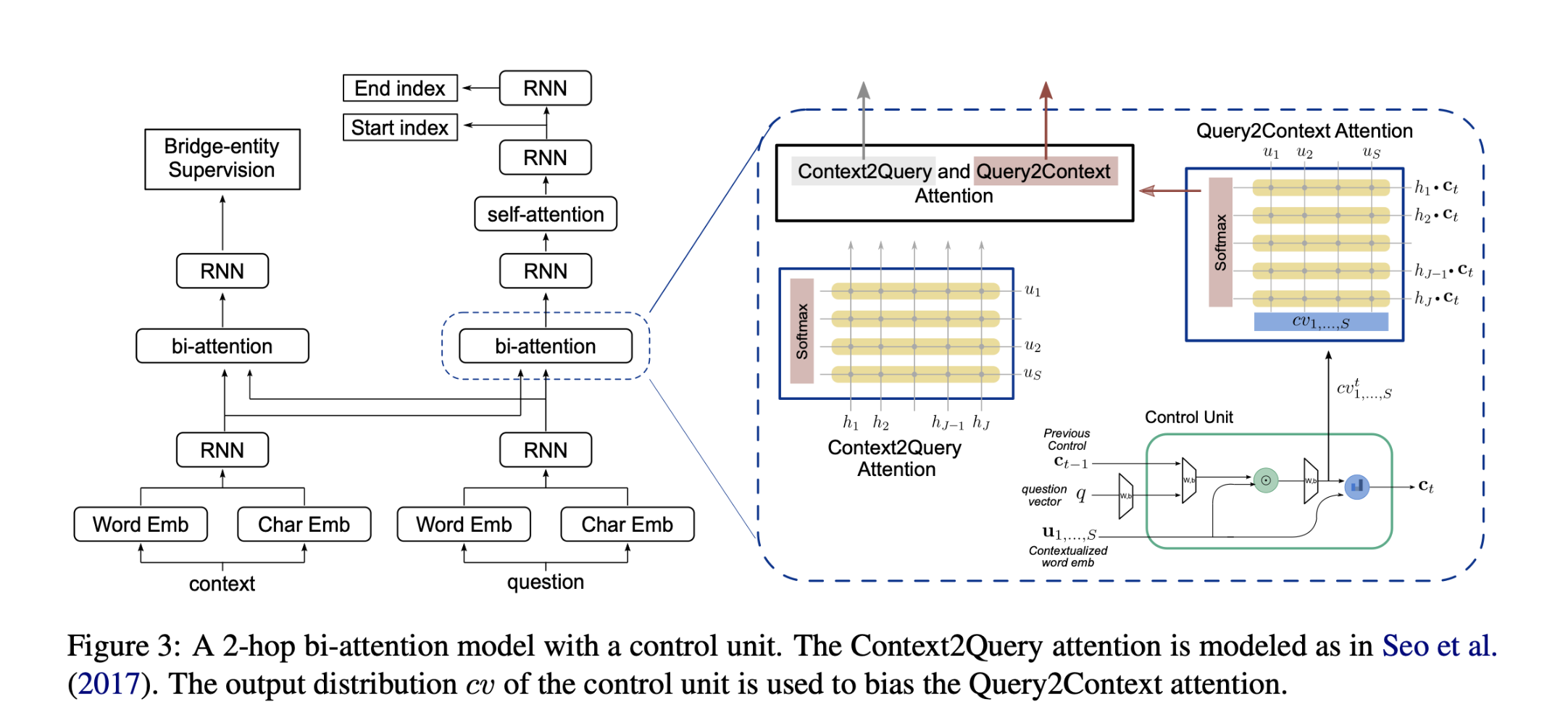
Hierarchical Meeting summarization Network (HMNet)
本文设计了一个分层(Hierarchical)结构来适应长的会议记录,并设计了一个角色向量来描述发言者之间的差异。
为会议中的每个角色设计一个角色向量描述不同与会者的立场差异
使用新闻数据预训练模型应对会议数据不足的情况
模型结构:
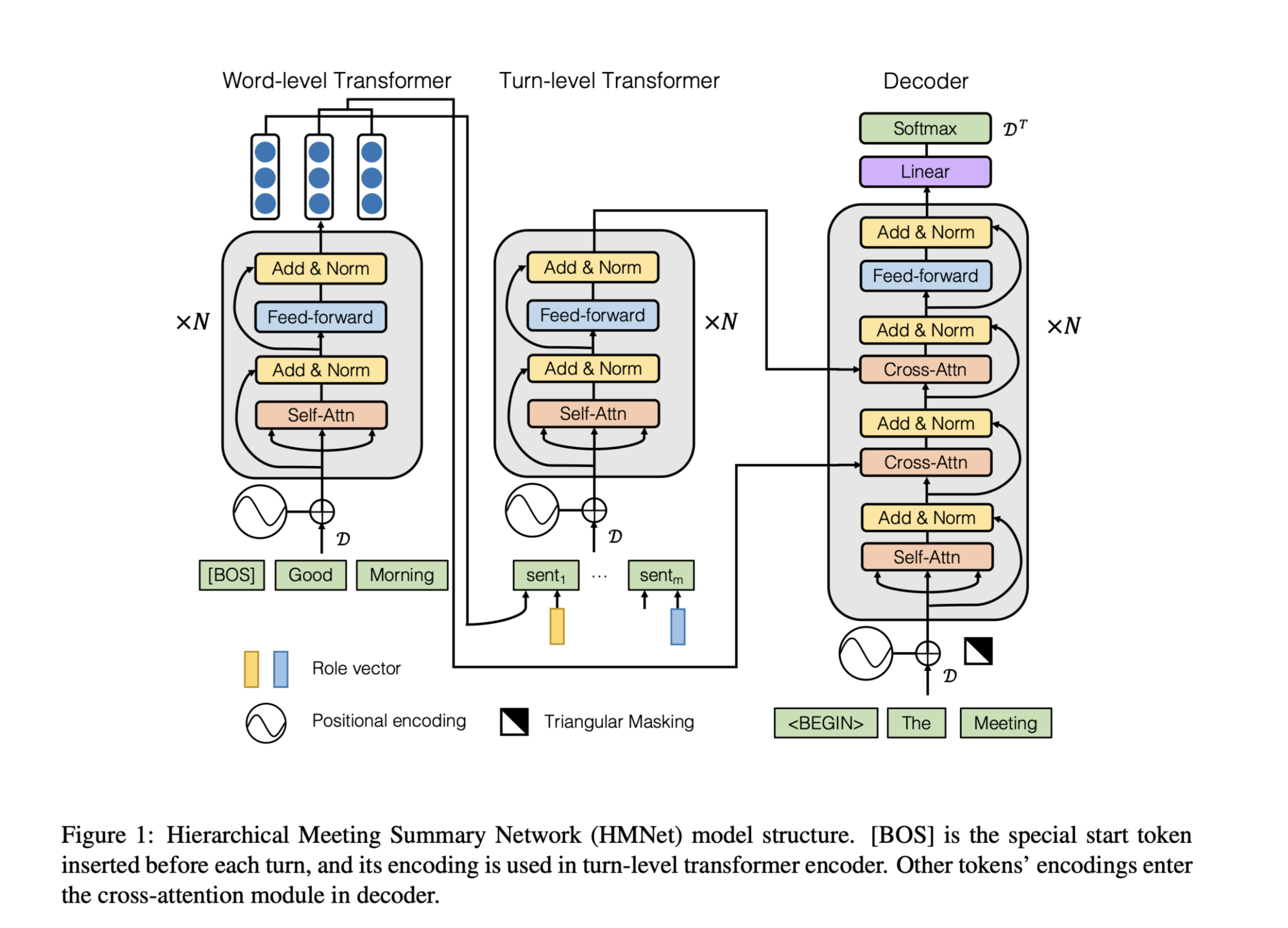
Encoder
- Role Encode 考虑 various participants
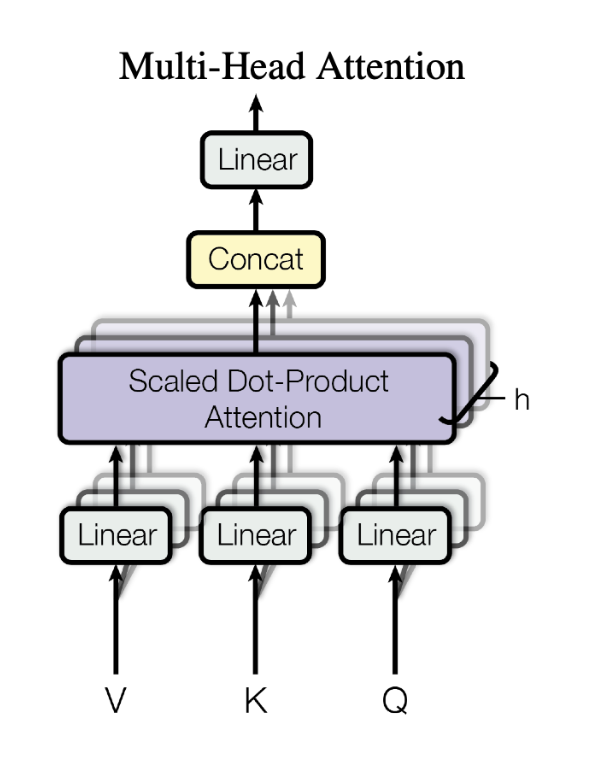
