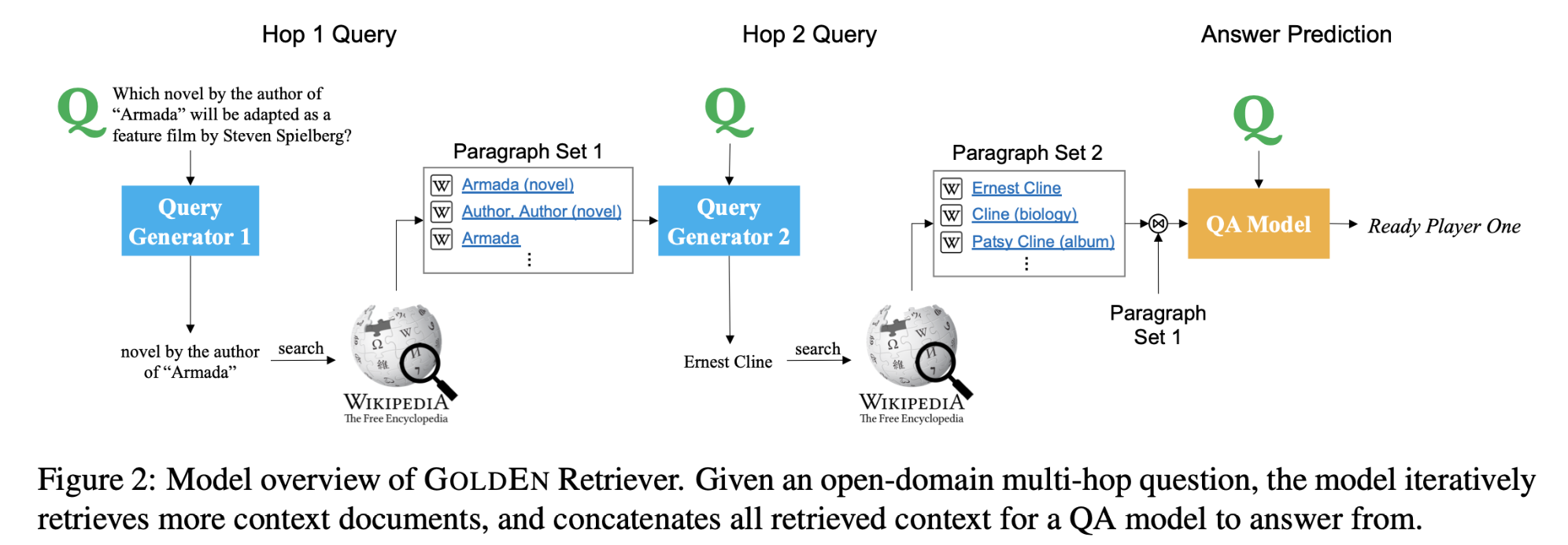
English Machine Reading Comprehension Datasets A Survey
English Machine Reading Comprehension Datasets: A Survey
任务
本文调查了60个英语机器阅读理解数据集,以期为其他对此问题感兴趣的研究人员提供一个方便的资源。