
Multi-hop Question Generation with Graph Convolutional Network
Multi-hop Question Generation with Graph Convolutional Network
论文:https://arxiv.org/abs/2010.09240
代码:https://github.com/HLTCHKUST/MulQG
任务多跳问题生成(Multi-hop Question Generation,QG)的目的是通过对不同段落中多个分散的证据进行汇总和推理,生成与答案相关的问题。解决两个问题:1.如何有效地识别分散的证据,可以连接答案和问题的推理路径。2.如何推理多个分散的证据来产生事实连贯的问题。
识别分散的证据,可以连接答案和问题的推理路径:
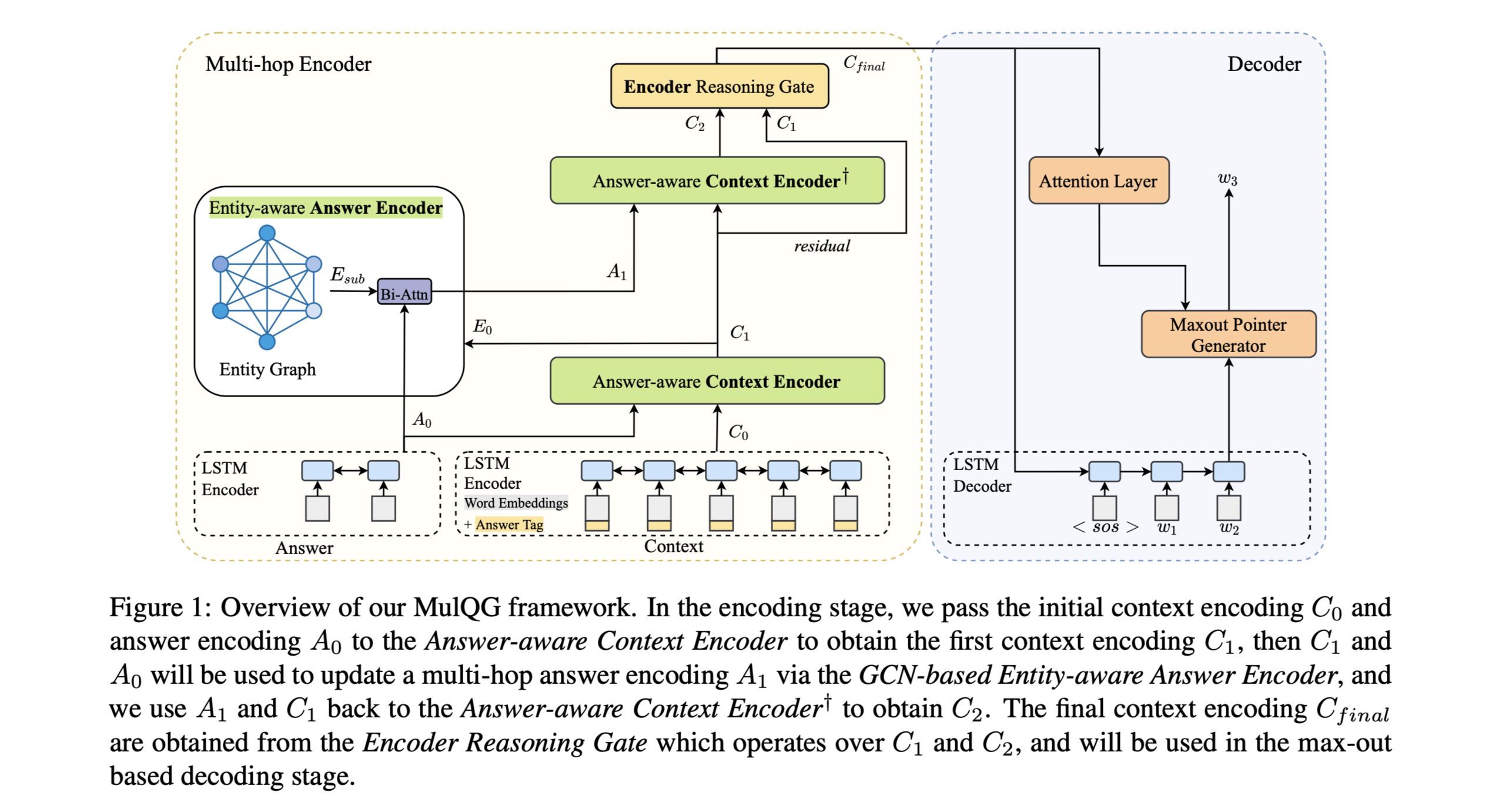
方法(模型)为了解决多跳QG(MulQG)中的额外挑战,本文提出了问题生成的多跳编码融合网络(Multi-Hop Encoding Fusion Network),它通过Graph Convolutional Network在多跳中进行上下文编码,并通过编码器推理门(Encoder Reasoning Gate)进行编码融合。
MulQG将Seq2Seq QG框架从单跳扩展到多跳进行 ...
