

最优化方法
最优化方法极小点判定条件凸函数:Hessen矩阵 半正定 (正定时为严格凸函数)
凹函数:Hessen矩阵 半负定
线性规划线性规划的目标函数等值面是平行平面。
标准线性规划
主约束都是右端项非负的等式约束
结果要不是 最优解 要不是 解无界。(不会出现 无解)
标准线性规划有容许解,则必有基本容许解。
若有最优解,则必有最优基本容许解。
典范线性规划I阶段线性规划或存在最优基本容许解(W=0),或 原问题无解(W>0)。
典范线性规划 或者 解无界 或者 有最优解 不会出现无解的情况。
第一阶段
解辅助线性规划,目的是求标准线性规划 主约束的一个 G-J方程组
第二阶段
解标准线性规划,即解原线性规划
单纯形
本质上是解典范线性规划的算法
根本目标是让人工变量全部退基
具有有限终止性
自由变量 $x_1 = x_2 -x_3$
最优性检验最大判别数$\delta _l$
最优解 $\delta _l \leq 0$
无界 $\delta _l \gt 0 $ $a_l \leq0$ 异号
无解 第一阶段 最优值 $w>0$
$\del ...

CLeQA 模型实现
CLeQA 模型实现环境部署12345678910111213141516conda create -n cleqa python=3.7conda install pytorch torchvision torchaudio cudatoolkit=10.1 -c pytorch# 或者pip3 install torch torchvision torchaudiopip install transformers# wbcpip3 install torch==1.7.1+cu110 torchvision==0.8.2+cu110 -f https://download.pytorch.org/whl/cu110/torch_stable.html
Knowledge Enhanced Fine-Tuning for Better Handling Unseen Entities in Dialogue Generation
Knowledge Enhanced Fine-Tuning for Better Handling Unseen Entities in Dialogue Generation
EMNLP2021
论文:https://arxiv.org/abs/2109.05487
