Cross-Lingual Machine Reading Comprehension
Cross-Lingual Machine Reading Comprehension
任务
- 虽然机器阅读理解研究得到了飞速发展,多数工作面向的是英文数据,而忽略了机器阅读理解在其他语言上的表现,其根本原因在于大规模训练数据的缺失。本文提出跨语言机器阅读理解(Cross-Lingual MachineReading Comprehension,CLMRC)任务来解决非英文下的机器阅读理解。
- 本文所提出的方法具有良好的通用性,可适配多种机器阅读理解任务。在本文中将着重解决基于篇章片段抽取的机器阅读理解(Span-Extraction MRC),这也是目前在该领域中研究最为广泛的任务之一。该任务需要对<篇章,问题>进行建模,并从篇章中抽取出一个连续的片段作为答案。最广为熟知的是由斯坦福大学提出的SQuAD(Stanford Question Answering Dataset)数据集。
- 利用英文(源语言)数据来提升中文(目标语言)机器阅读理解系统效果。
方法(模型)
首先给出了基于回译(Back-Translation)的跨语言阅读理解方法来解决目标语言没有训练数据的情况。
对于目标语言存在一定的训练数据时,创新地提出了Dual BERT模型来进一步借用富资源语言(例如:英文)的训练数据来帮助低资源语言下的机器阅读理解效果。该模型能够对<篇章,问题>在双语环境中建模,并且最终融合成一种统一的语义表示,进而得到更加精准的答案预测。
主要贡献:
- 提出了跨语言机器阅读理解任务来进一步提升低资源语言下的机器阅读理解系统效果
- 提出了Dual BERT模型,对输入文本和问题在双语环境中建模,进一步丰富了语义表示
- 所提出的Dual BERT模型在两个中文机器阅读理解数据集上获得state-of-the-art效果
Back-Translation Approaches
- 源语言:具有大规模的语料资源的语种。我们需要从该语种的资源中抽取出丰富的知识。下文中使用下标S来代表源语言变量。
- 目标语言:希望优化系统性能的语种,即目标系统的语种。该语种没有可用或仅有少量的语料资源。下文中使用下标T来代表目标语言变量。
本文利用英文(源语言)数据来提升中文(目标语言)机器阅读理解系统效果。
several back-translation approaches
GNMT
(Google Neural MachineTranslation,GNMT)
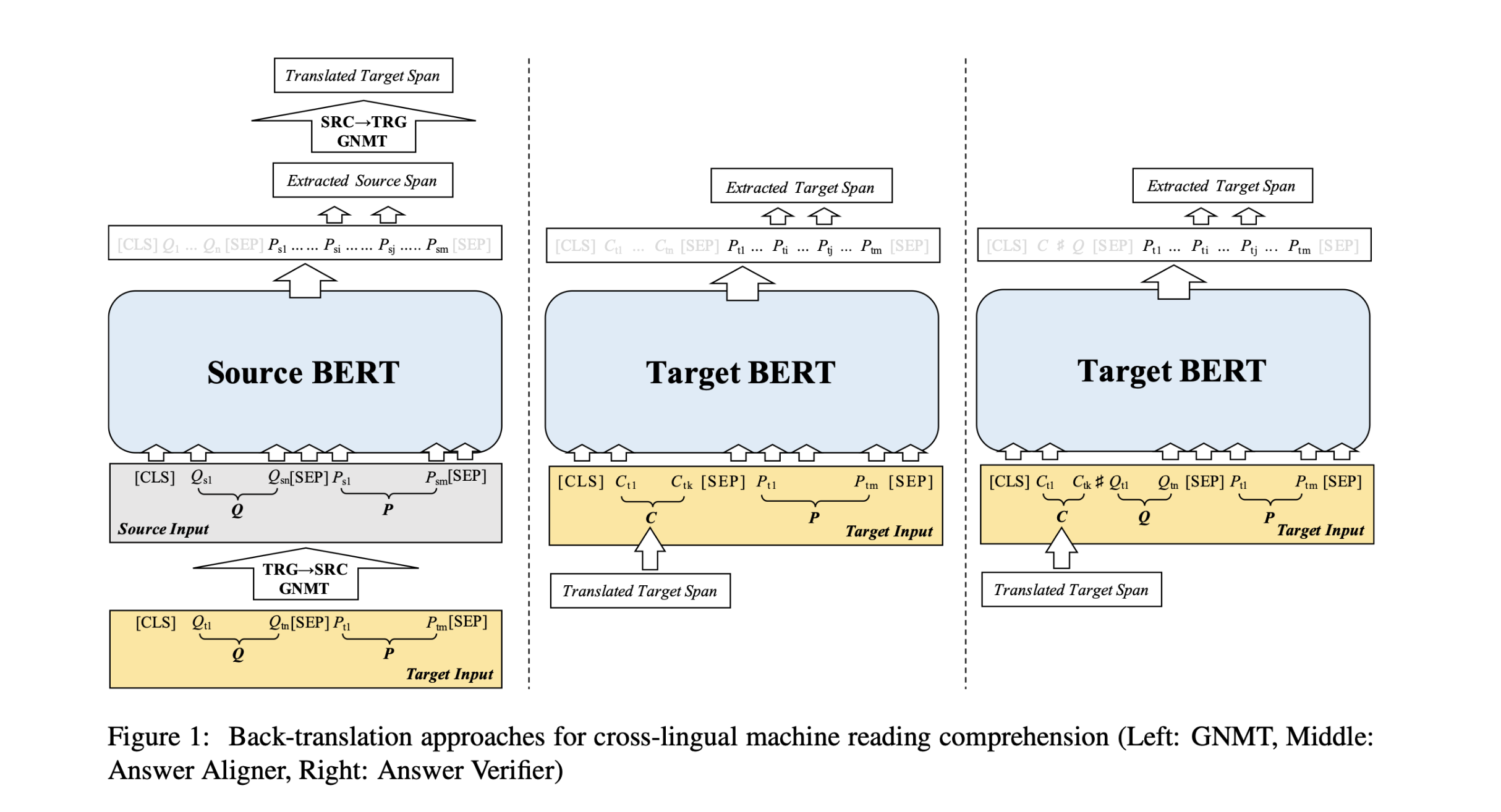
使用翻译系统来实现跨语言机器阅读理解是很直接的方法,主要流程(Figure1 left):
- 将目标语言输入<篇章,问题>翻译成源语言
- 通过源语言的阅读理解系统得到一个源语言的答案
- 将源语言答案回译为目标语言
存在问题:经过回译的答案不一定是原文中的某个精准片段。
解决方法:
Simple Match
利用滑动窗口在目标语言篇章中进行滑动,假设翻译出的答案与真实答案长度基本相似,由此计算出候选span和翻译答案的F1-score,从这些窗口中选取一个字级别F1-score最高的窗口作为最终的预测答案C。使用所提出的SimpleMatch可以确保预测的答案是目标段落中的精确跨度。
