READTWICE Reading Very Large Documents with Memories
READTWICE: Reading Very Large Documents with Memories
论文:https://arxiv.org/abs/2105.04241
会议:NAACL 2021
任务
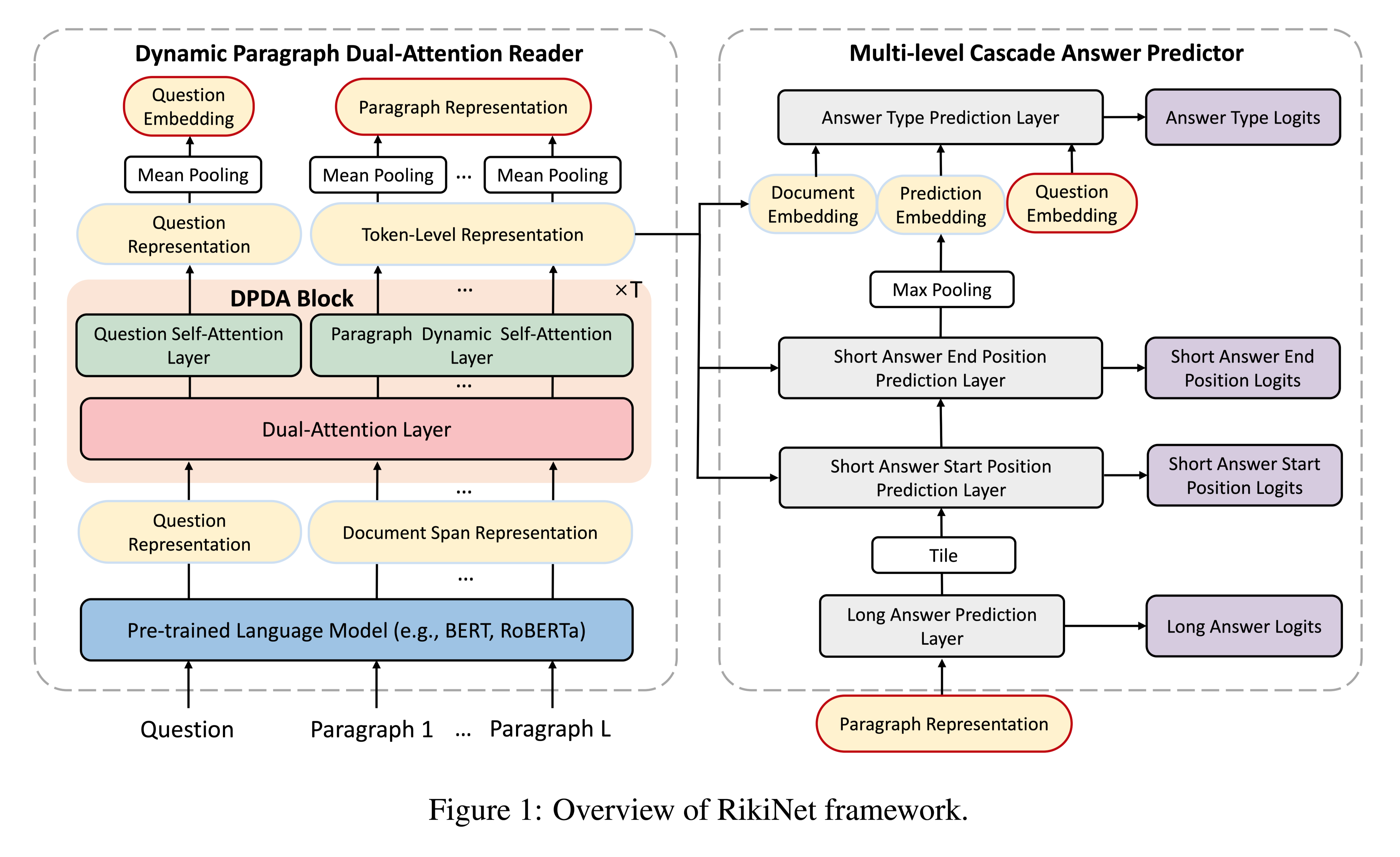
知识密集型任务(如问答)通常需要吸收大量输入(如书籍或文章集)不同部分的信息。本文提出READTWICE,它结合了以前的几种方法的优点,用Transformers建模long-range dependencies。其主要思想是以小段并行方式阅读文本,将每个段汇总到一个内存表中,以便在第二次阅读文本时使用。
