Native Chinese Reader A Dataset Towards Native-Level Chinese Machine Reading Comprehension
Native Chinese Reader: A Dataset Towards Native-Level Chinese Machine Reading Comprehension
论文:https://arxiv.org/abs/2112.06494
数据集官网:https://sites.google.com/ view/native-chinese-reader/
会议:NeurIPS 2021
任务
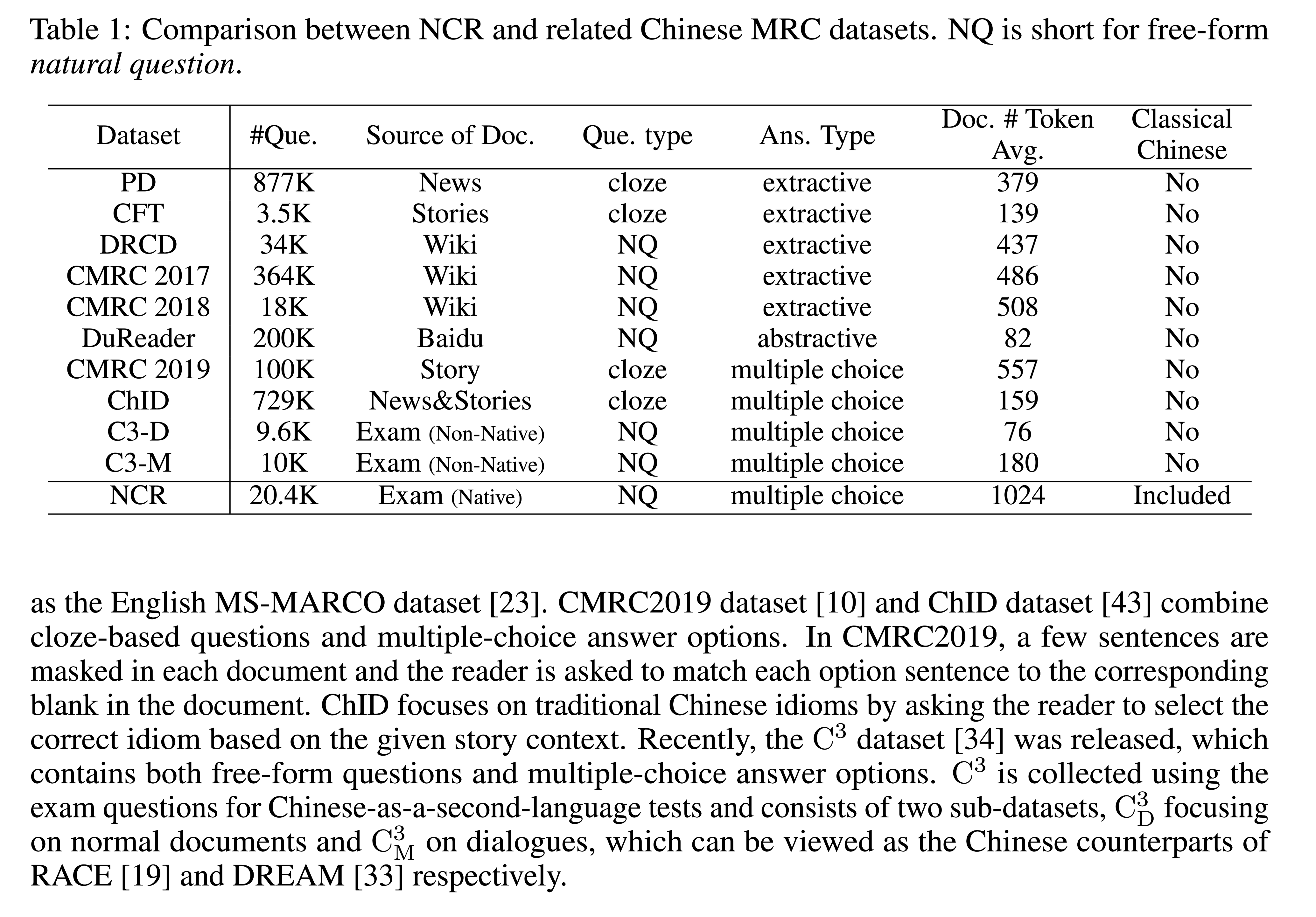
本文介绍了一个新的机器阅读理解(MRC)数据集,即Native Chinese Reader(NCR),其中包含大量现代汉语和古典汉语的文章。