Answer Aligner
Figure 1 middle
如果目标语言有一定量的训练数据,那么可以进一步提升答案对齐的效果。将对齐后的答案C与目标语言篇章P输入到BERT中,并以目标语言真实答案作为目标进行训练,就可以得到答案对齐器(Answer Aligner)。
Answer Verifier
Figure 1 right
在答案对齐器的基础上进一步加入目标语言问题Q,即可成为答案验证器(Answer Verifier),使用翻译答案验证正确性。
Dual BERT
适用于目标语言存在一定的训练数据的情况。
模型结构:
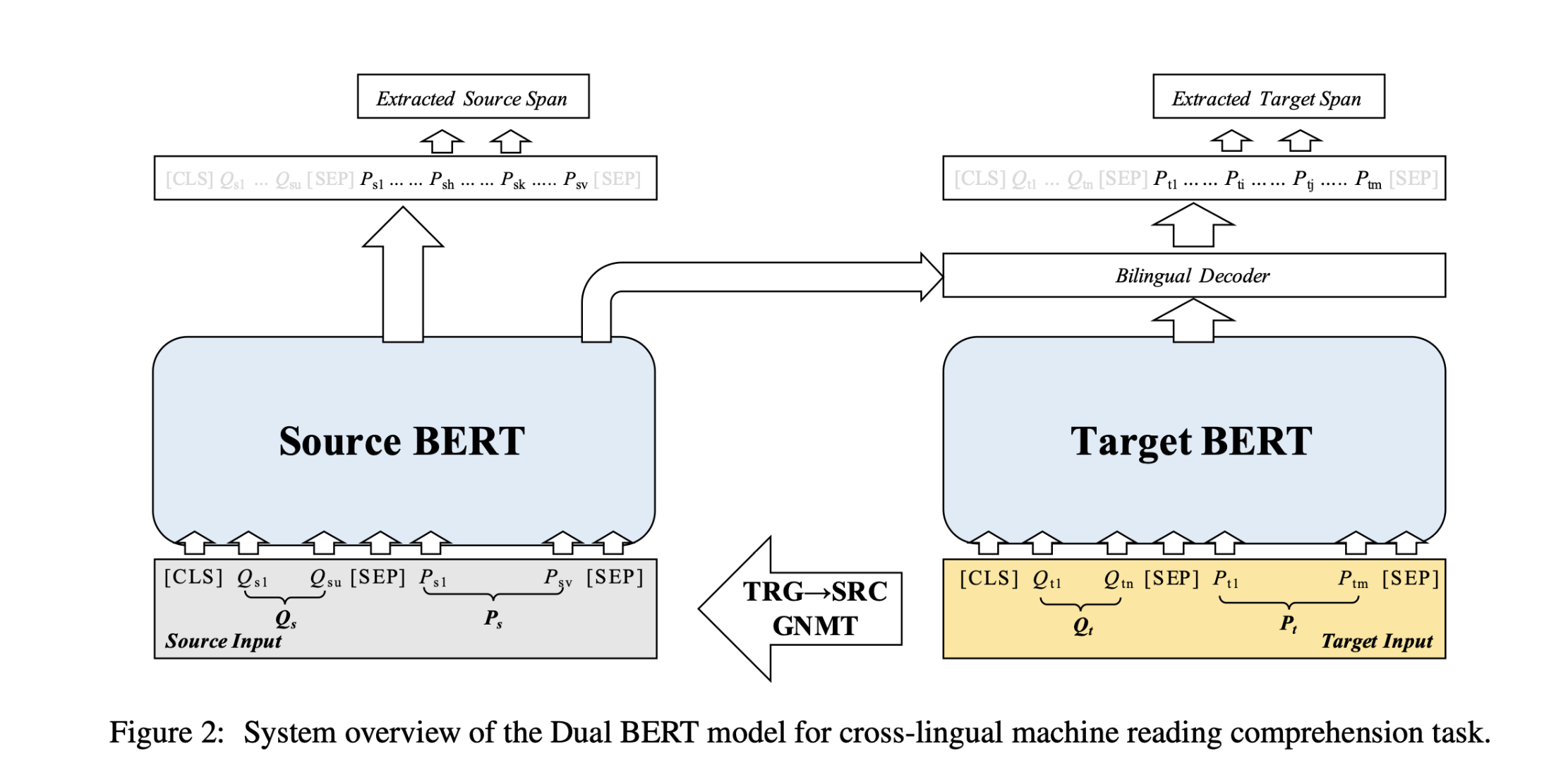
Dual Encoder
本文使用BERT作为文本表示模型,对于给定的目标语言篇章$P_T$和问题$Q_T$,BERT的输入$X_T$可以表示为:
利用GNMT系统,可以将目标语言数据翻译成源语言,从而获得源语言输入$X_S$。经过BERT编码后,分别获得目标语言表示$B_T$和源语言表示$B_S$。
Bilingual Decoder
双语解码器
为了将源语言表示融合到目标语言表示中,提出了一种自适应注意力机制(Self-Adaptive Attention, SAA)。
在原始Attention矩阵计算:
修改后:
该操作的目的是,在$B_T$和$B_S$计算注意力之前,首先让$B_T$和$B_S$先对自身进行Self-attention计算,过滤掉相对无用的部分,然后再计算两者之间的注意力,从而进一步提升注意力计算的精准度。
