

Python求解回归问题
Python求解回归问题y=wx+b
12import numpy as npimport matplotlib.pyplot as plt
12345678910# 计算给定(w,b)的平均误差def compute_error_for_line_given_points(b, w, points): totalError = 0 for i in range(0, len(points)): x = points[i, 0] y = points[i, 1] # computer mean-squared-error totalError += (y - (w * x + b)) ** 2 # average loss for each point return totalError / float(len(points))
12345678910111213141516171819def step_gradient(b_current, w_current, points, learningRate) ...
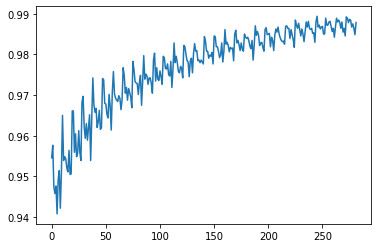
TensorFlow实现手写数字识别
TensorFlow实现手写数字识别123import tensorflow as tffrom tensorflow.keras import datasets, layers, optimizers, Sequential, metricsimport matplotlib.pyplot as plt
12345678910111213# 设置GPU使用方式# 获取GPU列表gpus = tf.config.experimental.list_physical_devices('GPU')print(gpus)if gpus: try: # 设置GPU为增长式占用 for gpu in gpus: tf.config.experimental.set_memory_growth(gpu, True) except RuntimeError as e: # 打印异常 print(e)
[]
加载数据集
12345678(xs, ys),_ = datasets.mnist.load_data() #自动下载print ...
