NumNet Machine Reading Comprehension with Numerical Reasoning
NumNet Machine Reading Comprehension with Numerical Reasoning
任务
MRC不可避免的要涉及到数值推理的问题,机器不仅要能够比较数字相对的大小,还要能够知道和哪些数字做比较并进行推理,这就需要把数字相对的大小等等知识注入模型。但在之前大多数机器阅读理解模型中,基本上都将数字与非数字单词同等对待,无法获知数字的大小关系,也不能完成诸如计数、加减法等数学运算。正是基于这一原因,微信AI团队提出了一种数字感知的图神经网络(numerically-aware graph neural network,NumGNN),并基于此提出NumNet。
将数值推理集成到机器阅读理解模型中。两个关键因素:
- 数值比较:问题的答案可以通过在文档中进行数值比较,如排序和比较,直接获得。例如,在表1中,对于第一个问题,如果MRC系统知道“49 > 47 > 36 > 31 > 22”的事实,它可以很容易地提取出第二长的场地目标是47码。
- 数值条件:问题的答案不能通过文献中简单的数值比较直接得到,往往需要数值比较才能理解文本。例如,对于表1中的第二个问题,MRC系统需要知道哪个年龄组占人口的7%以上才能计算组数。
例子:

方法(模型)
模型结构:
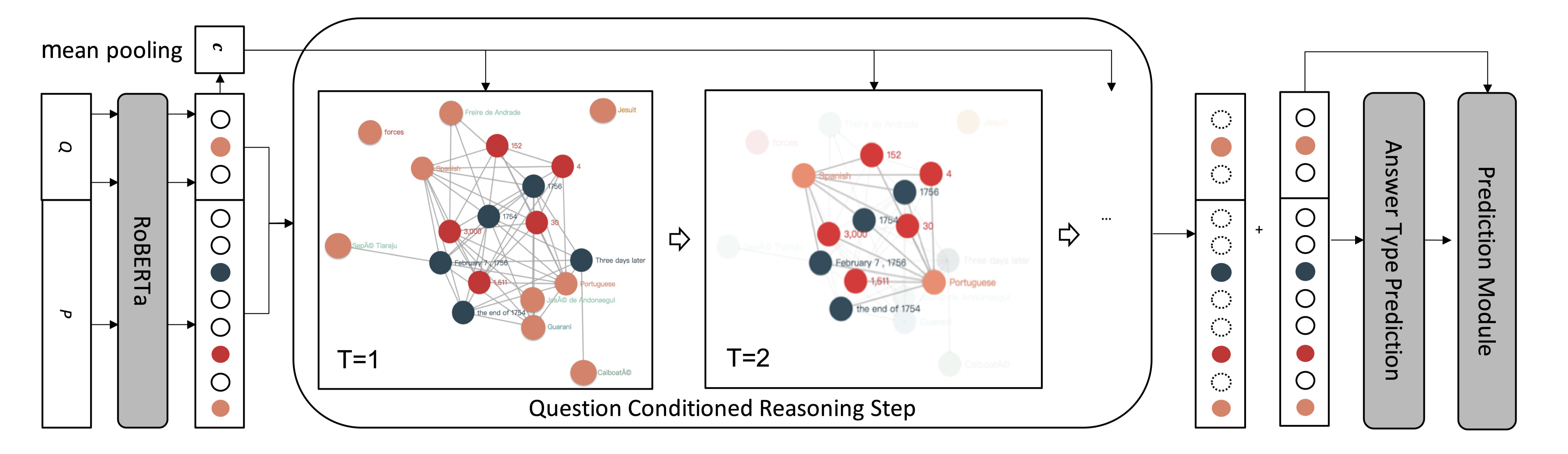
分为编码模块、推理模块和预测模块。利用图的拓扑结构编码数字间的大小关系,将文章和问题中的数字作为图结点,在具有$>$和$\leq$关系的数字间建立有向边,从而将数字的大小关系作为先验知识注入模型。
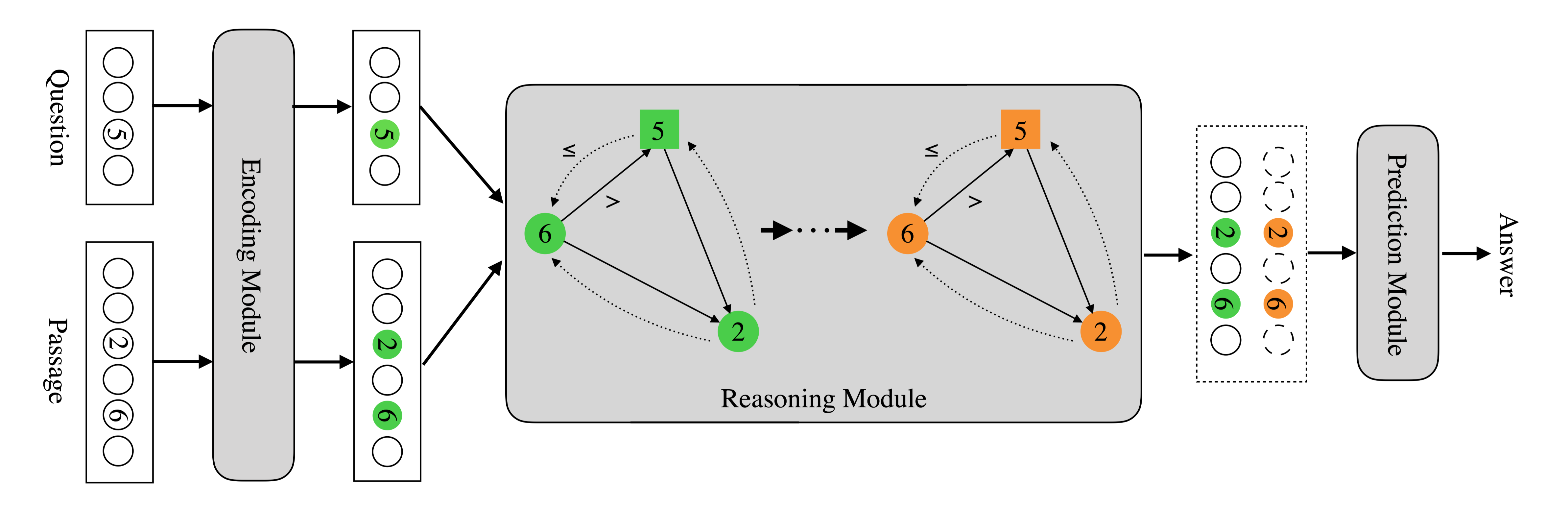
在上图Reasoning Module中,数字是一个节点,数字之间的黑色实线代表大于关系,黑色虚线代表小于等于关系。
具体来讲,给定一个问题和一段文本,先把问题里面的数字和文本里面的数字都抽出来。每个数字就是图上一个节点,同时对于任意两个数字,假如A数字和B数字,如果A大于B的话,那么A和B中间加一条有向边,表示数字A和B之间是A大于B的关系。如果A小于等于B,则会加另外一种有向边,把它们两个连接起来。通过这种操作,用图的拓谱结构把数字相对大小知识注入模型。另一方面,是结合文本信息去做更复杂的数学推理,具体的实现方式是使用图卷积神经网络在前述图结构上执行推理,从而获得更复杂的数学推理功能。
Encoding Module
和传统的编码层一样,使用了QANet和NAQANet,将问题和信息片段转换为向量空间表示,具体公式如下:
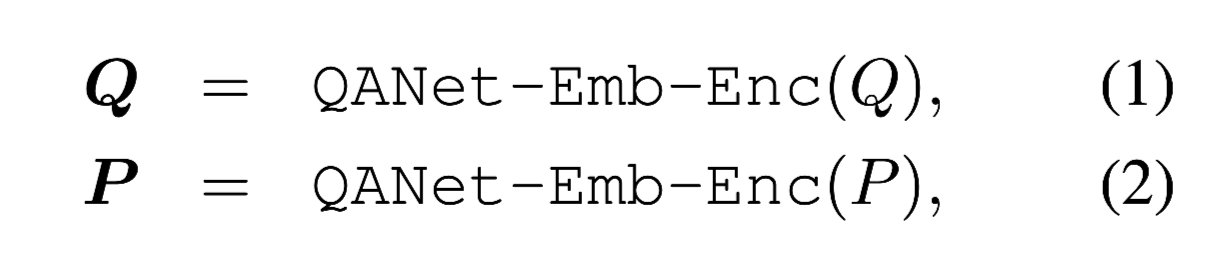
