Read before Generate! Faithful Long Form Question Answering with Machine Reading
Read before Generate! Faithful Long Form Question Answering with Machine Reading
论文:https://aclanthology.org/2022.findings-acl.61.pdf
会议:ACL2021
飞书:https://zlc6vppbrn.feishu.cn/docx/P45VdH0vmosFNMxwMyxc3R5Anif
任务
长文本问答 (LFQA) 旨在为给定问题生成段落长度的答案。当前使用大型预训练模型生成的LFQA工作可以有效地产生流畅且较为相关的内容,但对长文本问答来说,不同的文档可能包含冗余,互补或矛盾的信息,主要的挑战在于如何生成具有较少空洞内容的高置信度(faithful)答案。
关键思想:本文提出了一个新的端到端框架,该框架对答案生成和机器阅读进行联合建模,使用与答案相关的细粒度的显著信息来增强生成模型,这些信息可以被视为对事实的强调。
a fluent and relevant but unfaithful answer:
unfaithful answer 会误导读者
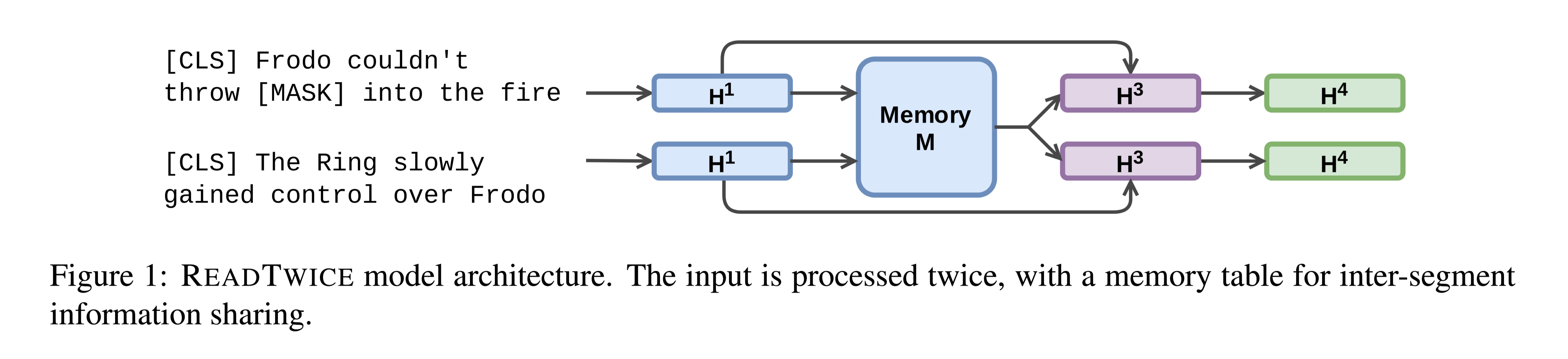
方法(模型)
本文将基于Seq2Seq的生成器与机器阅读理解 (reader) 模块相结合。reader会为每个句子生成作为证据的概率得分,该分数将与生成器集成在一起,用于最终的分布预测。
模型结构:
为了对给定的通用领域问题生成深入的长答案,首先使用检索器从大量的外部知识中检索相关信息。然后,reader和generation模块将多个检索到的文档以及问题作为输入以生成答案。
reader模块: 为每个文档中的每个句子计算证据得分。
generator模块: 采用预训练的Seq2Seq语言模型,将句子证据得分融合到其生成过程中。
Supporting document retriever
使用DPR检索相关文档
retriever根据文档的相关性对文档进行排名:
对于问题Q,使用 $D = {D_1,D_2, …,D_k}$表示top-k相关文档。
Document reader
由于没有用于长答案的标注标签,因此检索到的文档可能包含与答案相关的补充,矛盾或冗余信息。因此,使用阅读器模块来预测每个文档中句子的证据概率。
Evidence span prediction
输入: $D_i \& Q$
输出: $D_i$中可能是evidence spans的开始和结束位置,每个输出token有两个概率分布, $P^s_i (w_s) \ and \ P^e _i (w_s)$,分别表示token $w_s$作为头和尾token的概率
Sentence evidence probability
句子级的概率更适合长文本任务,支持句可以为每个答案跨度提供所需的最小上下文信息,这一点非常重要,尤其是在多文档生成中。
文档中第i个句子的概率表示为 $P^i_{ rea}(S)$,由该句子中所有token的证据概率加和得到。
$P_{rea}(S)$:表示经过归一化后,所有top-k句子的证据概率
Multi-task MRC
由于LFQA数据没有gold answer span,因此选择SpanBert在MRQA,sQuAD,NewsQA,TriviaQA,SearchQA,HotpotQA,NatualQuestions上进行多任务微调,在下游任务上实现远程监督训练。
Generator
FiD-BART
选择BART作为生成任务的backbone,本文提出FiD-BART(Fusion-in-Decoder),以使BART能够处理多个长文档输入。FiD-BART在编码器中独立处理每个文档,同时在解码器中联合执行交叉注意力。
- Encoder
$h{enc}^i$:文档 $D_i$作为encoder输入得到的最后一层隐藏层表示
$h{enc}$:top-k文档encoder输出的拼接
- Decoder
$hl$:表示decoder的第l层
$h{dec}$:表示decoder的最后一层输出
计算时间与输入数量线性相关
Reader-before-generator
使用指针网,将证据概率融入到生成过程中。
$A$:attention分布
$hc$:上下文向量
$p{gen}$:生成概率
$W_c,W_g$:可训练参数
$p_{gen}$用于选择:
- 生成器从vocab中采样单词(词表)
- 根据证据分布 $P_{rea}(w)$从输入序列复制单词(输入序列)
Pre-training
为了进一步提高检索文档的能力,提出了retrieval-augmented recovery (RAR)预训练任务,期望模型能够依赖更多的外部知识生成事实性陈述。
任务定义:
给定原始文本:S
从外部知识(BM25)中检索top-k文档: $D_1,D_2, …,D_N$
构造伪查询Q:替换S中30%的单词为[MASK]
任务:使用伪查询Q和top-k文档恢复S
数据集
- LI5
- 唯一可公开获得的大规模LFQA数据集
- 272,634个train样例和1,507个dev样例
- 答案平均长度130个单词
- MS MARCO
- 来自Bing查询
- 本文使用passage ranking track训练模型,该赛道比NLG更加抽象,并且更依赖多文档信息。
- train样例大约500,000,dev样例6980
性能水平
评价指标:
F1 score and ROUGE-L
模型性能
Fine-grained Comparison
将MARCO数据集按照检索到的文档质量拆分为不同的子集,验证文档的质量对生成质量的影响。
RBG在完整MS-MARCO评估集中Rouge-L只比FiD领先0.1,但从表3中可以看出,随着评估子集检索质量的提高,性能差距继续增加。表明RBG在提供高质量的检索文档时更加有效。
消融实验
文档质量对生成结果的影响
- 检索得到的高质量文档能够提高生成质量
- 检索的文档并不是越多越好
Zero-shot on extractive QA tasks
评价指标:模型生成的长答案中是否包含NQ和HotpotQA中的短答案
模型在需要综合复杂信息的问题上生成faithful答案的能力更强。
结论
主要贡献:
- 本文是截至当前第一个尝试解决LFQA中的faithful挑战的人。
- 为开放域LFQA提出了一个新的端到端框架,该框架在reader模块的句子证据得分的指导下生成答案。
- 本文的方法可以提高生成答案的事实正确性,同时仍保持较高的信息性。