Graph Convolutional Networks for Text Classification
Graph Convolutional Networks for Text Classification
论文:https://arxiv.org/abs/1809.05679
代码:https://github.com/yao8839836/text_gcn
会议:AAAI 2019
任务
文本分类是自然语言处理中一个重要的经典问题。有许多研究将卷积神经网络应用于分类。然而,只有有限的研究探索了更灵活的图卷积神经网络来完成这项任务。在这项工作中,使用图卷积网络进行文本分类。
方法(模型)
基于单词共现和文档-单词关系为语料库构建单个文本图,然后为语料库训练文本图卷积网络(Text-GCN)。Text-GCN使用word和document的独热表示进行初始化,然后在文档的已知类标签的监督下,联合学习word和document的嵌入。
Graph Convolutional Networks (GCN)
GCN是一个多层神经网络,它直接在图上运行,并根据节点的邻居属性获取节点的嵌入向量。
符号定义:
图$G=(V,E)$
其中$V$和$E$分别是节点和边的集合。
假设每个节点都与自身相连,即$(v,v)∈E$ 。
$X∈ R^{n×m}$:包含所有n个节点及其特征的矩阵,其中m是特征向量的维数。
A:G的邻接矩阵。
D:A的出度矩阵。
GCN只能捕获具有一层卷积的近邻信息。当多个GCN层堆叠时,更大邻域的信息将被聚合。对于单层GCN,新的k-dimensional节点的特征矩阵$L$计算方式如下:
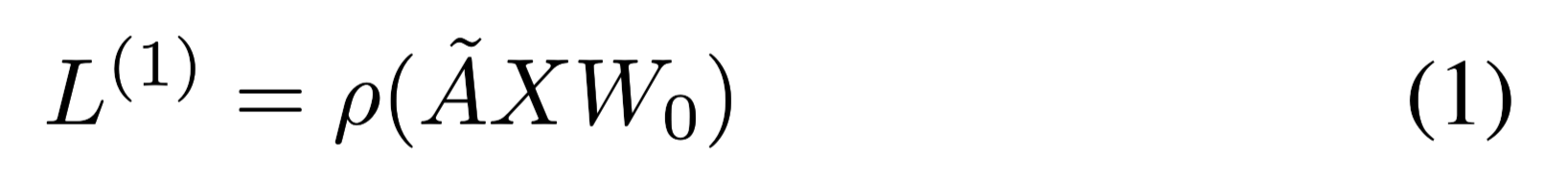
其中
是归一化操作。
ρ:激活函数,本文用的RELU。
堆叠多层GCN:
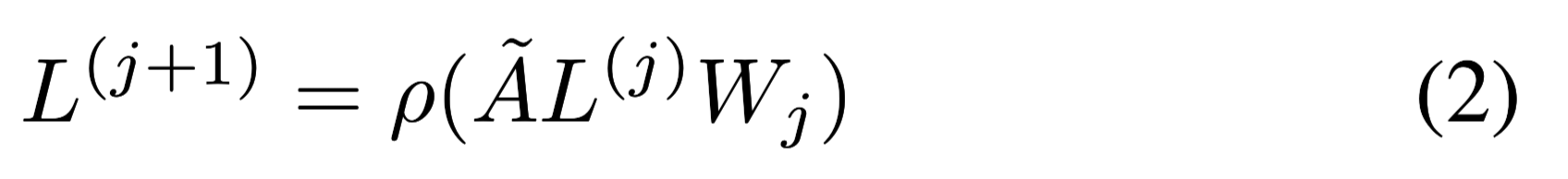
j表示层号。
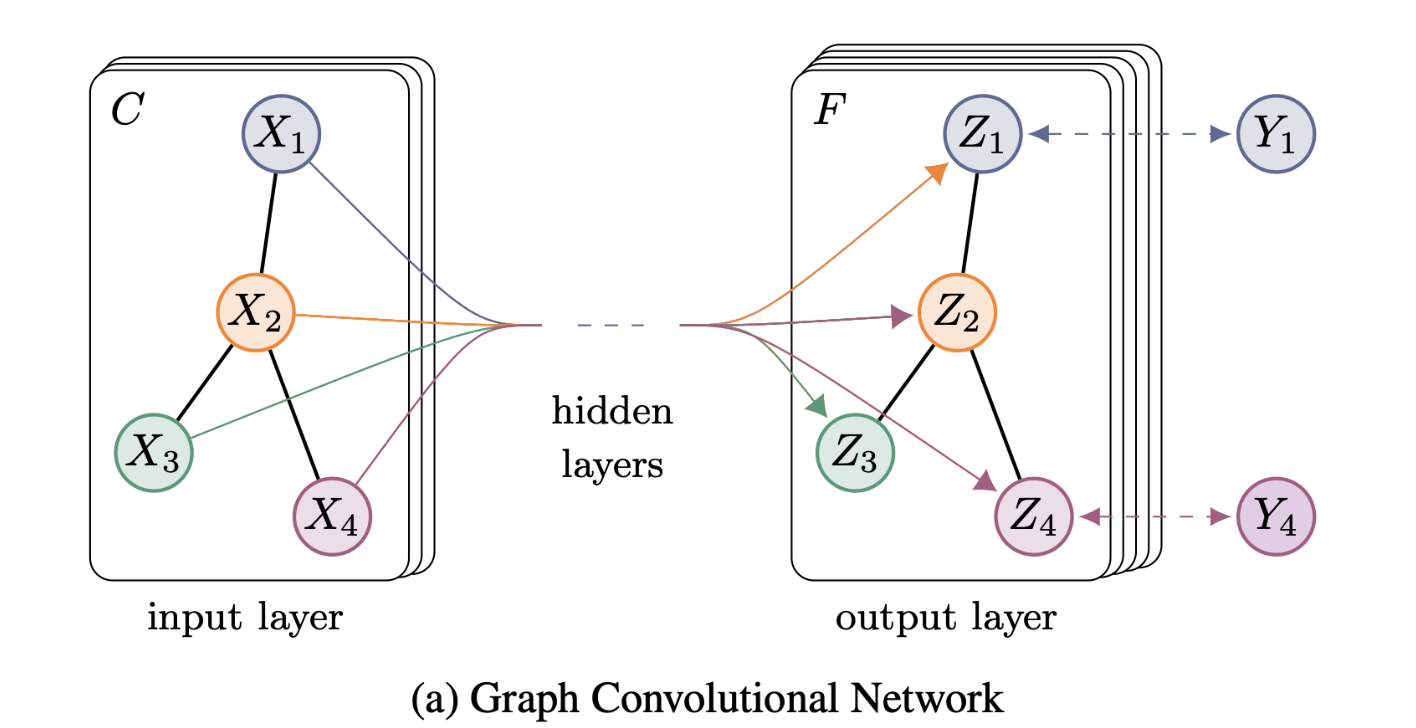
