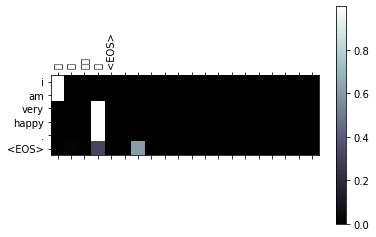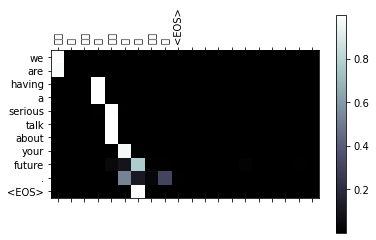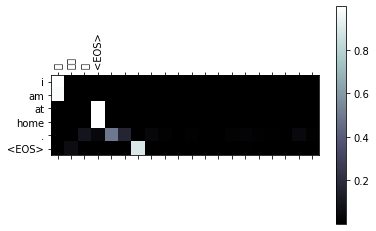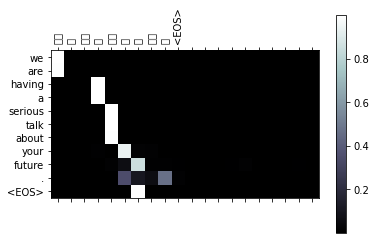il est en train de peindre un tableau . = he is painting a picture . < he is painting a picture .
pourquoi ne pas essayer ce vin delicieux ? = why not try that delicious wine ? < why not try that delicious wine ?
elle n est pas poete mais romanciere . = she is not a poet but a novelist . < she not not a poet but a novelist .
导入需要的模块及数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from __future__ import unicode_literals, print_function, division from io importopen import unicodedata import string import re import random import jieba import torch import torch.nn as nn from torch import optim import torch.nn.functional as F
import matplotlib.font_manager as fm myfont = fm.FontProperties(fname='/Users/maqi/opt/anaconda3/lib/python3.8/site-packages/matplotlib/mpl-data/fonts/ttf/DejaVuSans.ttf')
classLang: def__init__(self, name): self.name = name self.word2index = {} self.word2count = {} self.index2word = {0: "SOS", 1: "EOS"} self.n_words = 2# Count SOS and EOS
defaddSentence(self, sentence): for word in sentence.split(' '): self.addWord(word) defaddSentence_cn(self, sentence): for word inlist(jieba.cut(sentence)): self.addWord(word)
defaddWord(self, word): if word notin self.word2index: self.word2index[word] = self.n_words self.word2count[word] = 1 self.index2word[self.n_words] = word self.n_words += 1 else: self.word2count[word] += 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# 为便于数据处理,把Unicode字符串转换为ASCII编码
defunicodeToAscii(s): return''.join( c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn' )
# 对英文转换为小写,去空格及非字母符号等处理
defnormalizeString(s): s = unicodeToAscii(s.lower().strip()) s = re.sub(r"([.!?])", r" \1", s) #s = re.sub(r"[^a-zA-Z.!?]+", r" ", s) return s
Reading lines...
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/7t/wvjcfn5575g892qb2nqbd9kw0000gn/T/jieba.cache
Read 21007 sentence pairs
Trimmed to 640 sentence pairs
Counting words...
Loading model cost 0.571 seconds.
Prefix dict has been built succesfully.
Counted words:
cmn 1063
eng 808
['他很穷。', 'he is poor .']
1
pairs[:3]
[['我冷。', 'i am cold .'], ['我沒事。', 'i am okay .'], ['我生病了。', 'i am sick .']]
if use_teacher_forcing: # Teacher forcing: Feed the target as the next input for di inrange(target_length): decoder_output, decoder_hidden, decoder_attention = decoder( decoder_input, decoder_hidden, encoder_outputs) loss += criterion(decoder_output, target_tensor[di]) decoder_input = target_tensor[di] # Teacher forcing
else: # Without teacher forcing: use its own predictions as the next input for di inrange(target_length): decoder_output, decoder_hidden, decoder_attention = decoder( decoder_input, decoder_hidden, encoder_outputs) topv, topi = decoder_output.topk(1) decoder_input = topi.squeeze().detach() # detach from history as input
loss += criterion(decoder_output, target_tensor[di]) if decoder_input.item() == EOS_token: break
loss.backward()
encoder_optimizer.step() decoder_optimizer.step()
return loss.item() / target_length
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
import time import math
defasMinutes(s): m = math.floor(s / 60) s -= m * 60 return'%dm %ds' % (m, s)
deftimeSince(since, percent): now = time.time() s = now - since es = s / (percent) rs = es - s return'%s (- %s)' % (asMinutes(s), asMinutes(rs))
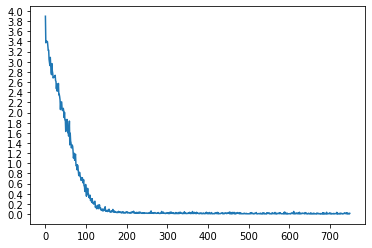
loss = train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion) print_loss_total += loss plot_loss_total += loss
> 今天下午我會外出。
= i am going out this afternoon .
< i am going out this afternoon . <EOS>
> 我相信他是無辜的。
= i am convinced that he is innocent .
< i am convinced that he is innocent . <EOS>
> 他在自己房里玩。
= he is playing in his room .
< he is playing in his room . <EOS>
> 我來自四國。
= i am from shikoku .
< i am from shikoku . <EOS>
> 她戴著一頂帽子。
= she is wearing a hat .
< she is wearing a hat . <EOS>
> 您非常勇敢。
= you are very courageous .
< you are very brave . <EOS>
> 他有几分像学者。
= he is something of a scholar .
< he is something of a scholar . <EOS>
> 你真傻。
= you are so stupid .
< you are so stupid . <EOS>
> 他年紀夠大可以瞭解它。
= he is old enough to understand it .
< he is old enough to understand it . <EOS>
> 你別小看了他。
= you are selling him short .
< you are selling him short . <EOS>
input = 我很幸福。
output = i am very happy . <EOS>
<ipython-input-23-2d6791f485ef>:9: UserWarning: FixedFormatter should only be used together with FixedLocator
ax.set_xticklabels([''] + list(jieba.cut(input_sentence)) +
<ipython-input-23-2d6791f485ef>:11: UserWarning: FixedFormatter should only be used together with FixedLocator
ax.set_yticklabels([''] + output_words)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 25105 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 24456 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 24184 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 31119 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 12290 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 25105 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 24456 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 24184 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 31119 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 12290 missing from current font.
font.set_text(s, 0, flags=flags)
input = 我们在严肃地谈论你的未来。
output = we are having a serious talk about your future . <EOS>
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 20204 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 22312 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 20005 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 32899 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 22320 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 35848 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 35770 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 20320 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 30340 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 26410 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 26469 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 20204 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 22312 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 20005 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 32899 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 22320 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 35848 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 35770 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 20320 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 30340 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 26410 missing from current font.
font.set_text(s, 0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 26469 missing from current font.
font.set_text(s, 0, flags=flags)
input = 我在家。
output = i am at home . <EOS>
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:240: RuntimeWarning: Glyph 23478 missing from current font.
font.set_text(s, 0.0, flags=flags)
/Users/maqi/opt/anaconda3/envs/mq_env/lib/python3.8/site-packages/matplotlib/backends/backend_agg.py:203: RuntimeWarning: Glyph 23478 missing from current font.
font.set_text(s, 0, flags=flags)
input = 我们在严肃地谈论你的未来。
output = we are having a serious talk about your future . <EOS>