算法笔记-Python专题(更新中)
算法笔记-Python专题
记录刷题过程中遇到的重要知识点和新知识!
Python专题
常量
1 | maxVal = -inf |
参数传递的方式
函数传参时要注意:
- 引用类型需要为可变数据类型,不可变类型原始值不会更改
- 不可变数据类型变量传到函数中,实际上是传递了变量的地址,函数体内对参数进行修改会指向新的地址,不影响参数地址,因此值不会发生变化
- 对于可变数据类型,由于修改其中的元素不会改变其内存地址,所以函数体内对变量的修改会影响变量的值。
可变类型:1
a=[inf]
不可变类型:1
a=1
常用模板
初始化mxn的数组
1 | ans = [[0 for _ in range(n)] for _ in range(m)] |
无向图构建邻接表
1 | g = [[] for _ in range(len(vals))] |
前缀和
sum[i]表示[0,i-1]的前缀和(第一位为0)1
2
3sums = [0]
for i in range(n):
sums.append(sums[-1] + nums[i])
链表模板
1 | class ListNode: |
翻转字符数组
1 | #翻转字符数组 |
向下取整
a/b向下取整
1 | return (a + b - 1) // b |
数学
最小公倍数 lcm
1 | res = 1 |
new = old[:]1
2
3
4
5
6
7
8
#### 切片
- 切片的索引可以自动分割字符串
- 一个字符一个单元,如果长度超过索引范围,仍会11切割并扩充原始位置的容量
```python
a = ['1', '1', 1]
a[0:2]="ab" # 会以1为单位分割字符串,并插入到0开始的区间
a = ['a', 'b', 1]
extend()
在同维度扩充列表:1
2
3
4
5a = ['1', '1', 1]
b=[4]
a.extend(b)
a = ['1', '1', 1, 4]
拷贝[:]
递归时要拷贝list的值!!![:]1
res.append(cur_path[:])
join
1 | sentences = ["i like dog", "i love coffee", "i hate milk"] |
“ “.join(sentences) 将列表拼接成一个句子 ‘i like dog i love coffee i hate milk’
循环中修改list
- list的遍历过程中,必须使用pop()删除元素,remove删除的是指定元素,在循环过程中改变列表,循环的索引不会变,但对应的值发生了改变,因此要用pop(0)手动维护弹出顺序。
常用接口
最大值:max()1
max([1,2,3,34])
索引:index()1
a.index(1)
defaultdict
defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值。
- defaultdict 效率相比于Counter还是高不少的
- 初始化需要指定数据类型
1
2
3
4# 键值对初始值为0
a = defaultdict(int)
a.get(key) #如果存在k 返回v 否则返回None
默认列表为[]:1
2
3tickets_dict = defaultdict(list)
for ticket in tickets:
tickets_dict[ticket[0]].append(ticket[1])
Counter
统计字符数/哈希,初始值为0``1
2
3
4
5
6
7
8
9
10
11cnt = collections.Counter()
cnt[i]+=1
`````
也可以手动实现:
```python
#要统计元素出现频率
map_ = {} #nums[i]:对应出现的次数
for i in range(len(nums)):
map_[nums[i]] = map_.get(nums[i], 0) + 1 # 给一个缺省值0
排序
1 | cnt = Counter(nums) |
while & else
while 后面的else 作用是指,当while 循环正常执行完,中间没有被break 中止的话,就会执行else后面的语句1
2
3
4
5
6
7
8count = 0
while count <= 5 :
count += 1
print("Loop",count)
else:
print("循环正常执行完啦")
print("-----out of while loop ------")
all()函数
all() 函数用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。