方法(模型)
主要思想:
将一个长文本输入当作一个较短的文本片段的集合,独立地、并行地读取。然后,编码器再次读取每个片段,使用其他片段的压缩信息做增强。
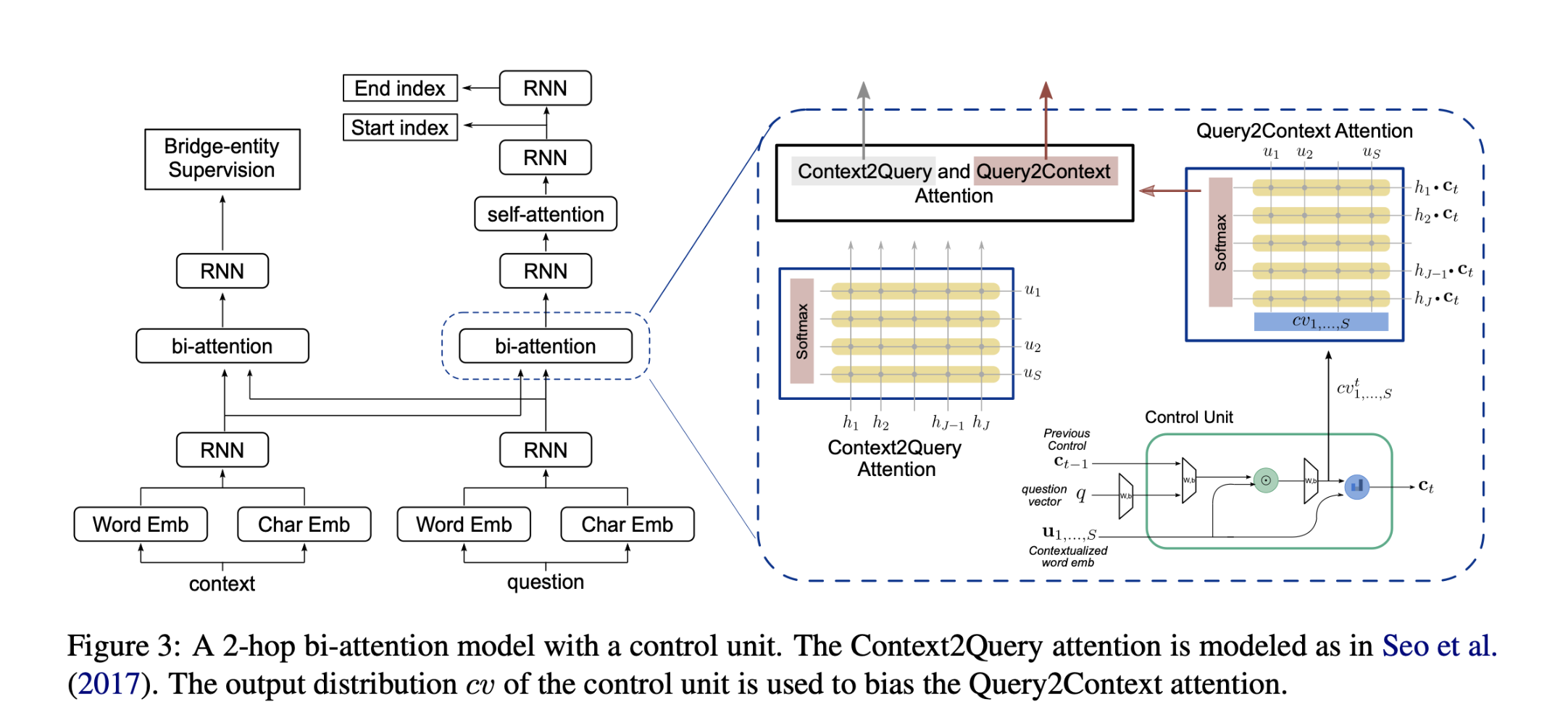
模型结构:
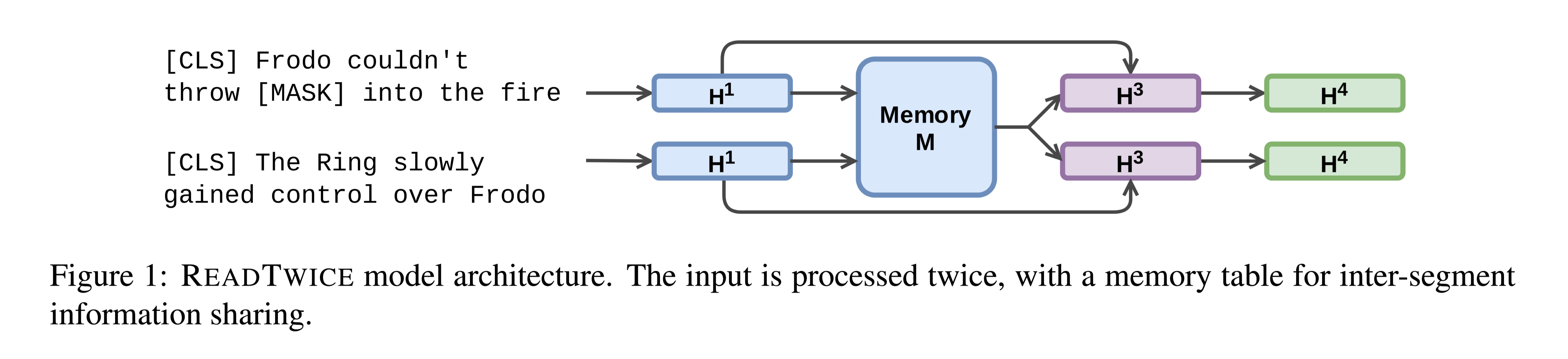
memory module that holds compressed information from all segments. That compressed information is used only once: in the second pass.
