EQG-RACE Examination-Type Question Generation
EQG-RACE: Examination-Type Question Generation
论文:https://arxiv.org/abs/2012.06106
代码:https://github.com/jemmryx/EQG-RACE
会议:AAAI-2021
任务
本文提出了一种创新的考试型问题生成方法(EQG-RACE),基于从RACE提取的数据集生成类似考试的问题。EQG-RACE中采用了两个主要的策略来处理离散的答案信息和长语境中的推理:
- 一个粗略的答案和关键句子标签方案被用来加强输入的表述。
- 一个答案引导的图卷积网络(AG-GCN)被设计用来捕捉揭示句子间和句子内关系的结构信息。
方法(模型)
构建数据集的两个挑战:
- 首先,答案往往是完整的句子(或长短语),而不是包含在输入序列中的短文本跨度,这使得之前的答案标签方法失效。
- 其次,上下文段落较长,问题是通过多个句子的深度推理而产生的,这使得像LSTM这样的顺序编码方法无法发挥作用。
解决方案:
- 为了解决第一个问题,本文采用了一种远距离监督的方法来寻找关键的答案词和关键的句子,然后将它们融入词的表示中。
- 为了解决第二个问题,并对句子内部和句子之间的推理关系进行建模,本文设计了一个Answerguided Graph Convolutional Network(AG-GCN)来捕捉结构信息。
Model Description
模型结构:
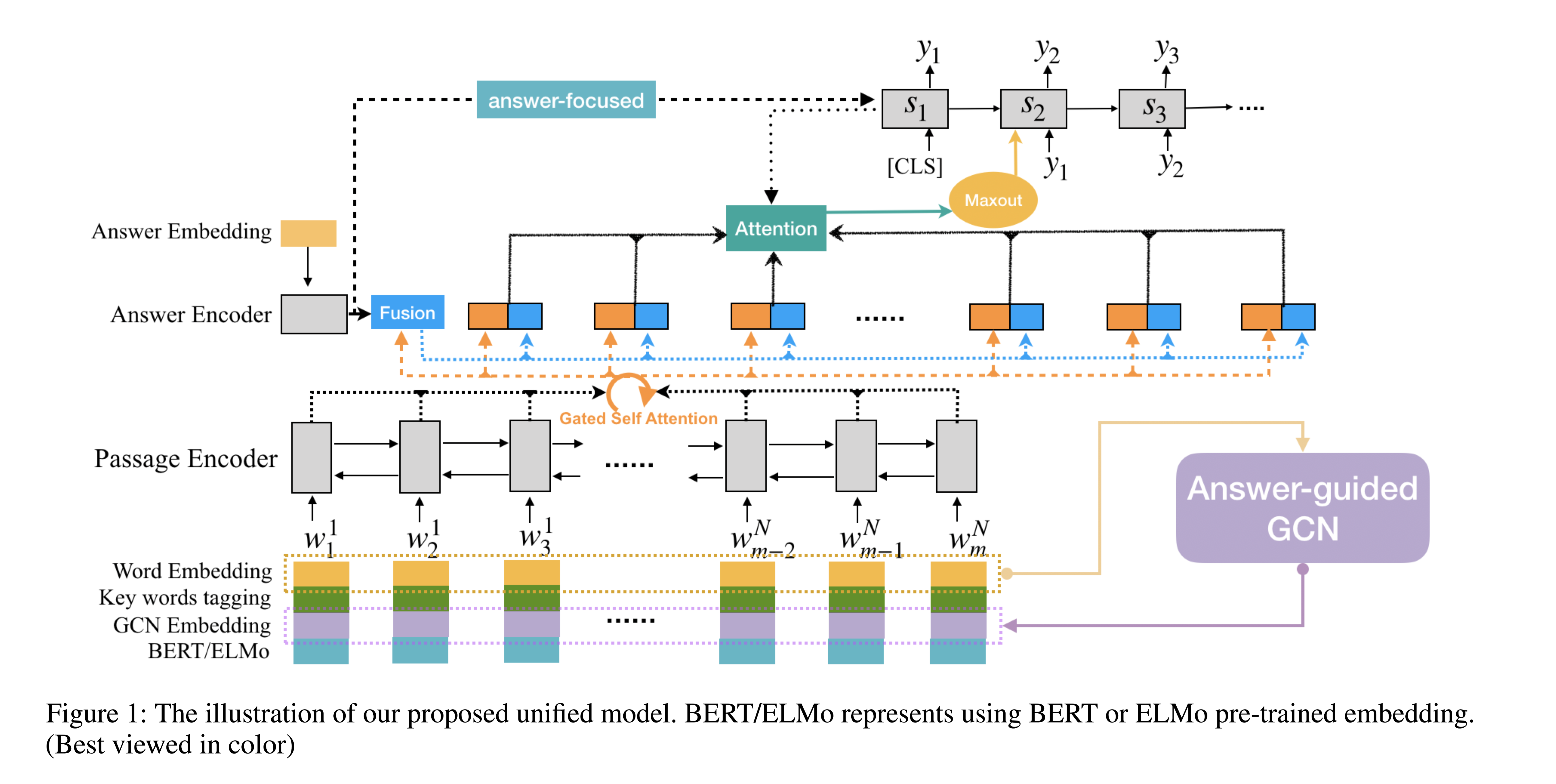
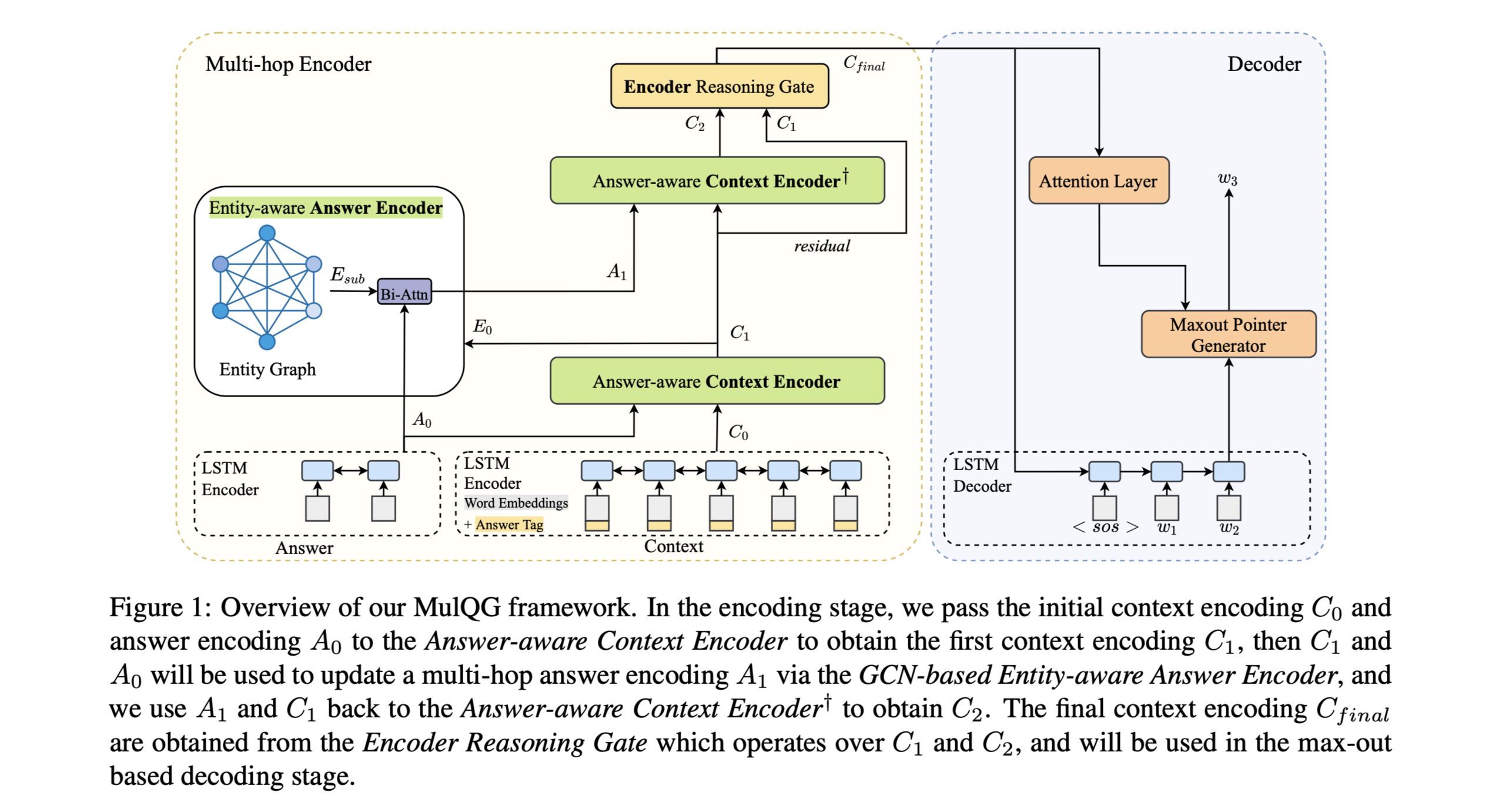
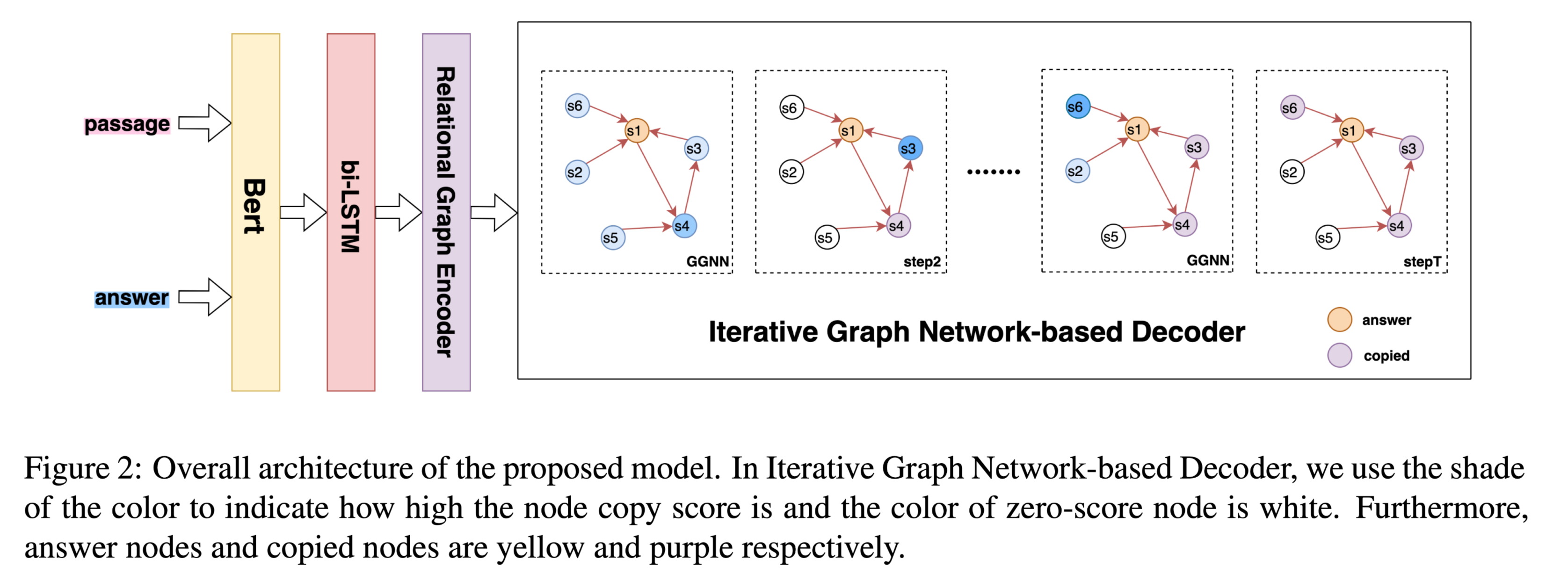
首先,根据答案信息对段落关键词进行注释。输入的段落被送入一个答案引导的GCN,以获得以答案为中心的语境嵌入。然后,单词嵌入、关键词标签嵌入、GCN嵌入和预训练嵌入的特征被连接起来,作为双向LSTM编码器的输入,将一个门控的自意机制被应用于passage隐藏状态。