Text Graph Convolutional Networks (Text GCN)
本文构建了一个包含单词节点和文档节点的大型异构文本图,这样可以显式地建模全局单词共现,并且可以轻松地调整图卷积。
模型结构:
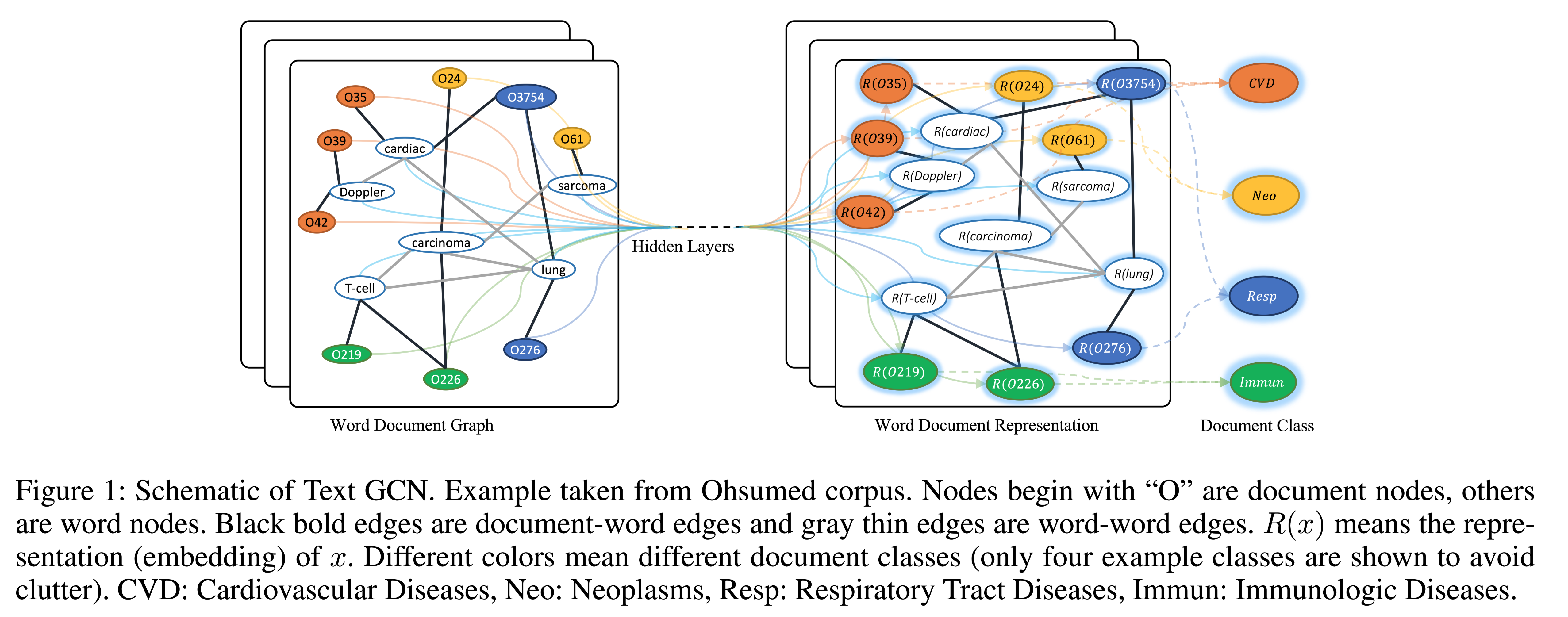
节点定义: 文本图中的节点数$| V |$是文档数(语料库大小)加上不同单词数(词表大小)。
边的定义:document-word edges and word-word edges
文档节点和单词节点之间的边的权重是文档中单词的TF-IDF值。我们发现使用TF-IDF权重比仅使用术语频率更好。为了利用全局词共现信息,对语料库中的所有文档使用固定大小的滑动窗口来收集共现统计信息。我们使用 point-wise mutual information(PMI)来计算两个词节点之间的权重。
PMI是一种常用的词关联度量方法。