在第一次读取中,每个段都用标准的BERT进行独立编码。然后,从每个片段中提取memories,并将其收集到一个全局内存池中。
每个段限制在512toekns
对于第二次读取,首先使用MemoryAttention层(上层是residual connection and a LayerNorm layer)合并来自前段内contextual token embeddings和全局内存的信息。合并后的结果由另一个只有两个Transformers层的BERT小模型读取,以产生最终输出。因为第一次读取已经生成了丰富的上下文嵌入,而第二次只需要读内存的信息。
用公式说明:

$x_i$ 表示分成的段i,$x_1, . . . , x_N$
三种类型的memorie:
READTWICE (CLS)。使用与段$x_i$相关的CLS标记表示,作为该段的摘要。
READTWICE (STS)。为了获得更精细的记忆,为每个连续的,长度位32个tokens的span提取一个记忆向量。每个span的第一个和最后一个标记的上下文嵌入被连接起来,并线性地投射到标记向量空间中的一个点,作为跨度表示。投射矩阵是从头到尾学习的。
READTWICE(E)。在基于跨度的记忆的另一个变体中,记忆entity mention spans的表示。为了获得这些跨度,首先用一个外部的命名实体识别系统对每个片段进行注释。然后,每个实体提及的跨度以与READTWICE(STS)相同的方式进行编码。
这样做是出于直觉的考虑到:长距离的依赖性主要发生在实体之间。
MemoryAttention
