Knowledge Enhanced Fine-Tuning for Better Handling Unseen Entities in Dialogue Generation
Knowledge Enhanced Fine-Tuning for Better Handling Unseen Entities in Dialogue Generation
EMNLP2021
任务
预训练模型在对话生成方面取得了很大的成功,但当输入包含预训练和微调数据集中没有出现的实体(unseen entity)时,它们的性能会显著下降。为了解决这个问题,现有的方法利用外部知识库来生成适当的响应。在现实场景中,实体可能不被知识库所包含,或者受到知识检索精度的影响。为了解决这个问题,本文不再引入知识库作为输入,而是只根据输入上下文,通过预测知识库中的信息来强迫模型学习更好的语义表示。
具体来说,在知识库的帮助下,引入了两个辅助训练目标:
- 解释masked word:在给定上下文的情况下猜测masked entity 的含义。例如“I want to submit a paper to EMNLP”,一般情况下,有人可能不知道EMLNLP这个专业名词,但是可以根据上下文猜出,这是一个“会议”或者“期刊”。
- 生成上位词:根据上下文预测实体的上位词。
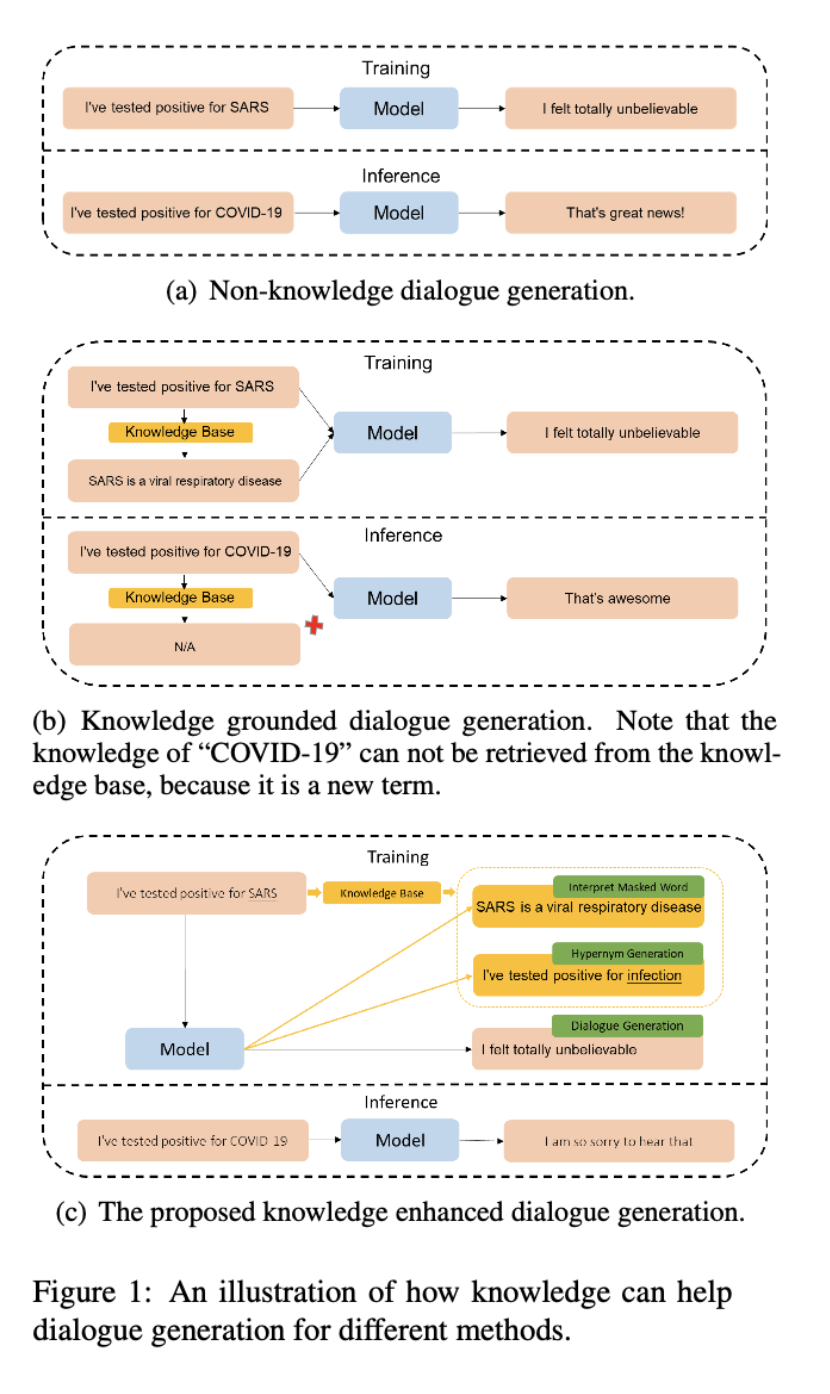
从1a中可以看出,不在知识库中的实体COVID-19虽然与SARS语意接近,但模型推理给出了完全不同的生成结果。
1b中引入外部知识库,但由于COVID-19是比较新的词语,在外部知识库中无法检索得到,生成结果仍然错误。
1c中引入两个子任务辅助训练,预测Masked wordv并预测SARS的上位词得到infection。测试未知实体COVID-19时模型效果有所提升。
方法(模型)