Avoiding Reasoning Shortcuts Adversarial Evaluation, Training, and Model Development for Multi-HopQA
Avoiding Reasoning Shortcuts Adversarial Evaluation, Training, and Model Development for Multi-HopQA
论文:https://arxiv.org/abs/1906.07132
代码:https://github.com/jiangycTarheel/Adversarial-MultiHopQA
任务 多跳答题需要模型将分散在长上下文中的多个证据连接起来来回答问题。本文在HotpotQA数据集上,通过构建对抗性文档(由于在生成问题时,人工并没有提供干扰文档,因此无法保证支持文档必须在整个上下文推断答案)来证明,通过数据集中部分例子包含的捷径,模型可以直接将问题与上下文中的句子进行词义匹配来定位答案。生成的这些对抗性文档会对捷径产生矛盾的答案,但不会影响原始答案的有效性。
方法(模型)为探究神经网络模型是否利用推理快捷方式而不是探索所需的推理路径,使用HotpotQA中原始数据以消除这些快捷方式(shortcuts)。
context-question-answer tu ...

Answering while Summarizing Multi-task Learning for Multi-hop QA with Evidence Extraction
Answering while Summarizing: Multi-task Learning for Multi-hop QA with Evidence Extraction
论文:https://arxiv.org/pdf/1905.08511.pdf
任务本文聚焦于可解释的多跳QA任务,要求系统通过推理和收集参考文本的不相交片段来返回带有证据句子的答案。提出了Query Focused Extractor(QFE)模型用于证据提取,并使用多任务学习与QA模型。
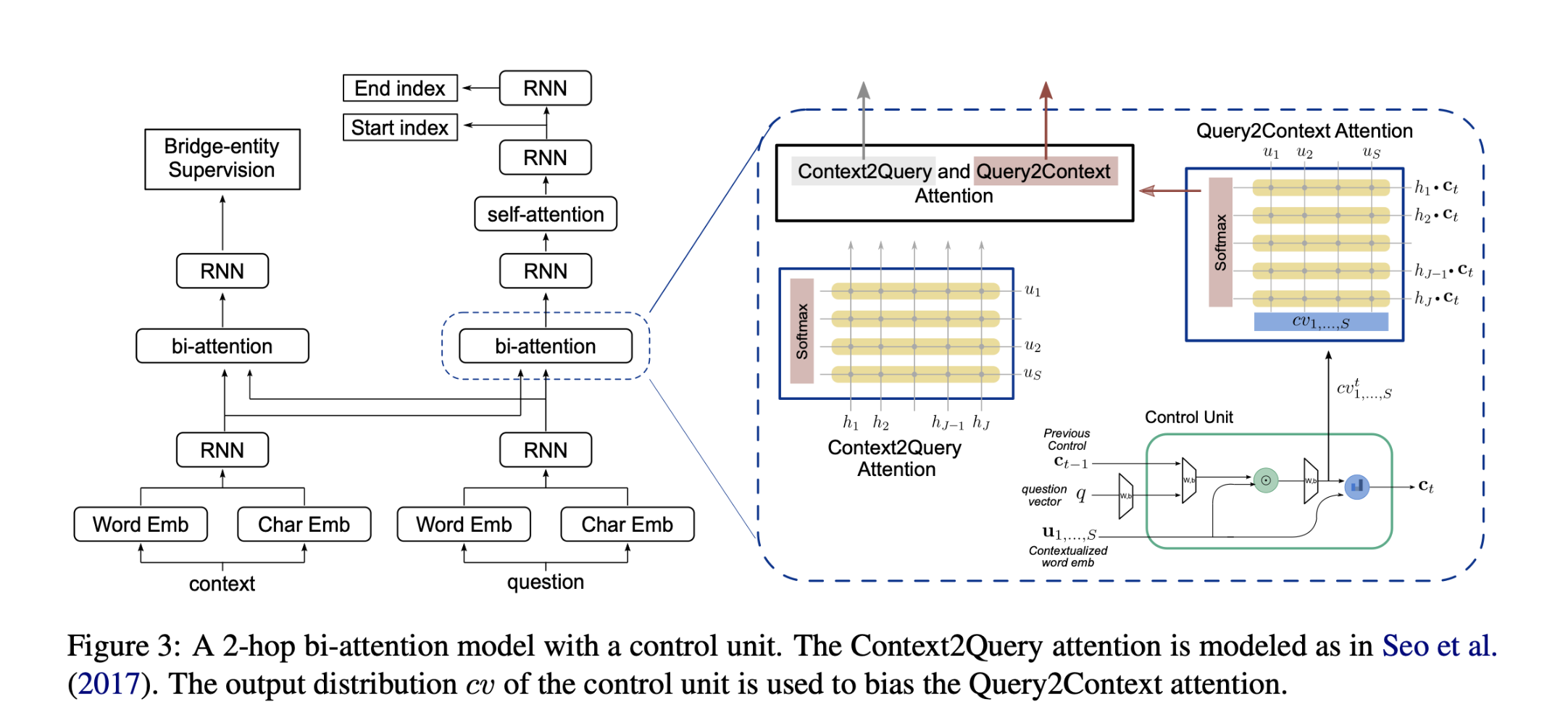
方法(模型)Query Focused Extractor (QFE)
整体模型采用多任务学习,答案选择采用QA模型,证据提取采用QFE模型。
QFE的灵感来自于提取式摘要模型(extractive summarization models),将可解释的多跳QA的证据提取看作是一个以查询为中心的摘要任务,与现有方法独立提取每个证据句相比,它通过使用RNN对问题句的关注机制(attention mechanism),依次提取证据句。它使QFE考虑到证据句之间的依赖性,覆盖了问题句中的重要信息。
模型 ...