TensorFlow学习笔记(一)TensorFlow基础
TensorFlow学习笔记(一)TensorFlow基础1234567import tensorflow as tfimport tensorflow.keras as kerasimport tensorflow.keras.layers as layers# physical_devices = tf.config.experimental.list_physical_devices('GPU')# assert len(physical_devices) > 0, "Not enough GPU hardware devices available"# tf.config.experimental.set_memory_growth(physical_devices[0], True)
数据类型数值类型标量在 TensorFlow 是如何创建的
123456# python 语言方式创建标量a = 1.2 # TF 方式创建标量aa = tf.constant(1.2)type(a), type(aa), tf.is_tensor( ...
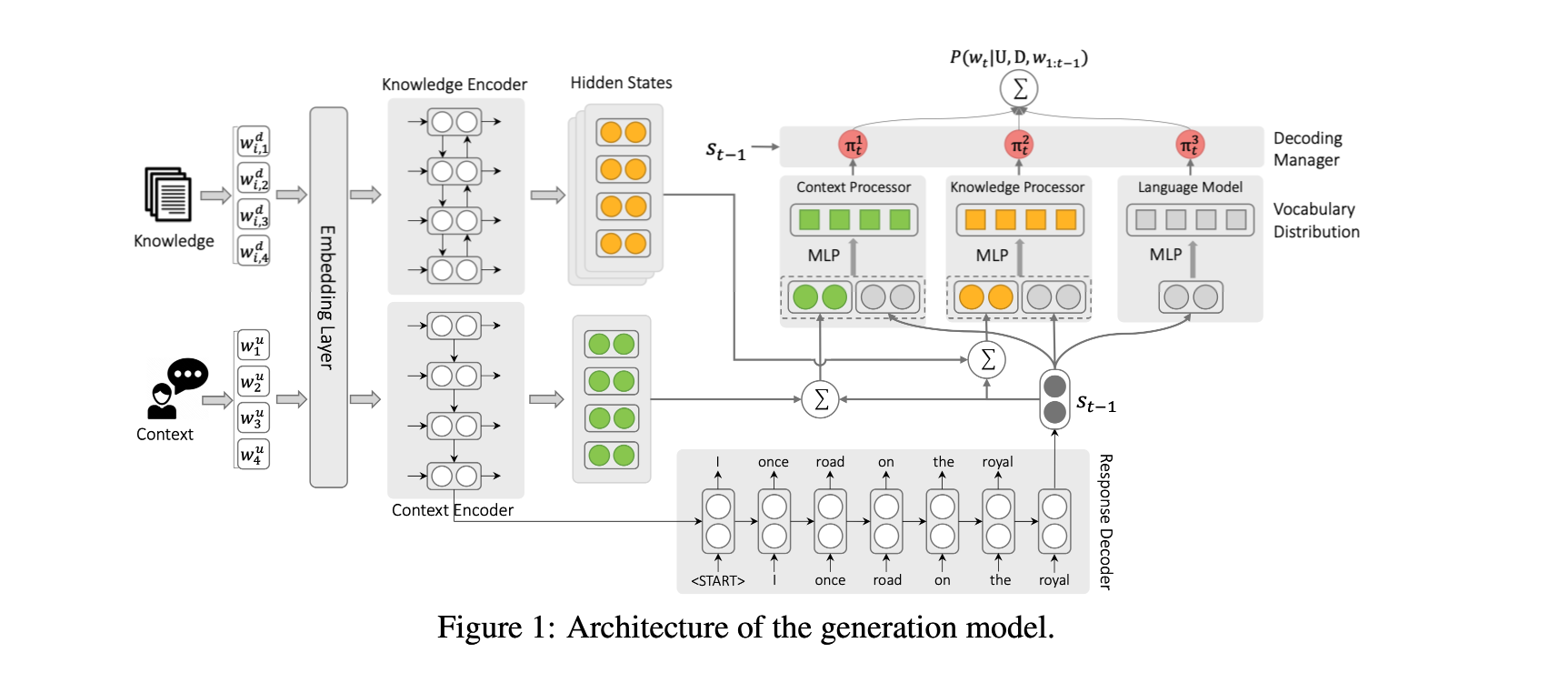
Low-Resource Knowledge-Grounded Dialogue Generatio
Low-Resource Knowledge-Grounded Dialogue Generatio
论文:https://arxiv.org/abs/2002.10348
任务以知识为基础的对话,作为反应生成模型的训练数据,很难获得。本文在有限的训练数据下,进行以知识为基础的对话生成。
在这项工作中,专注于以文档为基础的对话生成,但所提出的方法实际上为低资源知识为基础的对话生成提供了一个通用的解决方案,其中的知识可以是结构化的知识库、图像或视频。要做到这一点,只需要修改知识编码器和知识处理器,使其与特定类型的知识兼容,并预先训练知识编码器。
方法(模型)在低资源环境下,设计了一个分解反应解码器(disentangled response decoder),以便从整个生成模型中分离出依赖于knowledge-grounded的对话的参数。通过这种方式,模型的主要部分可以从大量无基础的对话和非结构化文档中学习,而剩余的小参数则可以用有限的训练实例很好地拟合。
