Extract Integrate Compete Towards Verification Style Reading Comprehension
Extract, Integrate, Compete:Towards Verification Style Reading Comprehension
论文:https://arxiv.org/abs/2109.05149
代码:https://github.com/luciusssss/VGaokao
会议:EMNLP 2021
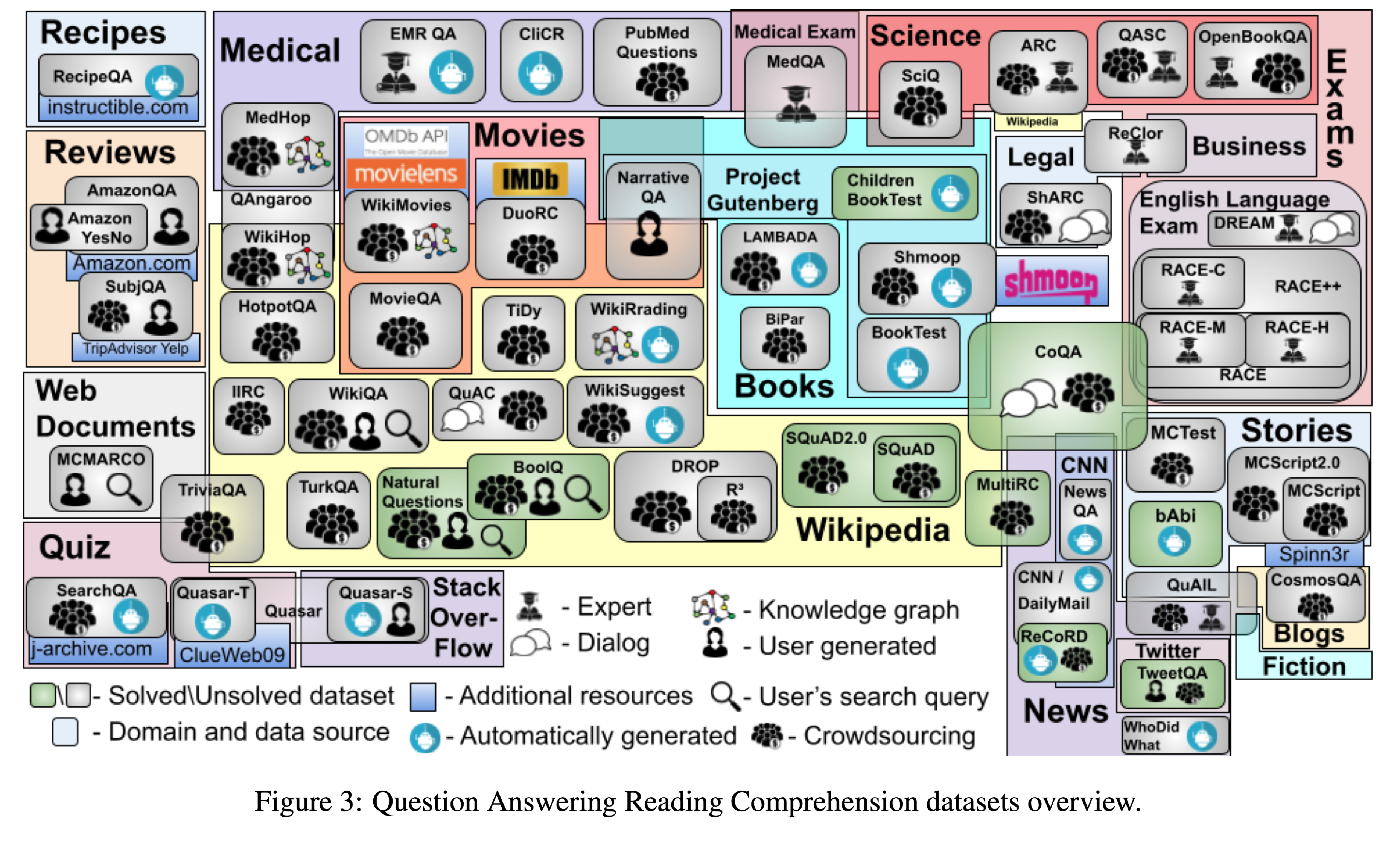
任务
本文提出了一个新的验证式阅读理解数据集,名为VGaokao。与现有的研究不同,新的数据集最初是为母语人士的评估而设计的,因此需要更高级的语言理解技能。为了应对高考中的挑战,我们提出了一种新的Extract-Integrate-Compete方法,该方法通过一种新的查询更新机制迭代选择补充证据,并自适应地提取支持证据,然后通过两两竞争来推动模型学习相似文本片段之间的细微差异。
高考涉及更多的词汇和更复杂的句子结构。此外,高考中近一半的陈述需要多重证据来证实。但是高考中的大多数陈述既不是绝对正确的,也不是绝对错误的,这需要模型仔细比较一种陈述与另一种陈述,根据给定的段落选择最合适的答案。