Knowledge Enhanced Blender (KE-Blender)
TASK
Blender
训练集结构:
其中$U^S_i, K^S_i, R^S_i$分别表示,对话上下文、从知识库中检索到的外部知识和回应。
测试集没有外部知识,因为在推理过程中很难实时获取未见过词的相关背景知识。
目标:
$P(R|U; θ)$ with the help of $K^S$
- 外部知识 K 不作为输入。
对话上下文:
Response:
句子的隐藏层表示:
在解码器的第t步中,$h^{enc}$和先前的输出token $y_{1:t-1}$ 作为输入,使用注意生成表示:
y_t 的概率分布:
$W^o$ and $b^o$ are trainable parameters.
使用标准最大似然估计优化模型参数 θ
Given a training pair (U, R)
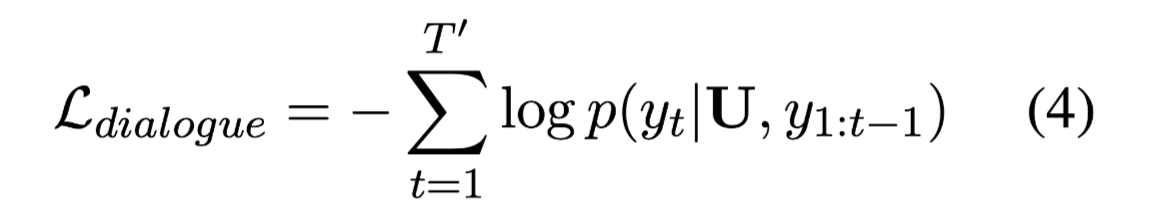
Knowledge Grounded Blender(KG-Blender)
KG-Blender中将 对话上下文U 和 外部知识 K 作为输入。

与Blender相比,损失函数稍有不同:
Given a training pair (U, K, R)
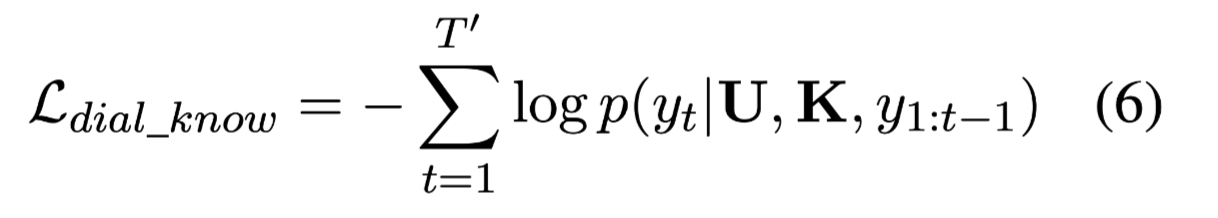
当知识不可用时,很难直接使用KG-Blender,因为KG-Blender 依赖知识作为输入。
Knowledge Enhanced Blender(KE-Blender)
辅助任务详细介绍
Interpret Masked Word:
根据上下文预测单词的定义,其中定义是从知识库获得的。
- mask proper nouns(专有名词) or pre-defined topic word for specific dataset.