贡献:
在低资源环境下探索以知识为基础的对话生成
提出了用无基础的对话和文档对以知识为基础的对话生成模型进行预训练的建议
在 ...
ubuntu开启ssh服务远程登录
ubuntu开启ssh服务远程登录1. 查看当前的ubuntu是否安装了ssh-server服务。默认只安装ssh-client服务dpkg -l | grep ssh
2. 安装ssh-server服务sudo apt-get install openssh-server
然后确认ssh-server是否启动了:
ps -e | grep ssh
如果看到sshd那说明ssh-server已经启动了。如果没有则可以这样启动:
sudo /etc/init.d/ssh start或sudo service ssh start
3. 登陆SSH(Linux)ssh username@192.168.1.103其中,username为192.168.1.103机器上的用户,需要输入密码。断开连接:exit
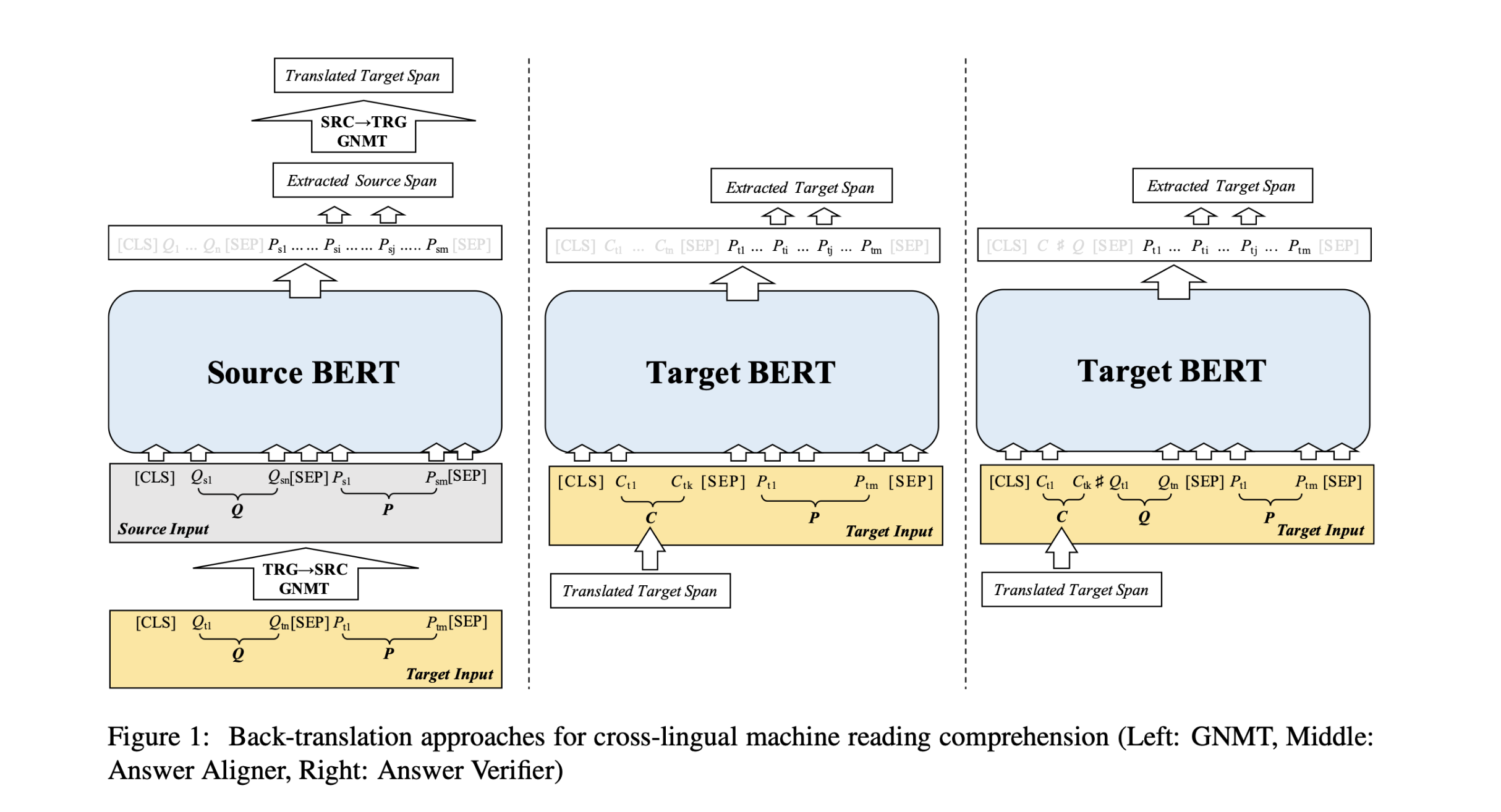
Cross-Lingual Machine Reading Comprehension
Cross-Lingual Machine Reading Comprehension
论文:https://arxiv.org/abs/1909.00361
代码:https://github.com/ymcui/Cross-Lingual-MRC
任务
虽然机器阅读理解研究得到了飞速发展,多数工作面向的是英文数据,而忽略了机器阅读理解在其他语言上的表现,其根本原因在于大规模训练数据的缺失。本文提出跨语言机器阅读理解(Cross-Lingual MachineReading Comprehension,CLMRC)任务来解决非英文下的机器阅读理解。
本文所提出的方法具有良好的通用性,可适配多种机器阅读理解任务。在本文中将着重解决基于篇章片段抽取的机器阅读理解(Span-Extraction MRC),这也是目前在该领域中研究最为广泛的任务之一。该任务需要对<篇章,问题>进行建模,并从篇章中抽取出一个连续的片段作为答案。最广为熟知的是由斯坦福大学提出的SQuAD(Stanford Question Answering Dataset)数据集。
利用英文(源语言)数据来 ...