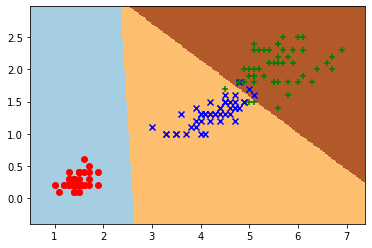
使用逻辑回归对鸢尾花进行分类
使用逻辑回归对鸢尾花进行分类12345import numpy as npimport matplotlib.pyplot as pltfrom sklearn import linear_modelfrom sklearn.metrics import accuracy_scorefrom sklearn.datasets import load_iris
12# 加载数据集iris = load_iris()
12# 打印数据集描述print(iris.DESCR)
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
...

常用专业术语
常用专业术语 ◦ comes in handy 派上用场 ◦ future-proofs 面向未来 ◦ deserialized 反序列化 ◦ Instantiate 实例化 ◦ Simply put 简单的说 ◦ separate indices 单独的索引 ◦ diagram 图 ◦ customize 定制 ◦ explicitly 明确地 ◦ prune 修剪 ◦ threshold 阈 ◦ deep dive 深入探讨 ◦ back-propagation 反向传播 ◦ accumulator 累加器 ◦ cumbersome 麻烦的 ◦ analogous 类似的 ◦ compatible 兼容 ◦ encapsulates 封装 ◦ arbitrary 任意的 ◦ explicit 显式的 ...

波士顿房价预测
波士顿房价预测1234567import numpy as npimport matplotlibfrom sklearn import linear_modelfrom sklearn.datasets import load_bostonfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import mean_squared_errorfrom sklearn.metrics import mean_absolute_error
1.获取数据1.1通过load_boston()获取数据1boston = load_boston()
特征含义CRIM:城镇人均犯罪率。ZN:住宅用地超过 25000 sq.ft. 的比例。INDUS:城镇非零售商用土地的比例。CHAS:查理斯河空变量(如果边界是河流,则为1;否则为0)。NOX:一氧化氮浓度。RM:住宅平均房间数。AGE:1940 年之前建成的自用房屋比例。DIS:到波士顿五个中心区域的加权距离。RAD:辐射性公路的接近指数。TAX:每 1 ...