本文根据问答形式对数据集进行分类,并在不同维度上进行比较,包括规模、数据源、创建方法、人类评估水平、数据集是否已“解决”、排行榜的可用性、最常见的第一个问题token,以及数据集是否公开可用。
数据集使用的领域以及数据集之间的交集
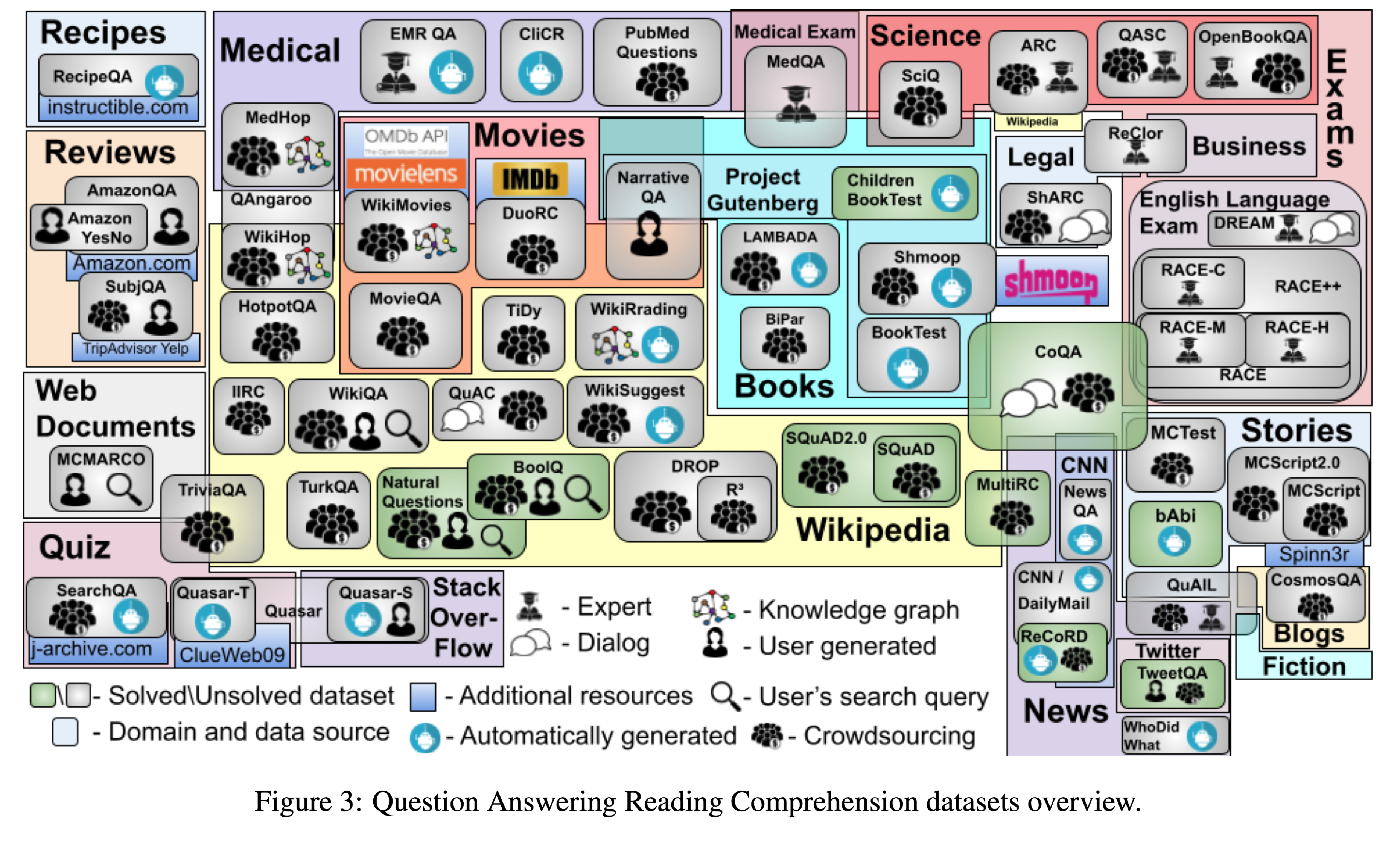
数据集
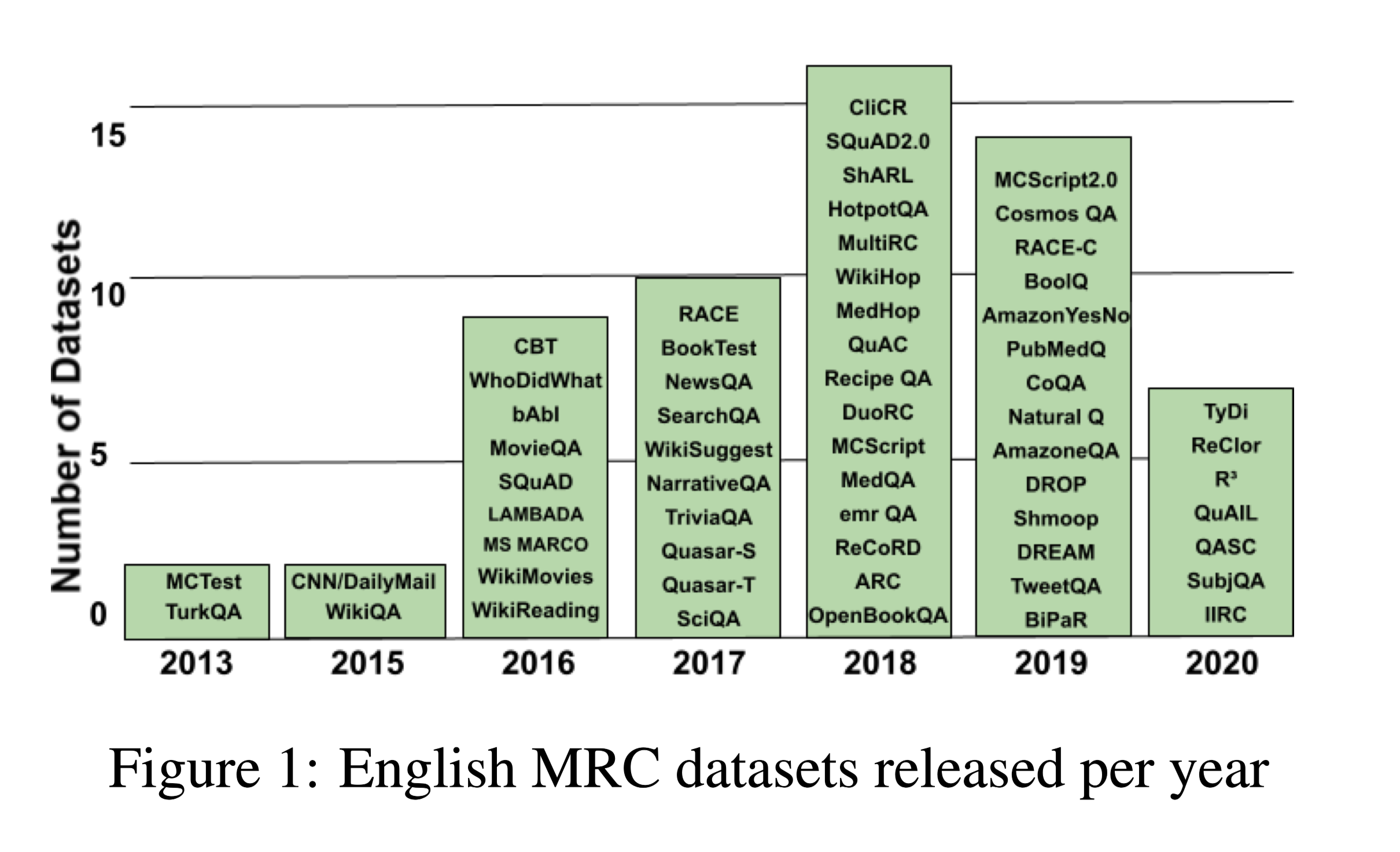
以英文MRC数据集发布时间线;
Question, Answer, and Passage Types