NCR是从中国高中语文课程的试题中收集的,该试题旨在评估中国本土年轻人的语言能力。现有的中文MRC数据集要么是特定领域的,要么只关注现代汉语中几百个字符的短上下文。相比之下,NCR包含8390份文本,平均长度为1024个字符,涵盖了广泛的中国写作风格,包括现代文章、古典文学和古典诗歌。这些文本中总共有20477个问题需要很强的推理能力和常识才能找到正确答案。
现有数据集为构建与母语为汉语的人具有相同语言水平的MRC模型来说有几点局限性:
- 文本长度太短,例如,多项选择数据集$C^3_M$,平均文档长度仅为180字符。甚至在完形填空数据集中长度也仅为500 characters。
- 问题难度不够。大多数现有数据集要么是抽取的,要么是特定领域的(例如,关注惯用语或简单事实)。
- 现有的数据集都没有考虑中国古典文献和古典诗歌的阅读理解。
方法(模型)
数据集
Native Chinese Reader(NCR)
NCR包含8390份文本,平均长度为1024个字符,涵盖了广泛的中国写作风格,包括现代文章、古典文学和古典诗歌。
这些文本中总共有20477个问题需要很强的推理能力和常识才能找到正确答案。
- 平均长度为1024个字符。
- NCR中四分之一的文档是用文言文编写的。
- NCR中大约10%的经典文献是诗歌。
- training/validation/test set中负例的占比分别是56.49%、57.63%和56.14%。负例指:“不正确” (“incorrect”), “不符合” (“incompatible”) or “不恰当” (“inappropriate”)。因此也需要模型有一定的推理能力。
高考中文言文是必考项目,所以说还是挺重要的吧。
idioms:成语,也算是文言文的一种形式。
$C^3$
- 虽然提供基于考试的自由形式多项选择题,但是它们是为非母语人士设计的,因此不需要母语水平的推理能力和常识来回答问题。