使用sklearn对文档进行向量化的程序
使用sklearn对文档进行向量化的程序12345678910# -*- coding: utf-8 -*-"""演示内容:文档的向量化"""from sklearn.feature_extraction.text import CountVectorizercorpus = ['Jobs was the chairman of Apple Inc., and he was very famous','I like to use apple computer','And I also like to eat apple']
123456#未经停用词过滤的文档向量化vectorizer =CountVectorizer()print(vectorizer.fit_transform(corpus).todense()) #转化为完整特征矩阵print(vectorizer.vocabulary_)print(" ")
[[0 1 1 1 0 0 ...
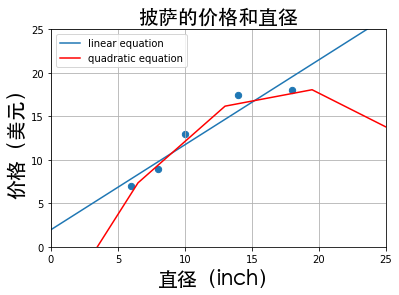
使用sklearn进行线性回归和二次回归的比较程序
使用sklearn进行线性回归和二次回归的比较程序12345678910111213141516171819202122#coding=utf-8"""#演示内容:二次回归和线性回归的拟合效果的对比"""print(__doc__)import numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegressionfrom sklearn.preprocessing import PolynomialFeaturesfrom matplotlib.font_manager import FontPropertiesfont_set = FontProperties(fname=r"/System/Library/Fonts/STHeiti Medium.ttc", size=20) def runplt(): plt.figure()# 定义figure plt.title(u ...

使用sklearn进行量纲缩放的程序
使用sklearn进行量纲缩放的程序1234567891011121314151617181920212223242526# -*- coding: utf-8 -*-"""演示内容:量纲的特征缩放(两种方法:标准化缩放法和区间缩放法。每种方法举了两个例子:简单二维矩阵和iris数据集)"""#方法1:标准化缩放法 例1:对简单示例二维矩阵的列数据进行from sklearn import preprocessing import numpy as np #采用numpy的array表示,因为要用到其mean等函数,而list没有这些函数X = np.array([[0, 0], [0, 0], [100, 1], [1, 1]]) # calculate mean X_mean = X.mean(axis=0) # calculate variance X_std = X.std(axis=0) #print (X_std)# standardize X X ...
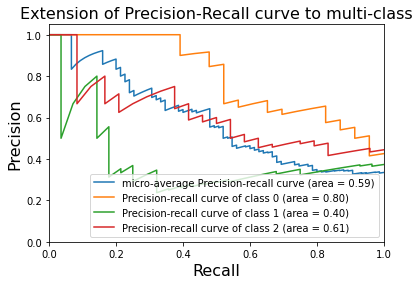
使用Sklearn进行精确率-召回率曲线的绘制
使用Sklearn进行精确率-召回率曲线的绘制
精确率:模型判定的正例中真正正例所占的比重
召回率:总正例中被模型判定为正例的比重
12345#coding=utf-8"""#演示目的:利用鸢尾花数据集画出P-R曲线"""print(__doc__)
#演示目的:利用鸢尾花数据集画出P-R曲线
123456789import matplotlib.pyplot as pltimport numpy as npfrom sklearn import svm, datasetsfrom sklearn.metrics import precision_recall_curvefrom sklearn.metrics import average_precision_scorefrom sklearn.preprocessing import label_binarizefrom sklearn.multiclass import OneVsRestClassifier#from sklearn.cross_validation ...