代码:https://github.com/nealcly/ke-blender
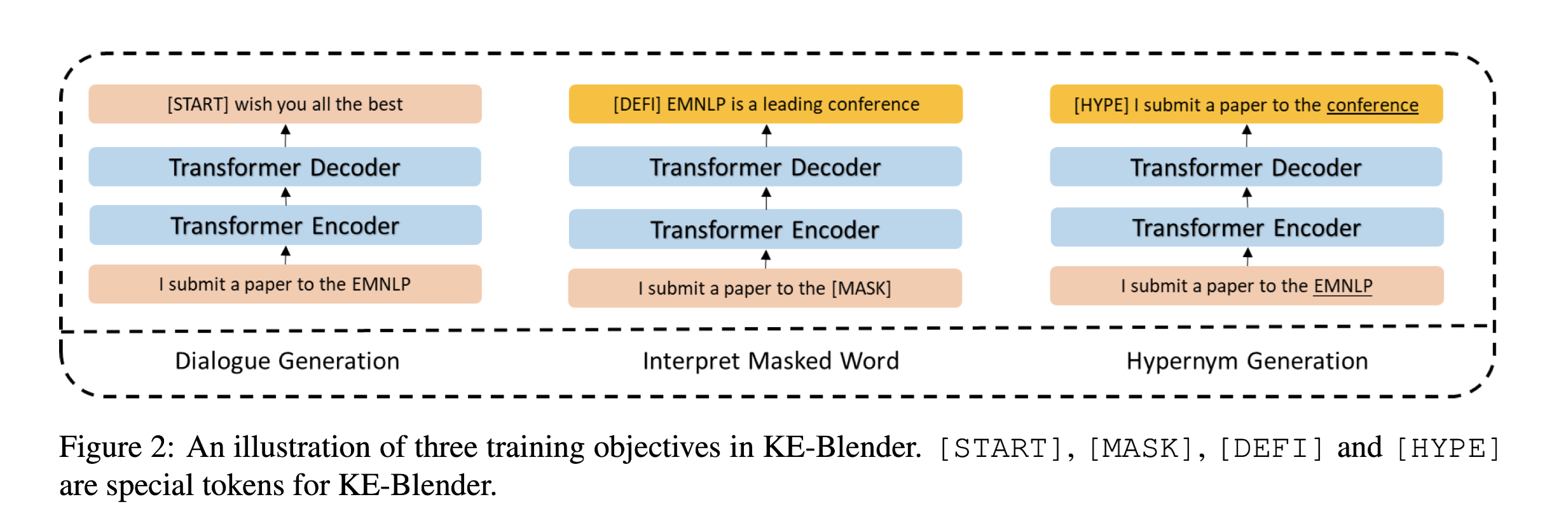
任务预训练模型在对话生成方面取得了很大的成功,但当输入包含预训练和微调数据集中没有出现的实体(unseen entity)时,它们的性能会显著下降。为了解决这个问题,现有的方法利用外部知识库来生成适当的响应。在现实场景中,实体可能不被知识库所包含,或者受到知识检索精度的影响。为了解决这个问题,本文不再引入知识库作为输入,而是只根据输入上下文,通过预测知识库中的信息来强迫模型学习更好的语义表示。
具体来说,在知识库的帮助下,引入了两个辅助训练目标:
解释masked word:在给定上下文的情况下猜测masked entity 的含义。例如“I want to submit a paper to EMNLP”,一般情况下,有人可能不知道 ...

Heterogeneous Graph Attention Network
Heterogeneous Graph Attention Network
Heterogeneous graph Attention Network, named HAN
异构图注意力网络
heterogeneous graph which contains different types of nodes and links
homogeneous graph which includes only one type of nodes or links
heterogeneous information network (HIN)Meta-path, a composite relation connecting two objects, is a widely used structure to capture the semantics
论文:
代码:
任务异构图中包含不同的节点和边,GNN做的还不够完善。由于异质图的复杂性,传统的图神经网络不能直接应用于异构图。本文提出了一种新的异构图神经网络分层注意力机制,涉及到节点级别和语义级别。节点级别的Attention主要学习 ...
Knowledge Generation MRC模型复现
Knowledge Generation MRC模型复现扩展知识
哈工大 RoBERTa-wwm-ext, Chinese https://github.com/ymcui/Chinese-BERT-wwm