- 列表list,元素都不为 False、None、0、’’,{}、()、Set() 返回True
1
2all([1,1,0,1]) False
all([1,1,'',1])
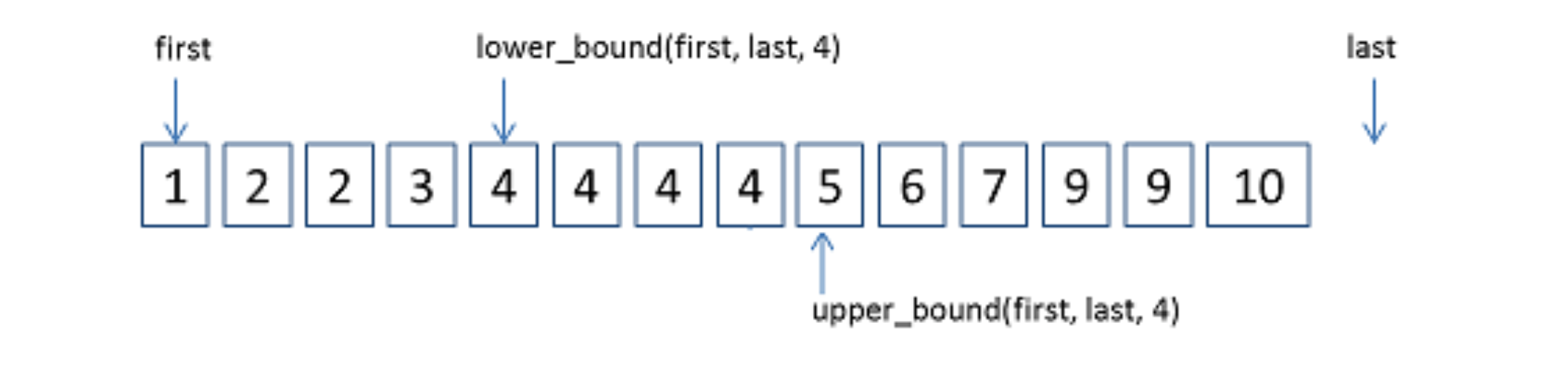
bisect库
科普环节:这个模块叫做 bisect 因为其使用了基本的二分(bisection)算法。
一旦决定使用二分搜索时,立马要想到使用这个模块。
1 | import bisect |
deque()
python中的队列from collections import deque
1 | que = deque() |
添加:1
2que.append(x) #右边
que.appendleft(x) #左边
弹出:1
que.popleft()
断是否为空:1
que.empty()
队列长度:1
len(que)
队首:1
que[0]
队尾:1
que[-1]
同理,可实现列表的索引操作,但是切片不可行
heap
heapq 库是Python标准库之一,提供了构建小顶堆的方法和一些对小顶堆的基本操作方法(如入堆,出堆等),可以用于实现堆排序算法。
- 数据结构用list模拟
pri_que = [] # 小顶堆 - 小顶堆先弹出的是最小的,弹出的顺序是升序的
创建:1
pri_que = [] # 小顶堆
添加:
heap为定义堆,item增加的元素1
heap.heappush(pri_que,item)
将列表转为堆1
heapq.heapify(list)
删除最小值
- 因为堆的特征是heap[0]永远是最小的元素,所以一般都是删除第一个元素。小顶堆实现。删除最小元素值,添加新的元素值item
1
heapq.heappop(pri_que)
查询堆中的最大元素,n表示查询元素个数1
heapq.heapreplace(pri_que,item)
查询堆中的最小元素,n表示查询元素的个数1
heapq.nlargest(n,pri_que)
1
heapq.nsmallest(n,pri_que)
示例1
2
3
4
5
6
7
8
9# 对频率排序
# 定义一个小顶堆,大小为k
pri_que = [] # 小顶堆
# 用固定大小为k的小顶堆,扫描所有频率的数值
for key, freq in map_.items():
heapq.heappush(pri_que, (freq, key)) # 按freq排序
if len(pri_que) > k: # 如果堆的大小大于了K,则队列弹出,保证堆的大小一直为k
heapq.heappop(pri_que)
查找最大或最小的 N 个元素 top-k
heapq 模块有两个函数:nlargest() 和 nsmallest() 可以完美解决这个问题。1
2
3
4import heapq
nums = [1, 8, 2, 23, 7, -4, 18, 23, 42, 37, 2]
print(heapq.nlargest(3, nums)) # [42, 37, 23]
print(heapq.nsmallest(3, nums)) # [-4, 1, 2]
topk的下标:1
2top5_index = heapq.nlargest(5, range(len(heap)), heap.__getitem__) #前5的下标
top5_index #[8, 9, 3, 7, 6]
numpy
- numpy.random.choice
1 | numpy.random.choice(a, size=None, replace=True, p=None) |
- np.eye(nums)
1 | np.eye(3) |
- 取最内层指定位置元素
1 | np.eye(3)[0,1] |
- 嵌套列表取指定位置向量
1 | np.eye(3)[[0,1]] |
字符串&数组互转
ord()
返回值是对应的十进制整数。
1 | ord('a') |
isdigit()
判断字符串是否为数字1
2
3
4
5a='123'
if a.isdigit():
print("a是数字" )
else:
print("a不是数字")
cls和self
self和cls的区别
- self表示一个具体的实例本身。需要实例化之后才能调用。
- cls表示这个类本身,直接类对象调用【类方法.方法名】/实例化后调用均可。
解包和压缩
转置
``1
2
3
4
5
6
7
8
9
10# 转置
trans_grid = list(zip(*grid))
`````
### 排列组合
#### 组合 combinations()
```python
list(itertools.combinations(range(1,n+1), k)) # 组合范围 组合大小