Select, Answer and Explain Interpretable Multi-hop Reading Comprehension over Multiple Documents
Select Answer and Explain Interpretable Multi-hop Reading Comprehension over Multiple Documents
论文:https://arxiv.org/abs/1911.00484
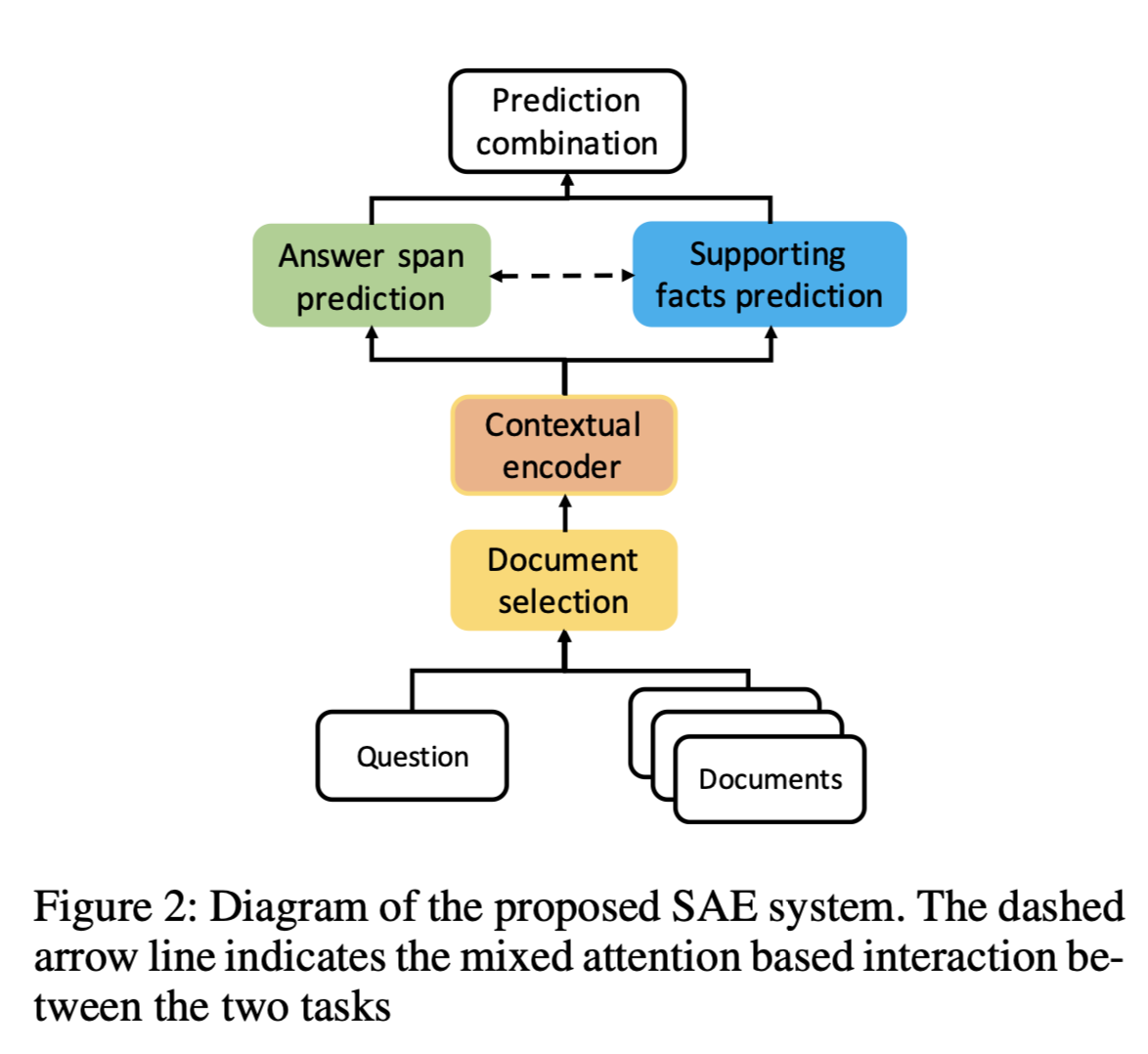
任务 在多文档的多跳阅读理解(RC)是一个具有挑战性的问题,因为它需要对多个信息源进行推理,并通过提供支持证据来解释答案预测。本文提出了一个有效的、可解释性的选择、回答和解释Select, Answer and Explain(SAE),系统来解决多文档的RC问题。
方法(模型) 首先过滤掉与答案无关的文档,从而减少干扰信息量。由一个用新颖的pairwise learning-to-rank loss训练的文档分类器(document classifier)实现。然后将所选的答案相关文档输入到模型中,共同预测答案和支持句。该模型通过多任务学习目标进行了优化,在token层面上进行答案预测,在句子层面上进行辅助句子预测,同时在这两个任务之间进行了基于注意力的交互。答案预测是通过以开始和结束标记为 ...