根本目的:
- 从文章中提取证据,并根据检索到的证据和其他选项验证陈述。
数据集中样例的推理过程:
方法(模型)
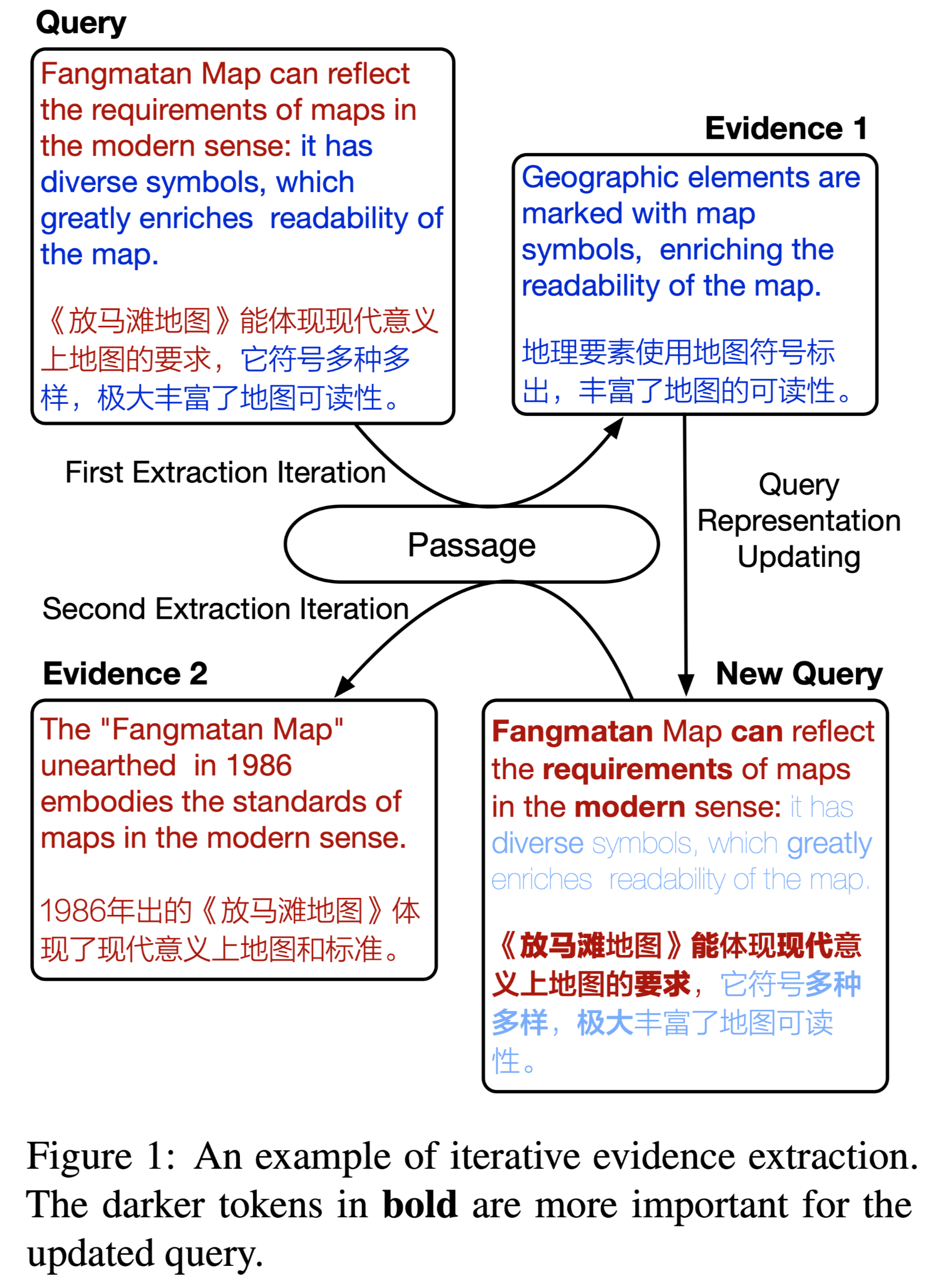
图1展示了一个使用 soft masking 来突出显示在当前迭代之前尚未找到相应证据的tokens的示例。在证据提取之后,模型自适应地过滤无关的证据句子,并动态地确定要整合的证据片段的数量。然后根据检索到的证据对每个问题中的选项进行验证,并以成对方式进行比较,以选择最合理的答案。
Extract-Integrate-Compete Approach
模型分为三个阶段:
- iterative evidence extraction(证据迭代提取)
- adaptive evidence integration(自适应证据整合)
- pairwise option competition
模型结构:
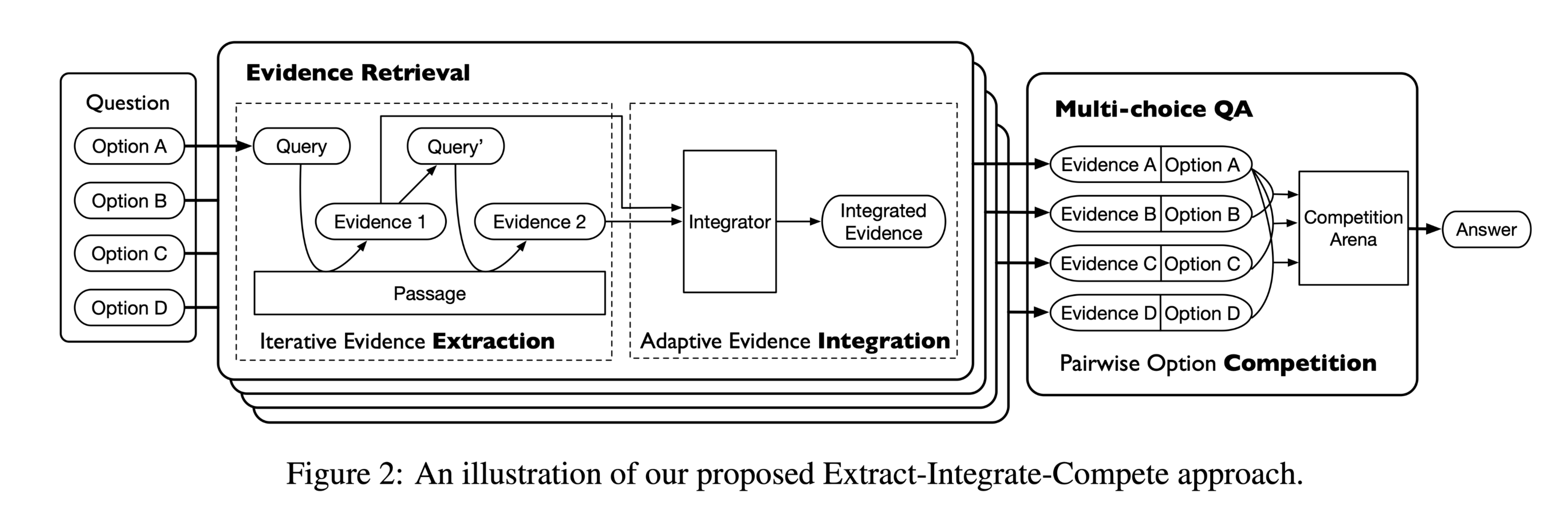
iterative evidence extraction
任务定义:
evidence sentences :${s_1, s_2, · · · , s_n}$
query:$q$