经过上述步骤,融合段落和答案的隐藏状态,以获得答案感知的上下文表征。最后,用一个基于注意力的解码器在maxout-pointer机制的帮助下依次生成问题。
目标:
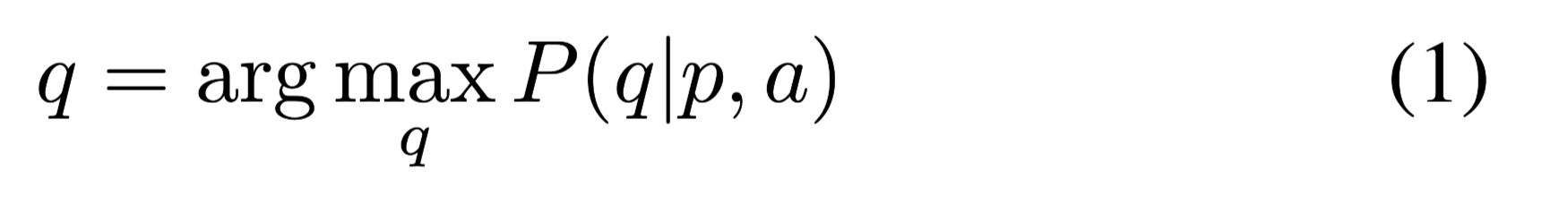
给定文章p和相关答案a提出问题q。
Baseline Model:gated self-attention maxout-pointer model
encoder:use two-layer bi-directional LSTMs
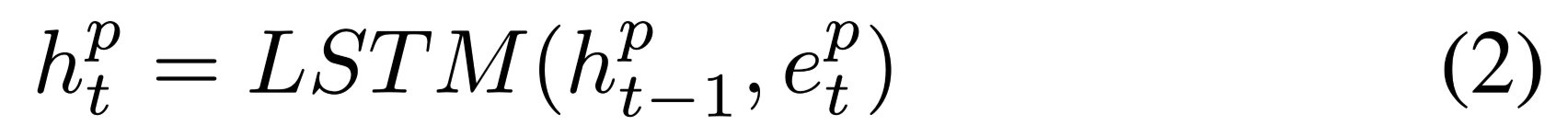
$h^pt$ and $h{t−1}$ are LSTM hidden states, and $e^p_t $ is word embedding
gated self-attention mechanism:
用来将passage的隐藏层表示H,聚合intra-passage(文档内)依赖,得到encoder output $ \hat H$:
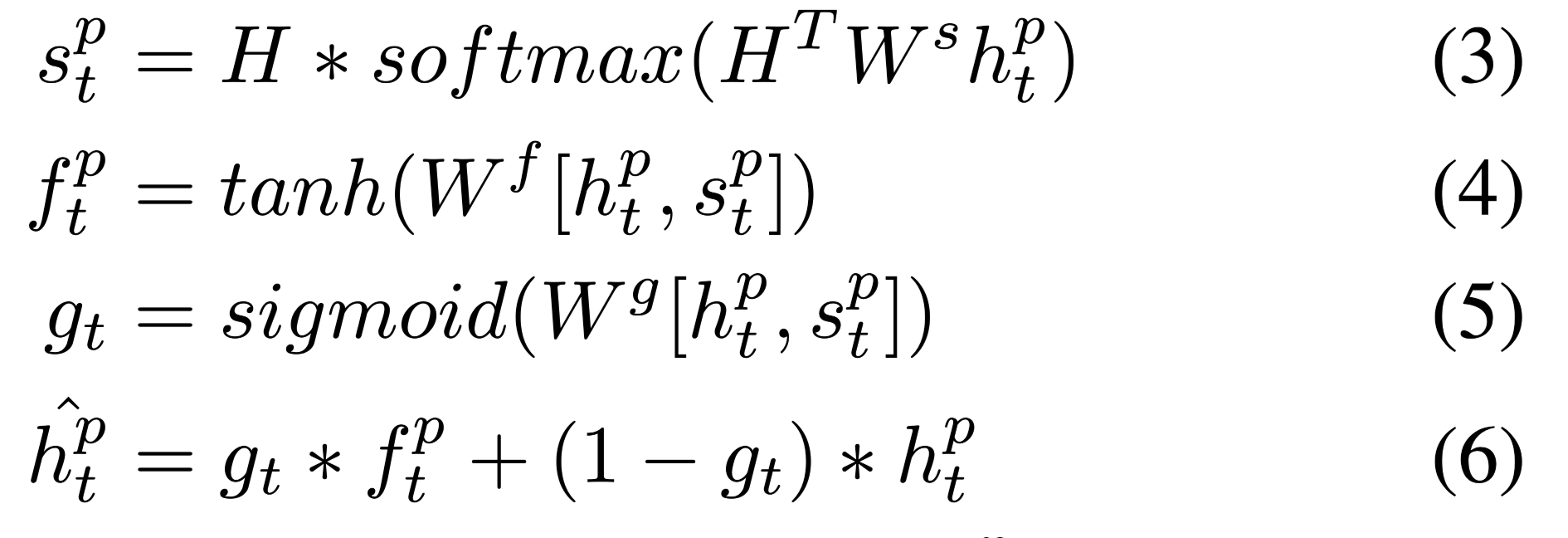
其中$g_t$是一个可学习的门控参数,用来平衡$f$ ,$h$对编码器输出$ \hat H$的贡献度。
decoder :another two-layer uni-directional(单向) LSTM。
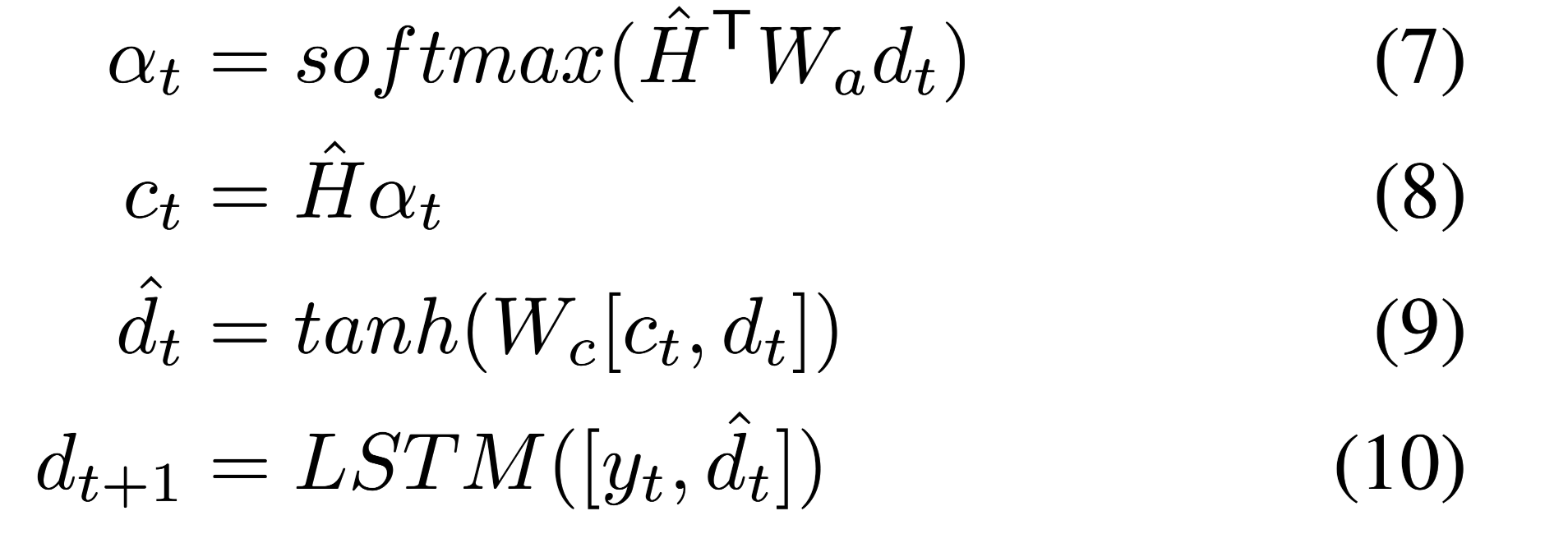
通过注意力机制聚合$\hat H$得到上下文向量$c_t$。
maxout-pointer mechanism计算目标单词$y_t$的概率分布:
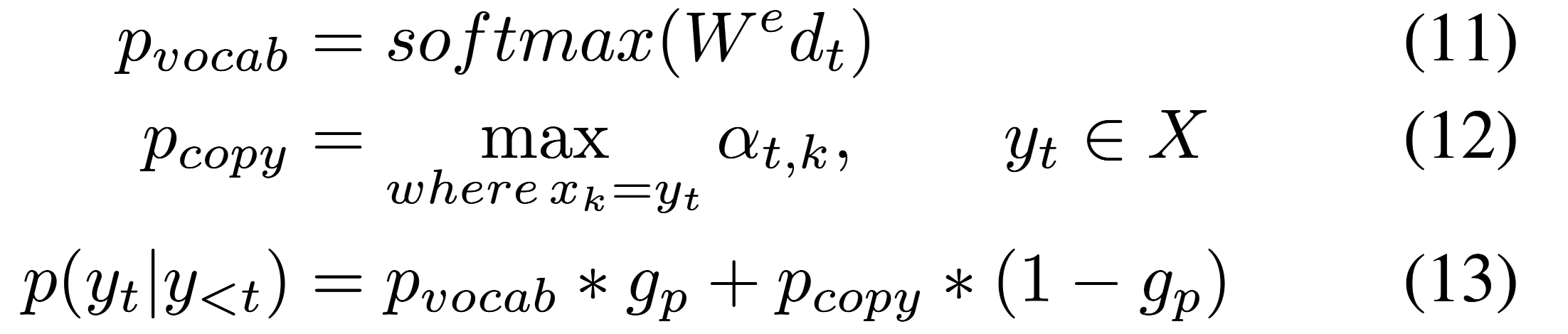
Keywords Tagging
标签”A”的优先级高于”S”,如果单词同时出现两个标签,则打上”A”标签
如果同时不出现,word打上”O”标签
标记答案:
将文章中出现的答案词标记为”A”
标记关键句:
根据文章回答特定的问题,答案往往在某几个关键句中,而不是全文。
关键句中所有单词都被打上”S”标签。