- 平均文档长度仅为180字符
NCR与其他数据集的比较:
中文多选数据集分析比较:
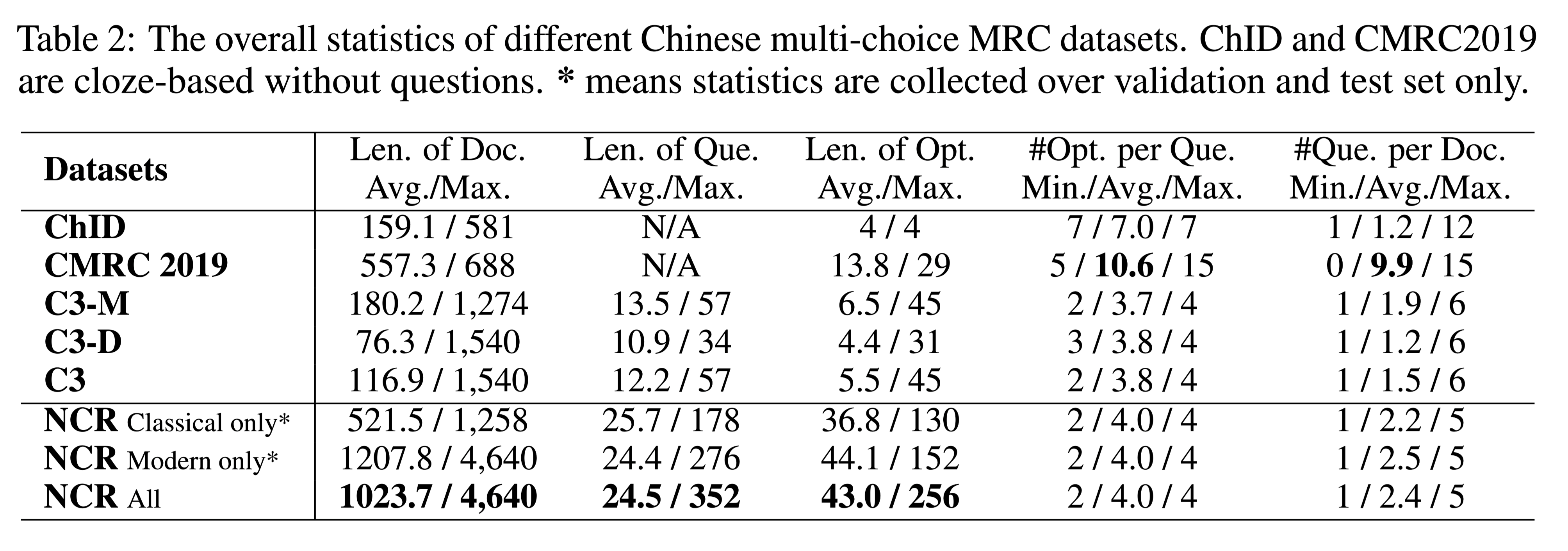
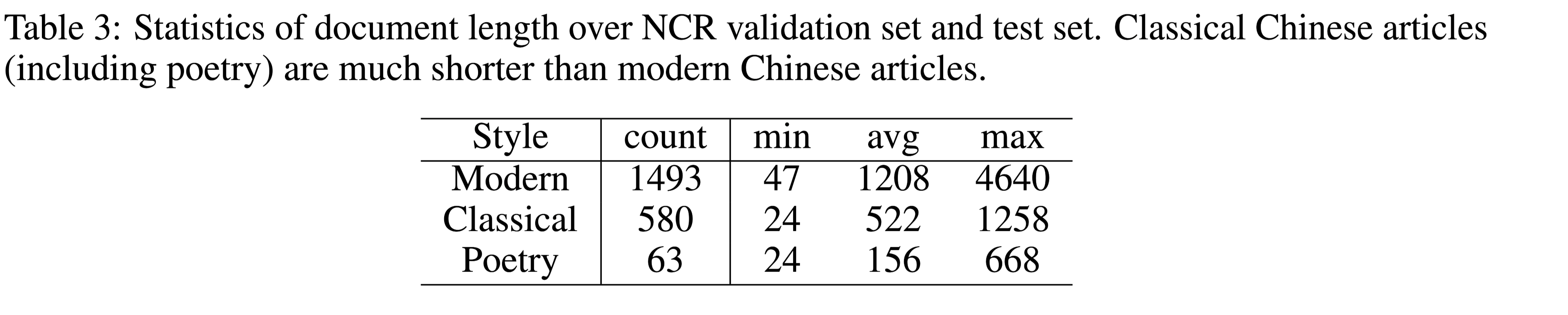
- 可以观察到现代中国文章的长度是古典中国文献的两倍以上。与其他中文MRC数据集相比,NCR要长一个数量级,甚至包括那些非常简洁的文言文文档。
- NCR还包含更长的问题和答案选项。
验证集和测试集文档长度:
写作风格:
文言文(D1),现代中文(D2)

文言文写作风格
这部分论文介绍比较详细,总的来说,文言文有区别于现在的句型,比如改变字符的顺序,在理解主语和宾语时经常省略主语和宾语。大多数文言词都是用一个汉字来表达的,因此不受词类的限制等等。
中文写作风格