evidence candidate:$s_i$
查询和候选证据的相关得分:
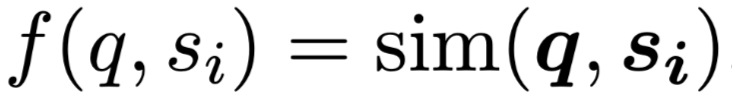
该方法独立处理每个候选证据,并生成排名列表。然而,当一个查询需要多个证据句时,独立选择排名前$k$的句子可能会忽略证据句之间的互补关系,从而产生较差的结果。
本文采取迭代的方法,当检索到新的证据时,query representation会被更新。
为了强调证据句之间的互补关系,同时避免过多的重叠,我们建议使用掩蔽策略来降低查询与其检索到的证据片段之间的相关性。
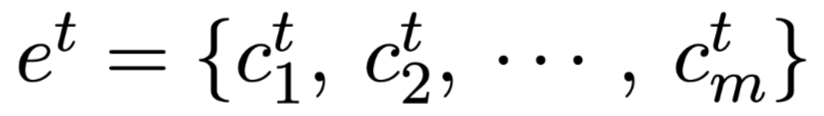
$e^t$:在t时间步,检索出来的证据。
$c_i^t$:证据中的第$i$个$tokens$。
为了寻找补充证据片段,本文建议减少$q$中已被检索到的证据语句等覆盖部分的影响,以便下一步的查询表示$q_{t+1}$将更多地关注尚未找到相应证据的部分。具体的做法就是使用掩码策略。
两种掩码策略:
- Hard Masking
- Soft Masking
Hard Masking
在第$t$时间步迭代之后,只丢弃出现查询$q$中的出现在时间步$t$ evidence的tokens。