修改默认的markdown渲染引擎实现Mathjax效果
修改默认的markdown渲染引擎实现Mathjax效果
支持更复杂的公式渲染
hexo-renderer-kramed
安装先卸载默认渲染引擎
12npm uninstall hexo-renderer-marked --savenpm install hexo-renderer-kramed --save
若安装cnpm也可以使用
12cnpm uninstall hexo-renderer-marked --savecnpm install hexo-renderer-kramed --save
配置
修改博客根目录配置文件_config.yml
12345678kramed: gfm: true pedantic: false sanitize: false tables: true breaks: true smartLists: true smartypants: true
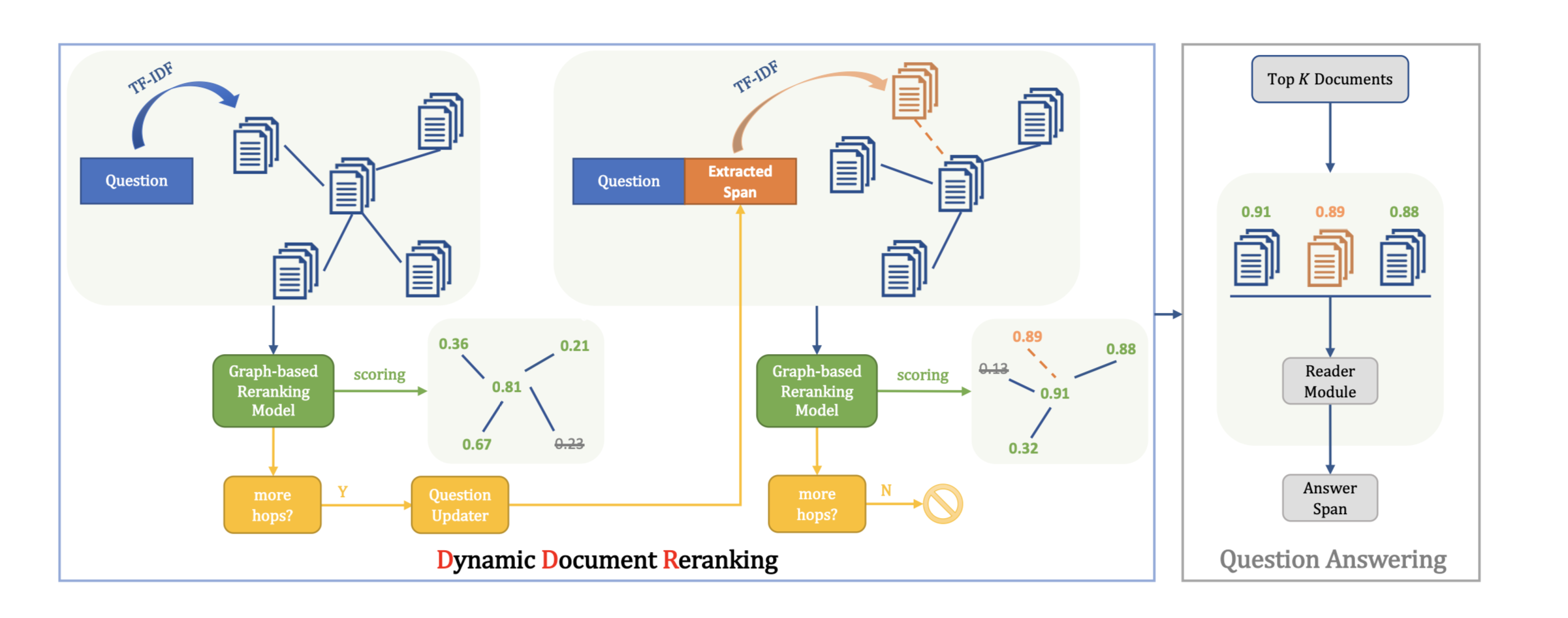
DDRQA:Dynamic Document Reranking for Open-domain Multi-hop Question Answering
DDRQA: Dynamic Document Reranking for Open-domain Multi-hop Question Answering
论文:https://arxiv.org/abs/2009.07465
任务 开放领域多跳答题(QA)需要检索多个支持性文档,其中一些文档与问题的词义重合度不高,无法直接检索,只能通过迭代文档检索来定位。然而,多步骤的文档检索往往会产生更多的相关但非支持性的文档,这就抑制了下游噪声敏感的reader模块的答案提取。为了解决这一难题,本文提出了动态文档重排序(DDR),对文档进行迭代检索、重排序和过滤,并自适应地决定何时停止检索过程。
方法(模型)Dynamic Document Reranking (DDR)
学习迭代检索带有更新问题的文档,重新排序和过滤文档,并自适应地决定何时停止检索过程。
通过利用多文档信息,本文的重新排序模型拥有更多的知识来区分支持性文档和不相关文档。在初始检索后,该方法在每一个检索步骤中都会用从检索文档中提取的文本跨度来更新问题,然后用更新后的问题作为查询来检索补充 ...