环境配置
conda
12conda create -n mq_mrc python=3.6source activate mq_mrc
PyTorch
pytorch 官网 自动安装cudnn
https://pytorch.org/get-started/locally/
123456conda install pytorch cudatoolkit=10.1 -c pytorch# 官方版conda install pytorch torchvision torchaudio cudatoolkit=10.1 -c pytorch# 测试:import torch torch.cuda.is_available()
conda 报错可以试试pip
1pip3 install torch torchvision torchaudio
!不使用 py ...
A Hierarchical Network for Abstractive Meeting Summarization with Cross- Domain Pretraining
A Hierarchical Network for Abstractive Meeting Summarization with Cross- Domain Pretraining
论文:A Hierarchical Network for Abstractive Meeting Summarization with Cross- Domain Pretraining
代码:https://github.com/JudeLee19/HMNet-End-to-End-Abstractive-Summarization-for-Meetings
非官方但比较简洁易懂的代码
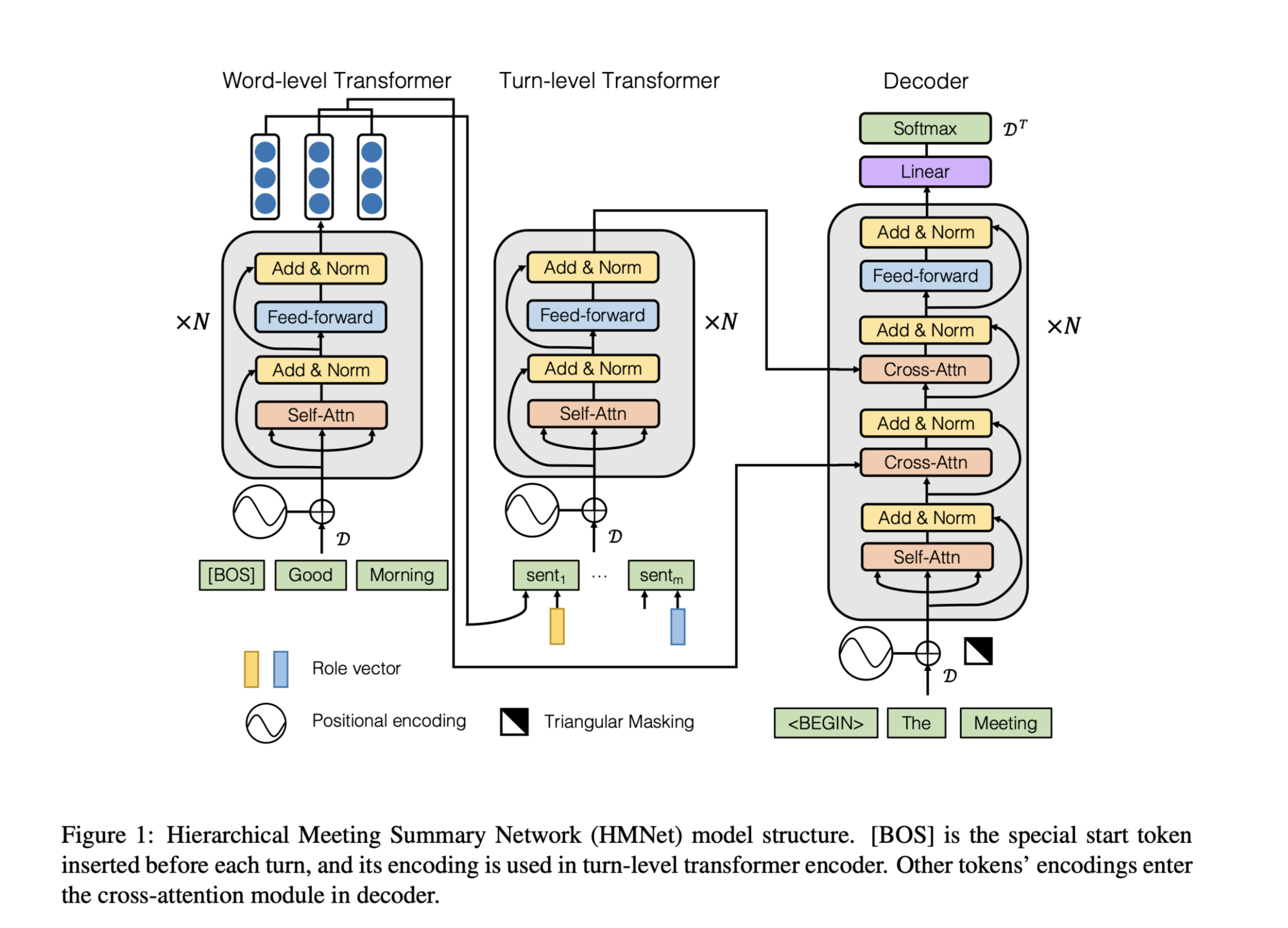
任务传统的会议总结方法依赖于复杂的multi-step pipelines,使得联合优化难以实现,并且会议记录的语义结构和风格与文章和对话有很大不同。本文提出了一个新颖的abstractive summary network,以适应会议的场景。
传统模型需要复杂的多阶段机器学习管道,如模板生成、句子聚类、多句子压缩、候选句子生成和排名。由于这些方法不是端到端的可优化的,因此很难联合改进管道中的各个部分以提高整 ...