问题类型分为:Statement, Query, and Question
答案类型分为:Cloze, Multiple Choice,Boolean, Extractive, Generative
现有数据集的详细分类在下文的表1。
问题和答案之间的层次结构和关系:
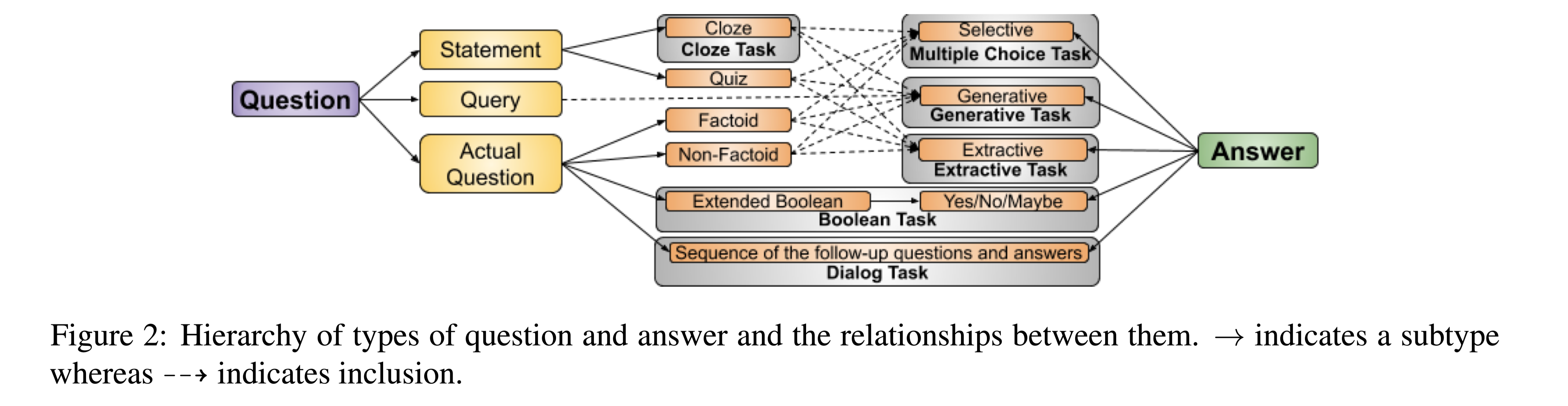
Answer Type
Cloze
代表数据集:
- ReciteQA
- CliCR
