
Improving Low-resource Reading Comprehension via Cross-lingual Transposition Rethinking
Improving Low-resource Reading Comprehension via Cross-lingual Transposition Rethinking
任务
解决抽取式阅读理解中低资源语言训练数据不足的问题。 通过在多语言环境中对现有的高质量提取式阅读理解数据集进行建模,提出了一个跨语言转置再思考(XLTT)模型(Cross-Lingual Transposition ReThinking)。
方法(模型)
提出了多语言适应性注意(multilingual adaptive attention MAA),将intra-attention,inter-attention结合起来,从每一对语言家族中学习更普遍的可归纳的语义和词法知识。为了充分利用现有的数据集,本文采用了一个新的训练框架,通过计算每个现有数据集和目标数据集之间的任务级相似度来训练模型。
模型结构
- 首先,对于现有的抽取式阅读理解数据集,首先利用GNMT构建了多个语系的多语言平行语料,如(英语、日语、韩语……)。
- 其次,利用多语言自适应注意力,在多语言环境中学习语言学相关的语义和词汇知识,以普及到低资源语言。
- 然后,计算每个训练数据集和目标数据集之间的任务级余弦相似度(使用TF-IDF计算),以使用多个训练数据集。
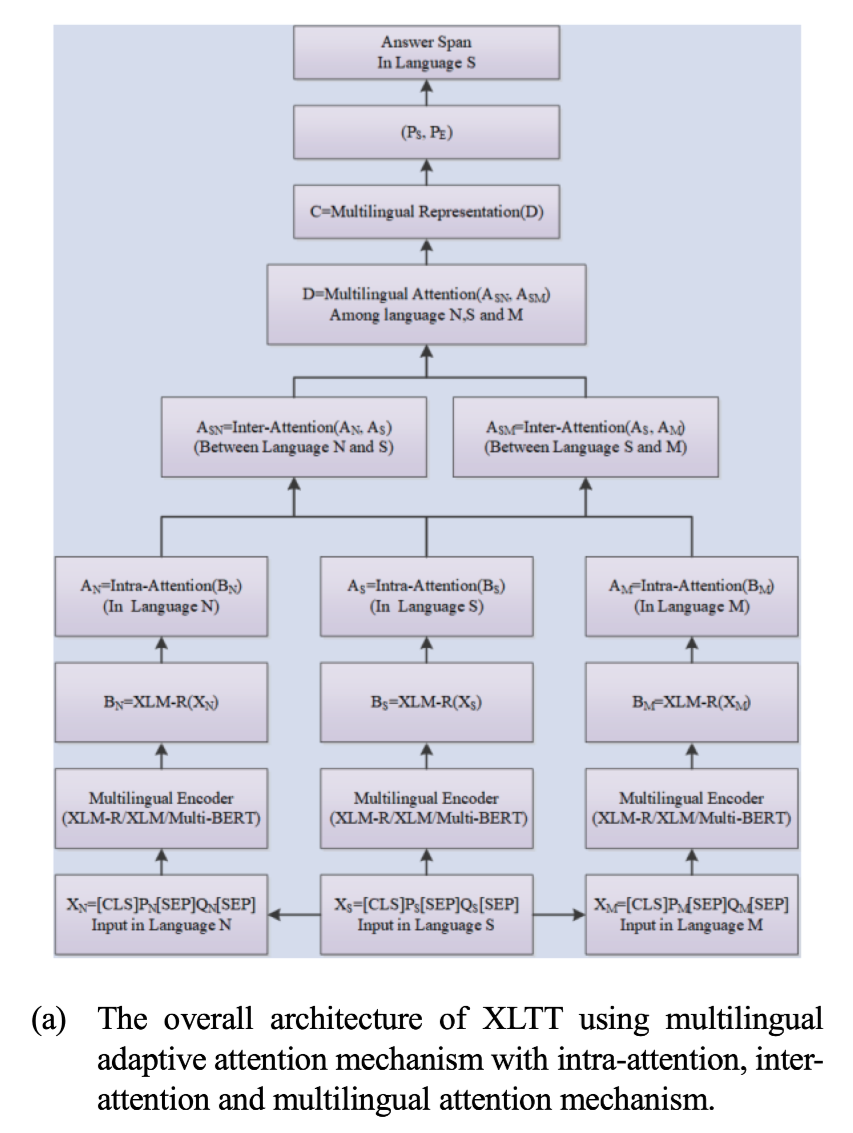
使用共享的多语言编码器,如Multi-BERT和XLM-R,对构建的多语言平行语料库进行编码,以获得上下文的向量表示。
主要贡献:
- 提出了一种跨语言转置再思考(XLTT)的方法,在多语言背景下利用现有的大规模高质量ERC(抽取式机器阅读理解)数据集来解决低资源ERC的问题。
- 提出了多语言适应性注意力(MAA)机制,通过结合intra-attention和inter-attention的关系,可以使抽取性RC模型从每一对语言家族中捕捉到更普遍的可归纳的语义和词汇信息,有利于推广到低资源语言。本文还提出了一个新的训练框架,通过计算每个现有训练数据集和目标数据集之间的任务级相似度来训练ERC模型。
- 实验结果显示,本文提出的模型在2个多语言提取阅读理解基准上的表现优于6个基准,证明了多语言建模方法的有效性。
数据集
MLQA
七种语言的多向平行抽取式问题回答评估基准
TYDI QA
涵盖11种不同类型语言的QA数据集,有204K个QA对。
XQuAD
通过将实例翻译成十种语言,从240个段落中获得了1190个SQuAD v1.1 QA对的数据集。
XTREME
大规模的多语言多任务基准,用于验证和确认多语言模型的跨语言泛化能力。
性能水平&结论
MLQA数据集测试结果:

XQuAD数据集测试结果:

与之前的最佳模型相比,XLTT模型在MLQA测试集上取得了平均5.1的F1成绩和4.5的EM成绩,在XQuAD测试集上获得了平均2.7的F1成绩和3.6的EM成绩。两种多语言ERC的实验结果证明了本文提出的多语言ERC方法对对低资源语言的有效性。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 没有胡子的猫Asimok!
相关推荐




评论