- 找到masked word的外部知识。
- 然后,要求预先训练的模型通过使用被屏蔽的话语作为输入来恢复masked word定义。
具体操作可以看下方公式:
signal utterance
$x_j$表示单词。
$x_i$ 是utterance $u_{l−1}$ 的topic word,相关定义:
将topic word mask掉作为输入:
损失函数:
Given a training pair $(u^{‘}{l−1}, K{x_i})$
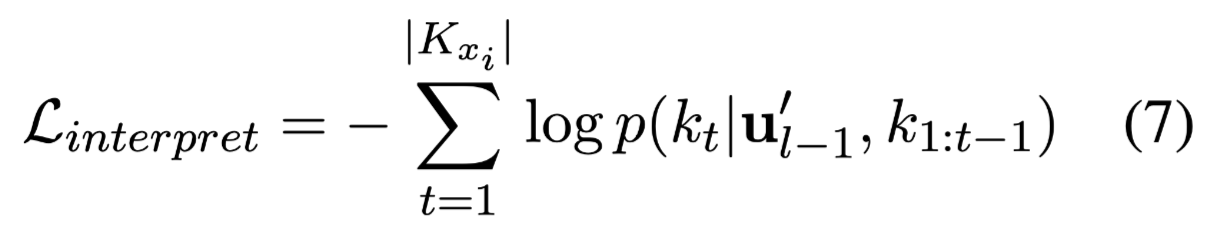
Hypernym Generation
预测WordNet给出的单词的相关上位词。
$u_{l−1}$= {I submit a paper to the EMNLP}
从WordNet中替换EMNLP为 上位词 conference。