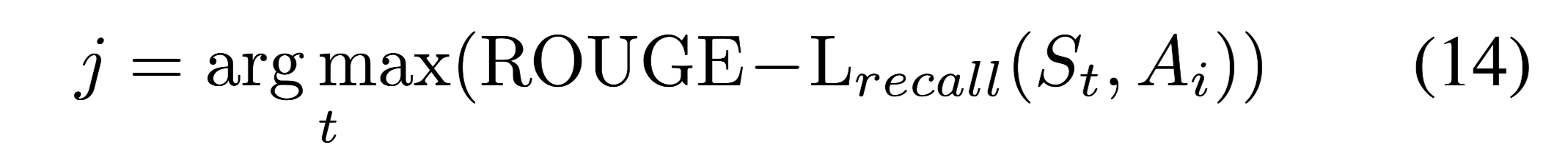
$S_t$:表示文章中的第t句
$A_i$:答案文本
融合关键词信息之后,encoder的输入可以改写为:
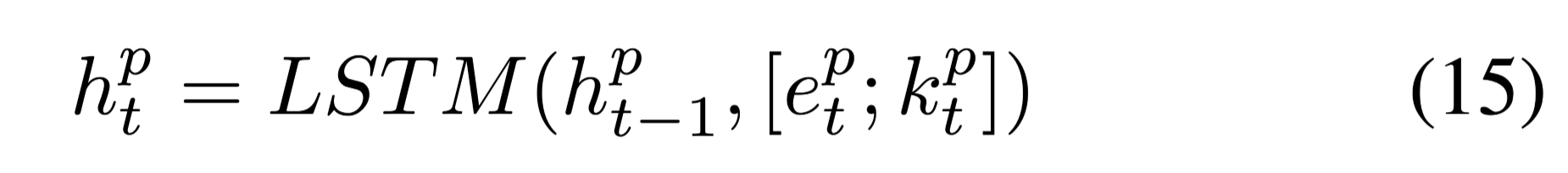
将Keywords tagging $k^p_t$ 和word embeddings $e^p_t$连接,作为输入特征的增强表示。
回答RACE中的问题,涉及不同的认知技能,通常需要对句子内部和句子之间的复杂关系进行深入推理,传统的CNN,RNN无法胜任,本文提出Answer-guided Graph Convolution Network (AG-GCN)编码文章。
图结构:
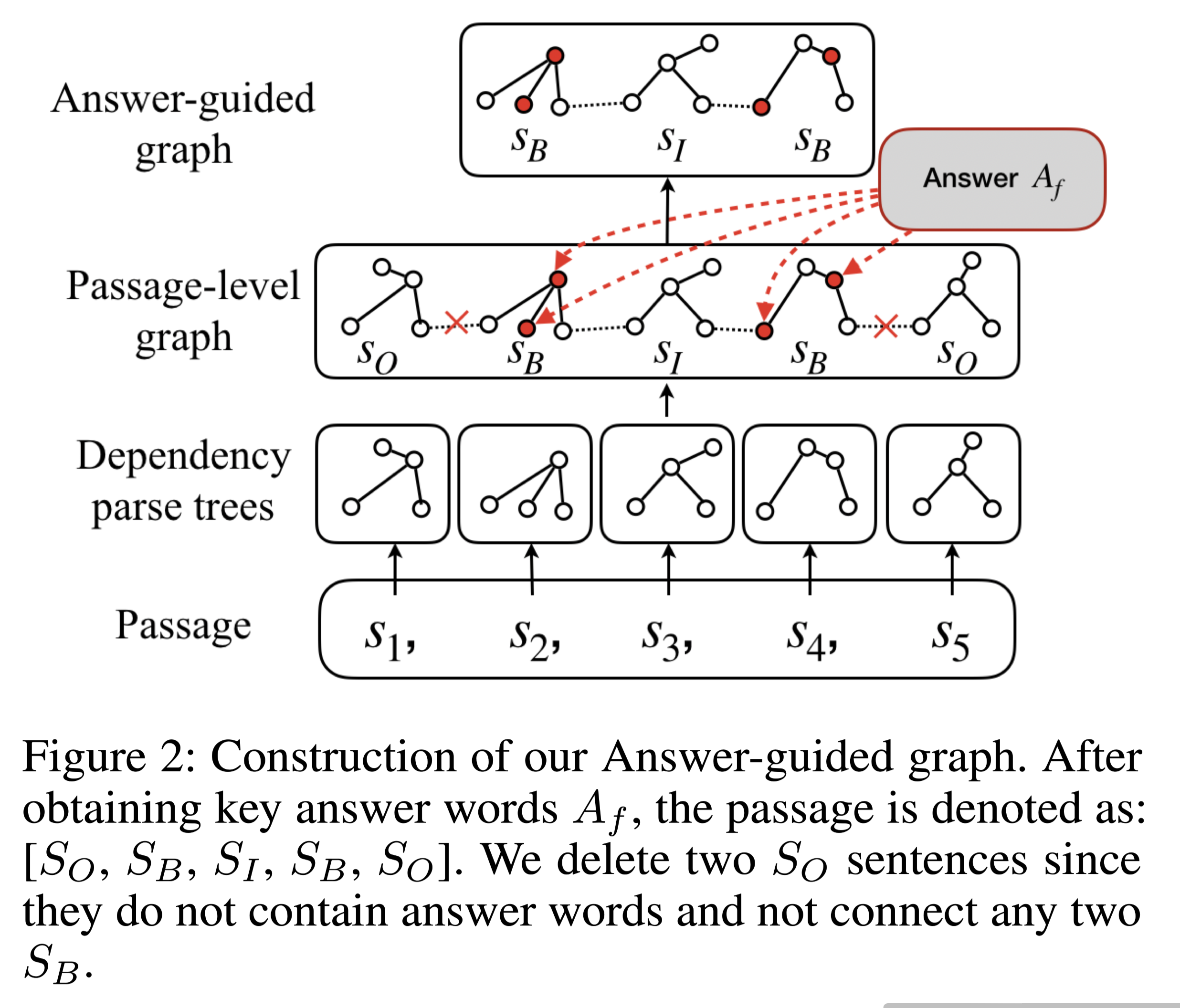
句子标签策略:
$S_B(Begining)$ :represents sentences containing words in $A_f$