Hierarchical Transformer
transformer block 由multi-head attention layer 和一个 feed-forward layer组成
由于注意机制是位置不可知的,将位置编码附加到输入向量中
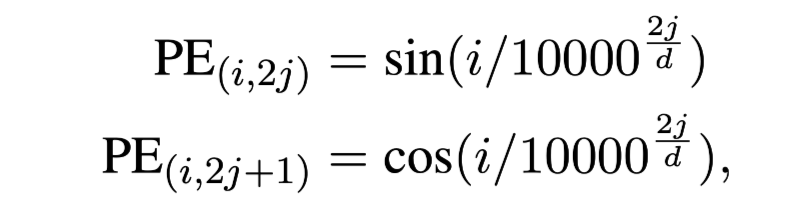
其中 $PE_{(i,j)}$代表输入序列中第i个word的位置编码的第j维。
transformer block的输入与输出维度相同,因此可以叠加。
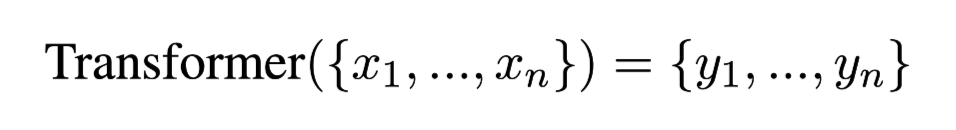
Word-level Transformer
为了结合句法和语义信息,训练了两个嵌入矩阵来表示词性标记和实体标记。