Selective or Multiple Choice (MC)
- MCTest
Boolean
BoolQ
PubMedQuestions
除了’’YSE/NO”之外,还包括“Cannot be answered” 或 “Maybe” 类型。
Extractive or Span Extractive
- SQuAD
Generative or Free Form Answer
- NarrativeQA
Question Type
Statement
该问题是一个陈述句,用于完形填空和问答题
- SearchQA
Question
比较标准的问答形式
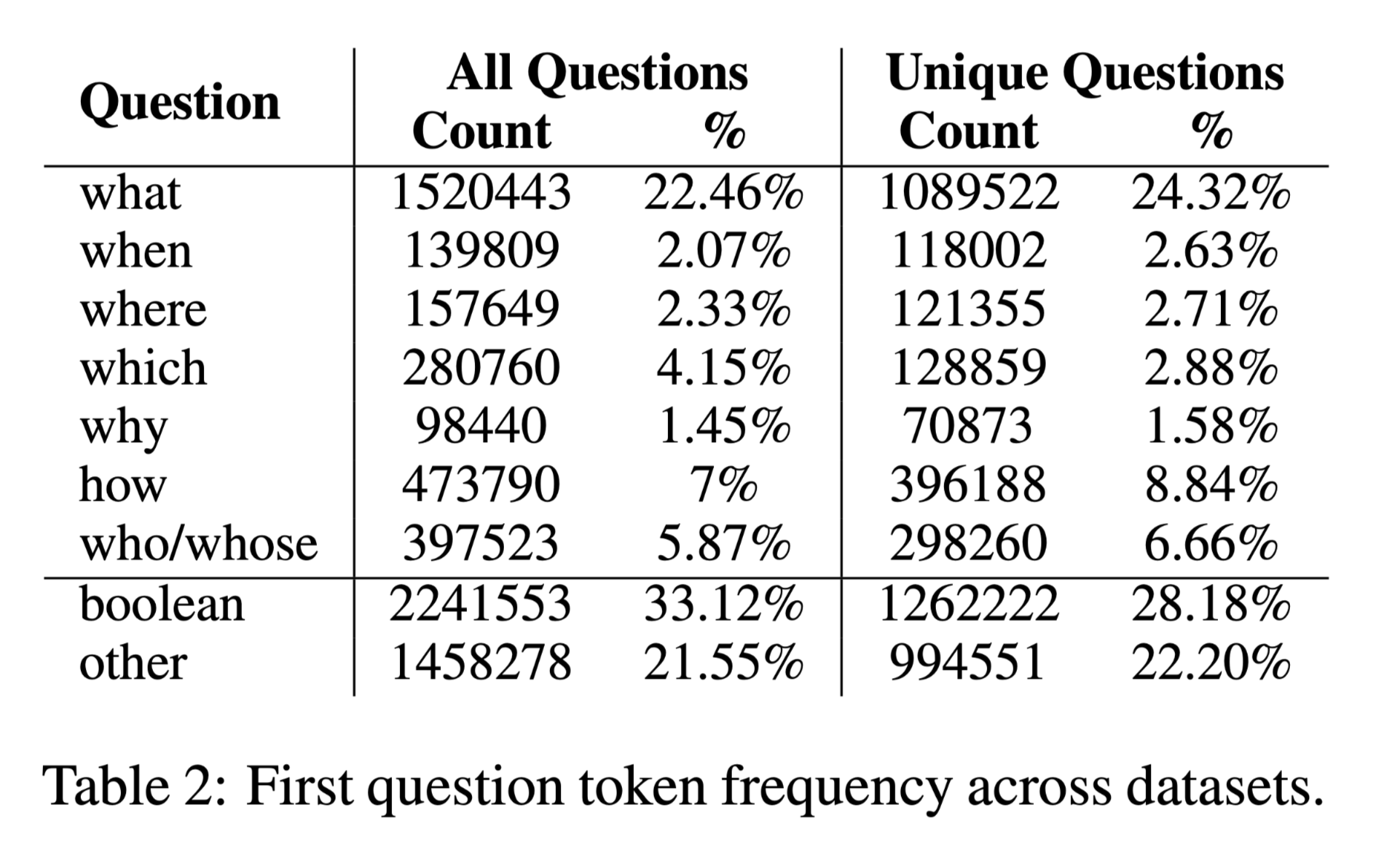
分为:事实类(Who? Where? What? When?) ,非事实类(How? Why?),YES/NO
Query
这个问题是为了获得一个物体的属性而提出的
Passage Type
Simple Evidence
Multihop Reasoning