$S_I(Inside)$: represents sentences that connect any two important sentences S_B;也就是说,$S_i$位于两个$S_B$之间。
others are represented as $S_O(Out)$
“isolated” nodes:本文认为$S_O$中的节点是 “孤立的 “节点,因为它们不包含以答案为中心的信息,不能对两个基本句子之间的推理过程做出贡献。
构建步骤:
第1步:对上下文段落中的每个句子进行依赖性分析。
第2步:通过连接处于句子边界和相邻的节点,将相邻句子的依赖树连接起来,建立一个段落级的依赖解析图。
- 第3步:通过粗略的答案标签方法检索关键的答案词$A_f$,并从段落级图中删除 “孤立的 “节点和它们的边来构建答案引导图。
encoding process:
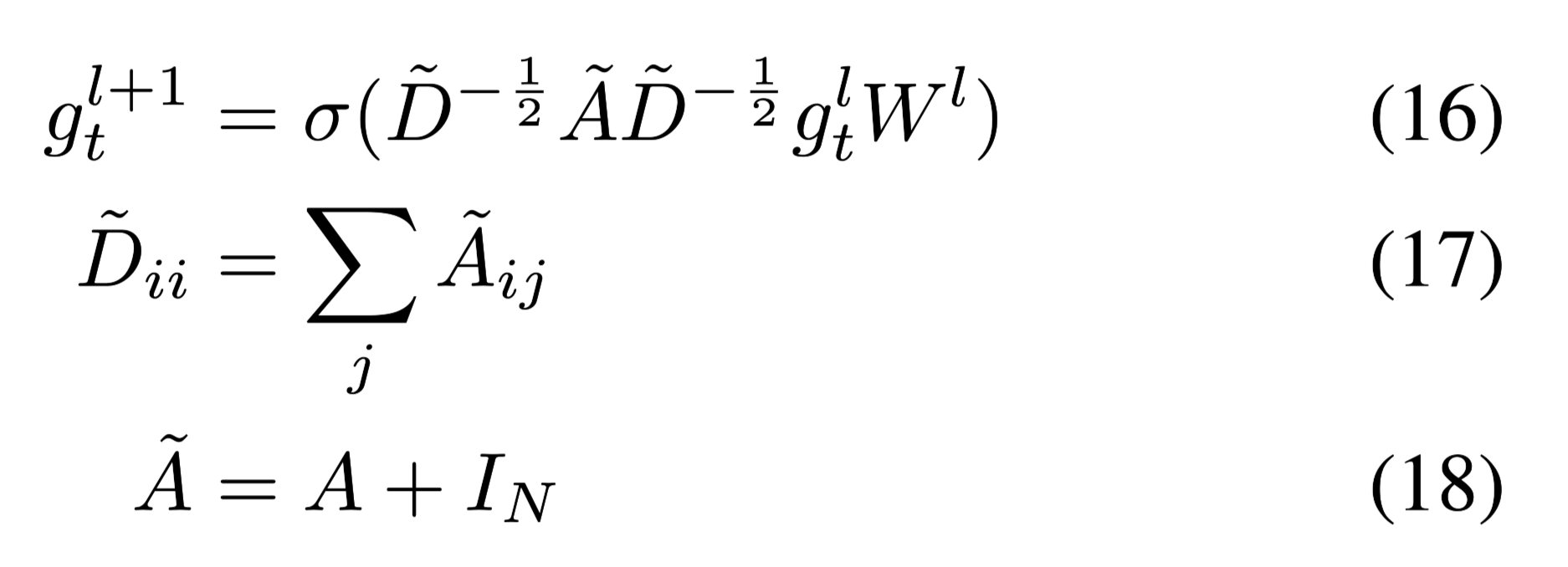
A:图的邻接矩阵
D is a diagonal matrix and INis the identity matrix