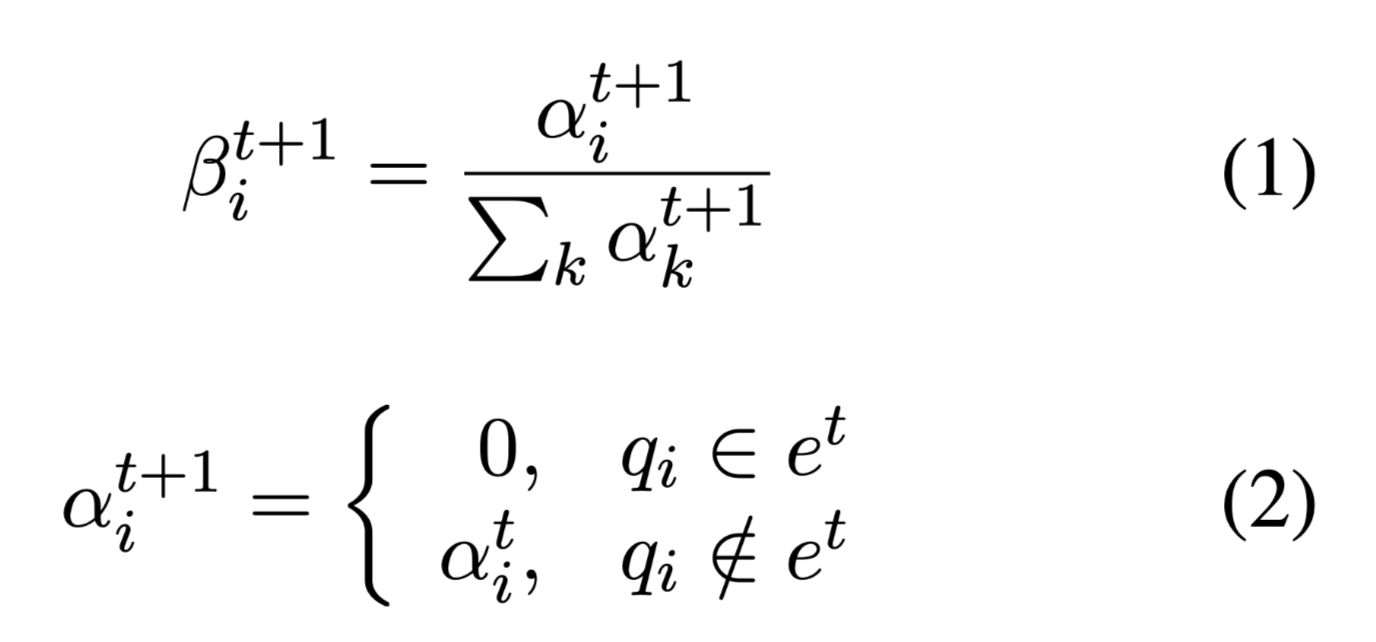
$\beta ^{i+1}_t$:表示第t次迭代,查询q中第i个tokens的权重。
如果q中的i-th tokens在证据$e^t$中,权重被置为0,意味着该tokens的向量表示置为0,即被查询q丢弃。
根据检索到的证据更新查询q的表示:
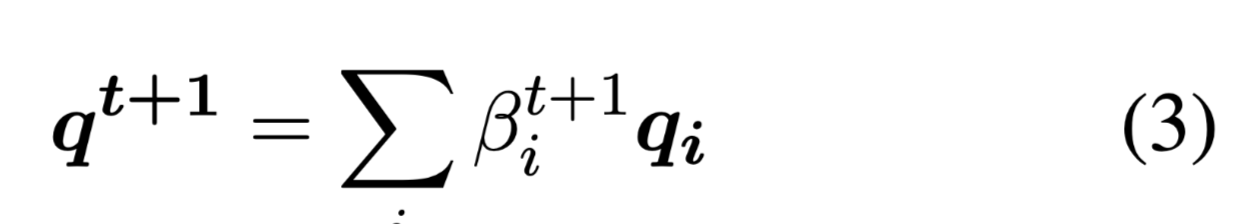
更新每个tokens的表示。
经过Hard Masking 新的查询表示仅限于关注尚未匹配的标记。
Soft Masking
与Hard Masking强硬的将tokens的权重置为0不同,Soft Masking,如其名,字面意义上的Soft,该策略在下一步表示中减少已被检索tokens的权重。
具体来说:查询q的i-th tokens 的权重与其在检索到的证据集中最相似的标记的匹配分数成反比。相似度使用简单的点积相似度,“反比”如何数学化的表示呢,很简单,将最高相似度变为相反数,再过一遍softmax,负数占的权重自然而然的变小了。
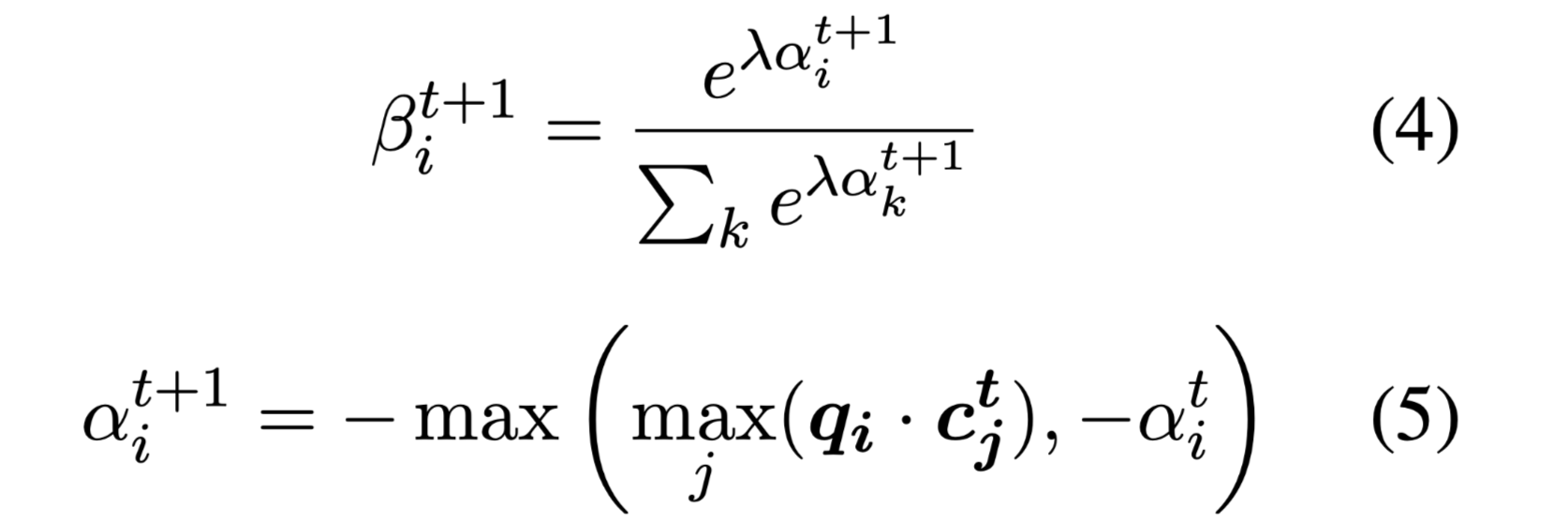
这里有一个猜想,用指数做底,可能是由于权重会出现负数。
否定上一条猜想,公式(4)不就是softmax吗?