之后定义了启发式的运算,在这里指的是加入了注意力计算:
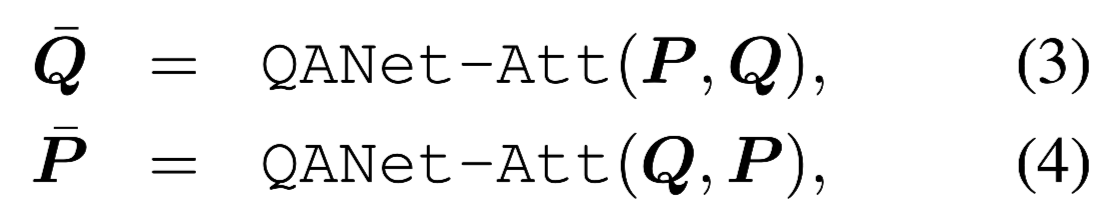
Q:代表question
P:代表passage
QANet-Emb-Enc(·)代表QANet中的”stacked embedding encoder layer”, 由convolution,self-attention,feed-forward层组成。
QANet-Att(·)代表QANet中的”context-query attention layer”,是一个passage-question的注意力层。
Reasoning Module
在推理模块中,是基于GNN(图神经网络)对于有向图 [公式] 进行推理的,有以下公式:

其中$W^M$是一个共享矩阵。
$U$是相应数字节点的表示。
QANet-Mod-Enc(·)是指在QANet中定义的”model encoder layer”。
因为$U$只有包含数字的表示,为了获取span-style(指答案之间有非数字词语的存在)的答案,这里将$U$和$M^P$拼接起来来产生数字启发式的passage表示$M_0$:
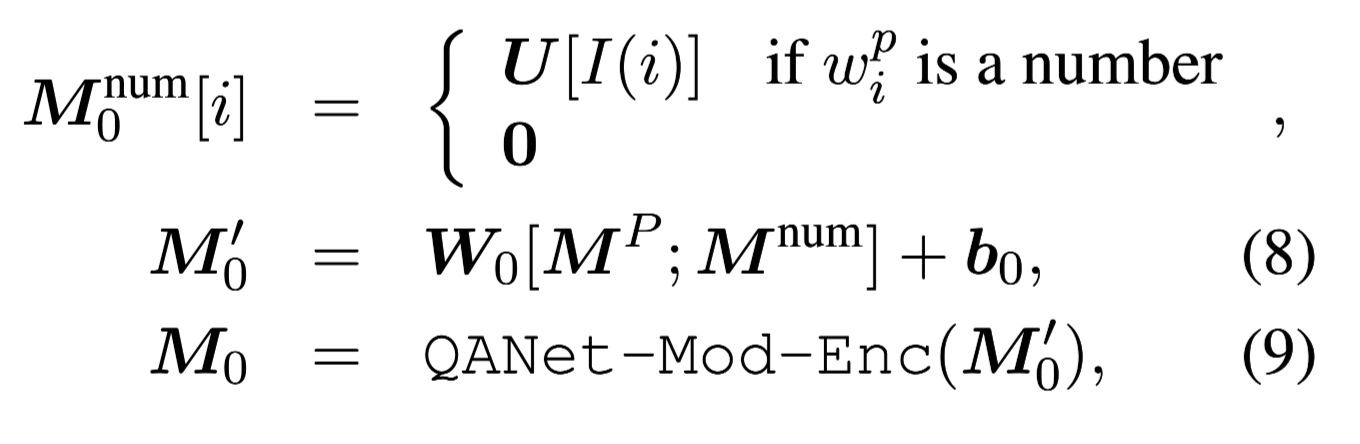
这里$[·;·]$代表矩阵拼接。
