Automatically Learning Data Augmentation Policies for Dialogue Tasks
Automatically Learning Data Augmentation Policies for Dialogue Tasks
论文:Automatically Learning Data Augmentation Policies for Dialogue Tasks
任务
AutoAugment算法主要应用在CV领域,本文调整AutoAugment算法应用在对话任务上。
自动数据增强(AutoAugment)通过使用目标任务上的采样策略的性能奖励训练的控制器搜索最佳扰动策略,从而减少data-level模型的偏差。
本文调整了AutoAugment,以自动发现自然语言处理(NLP)任务的effective perturbation policies(有效扰动策略),如对话生成。
还探索了以目标任务的源输入为条件的控制器,因为某些策略可能不适用于不包含该策略所需语言特征的输入。
方法(模型)
从一个原子操作池开始,对对话任务的源输入进行微妙的语义保护性扰动(例如,不同的POS-标签类型的停顿词、语法错误和意译)。
接下来,允许控制器通过搜索这些原子操作的各种组合的空间来学习更复杂的增强策略。
数据增强策略:
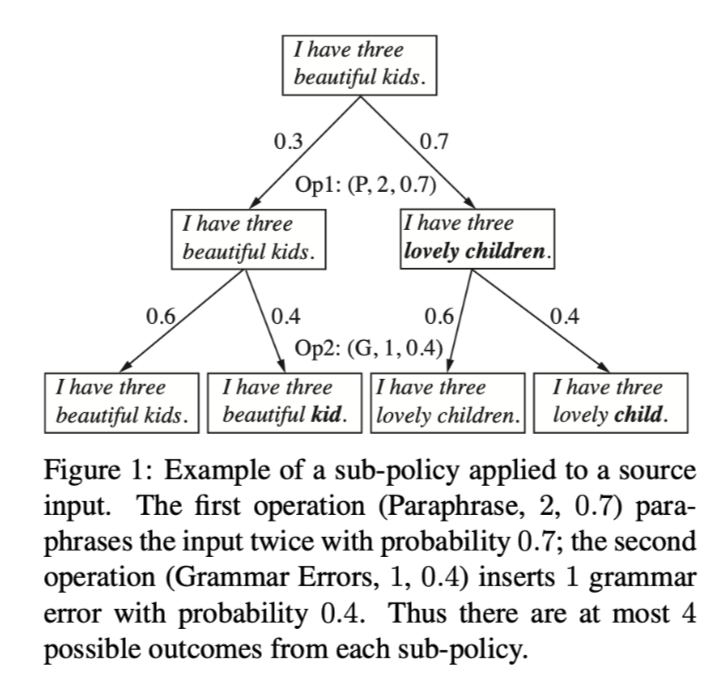
下图中,第一个操作(Paraphrase, 2, 0.7)以0.7的概率对输入进行两次转述;第二个操作(Grammar Errors, 1, 0.4)以0.4的概率插入一个语法错误。因此,每个子策略最多可能有4个结果。这种修改为模型提供了一个更大的操作组合空间,使其有可能学习到更复杂和细微的增强策略。