其中λ用于人为调整想要扩大匹配tokens和未匹配tokens之间的权重差距的程度。
根据检索到的证据更新查询q的表示:
与Soft Masking 一样,都是根据q更新后的rokens权重来得到新的查询表示。
Adaptive Evidence Integration
该证据集成器将候选证据链作为一个整体进行度量,并自适应地过滤在后续迭代中引入的无关证据片段。
use Sentence-BERT to measure the relevance between the query and the evidence chains in the adaptive integrator.
实际上,不同的查询需要不同数量的证据。固定证据句的数量可能会给需要更少或更多证据句的查询带来噪音。为了缓解这个问题,本文引入了一个证据集成模块来自适应地确定每个查询需要多少补充证据。
- 具体来说,经过t步BeamSearch,可以获得由t个不同的证据句子组成的多个证据链。在每条链中,根据证据句在原文中的顺序重新排列和连接证据句,以期维持证据句之间潜在的语义关系。
- 然后,把从不同检索步骤中获得的综合证据链输入到重新排序器(reranker)中,进一步比较它们与查询q的语义相似性。得分最高的证据链将被选为查询的q的最终证据链。
Pairwise Option Competition
use Chinese RoBERTa-wwm-ext-Large with Transformers toolkit.
高考数据集,难度较大,需要仔细区分几个选项,才能得出最终答案。
- 对于一个需要选择与文章最一致的选项的问题
Pairwise Option Competition 的 hinge loss:
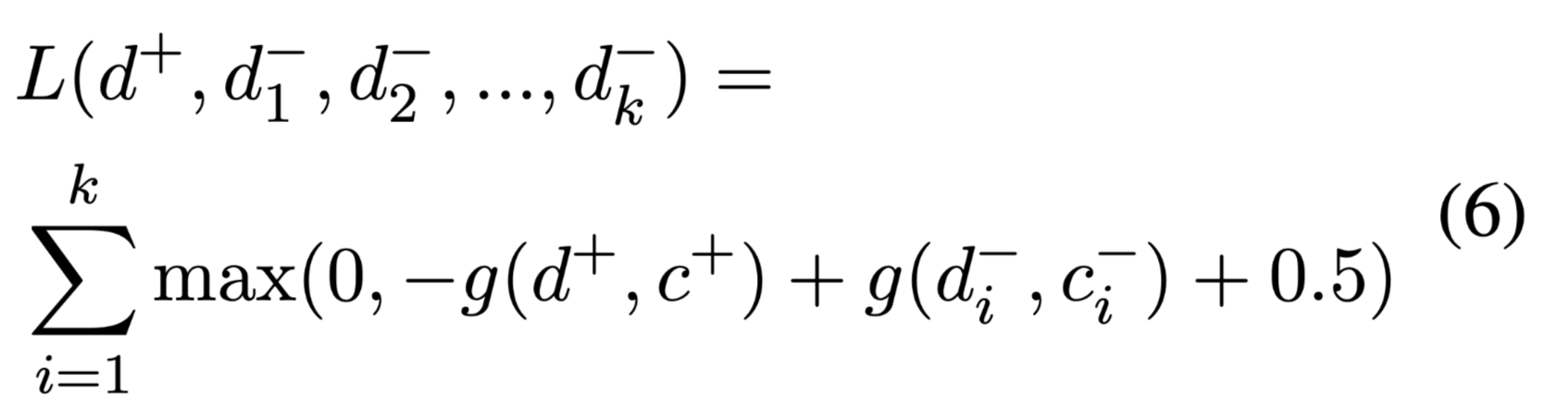
$g(·)$:是预训练模型计算证据集c,对声明d的支持度。
对于一个需要选择与文章最一致的选项的问题,$d^+$表示正确的选项,$d^-_i$表示一些错误选项。这些选项$d$都需要与他们的证据集$c^+, c^−_i$一一配对。
- 对于一个需要选择最矛盾选项的问题
hinge loss :
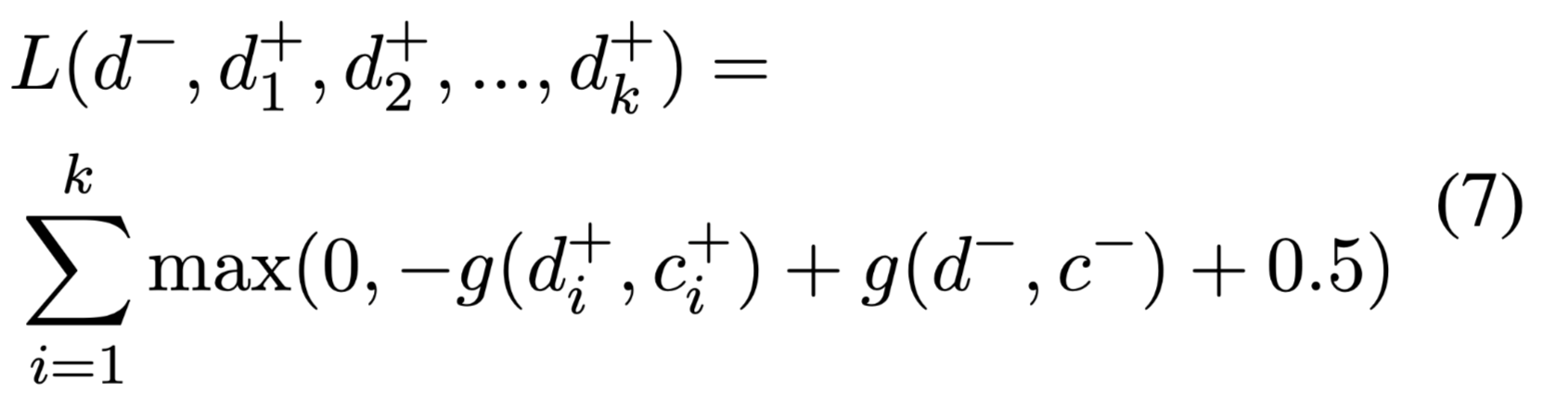
$d^-$表示最矛盾的选项,$d^+_i$表示一些正确选项。这些选项$d$都需要与他们的证据集$c^-, c^+_i$一一配对。