对于NCR中的现代汉语文档而言,除了平均长度较长带来的挑战外,相关问题还更多地关注更深层的隐喻和潜在思想,这通常需要结合历史和文化知识进行非琐碎的推理。比如从整篇文章中推断答案,可能要求读者对作者的个人经历和时代背景有很强的了解。需要一定的额外背景知识。
文本类型分类
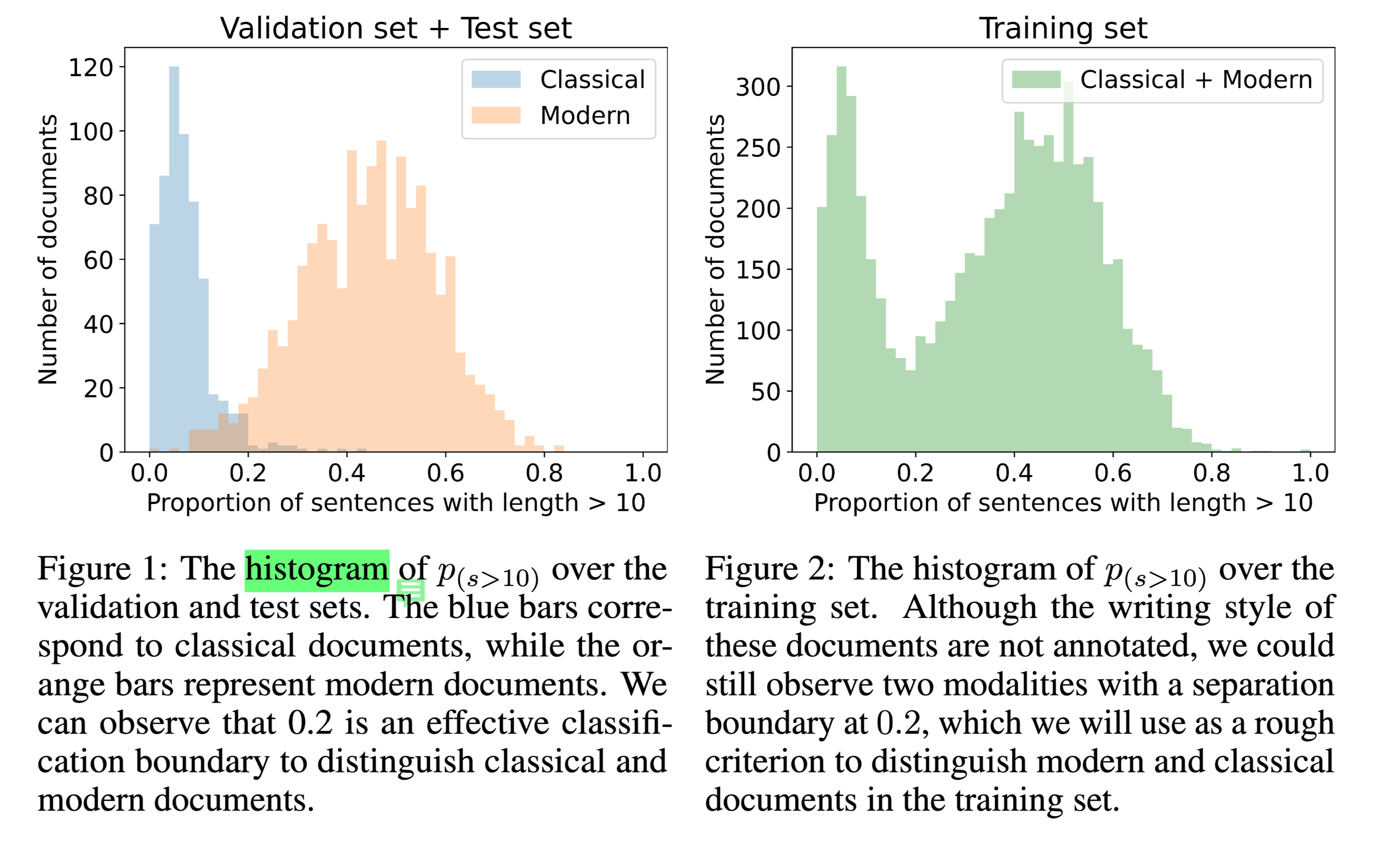
文言文和现代文在长度上的分界线
以长度为10计算。
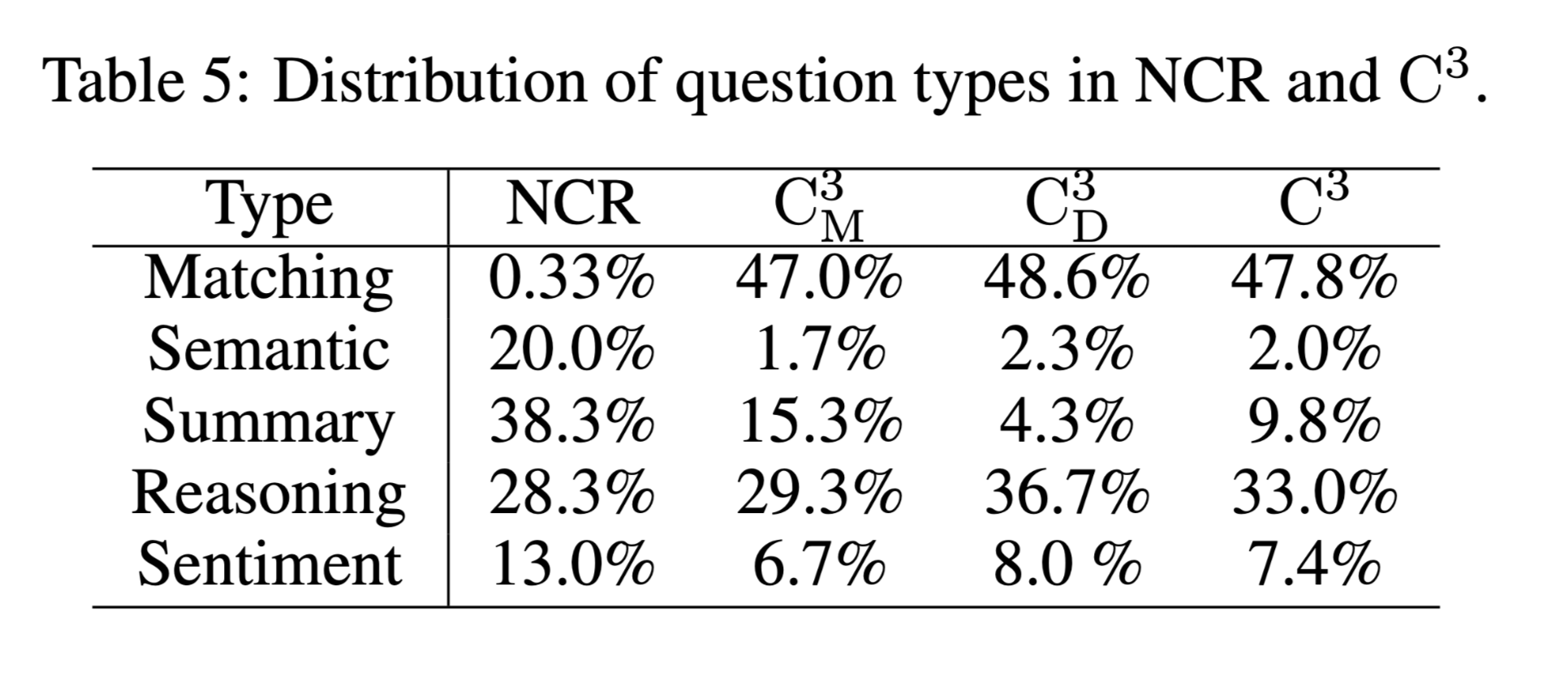
问题分类
分为5类
- 匹配问题:查询文档中明确描述的事实。正确答案可以直接从文件中的一小段或一句话中获得。请注意,不同的选项可以引用不同的跨度。
- 语义问题:询问句子中单词或字符的语义,包括反义词、同义词、修辞和分词。
- 摘要问题:要求读者理解整个文件中陈述的所有事实,以便选择所需的选项,该选项提供正确或错误的事实摘要。
- 推理问题:要求读者进行非琐碎(non-trivial)的推理,以推断文件中未明确说明的结论。NCR中的推理问题通常要求读者具备丰富的背景知识和常识。
