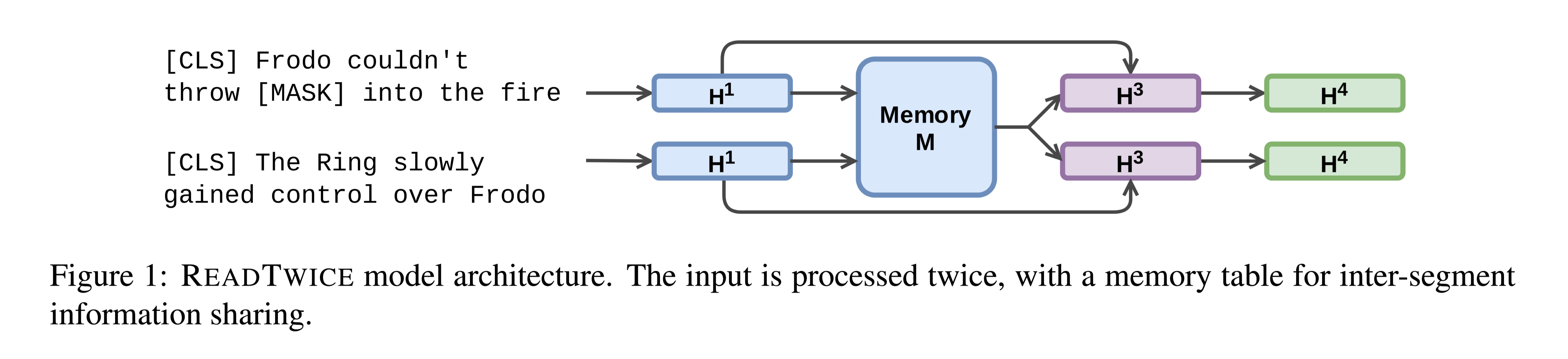
VAULT VAriable Unified Long Text Representation for Machine Reading Comprehension
VAULT: VAriable Unified Long Text Representation for Machine Reading Comprehension
论文:https://arxiv.org/abs/2105.03229
会议:ACL 2021
任务
现有的机器阅读理解(MRC)模型需要复杂的模型体系结构,才能有效地对具有段落表示和分类的长文本进行建模,从而使推理的计算效率不高。在这项工作中,本文提出了VAULT:一种轻量级、并行高效的MRC段落表示方法,基于长文档输入的上下文表示,使用一种新的基于高斯分布的目标进行训练,该目标密切关注ground-truth的部分正确实例。
方法(模型)
传统的QA,模型训练时,答案范围的标注非对即错,过于绝对。实际上,与真实答案重叠的跨度应被视为部分正确。基于此,本文将真实答案跨度的起始和结束位置视为类高斯分布,而不是单点,并使用统计距离优化模型。
模型:VAULT((VAriable Unified Long Text representation),因为它可以在任何位置处理可变数量和长度的段落,使用相同的统一模型结构来处理长文本。
模型结构:
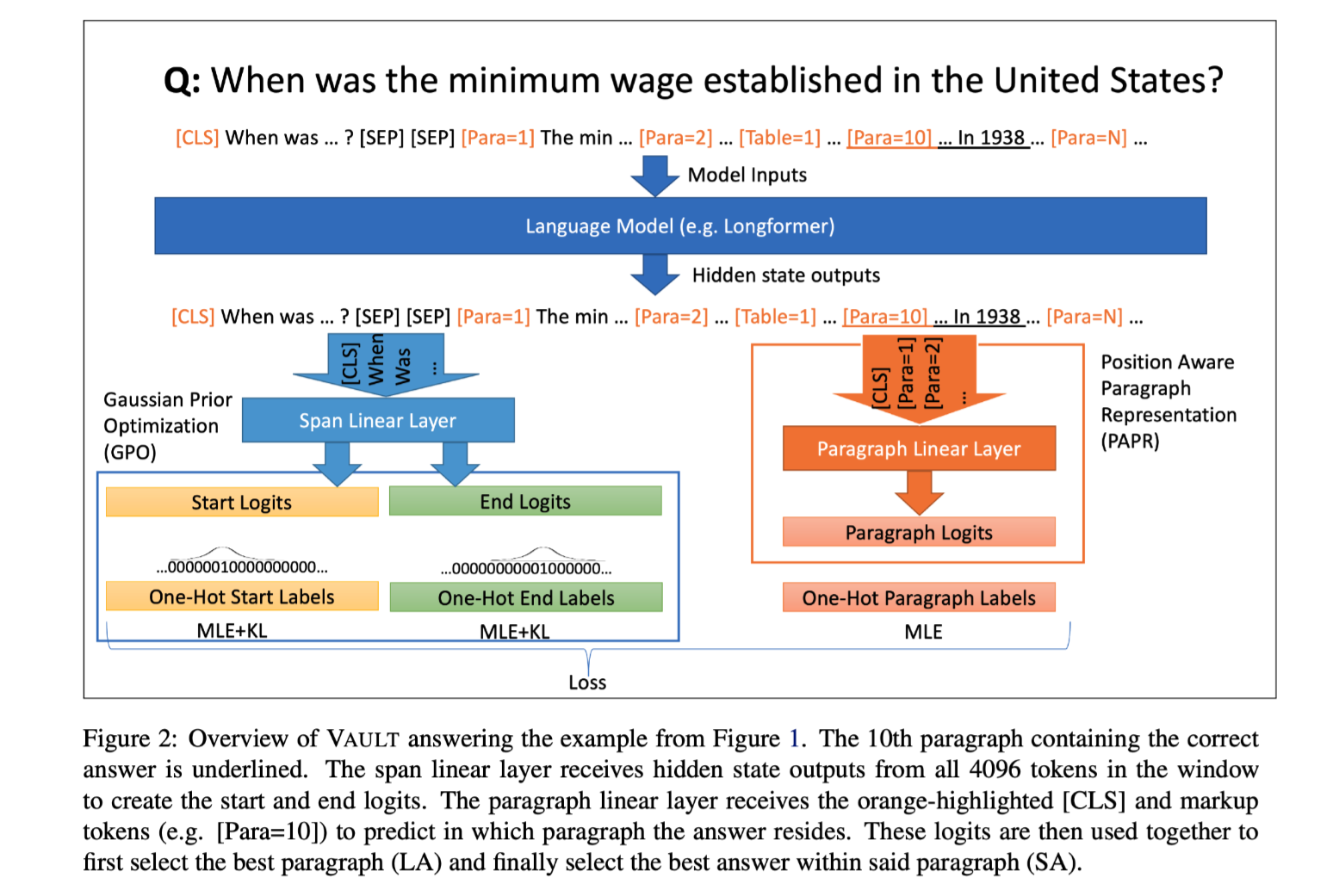
模型结构
A Base “Paragraph” Predictor Model
假设:通过建模更长的上下文,即使是简单的段落表示也可以有效地表示段落。
使用Longformerm建模输入,Longformer provides a much larger maximum input length of 4,096。