NLP的一些评价指标
NLP的一些评价指标ROUGEROUGE 指标的全称是 (Recall-Oriented Understudy for Gisting Evaluation),主要基于召回率。ROUGE 是一种常用的机器翻译和文章摘要评价指标,由 Chin-Yew Lin 提出。它通过将自动生成的摘要或翻译与一组参考摘要(通常是人工生成的)进行比较计算,得出相应的分值,以衡量自动生成的摘要或翻译与参考摘要之间的“相似度”。
4 种 ROUGE 方法:
ROUGE-N: 在 N-gram 上计算召回率。
ROUGE-L: 考虑了机器译文和参考译文之间的最长公共子序列(长度越长,得分越高,基于F值。)
ROUGE-W: 改进了ROUGE-L,用加权的方法计算最长公共子序列。
计算公式
ROUGE-N:
其中,$n$ 表示n-gram,$Count(gramn)$表示一个n-gram的出现次数,$Count{match}(gram_n)$ 表示一个n-gram的共现次数。
ROUGE-L:
其中, $X$表示候选摘要,$Y$表示参考摘要, $LCS(X,Y)$ 表示候选摘要与参考摘要的最长公 ...

Hugging Face 在线查看NLP数据集
Hugging Face 在线查看NLP数据集
官网:https://huggingface.co
Hugging Face在github上开源的自然语言处理,预训练模型库 Transformers, 提供了NLP领域大量state-of-art的 预训练语言模型结构的模型和调用框架。地址:https://github.com/huggingface/transformers
仓库名称的变迁过程:pytorch-pretrained-bert —> pytorch-transformers —> transformers
在知乎发现一篇十分详尽的入门教程:https://zhuanlan.zhihu.com/p/120315111
进制转换
进制转换
昨天做leetcode的每日一题,进制转换的时候突然联想到了辗转相除法,再跟室友交流之后才弄明白辗转相除法是求最大公约数的,为了捋清楚进制转换问题,在这篇博客里用两种方法解决。
背景:405. 数字转换为十六进制数
给定一个整数,编写一个算法将这个数转换为十六进制数。对于负整数,我们通常使用 补码运算 方法。
连除取余法
这个方法比较常规 一直取余数 最后将余数倒着输出就好啦
123456789101112131415class Solution: def toHex(self, num: int) -> str: CONV = "0123456789abcdef" ans =[] # 32位二进制数 转成十六进制 共8位 4*8 for _ in range(8): temp = num % 16 num = num//16 ans.append(temp) if not num: ...
Automatically Learning Data Augmentation Policies for Dialogue Tasks
Automatically Learning Data Augmentation Policies for Dialogue Tasks
论文:Automatically Learning Data Augmentation Policies for Dialogue Tasks
代码:https://github.com/WolfNiu/AutoAugDialogue
任务
AutoAugment算法主要应用在CV领域,本文调整AutoAugment算法应用在对话任务上。
自动数据增强(AutoAugment)通过使用目标任务上的采样策略的性能奖励训练的控制器搜索最佳扰动策略,从而减少data-level模型的偏差。
本文调整了AutoAugment,以自动发现自然语言处理(NLP)任务的effective perturbation policies(有效扰动策略),如对话生成。
还探索了以目标任务的源输入为条件的控制器,因为某些策略可能不适用于不包含该策略所需语言特征的输入。
方法(模型)从一个原子操作池开始,对对话任务的源输入进行微妙的语义保护性扰动(例如,不同的POS- ...