正的PMI值意味着语料库中单词的高度语义相关性,而负的PMI值意味着语料库中几乎没有语义相关性。因此,本文只在PMI值为正的词对之间添加边。
在初步实验中,发现使用PMI比使用单词共现计数获得更好的结果。
形式上,节点$i$和节点$j$之间的边的权重定义为:

PMI计算:
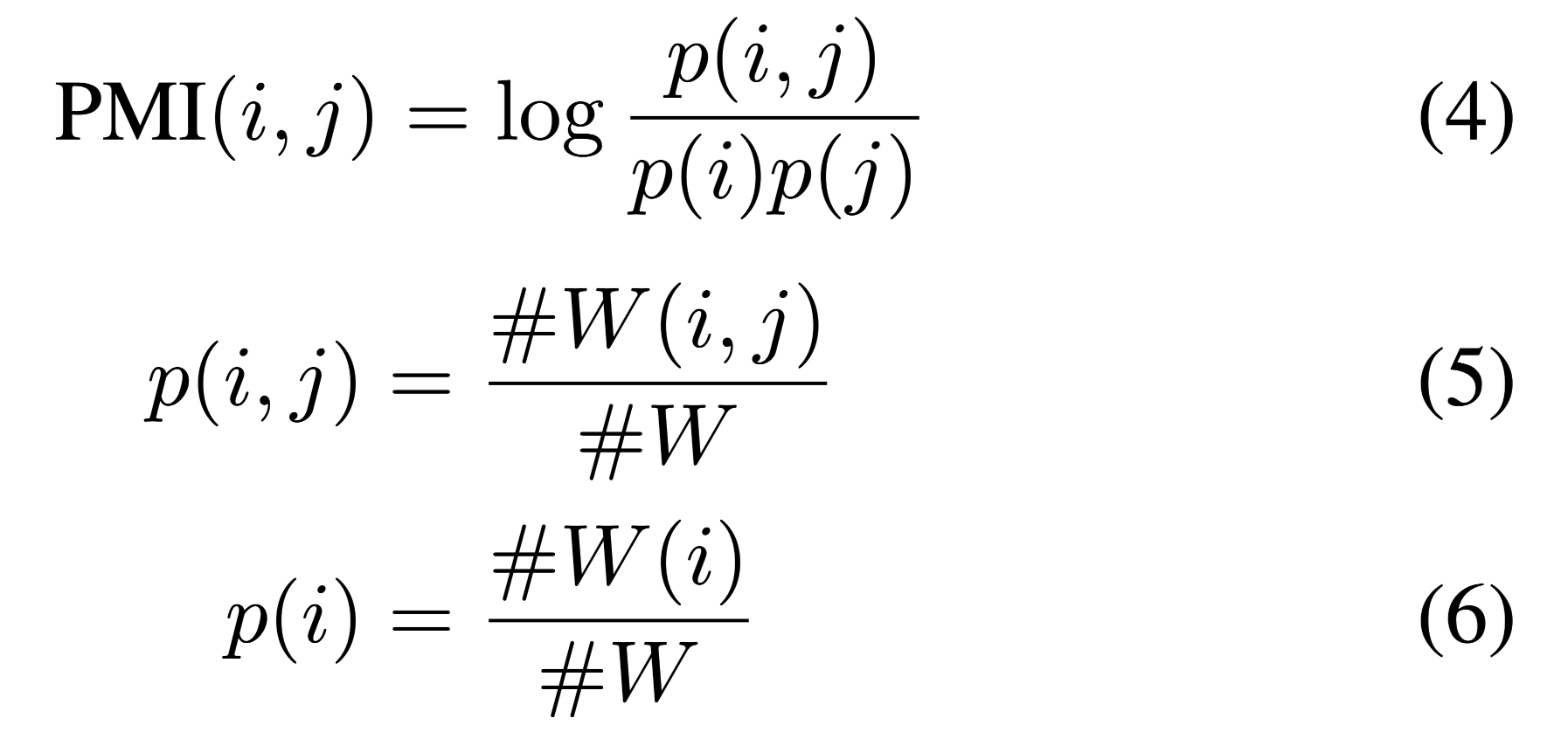
$#W(i)$是语料库中包含单词$i$的滑动窗口数量
$#W(i,j)$是同时包含单词$i,j$的滑动窗口数量
$#W$是滑动窗口的数量
构建好文本图之后输入到两层GCN,通过Softmax分类器做最终分类。
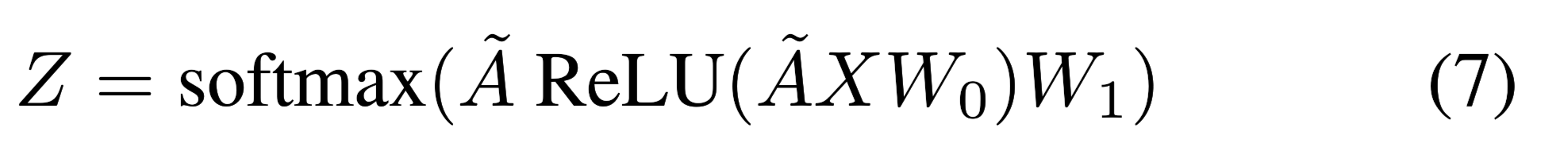
交叉熵损失函数:
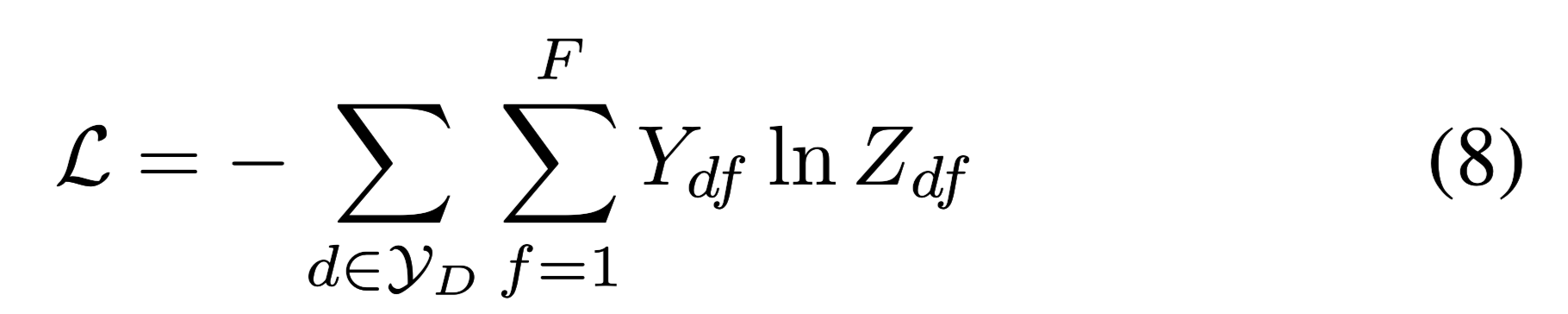
使用两层GCN的解释:
两层GCN允许消息在最多两步之外的节点之间传递。因此,尽管图中没有直接的文档边,但两层GCN允许成对文档之间进行信息交换。在初步实验中