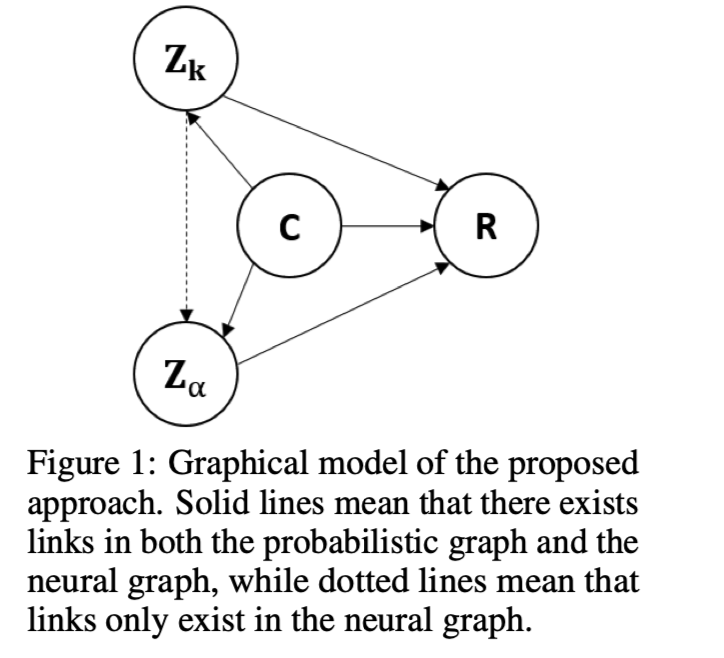
Zero-Resource Knowledge-Grounded Dialogue Generation
Zero-Resource Knowledge-Grounded Dialogue Generation
论文:https://arxiv.org/abs/2008.12918
代码:https://github.com/nlpxucan/ZRKGC
任务神经网络对话模型需要以知识为基础的对话,而这些对话很难获得。为了克服数据方面的挑战并降低构建知识基础对话系统的成本,本文通过假设训练时不需要context-knowledge-response三要素,在零资源环境下探索这个问题。
贡献:
在零资源环境下探索以知识为基础的对话生成;
提出了一个double latent variable model,不仅描述了连接context和response的知识,还描述了知识的表达方式;
提出了一个variational学习方法;
在知识为基础的对话生成的三个基准上对所提方法的有效性进行了经验验证。
方法(模型)本文提出将连接context 和response的知识以及知识的表达方式表现为潜在变量,并设计了一种variational方法,可以有效地从对话语料和知识语料中估计出一个相互独立的生 ...

Zero-Resource Knowledge-Grounded Dialogue Generation
Zero-Resource Knowledge-Grounded Dialogue Generation
论文:https://arxiv.org/abs/2008.12918
代码:https://github.com/nlpxucan/ZRKGC
任务神经网络对话模型需要以知识为基础的对话,而这些对话很难获得。为了克服数据方面的挑战并降低构建知识基础对话系统的成本,本文通过假设训练时不需要context-knowledge-response三要素,在零资源环境下探索这个问题。
贡献:
在零资源环境下探索以知识为基础的对话生成;
提出了一个double latent variable model,不仅描述了连接context和response的知识,还描述了知识的表达方式;
提出了一个variational学习方法;
在知识为基础的对话生成的三个基准上对所提方法的有效性进行了经验验证。
方法(模型)本文提出将连接context 和response的知识以及知识的表达方式表现为潜在变量,并设计了一种variational方法,可以有效地从对话语料和知识语料中估计出一个相互独立的生 ...
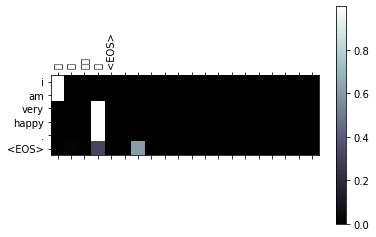
用注意力机制实现中英文互译
用注意力机制实现中英文互译
[KEY: > input, = target, < output]
il est en train de peindre un tableau .= he is painting a picture .< he is painting a picture .
pourquoi ne pas essayer ce vin delicieux ?= why not try that delicious wine ?< why not try that delicious wine ?
elle n est pas poete mais romanciere .= she is not a poet but a novelist .< she not not a poet but a novelist .
导入需要的模块及数据
12345678910111213141516from __future__ import unicode_literals, print_function, divisionfrom io imp ...