- 情绪问题:询问作者在文件中表达的隐含情绪。NCR中的情感问题通常需要了解意象、象征意义,甚至作者的社会政治观点。
问题类型分布:
性能水平
本文把随机猜测和确定性选择作为基线。
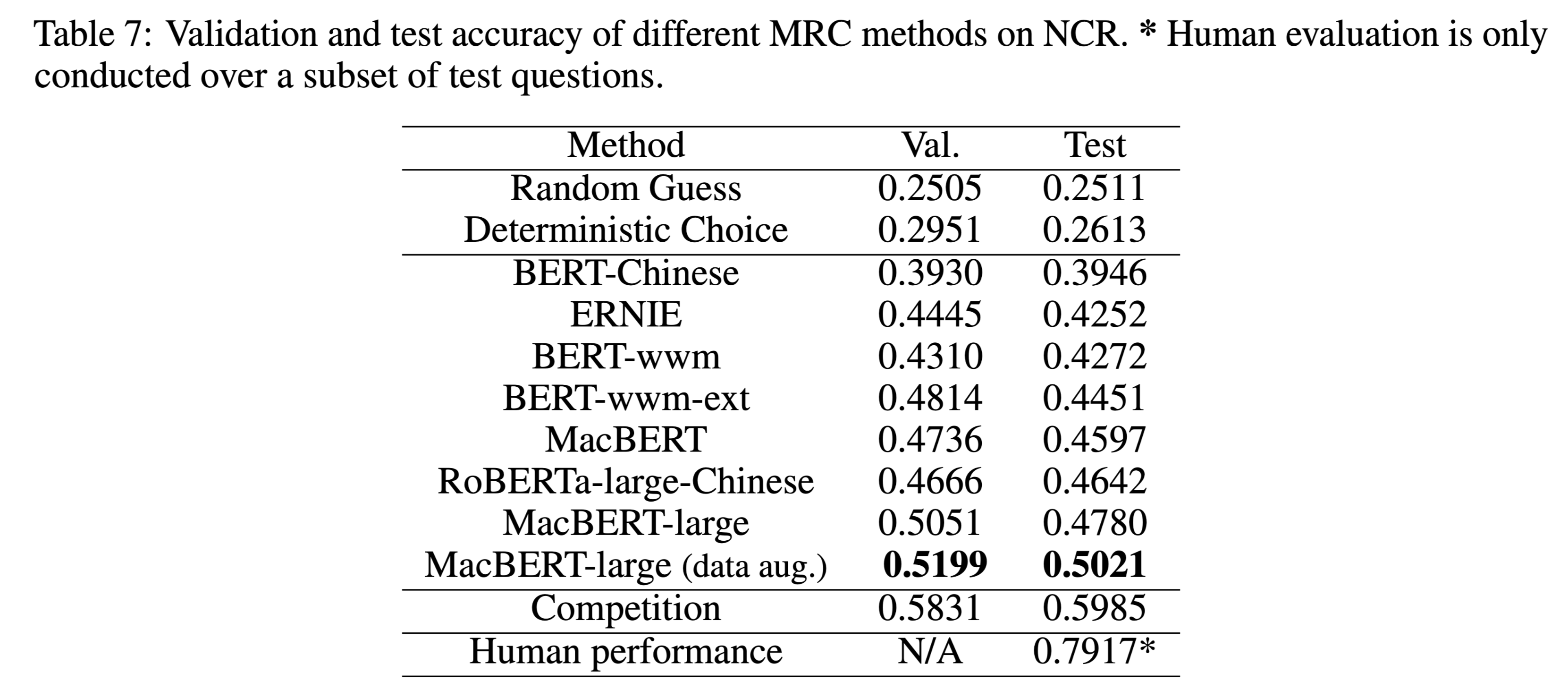
Competition 是比赛的最优结果。
不同写作风格下的性能:

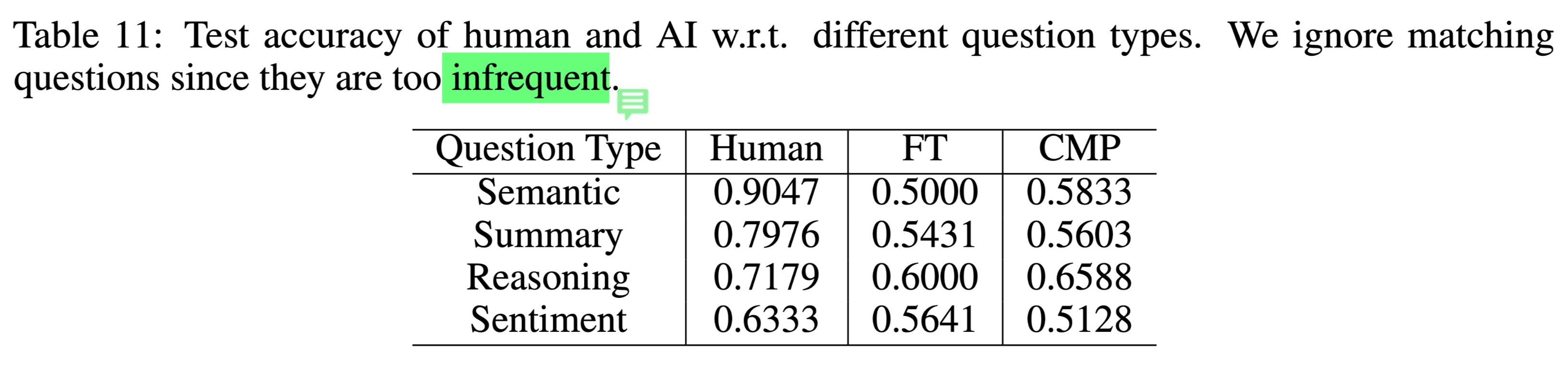
不同类型问题下,人与机器的性能对比:
结论
作者团队使用流行的中文预训练模型实现了多个基线模型,并使用NCR数据集启动了一个在线竞赛,以检查当前方法的局限性。最佳模型的测试准确率为59%,而人工评估的平均准确率为79%,这表明当前的MRC模型与母语为汉语的人之间存在显著的性能差距,这为未来的研究提供了巨大的机会,并有望推动中国自然语言理解的前沿。