SEQUENTIAL LATENT KNOWLEDGE SELECTION FOR KNOWLEDGE-GROUNDED DIALOGUE
SEQUENTIAL LATENT KNOWLEDGE SELECTION FOR KNOWLEDGE-GROUNDED DIALOGUE
论文:https://arxiv.org/abs/2002.07510
代码:https://github.com/bckim92/sequential-knowledge-transformer
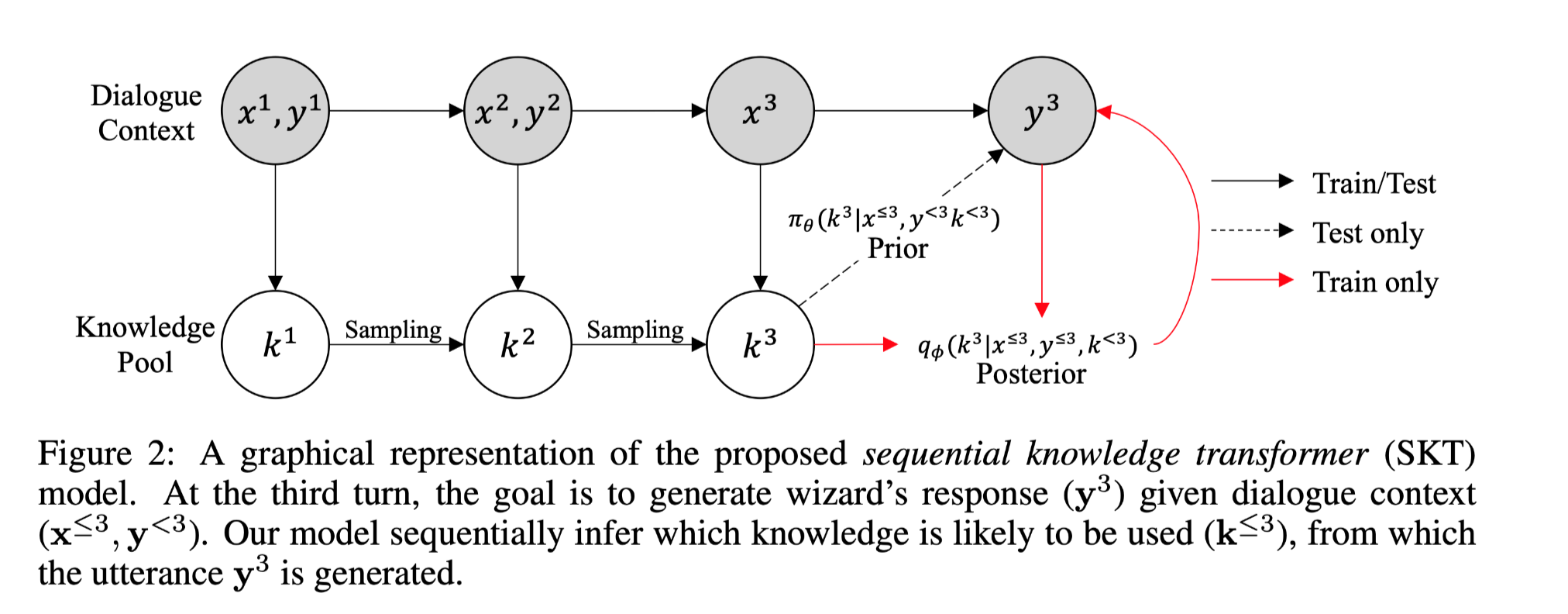
任务以知识为基础的对话是一项基于话语背景和外部知识产生信息性反应的任务。
提出sequential latent variable model(sequential knowledge transformer (SKT))更好地模拟多轮知识为基础的对话中的知识选择,该模型可以跟踪知识的先验和后验分布;因此,不仅可以减少对话中知识选择的多样性造成的模糊性,还可以更好地利用响应信息来正确选择知识。
方法(模型)主要贡献:
本文提出了sequential knowledge transformer (SKT)模型。该模型是第一次尝试利用顺序潜变量模型进行知识选择,随后改善以知识为基础的对话。
实验结果表明,所提出的模型不仅提高了知识选择的准确性,而且 ...

TensorFlow常用操作
指定GPU
终端指定
1CUDA_VISIBLE_DEVICES=0 nohup python demo.py >> base_log.out 2>&1 &
程序指定
12import osos.environ["CUDA_VISIBLE_DEVICES"] = "1"
TensorFlow常用操作检测GPU是否可用12import tensorflow as tftf.test.is_gpu_available()
使用TensorFlow实现LSTM
使用TensorFlow实现LSTM使用Cell实现123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125# 以Cell方式实现LSTM# %%import osimport numpy as npimport tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layers, losses, optimizers, Sequential# 指定GPUos.environ["CUDA_VISIBLE_DEVICE ...
使用TensorFlow实现RNN
使用TensorFlow实现RNN使用Cell实现123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137# 以cell方式实现RNN# %%import osimport numpy as npimport tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layers, losses, optimizers, Sequential# 指定GPUos ...