在推理过程中,选择得分最高的选项作为问题的答案。同样地,选择得分最低的选项来回答文章与提问最矛盾的选项。
数据集
VGaokao: verification style reading comprehension dataset.
特点:
- 在高考的汉语测试中,大约一半的阅读理解题要求学生选择与给定文章最一致或最矛盾的陈述(即四个选项中的一个选项)。(为什么用“最”呢,因为答案正确与否并不是绝对的。)
- 评估学生从长文章中提取和整合信息的能力,以及分析某些语言现象或几个相似句子之间的语义关系的能力。
根据上述对高考数据集问题的描述,称该问题为 verification style questions。
数据集大小:
- 2,786 passages
- 3,512 questions
- 1.6 evidence sentences for each option
数据集分析:
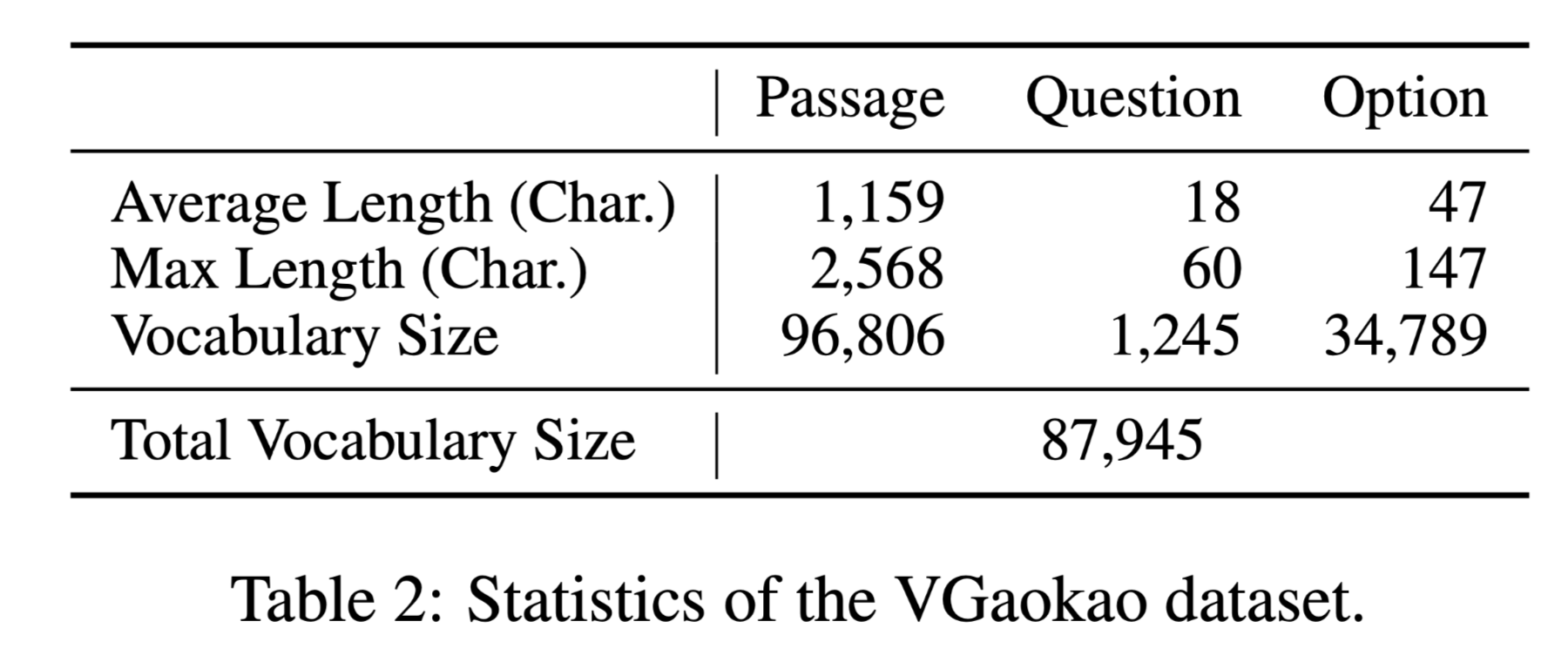
性能水平
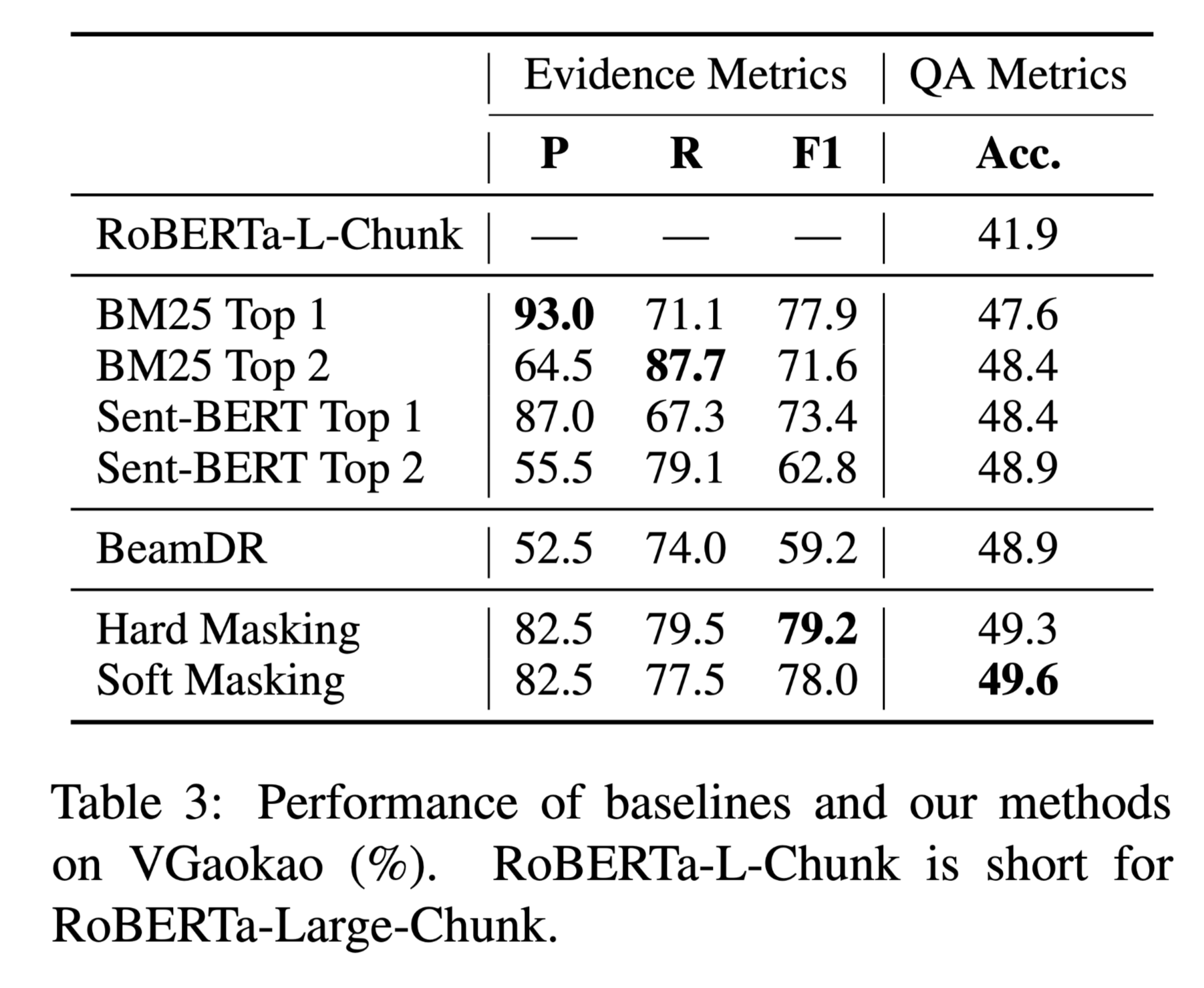
RoBERTa-Large-Chunk simply chunks passages into pieces.