$W[k]$代表矩阵$W$的第k列,$I{(i)}$代表passage数字$w^p_i$的索引。
$W_0$是一个权重矩阵。
$b_0$ 是一个偏置向量。
Prediction Module
预测模块遵循了NAQANet,将答案分为四种类型,使用了一种特殊的输出层来计算答案的条件概率$Pr(answer|type)$ :
Passage span:答案出现在passage里,并且答案概率等于开始位置与结束位置的乘积。
Question span:答案出现在question里,并且答案概率等于开始位置与结束位置的乘积。
Count:答案可以通过计数来获取,并且当做是0-9十个数字的多分类问题(十分类),因为这样做的原因是由0-9可以得出计数的问题涵盖了DROP数据集Count 类型问题的绝大数。
Arithmetic expression:答案是算数问题表达式的结果,比如1+1=?。表达式通过3个步骤生成:
(1) 提取passage中所有的数字。
(2) 给每个数字赋予符号(+,- ,0),0在这里指的是不进行操作;。
(3) 对带符号数字进行求和,(2)中的符号为数字的系数。
同时,额外的输出层是用来计算答案类型$Pr(type)$的概率。在训练阶段,答案的概率是所有答案的联合概率$\sum_{type}Pr(type)·Pr(answer|type)$ 。在测试阶段,模型会优先选择答案类型概率最大然后再去预测相应的最佳答案。预测模块很大程度上继承了NAQANet,另外文中也提到了NumNet与NAQANet的最大区别是:多了推理模块。