Position-aware Paragraph Representation (PAPR):
为了解决许多流行的非结构化文本(如维基百科页面),某些相关信息的展示方式相对标准的问题(例如,生日通常在第一段,而配偶姓名则在“个人生活”段),本文通过在每个段落的开头用特殊的atomic标记($[paragration=i]$)标记段落,指示段落在文本中的位置,为基础模型提供了它正在阅读的文本部分的表示。通过这种输入表示,可以使用特殊段落标记输出嵌入直接做长答案分类。
paragraph answer的计算:
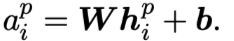
P:文本中的所有段落
组成P的相关token:$h^p_i$
给定上下文$c$,计算段落$l_i$的概率:
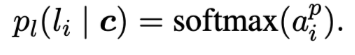
流程:首先在所有候选段落中选择logit最高的段落候选段落。然后,使用标准的指针网络在选定的段落答案候选中提取跨度答案。
Gaussian Prior Optimization (GPO)
高斯先验优化
传统的跨度提取模型通过极大似然估计优化了答案跨度与真实答案跨度的预测起点和终点位置的概率。MLE方法提高了真实答案位置的概率,同时抑制了所有其他位置的概率。但实际情况并非这样绝对,本文假设,接近真实答案的位置相对于较远位置的token要给较高的置信度,因为提取的答案会与真实答案部分重叠。
真实答案范围:$s \in {start, end}$
高斯分布:$N (y_s, σ)$
均值:真实答案的位置,$y_s$
方差:超参数
概率密度: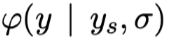
真实答案在$y_s$位置的类高斯分布:
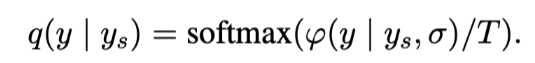
用T重新缩放
损失函数:
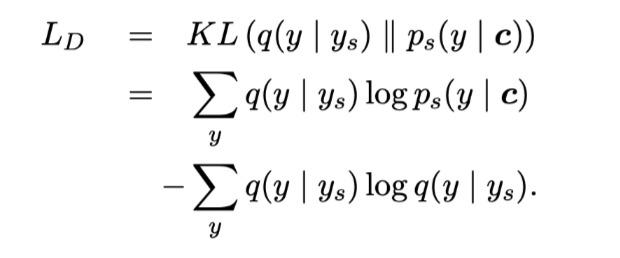
使用KL散度增强训练的MLE(极大似然估计)目标。
构建的分布:
模型的预测:
数据集
- 一个基于维基百科(Natural Questions,NQ)
NQ试图通过提供较长的维基百科文件作为语境和真实的用户搜索引擎查询作为问题,使机器阅读理解(MRC)更加真实,并旨在避免观察偏差:如果问题是在用户看到段落后创建的,那么问题和答案语境之间的词汇重叠会经常发生。
NQ由出现在谷歌搜索日志中的crowdsourced-annotated full维基百科页面组成,其中包含两个任务:短答案(SA)和长答案(LA,例如段落)的起始和结束偏移量(如果存在)
- 另一个基于技术说明(TechQA)
TechQA是从客户支持领域(customer support domain)的真实用户问题发展而来的,每个问题都有50个文档,其中大多数文档都有答案——答案比标准的MRC数据集(如SQuAD)长很多(~3-5倍)。
性能水平

VAULT可以从文章较后位置预测答案,但现有模型从一般答案最容易出现的第一段预测答案。
- 在NQ数据集上
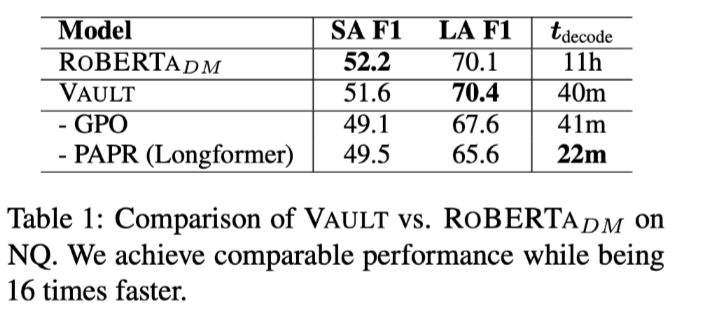
短答案和长答案
- TechQA

HA F1 (denotes Has Answer)
结论
在这项工作中,介绍并检验了一个功能强大但简单的长文本阅读理解模型,称之为VAULT,基于这样一个假设:如果序列长度较大,长答案可以有效分类,而无需计算繁重的基于图的模型。
本文贡献:
- 本文介绍了一种新颖、有效但简单的段落表示法。
- 在训练期间,引入软标签,以利用来自local contexts的信息,接近正确答案,这对于MRC来说是新颖的。
- 本文的模型提供了与NQ上的SOTA系统类似的性能,同时速度提高了16倍,并且有效地适应了一个新领域:TechQA。