part-of-speech (POS) and entity (ENT) tags
在序列前添加了一个特殊的标记[BOS],以表示一个回合的开始。
Turn-level Transformer
将Word-level Transformer的输出[EOS]与此轮role向量连接起来表示第i轮。
Decoder
解码器使用lower triangular mask 防止模型看到未来的token。
利用embedding矩阵的权重将解码器的输出$V_{K-1}$解码为词表上的概率分布。
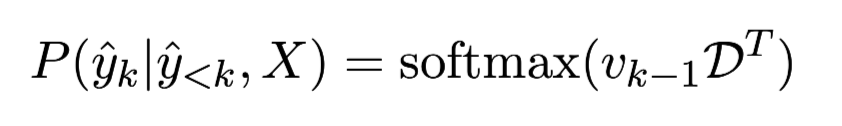
损失函数:
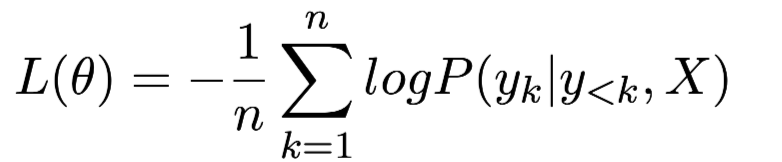
数据集
- AMI