发现,两层GCN的性能优于单层GCN,而多层GCN并不能提高性能。
数据集
20-Newsgroups (20NG)
Ohsumed
R52 and R8 of Reuters(路透社) 21578
Movie Review (MR)
具体数据集的介绍,可以去论文相关部分。
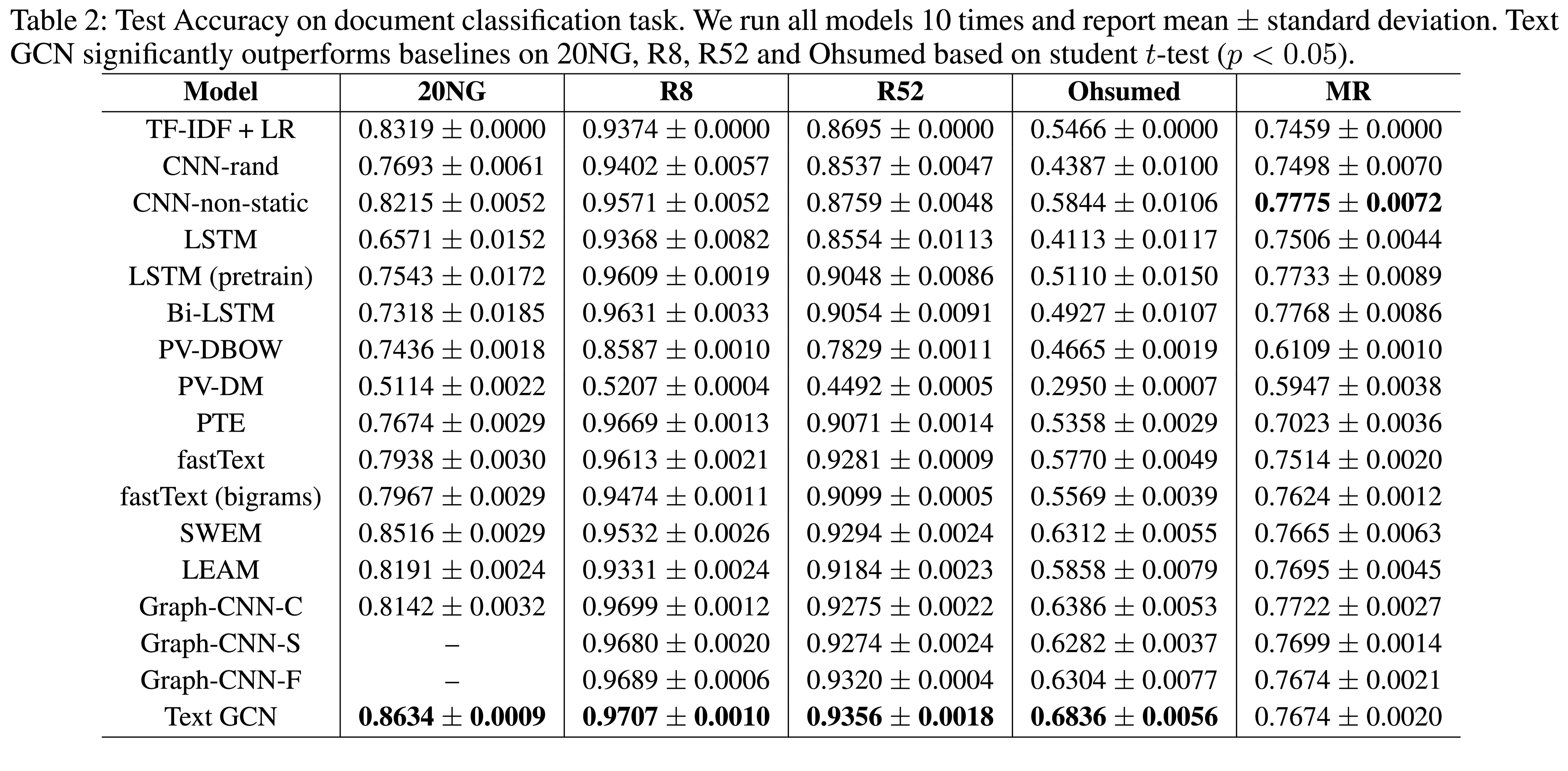
性能水平
结论
本文贡献:
- 提出了一种新的用于文本分类的图神经网络方法。这是第一次将整个语料库建模为一个异构图,并使用图神经网络联合学习单词和文档嵌入的研究。
- 在几个基准数据集上的结果表明,本文的文本分类方法,无需使用预先训练的单词嵌入或外部知识,该方法还可以自动学习预测词和文档嵌入。
此外,实验结果表明,随着训练数据百分比的降低,文本GCN相对于最先进的比较方法的改进变得更加显著,这表明文本GCN对文本分类中较少训练数据的鲁棒性。