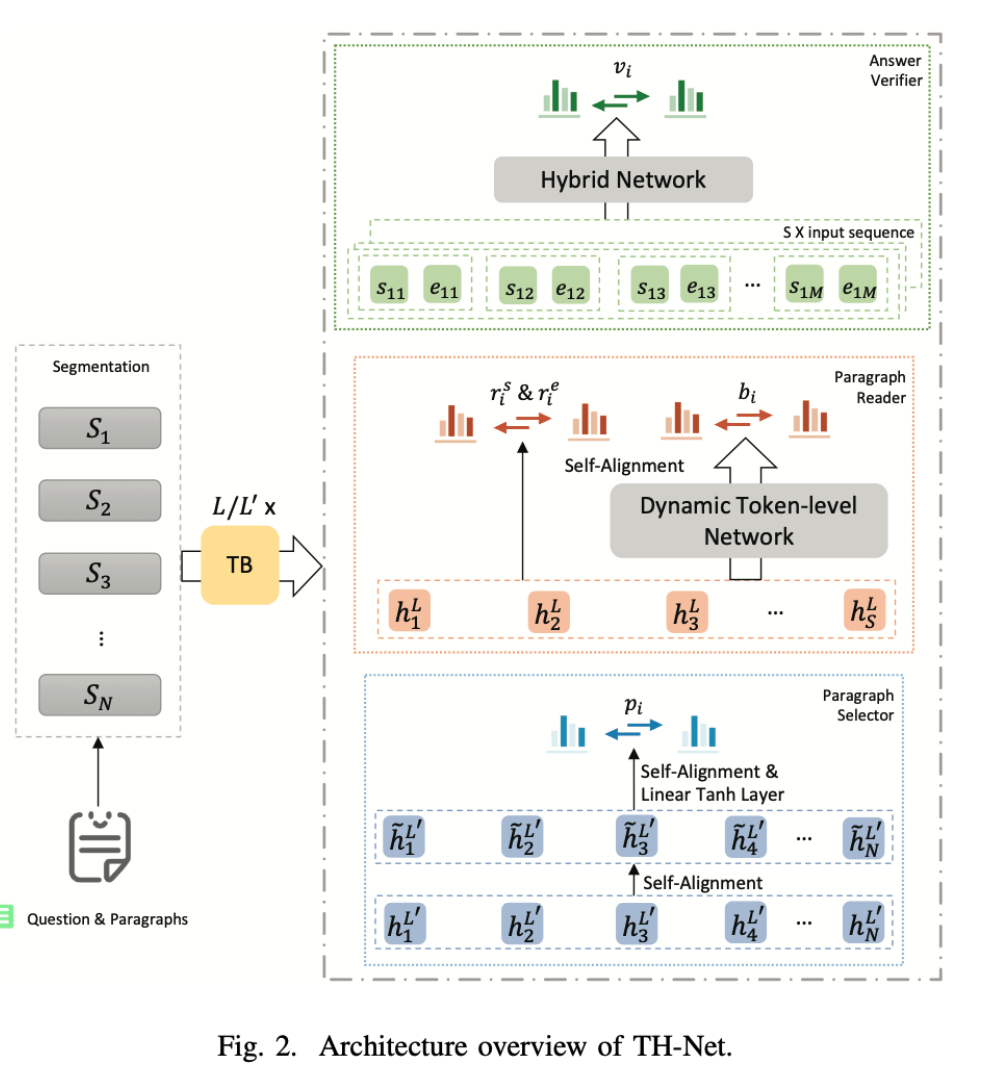
Multi-paragraph Reading Comprehension with Token-level Dynamic Reader and Hybrid Verifier
Multi-paragraph Reading Comprehension with Token-level Dynamic Reader and Hybrid Verifier
论文:http://vigir.missouri.edu/~gdesouza/Research/Conference_CDs/IEEE_WCCI_2020/IJCNN/Papers/N-20242.pdf
任务多段式阅读理解要求模型通过推理跨段落信息来推断任意用户生成的问题的答案。以前的工作通常通过直接采用指针网络预测答案的开始和结束位置来生成答案。然而,对于跨度级别的阅读理解是不够的,因为中间的词可能更重要。本文提出了一个统一的网络,包括一个选择器,一个token级动态阅读器,和一个混合验证器(TH-Net)。本文侧重于解决文档级数据而不是单段数据的挑战。
方法(模型)提出了token级动态阅读器和混合验证器,以避免边界和内容的相似性。
模型结构:
采用统一的方法(Unified approach),通过共享相同的上下文嵌入来提高三个组件的整体性能。这三个部分由预训练的LM初始化,并在训练过程中同时 ...