$u^{‘}_{l−1}$= {I submit a paper to the conference}
损失函数:
Given a training pair $(u{l−1}, u^{‘’}{l−1})$
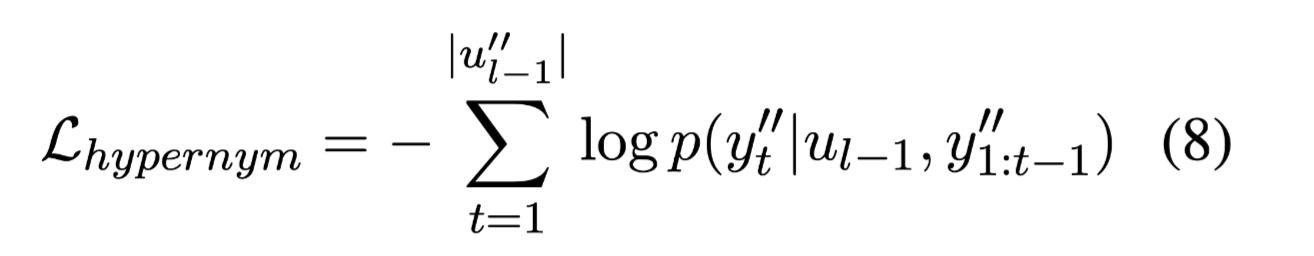
联合损失:
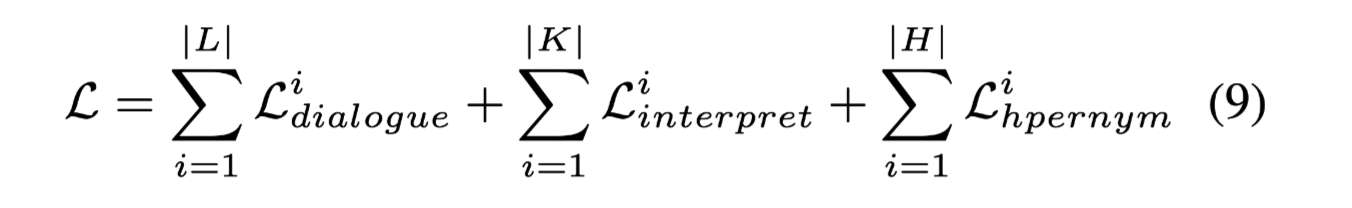
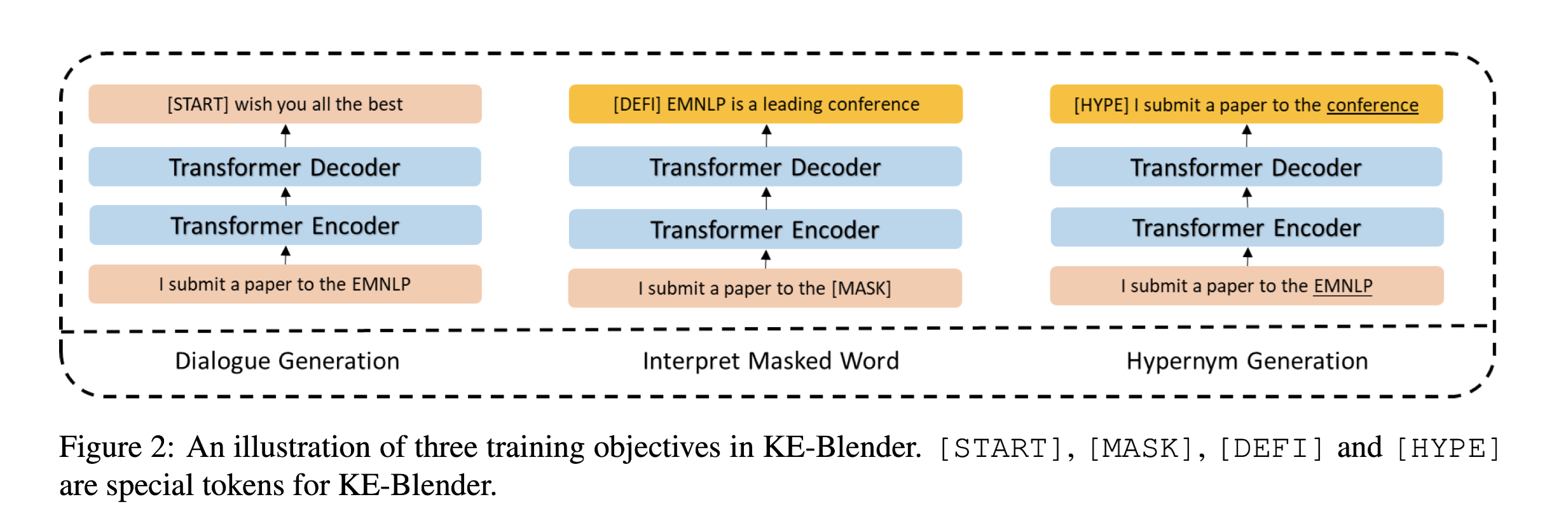
给个例子更直观的解释上面三部分。
这两个辅助任务强迫模型在训练期间从外部知识库学习更丰富的语义知识,根据上下文更好的猜测unseen entity的含义,生成更相关的对话。这两个训练目标都不需要进一步的人工标记,这为扩展到大规模的预训练提供了可能。