数字启发的图构建
question和passage中的数字作为节点,分别记为$V^Q$和$V^P$,所以所有节点集合$V=V^Q \or V^P$。
节点之间的边包括两种关系:
- Greater Relation Edge:大于
- Lower or Equal Relation Edge:小于等于。
实际上出现在两种边集合中的数字是等价的,但是为了避免潜在的歧义性,当每一个数字出现一次时添加一个不同的节点。
数字推理
初始化
对于每一个节点$v_i^P \in V^P$,它的表示是矩阵$M^P$相对应的第$i$列,记为 $v_i^P=M^P[I^P(v_i^P)]$ ,其中$I^P(v_i^P)$代表了$v_i^P$的索引。同理,对于问题中的节点,对于$v_i^Q$是做同样的初始化。
一步推理
给定图$G$和节点表示$v$,文章使用GNN进行推理,步骤有三:
- 节点关联度量
对于生成答案,通常只有很少的数字是相关的,所以通过sigmoid函数来计算数字权重,同时也可以过滤掉一些不相关数字,对于给定节点$v_i$,权重计算如下:
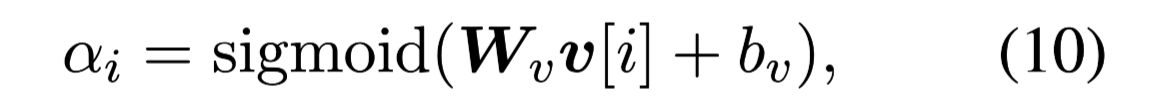
- 信息传递
信息传递函数如下:
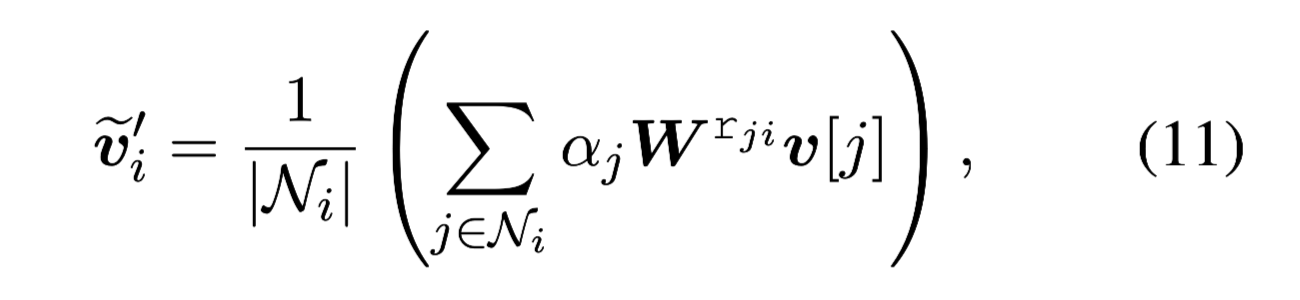
- 节点表示更新
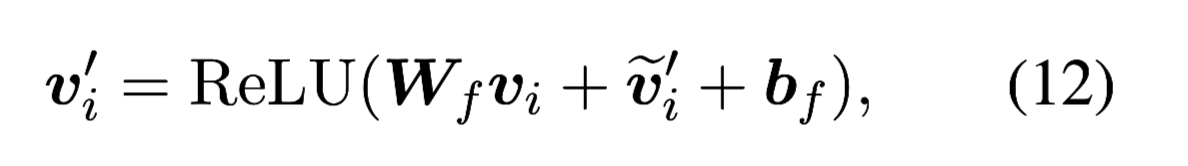
完整的单步推理过程可定义成如下函数:
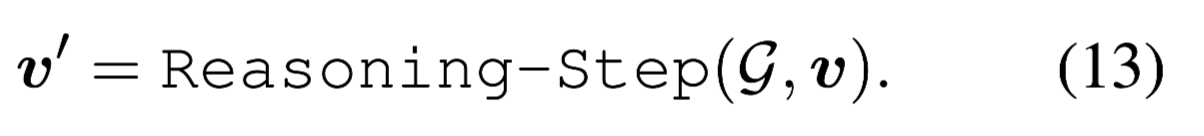
多步推理
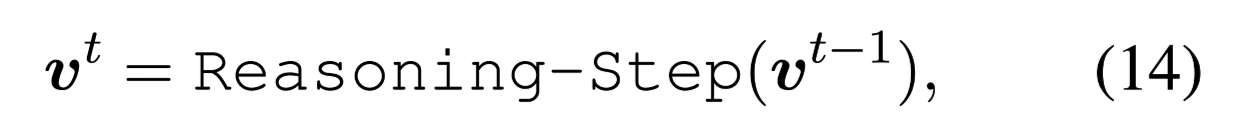
数据集
数据集:DROP
评价指标:EM和F1
DROP数据集,由AI2( Allen Institute for Artificial Intelligence)实验室提出,主要考察的是模型做类似数学运算相关的操作能力。
与 SQUAD数据集中大多都是“姚明的妻子是谁?”的题不同,其中的问题会涉及到数学算的情况。
性能水平
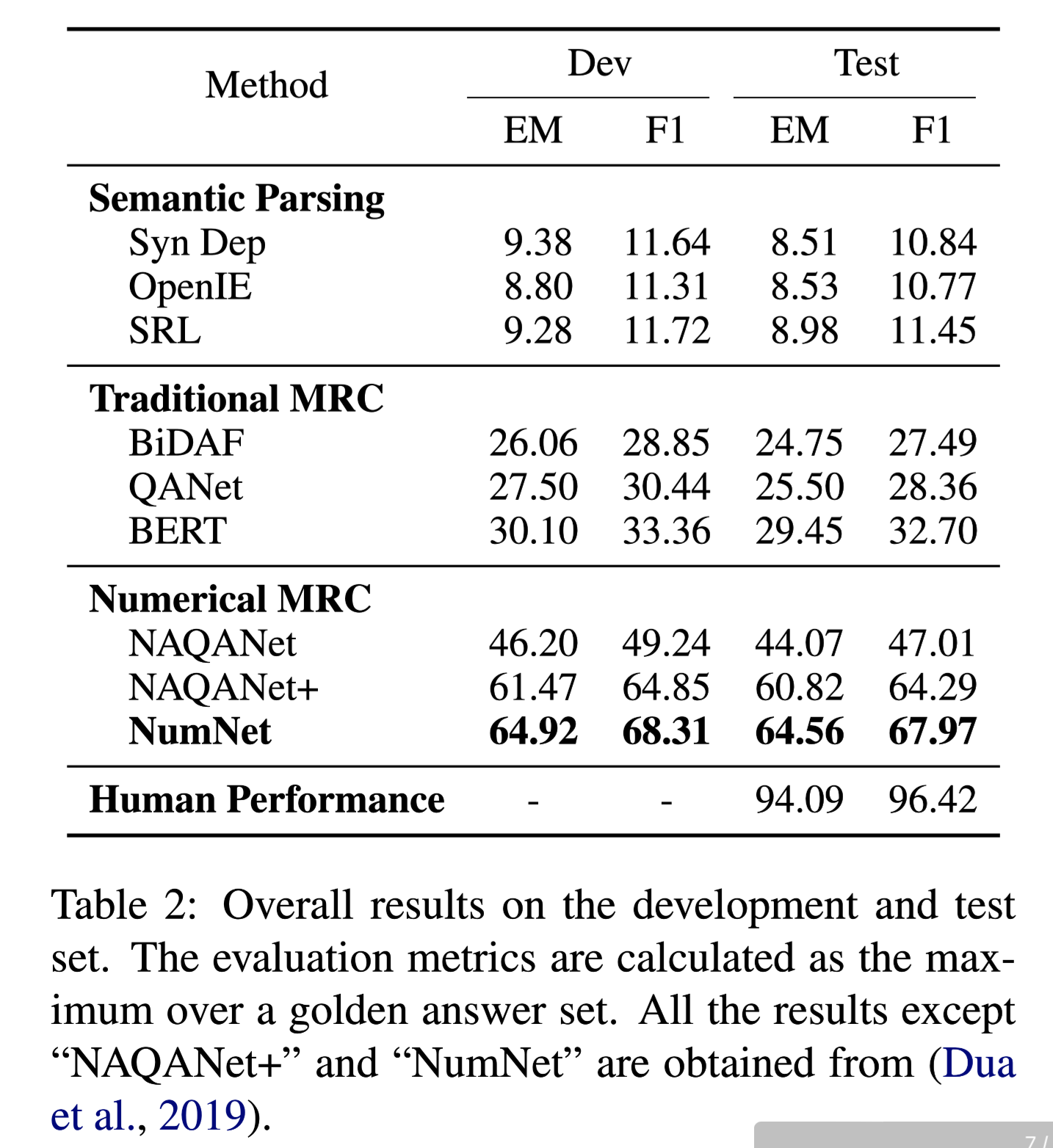
结论
在实践中,机器阅读理解(MRC)问题自然需要诸如加法、减法、分类和计数等数字推理技能。然而,这些技能在大多数现有的MRC模型中没有被明确考虑。在这项工作中,本文提出了一个名为NumNet的数字MRC模型,它在阅读段落的同时进行明确的数字推理。具体来说,NumNet将问题和段落中的数字关系编码为一个图作为其拓扑结构,并利用数字感知的图形神经网络对该图形进行数字推理。
case study