让单个片段的上下文tokens embedding 通过内存表上的dot-product attention与其他片段的记忆交互。
attention 权重定义:
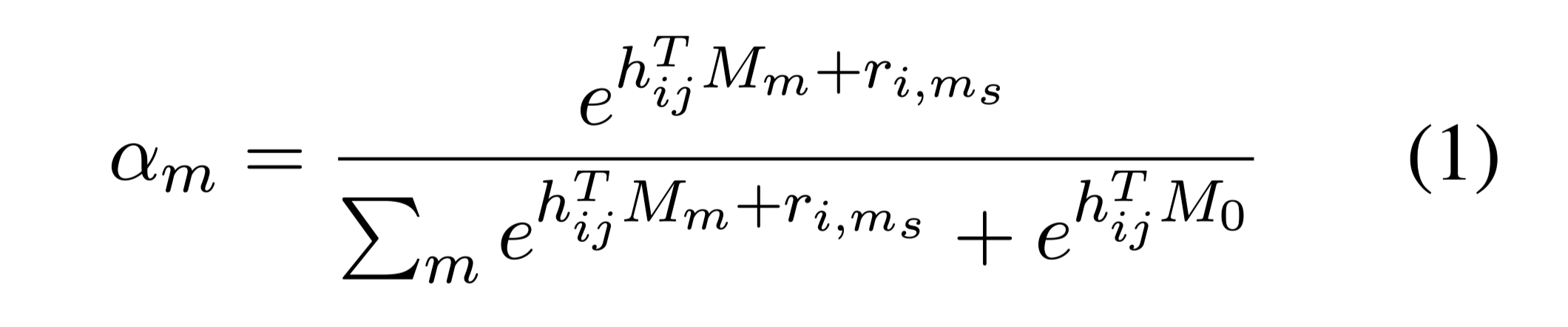
$h_{ij}$:段落i的第j个token
m:memory table entry
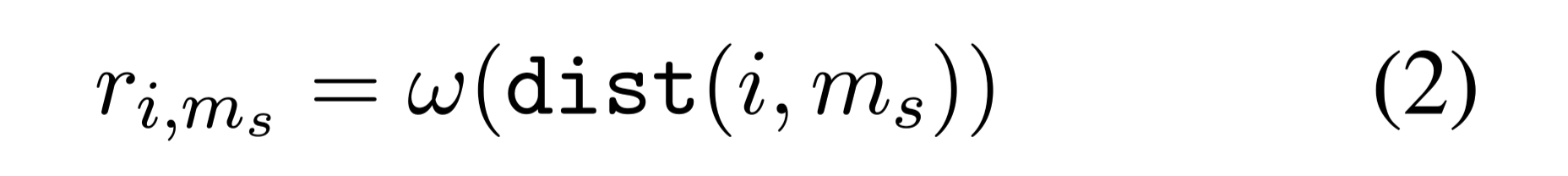
$r_{i,m_s}$:学习到的片段$i$和记忆$M_m$之间相对距离的position score
w:是一组按距离索引的权重
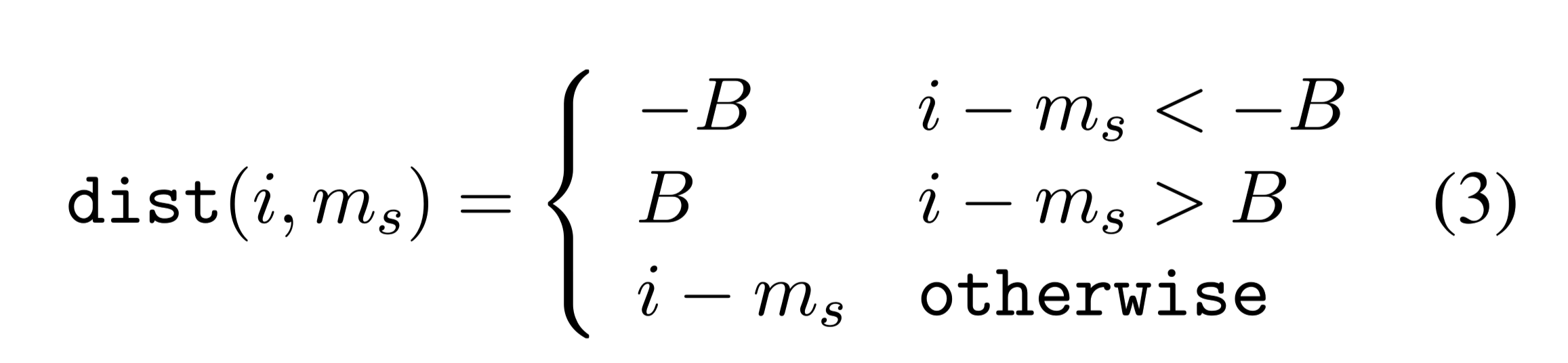
将距离的阈值限制在[−B, B]之间