- ICSI
这两个数据集分别包含来自自动语音识别(ASR)的会议记录。
性能水平
评测结果:
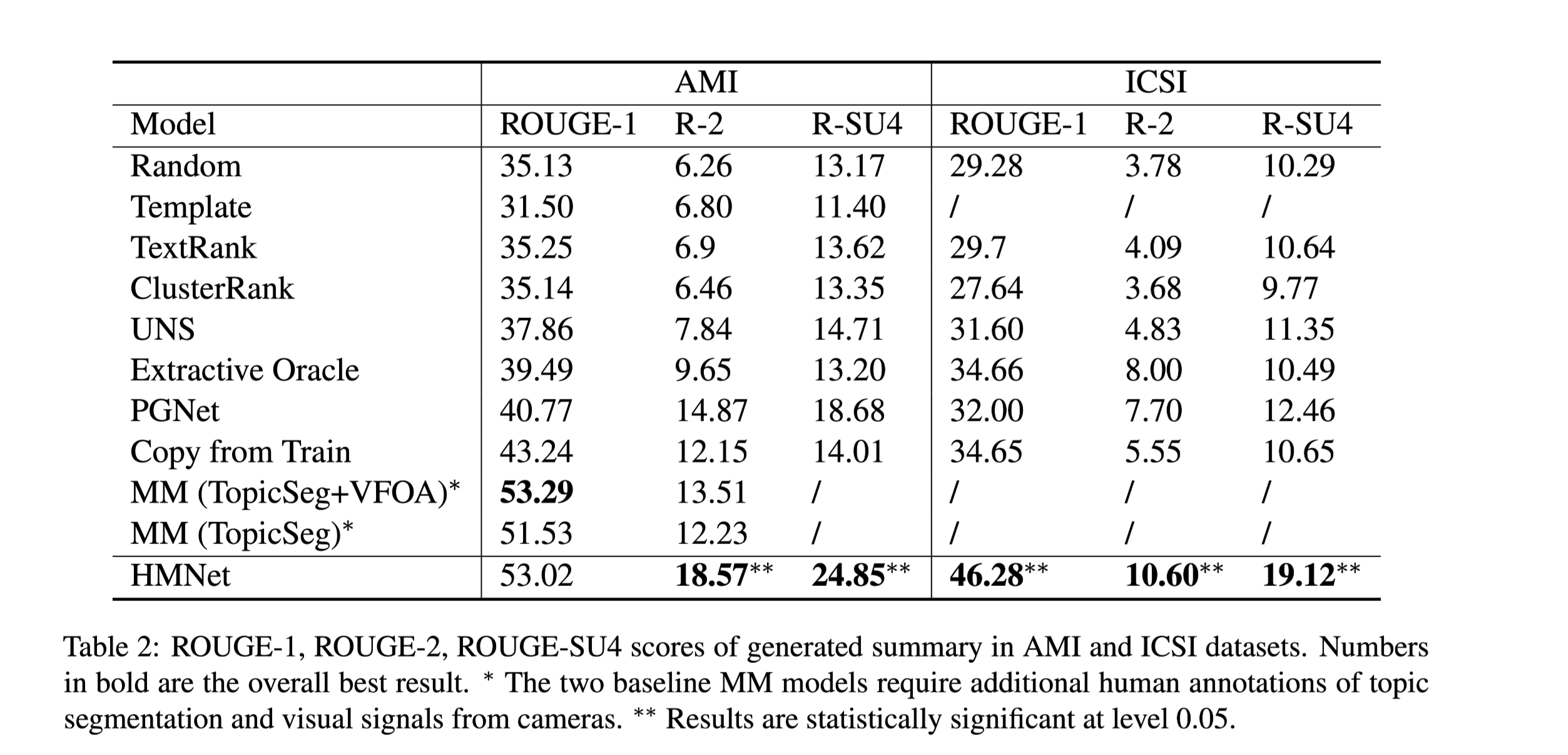
与之前模型性能相比,提升相当大。模型在自动指标和人工评估方面都优于以前的方法。例如,在ICSI数据集上,ROUGE-1得分从34.66%增加到46.28%。
结论
本文提出了一种用于抽象会议摘要的端到端分层神经网络HMNet。采用两级分层结构来适应长的会议记录,并用角色向量来表示每个与会者。还通过对新闻摘要数据进行预训练来缓解数据稀缺性问题。实验表明,HMNet在automatic metrics和人工评价方面都达到了最先进的性能。通过一个消融实验,表明角色向量、层次结构和预训练都有助于模型的性能。