相对于利用命名实体或知识库来增强预训练编码器的方法,本文在给定unseen word的情况下注入知识来提高seq2seq模型的生成能力。
数据集
- Wizard of Wikipedia
- Reddit Trendings
Reddit Trendings面板包含最新的热门话题,大部分都不包含在外部知识库中。
性能水平
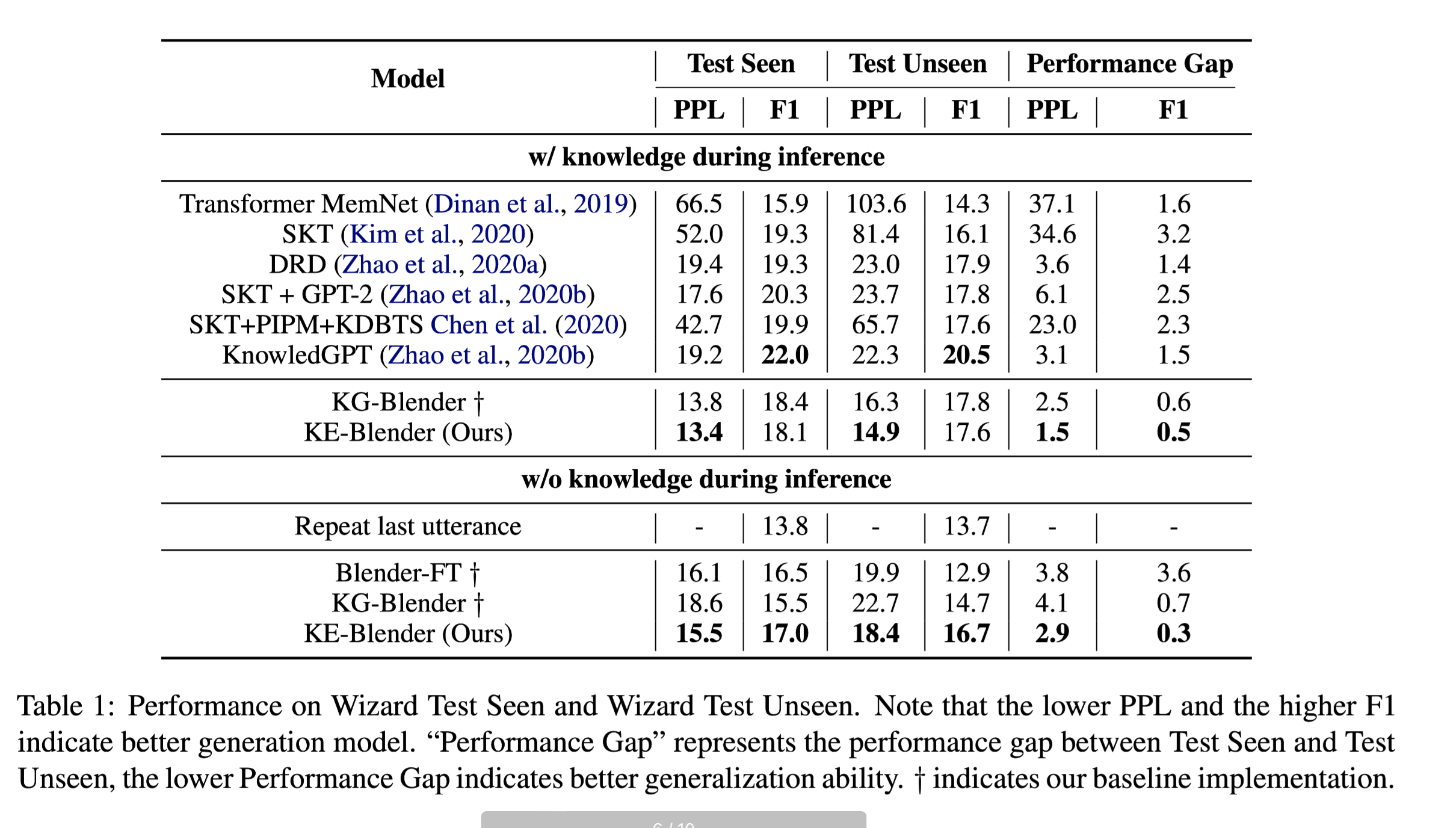
PPL:困惑度

masked word 和 上位词预测样例。
结论
为了更好地处理基于未见词的响应生成,本文提出了KE-Blender,它使模型在推理过程中无需外部知识就能生成有知识的响应。为了将知识显式地注入到模型中,提出了两个训练目标,包括解释屏蔽词和生成上位词。Wizard和Reddit趋势的结果显示,KE-Blender在外部知识可用和不可用的情况下都优于几种最先进的方法和强大的基线。