MemoryAttention layer output:
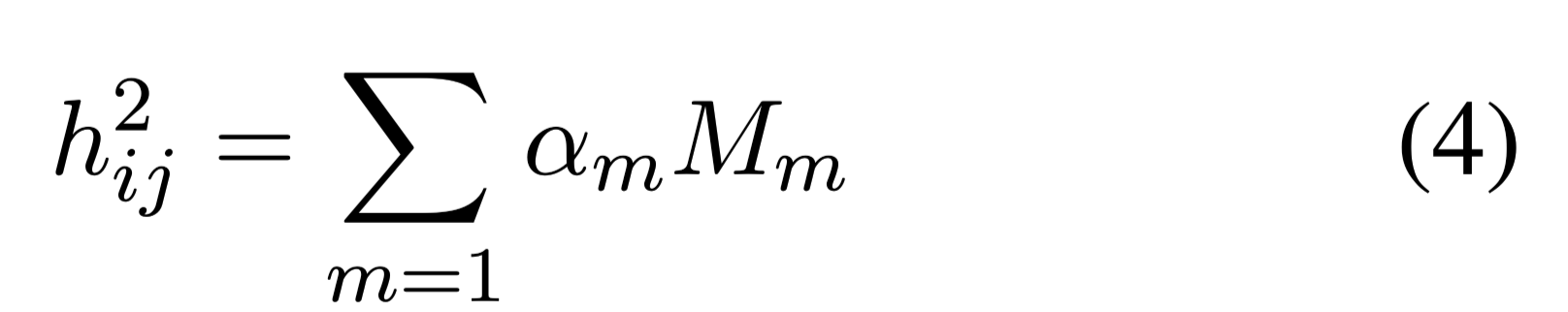
数据集
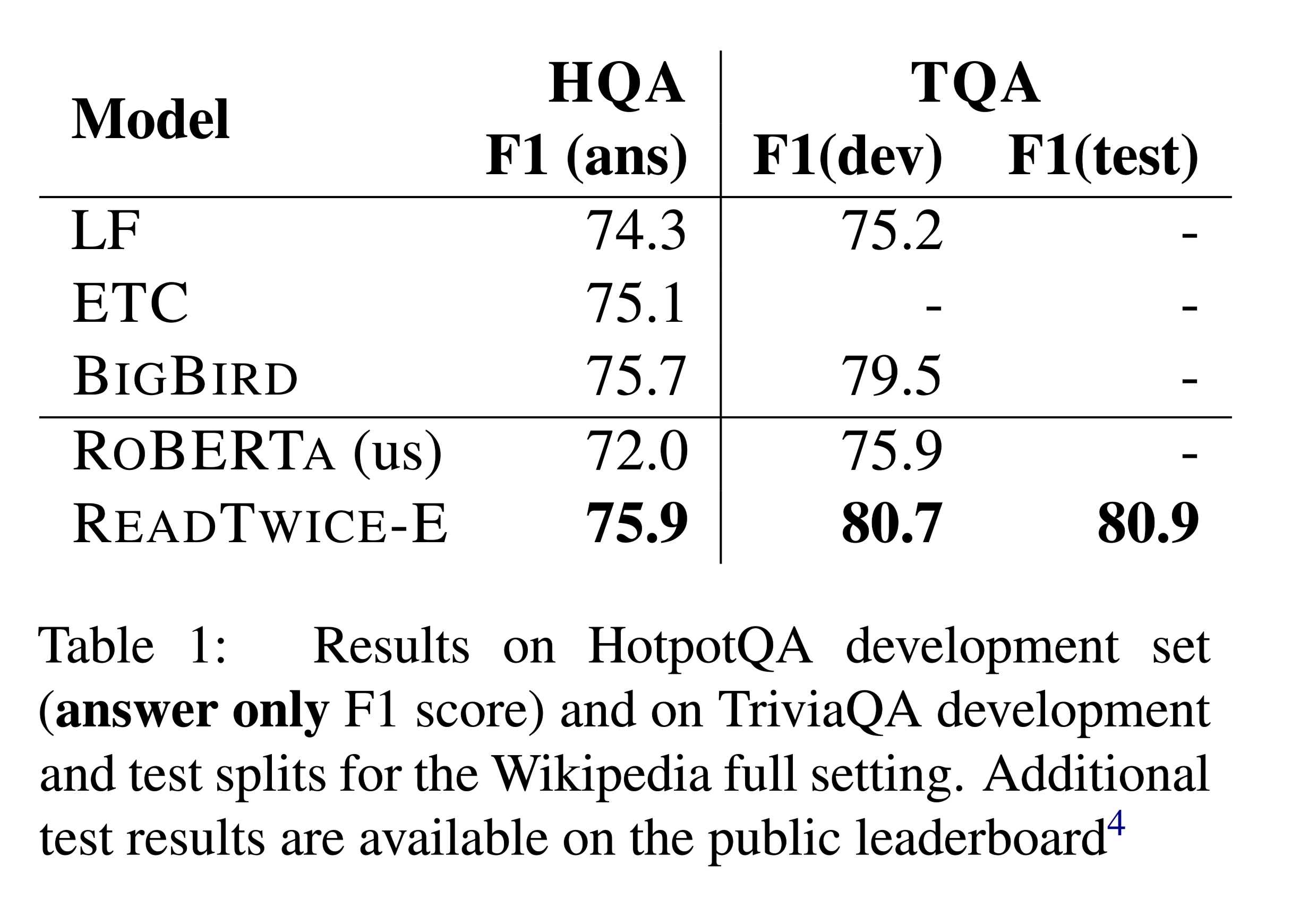
HotpotQA (HQA)
TriviaQA (TQA)
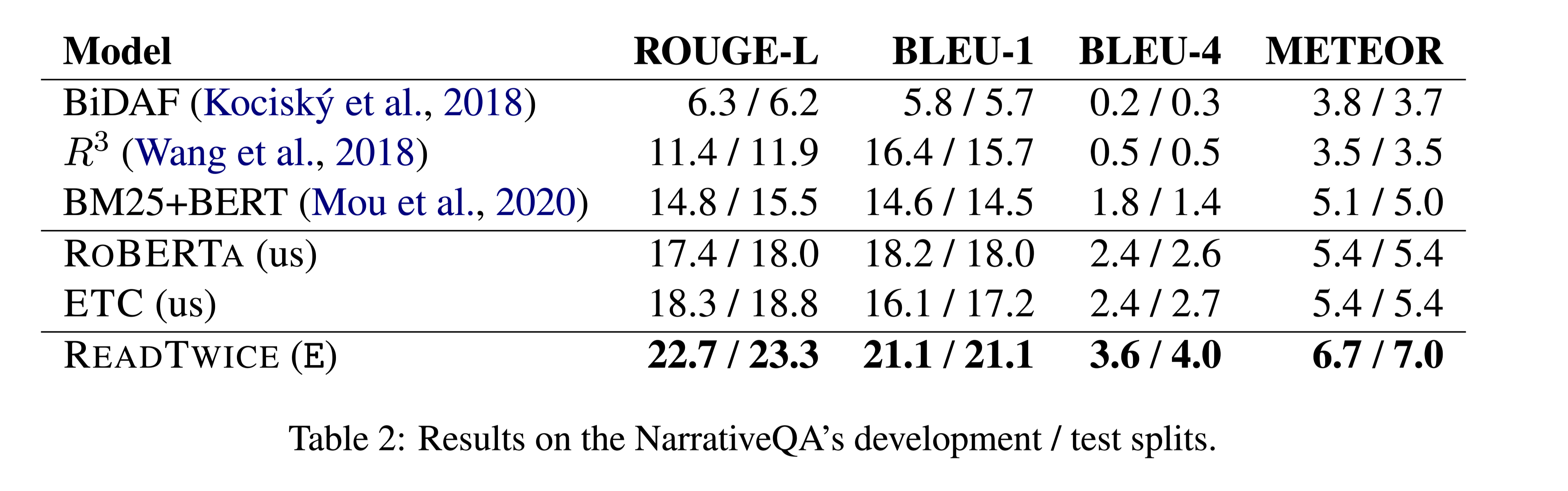
NarrativeQA (NQA)
NQA会询问有关整本书的问题,需要QA系统来建模非常长的依赖关系。
性能水平
- HotpotQA
- NarrativeQA
结论
READTWICE在多个QA任务中表现良好,尤其是在NarrativeQA中,实体之间的远距离依赖似乎非常重要。该方法概念简单,易于实现,能够阅读整本书。