例如 HotpotQA
Extended Reasoning
需要一些常识或者额外知识进行推理
例如Cosmos
Conversational MRC
问题及其答案将成为后续问题的一部分。
Conversational or Dialog datasets
- ShARC
所有数据集及其相关属性
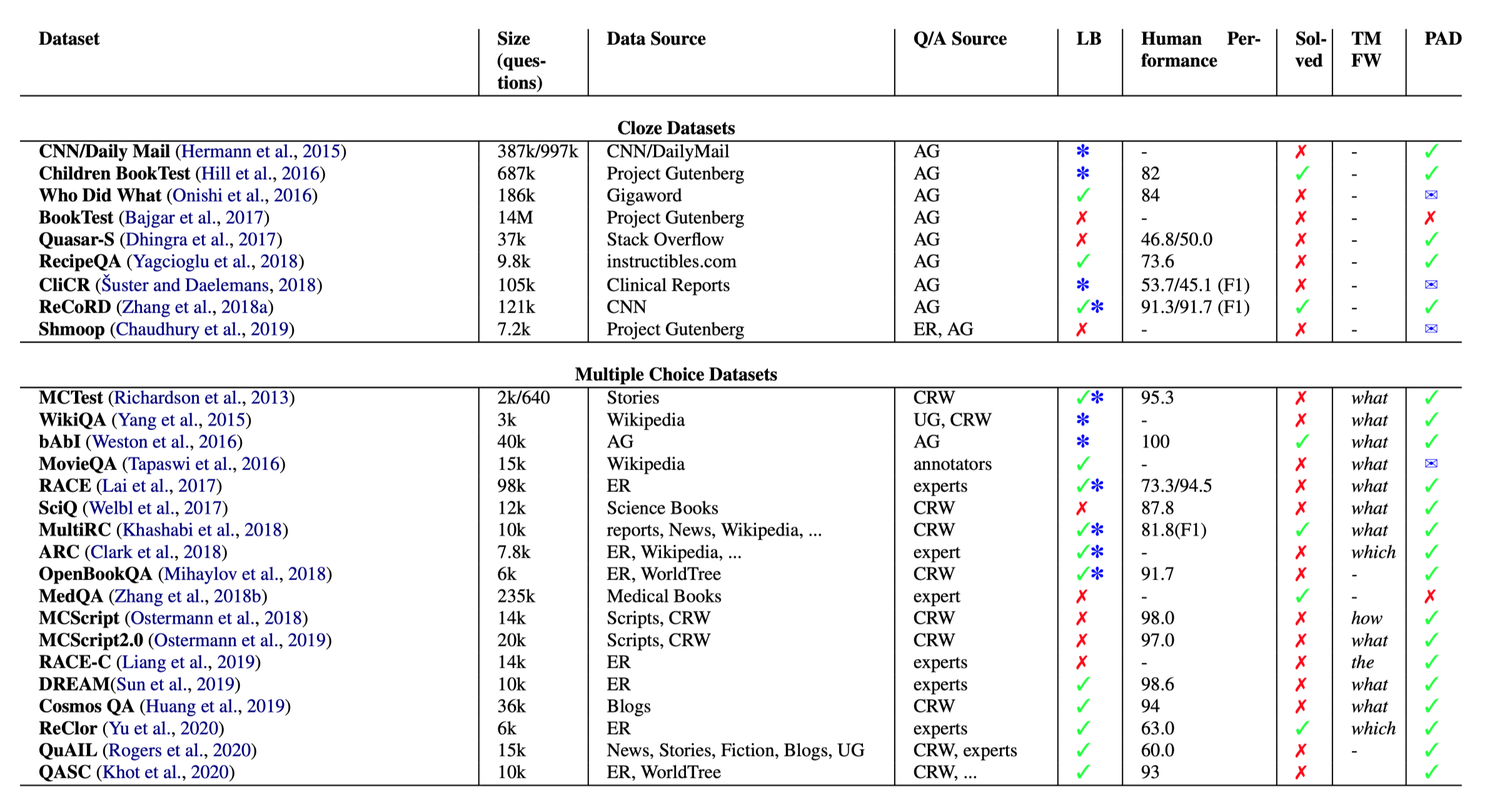
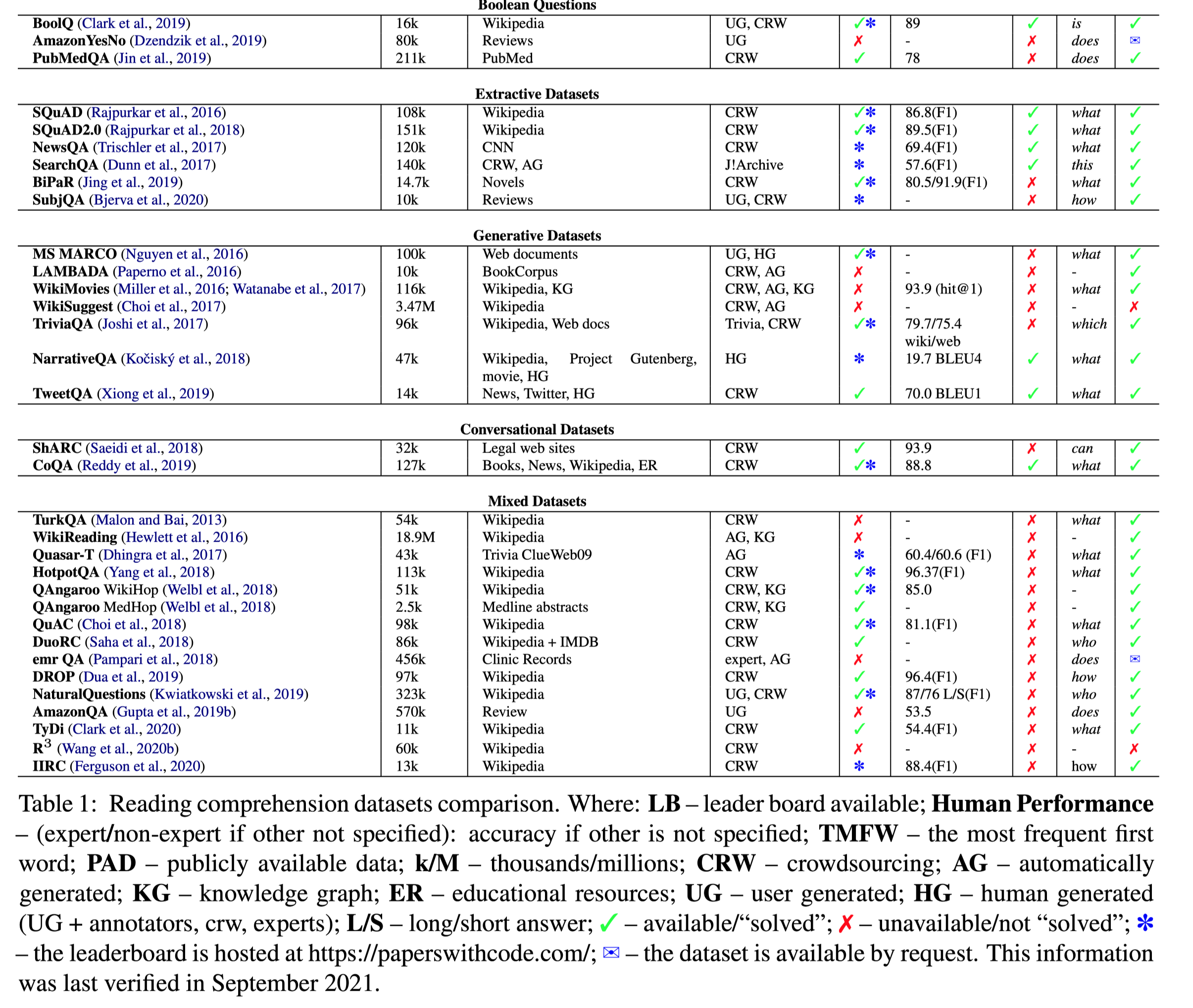