初始$g_0$初始化为单位矩阵E
encoder的输入(公式15)可以再次被改写为:
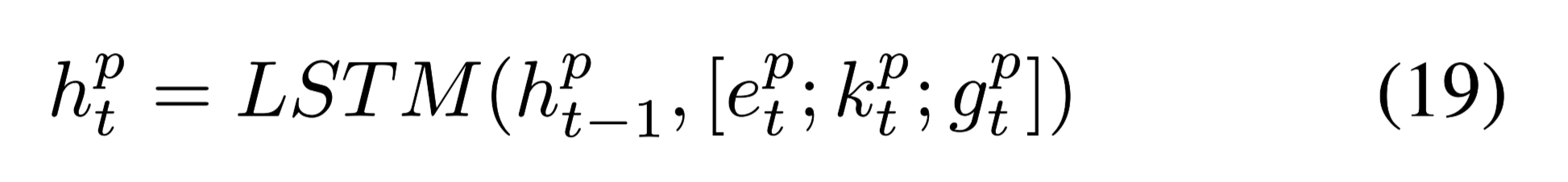
将Keywords tagging $k^p_t$ 和word embeddings $e^p_t$和GCN的输出$g_t^p$连接,作为输入特征的增强表示。
Exploring Pre-training Embeddings
由于EQG-RACE数据集的样本相对较少,直接用深层神经网络可能会出问题,因此使用预训练模型的embeddings作为encoder输入的补充。公式(19)可以继续被改写为:
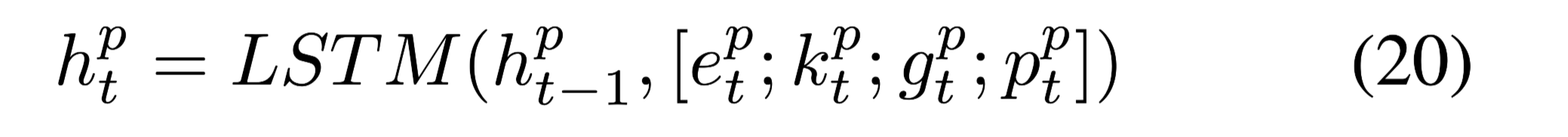
$p^p_t$:可使用像BERT、ELMO等预训练模型的embedding
Passage-answer Fusion
为了很好地捕捉段落P和答案A之间的相互依赖关系,融合answer representation $h^A$ 和 passage representation $h^p_t$ 得到 answer-aware representations作为
