Multi-span Style Extraction for Generative Reading Comprehension
Multi-span Style Extraction for Generative Reading Comprehension
论文:https://arxiv.org/abs/2009.07382
代码:https://github.com/chunchiehy/musst
会议:AAAI-2021
飞书:https://zlc6vppbrn.feishu.cn/docx/doxcnnIj90LvJt2BV33MMNyEKbh
任务
生成式机器阅读理解(MRC)的答案通常分布在输入问题和文档中,正确答案由单个或多个片段组成。对于答案为单个片段的MRC任务通常称为抽取式MRC,并且已有大量性能优异的single-span抽取模型,但当场景切换到生成式任务时通常会产生不完整的答案或引入多余的词,因此本文的目标是将single-span提取方法扩展到multi-span,使用生成式MRC的方法解决multi-span的QA问题。
方法(模型)
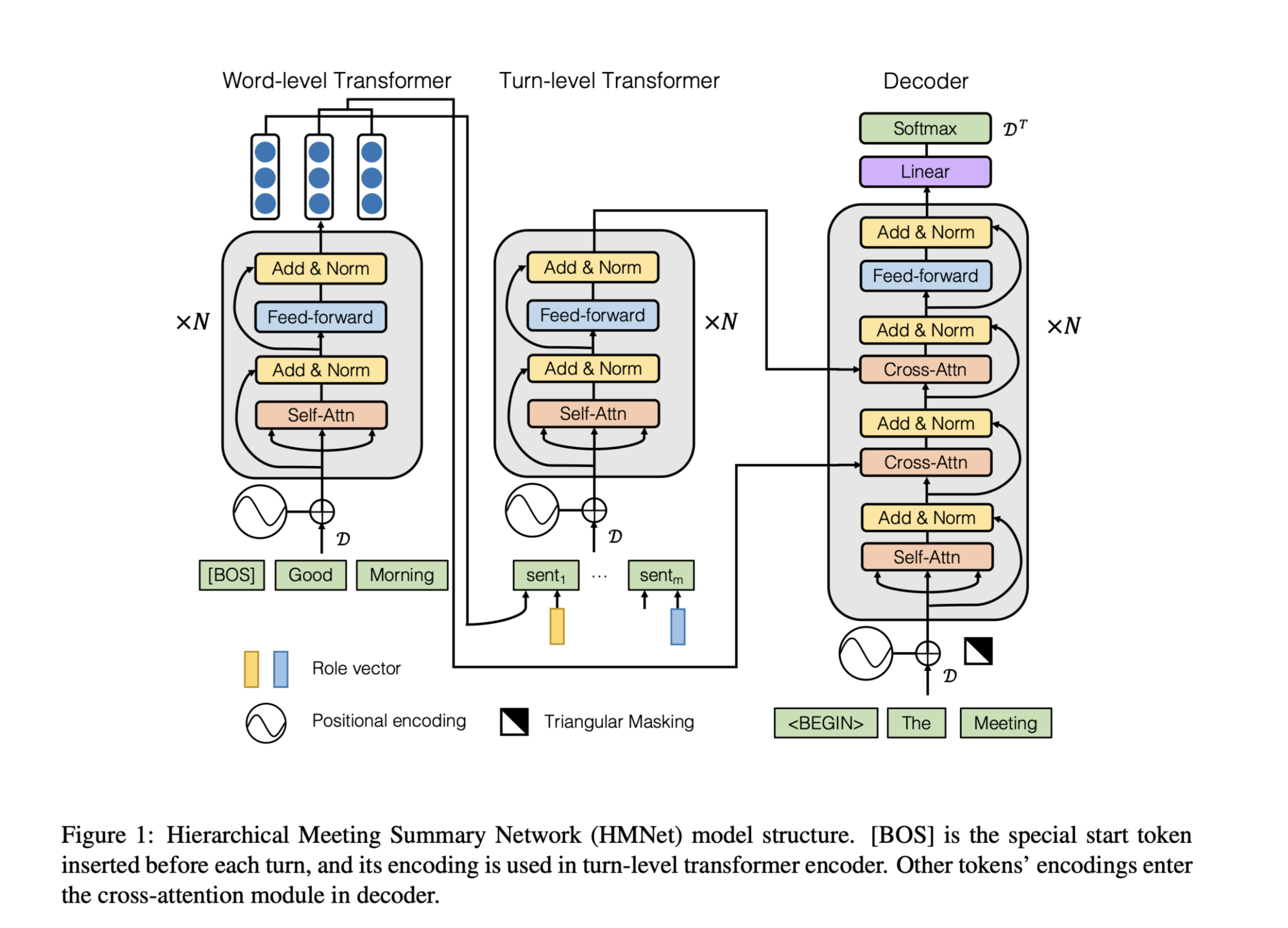
MUSST for MUlti-Span STyle extraction
由3个模块组成:passage ranker, multi-span answer annotator, question-answering module
Passage ranker
问题定义:
表示在给定问题Q时,P可能包含答案的概率分布, θ是模型参数。
输入形式:$[CLS]\ Q\ [SEP]\ P_i \ [SEP]$
使用最后一层的[CLS]作为输入的聚合表示。
Ranker:
使用两个全连接层作为预测模块,表示问题和段落的相关性。
其中$r_i,u_i$分别表示问答对$(Q, P_i)$的相关度和非相关度,s是一个二维向量。
对同一个问题Q,计算所有段落的相关性并作了如下的归一化:
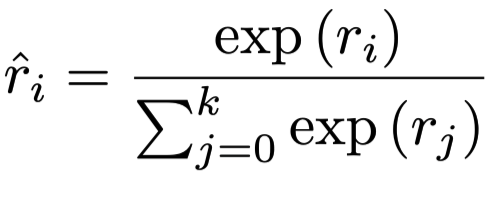
损失函数:
T:训练集中问题的总数
r():表示相关性得分
u():表示非相关性得分
训练过程中,每个问题Q都有n个question-passage pair组成候选集合,正例表示为与问题相关的段落,负例则从集合中随机采样未选中的question-passage pair。
trick:
动态采样:在每个epoch训练开始时重采样了负例,以避免在每个epoch对问题使用相同的训练样例。
Question-answering module
问题定义:
给定Q和P计算答案A的概率分布$P(y|Q, P) $。
Question-passage reader:
reader的结构设计与ranker类似,都是用预训练模型当encoder,不同的是ranker只用到了[CLS],而reader用到了最后一层的所有输出做预测:
Multi-span style answer generator:
token作为头尾的概率:
Training and inference:
这里值得学习的是,在预处理时加入了一个virtual span,跨度为整个输入序列,这种方法使模型能够在预测期间生成多种答案跨度,virtual span作为停止符。
损失函数:
选span的依据是头尾span乘积最大。
为了缓解生成span重复问题,在每个预测时间步j时,模型在计算token新的开始和结束位置的概率分布时mask掉之前时间步的预测过的span位置。
数据集
MS MARCO v2.1 dataset
性能水平
结论
本文提出的多跨度提取框架(MUSST),能够缓解生成式模型生成不完整答案或引入单跨度提取模型遇到的冗余单词的问题。并且在只有ranker分类器的支持下,模型性能也不错,可以看出,段落重排序任务是比较重要的。