模型结构
模型包含controller和target model
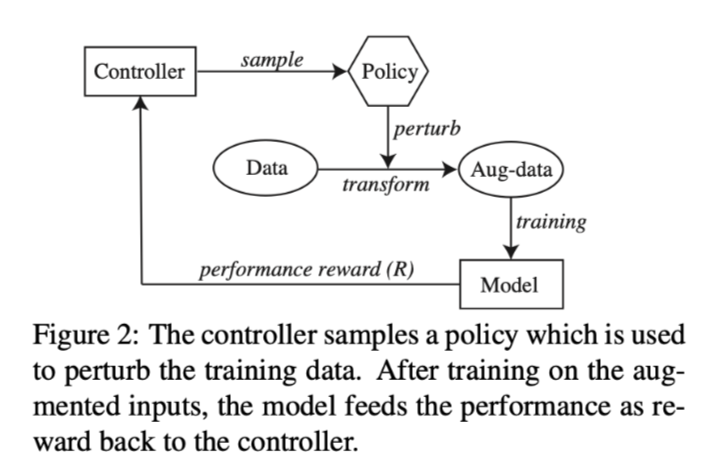
controller首先对一个策略进行采样,将原始数据转化为增强数据,目标模型在此基础上进行训练。训练结束后,对目标模型进行评估,以获得验证集上的性能。然后,这个性能被反馈给controller作为reward signal。
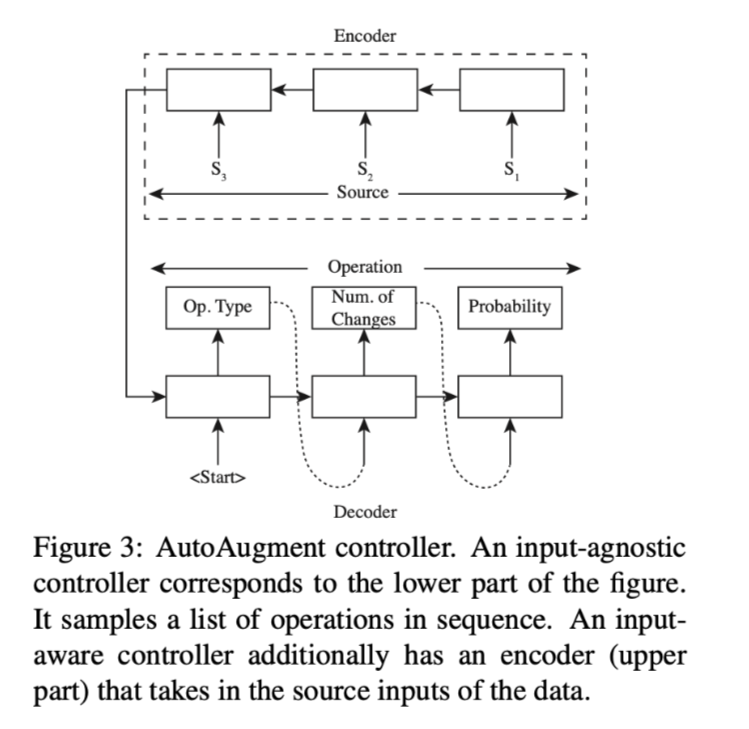
input-agnostic:由一个单一的解码器组成,依次对每个操作进行采样。
一个操作由3个参数定义。操作类型、允许执行操作的最大次数、应用该操作的概率。
input-aware:加入一个编码器,将训练数据作为输入,使其成为一个seq2seq模型。由于对于每个输入源,可能有一组不同的扰动最适合它,模型的输入感知控制器旨在为每个训练实例提供定制操作。
搜索算法:REINFORCE
对多个子策略进行抽样以形成一个策略,提供了对控制器性能不太偏颇的估计。
数据集
Variational Hierarchical Encoder-Decoder (VHRED)
性能水平
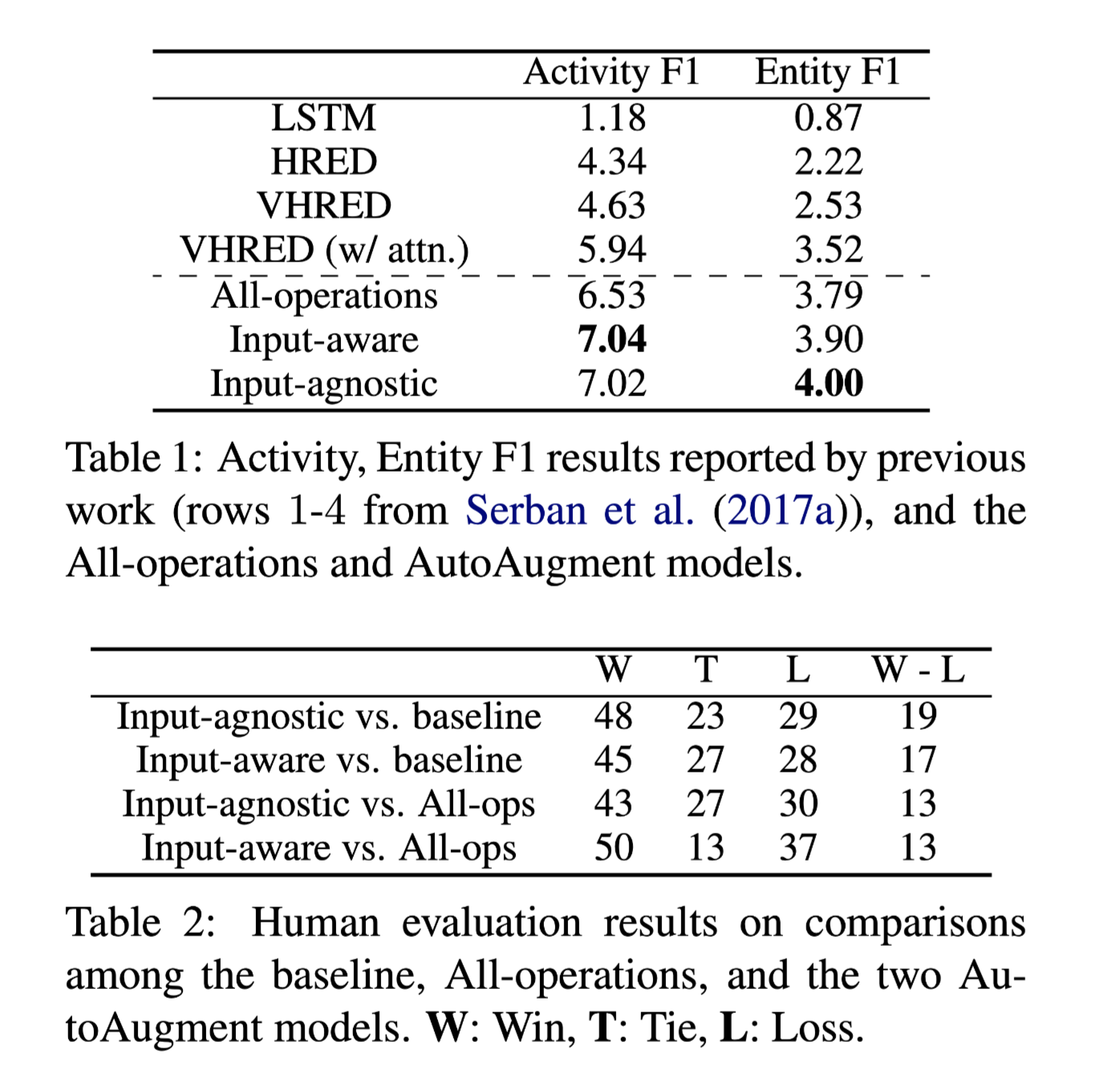
表1说明所有的数据增强方法(最后3行)都比最强的基线VHRED(w/attention)有明显的改善。
结论
本文使AutoAugment适用于对话,并将其控制器扩展到一个有条件的模型。通过自动和人工评估表明,AutoAugment模型学会了有用的数据增强策略。