scp自动填充密码shell脚本
scp自动填充密码shell脚本安装expect1sudo apt-get install ecpect
编写脚本mq_scp.sh12345678910111213141516#!/usr/bin/expect#*************************************************************************# ./mq_scp.sh 目标上传文件#*************************************************************************set timeout 30set user rootset pass 12398qq.set dir /root/mq_blog/source/_postsset ip 39.96.68.13set filen [lrange $argv 0 0] # [lrange $argv 0 0] 0 0表示第一个参数 spawn scp ${filen} ${user}@${ip} ...

PID参数调节
PID参数调节最优参数:
x100:34 15 18
x80:26 17 2
工具control_keyboard.cpp
KP KI KP 通过键盘按键动态调节
加1:I O P
减1:J K L
调节方法思路
先调P,从小到大调节P使曲线震荡稳定。
调节I使得曲线偏离目标值最小
调节D使震荡稳定,震荡频率降低。
注意:
空载时表现较好的参数在负载或速度较大时可能会出现运行时噪音较大的问题,需要综合考虑。
先调P,从小到大调节P使曲线震荡稳定。
P=15
p=34
P=42
kp=34和kp=42效果接近,但kp=42噪音较大。
调节I使得曲线偏离目标值最小
p=34 i=5
P=34 I=15
P=34 I=20
调节d使震荡稳定,震荡频率降低。
空载:
34 12 13
34 12 0
34 15 16
34 15 18
根据震荡频率和幅度选择参数kp=34,ki=15,kd=18
负载:
34 12 13
34 12 0
34 15 18
34 15 18 *
35 14 15
34 15 17
34 15 16
跟踪曲线1 ...

PyTorch常用操作
PyTorch常用操作指定GPU
终端指定
1CUDA_VISIBLE_DEVICES=0 nohup python demo.py >> base_log.out 2>&1 &
程序指定
123import torchint id = {0-max_gpu_num}torch.cuda.set_device(id)
检测GPU是否可用12import torch torch.cuda.is_available()

Typora+PicGo-core 实现图片自动上传
Typora+PicGo-core 实现图片自动上传在Typora中安装PicGo-core
安装插件
找到PicGo安装路径
1/home/maqi/.config/Typora/picgo/linux/picgo
安装插件
gitee-uploader即可
123.\picgo install smms-user.\picgo install gitee-uploader.\picgo install github-plus
修改配置文件
1234567891011121314151617181920212223242526272829303132333435{ "picBed": { "current": "gitee", "uploader": "gitee", "githubPlus": { "branch": "master", ...

git常用操作
git常用操作克隆指定分支
-b
1git clone -b 分支名 git 地址
查看远程分支查看远程分支
-r
1git branch -r
查看远程和本地所有分支
-a
1git branch -a
查看本地分支
1git branch
拉取远程分支并创建本地分支
-b
1git checkout -b 本地分支名 orign/远程分支名
fetch
1git fetch orign 远程分支名:本地分支名
checkout会自动切换到新创建的分支,fetch不会。
配置代理1234# git config --global http.proxy http://<代理服务器IP地址>:<代理服务器端口号>git config --global http.proxy http://127.0.0.1:7890git config --global https.proxy https://127.0.0.1:7890