encoder输出:
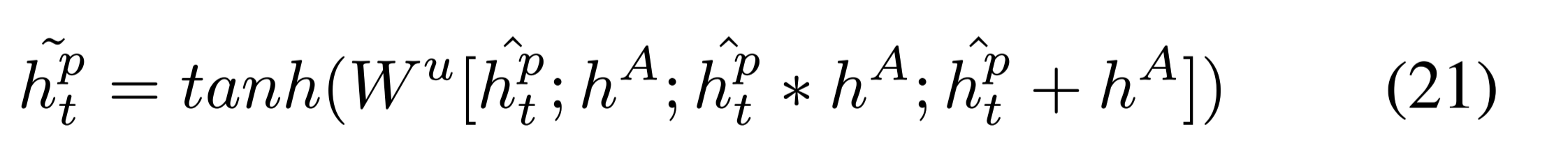
$h^A$:答案隐藏层表示
小技巧:
在解码过程中,第一个疑问词是整个生成问题中最重要的部分之一。因此,本文没有使用段落编码器的最后一个隐藏状态 $h^p_t$,而是利用答案编码器的状态$h^A$作为解码器的初始化,在这种设置下,解码器可能会产生更多关注答案的问句。
数据集
SQuAD和本文提出的EQG-RACE数据集详细比较:

性能水平
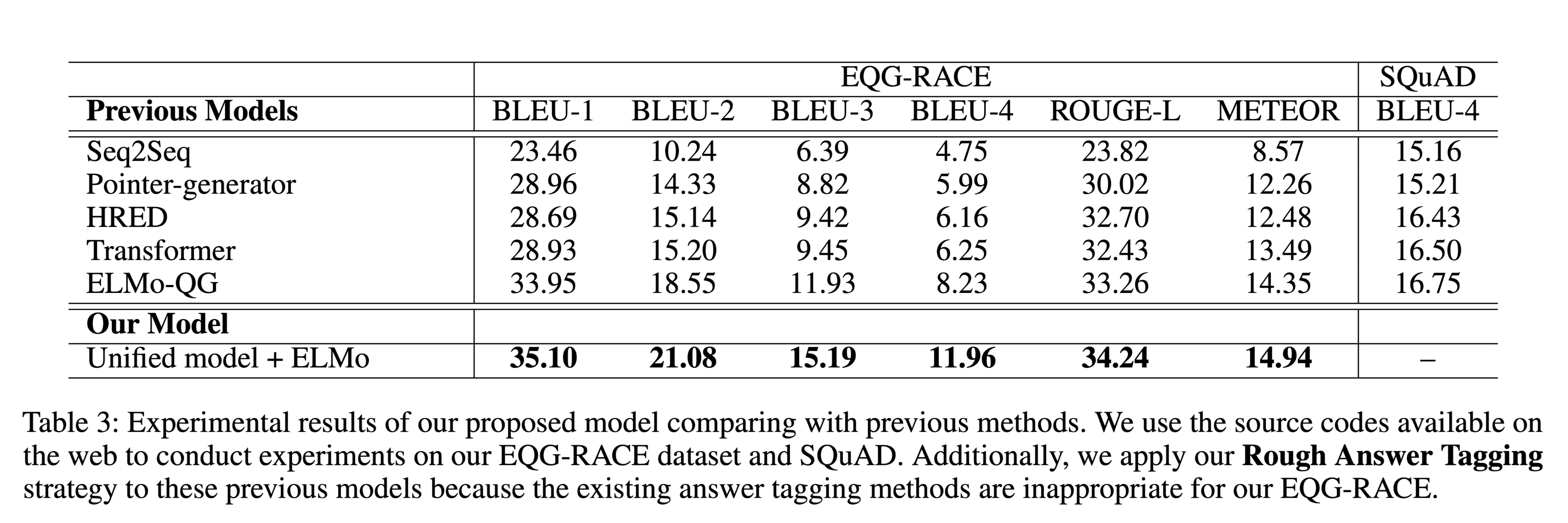
结论
Case Study:

本文提出EQG-RACE来自动生成考试类问题,重建了原始的RACE数据集,以适应问题的生成。为了处理上下文段落中离散的答案信息,提出了一个粗略的答案和关键句子标签方案来定位与答案有关的内容。此外,还设计了一个答案引导图来捕捉以答案为重点的结构信息,作为seq2seq模型的补充。