得到Attended表示$R’$后,并进一步通过残差连接(Residual Connection)和层归一化(Layer Normalization)获得最终的表示$H_T$。
最终利用$H_T$计算目标语言上的开始和结尾指针并计算对应的交叉熵损失。
Auxiliary Output
辅助损失
同时对源语言进行预测并计算对应的交叉熵$L{aux}$作为辅助损失。最终的损失函数为$L=L_T+\lambda L{aux}$,其中λ∈[0,1]为比例系数。源语言是经过翻译得到的,存在一定的信息缺失,$\lambda$为动态计算,控制辅助损失对主损失的影响。
数据集
两个篇章片段抽取型(Span-Extraction)中文机器阅读理解数据集
CMRC 2018(简体中文)
DRCD(繁体中文)
性能水平
实验结果:
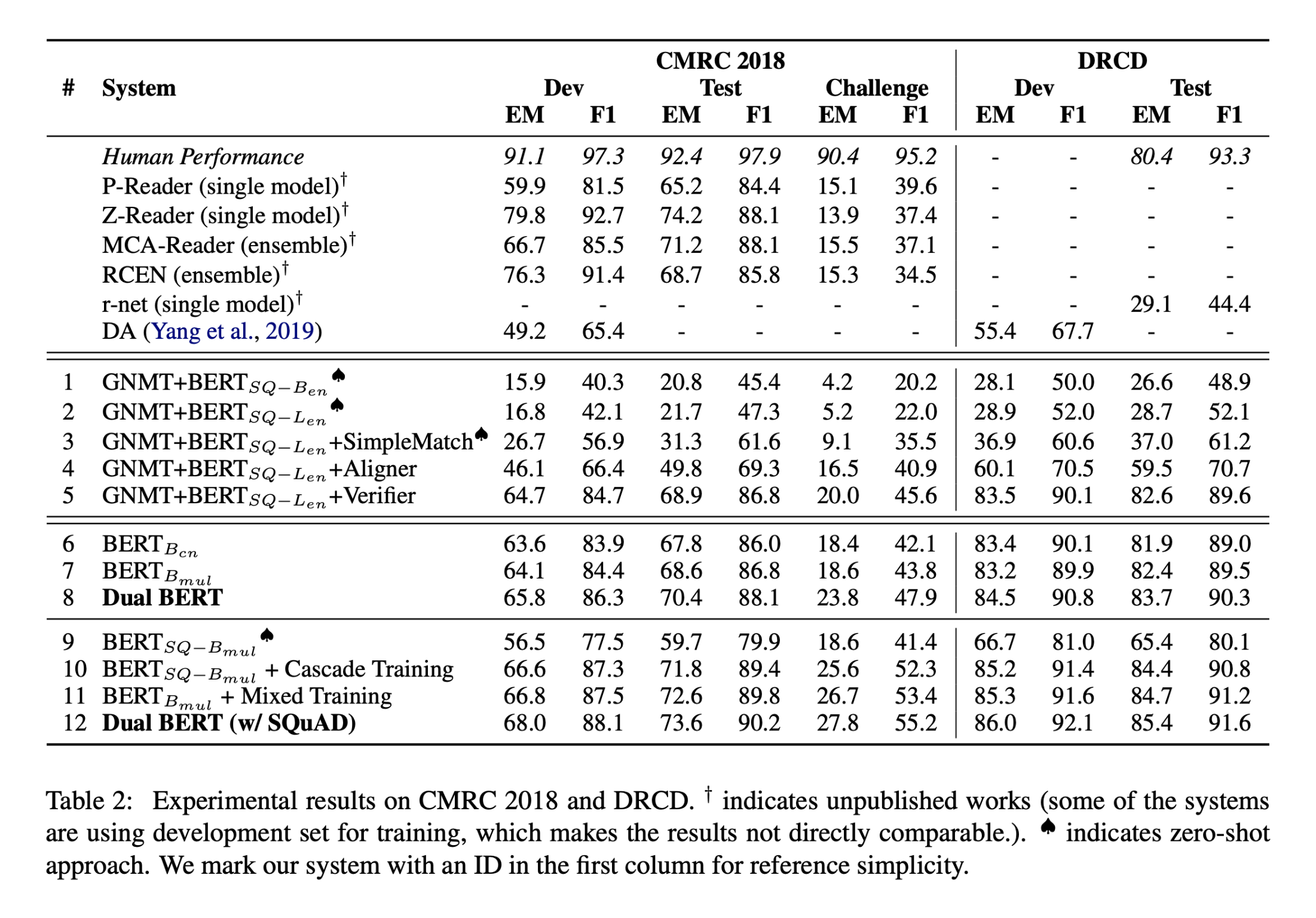
- 基于回译的系统中,简单匹配能够带来显著性能提升;在有一定训练数据的情况下,答案验证器和答案验证器能够进一步带来性能提升
- 采用源语言预训练的模型对目标语言的机器阅读理解系统有显著性能提升
- Dual BERT的双语建模能够在上述基础上带来进一步的性能提升
结论
阅读理解系统性能提升:
在数据量差异不大的情况下,无需根据语种的远近选择源语言数据;
在数据量差异较大的情况下,应首要考虑源语言数据的规模而非语种的远近。
在两个中文机器阅读理解数据集上验证得知该方法能够显著提升低资源下的机器阅读理解效果,为未来低资源下的机器阅读理解提供了一种解决方案。