- 使用三个指标来评估带有golden evdience 语句的子集上的证据质量:精确度(P)、召回率(R)和F1(F1)。
- 预测答案的准确性(Acc)用于评估问题层面的性能。
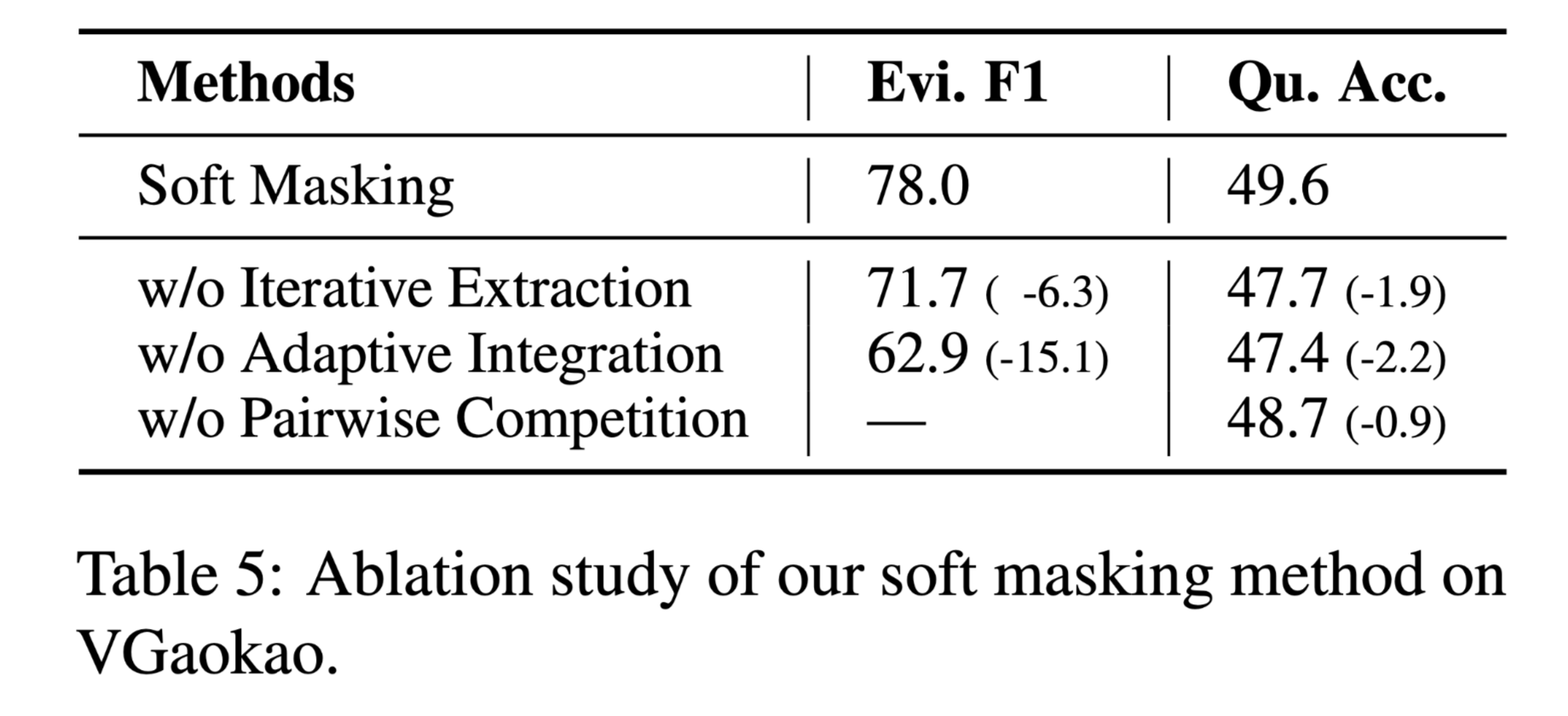
针对Soft Masking 的消融实验:
结论
case study:

实验表明,本文的方法在检索到补充证据的情况下,优于高考上的各种基线,同时具有效率和可解释性的优点。
主要贡献:
- 提出了一个新的验证式阅读理解数据集VGaokao,它嵌入了更高级的语言理解技能。
- 提出了一种新的抽取-集成-竞争(Extract-Integrate-Compete)方法,通过一种新的查询更新机制从长文章中迭代选择补充证据。基于hinge loss 的competition组件可以推动模型捕捉不同选择之间的细粒度差异。
- 实验表明,本文的方法在VGaokao上的证据检索F1和QA准确率都优于各种基线模型,同时显示了效率和可解释性的优点。