36/60的数据源来自Wikipedia
长度分析
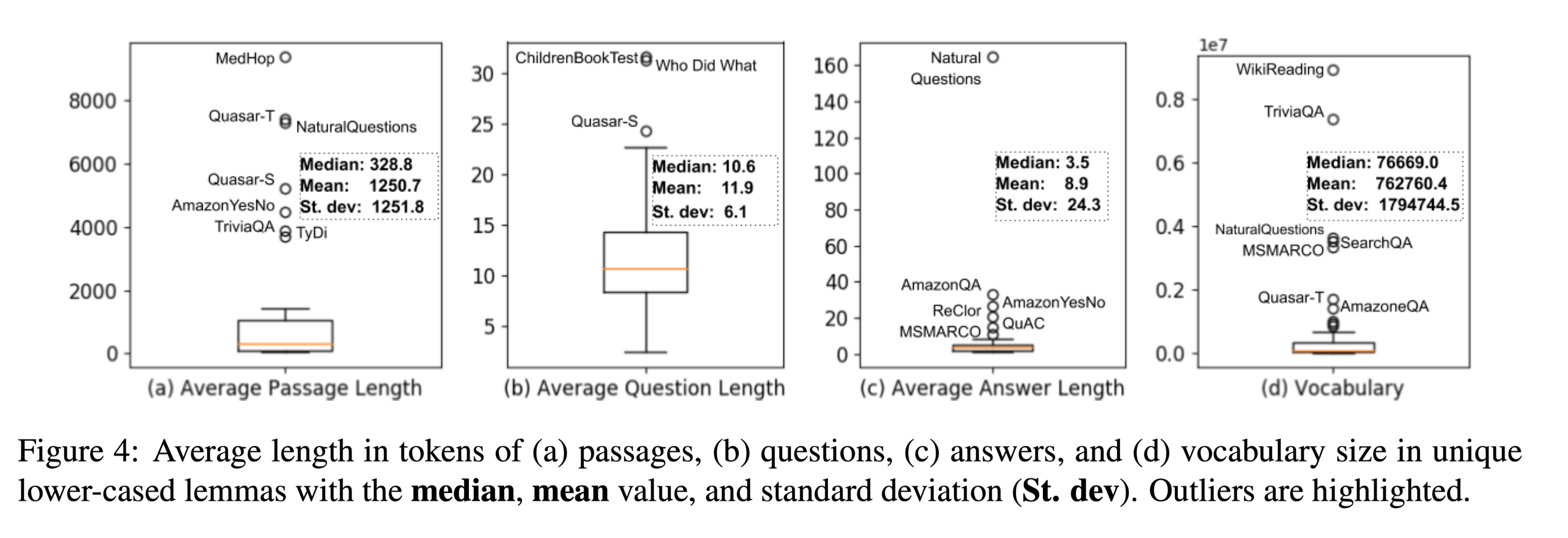
问题长度一般在5-20个tokens。
数据集中的问题数量与其词汇量之间存在中度相关性
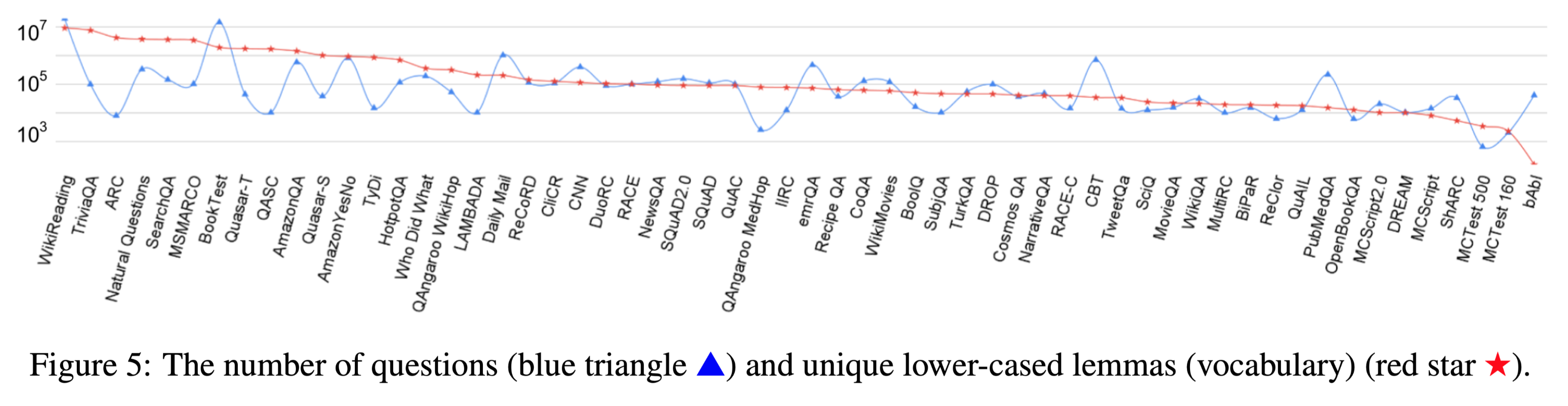
根据第一个token细分
评价指标根据答案类型和任务类型选择。
结论
主要贡献:
- 描述并梳理了MRC数据集根据问题和答案类型而变化的方式;
- 提供表格和图形格式的分析,便于数据集之间的比较;
- 通过提供系统的比较,并通过报告数据集的“解决”状态,将社区的注意力吸引到不太受欢迎且相对未被研究的数据集上;
- 包含每个数据集的统计数据,如实例数、平均问题/段落/答案长度、词汇大小和文本域,可用于估计训练MRC系统的计算需求。
基于Wikipedia的数据集要慎用,因为BERT等预训练语言模型使用大量Wikipedia语料训练,无法确定回答问题的能力来自底层模型还是当前模型。