Multi-paragraph Reading Comprehension with Token-level Dynamic Reader and Hybrid Verifier
Multi-paragraph Reading Comprehension with Token-level Dynamic Reader and Hybrid Verifier
论文:http://vigir.missouri.edu/~gdesouza/Research/Conference_CDs/IEEE_WCCI_2020/IJCNN/Papers/N-20242.pdf
任务
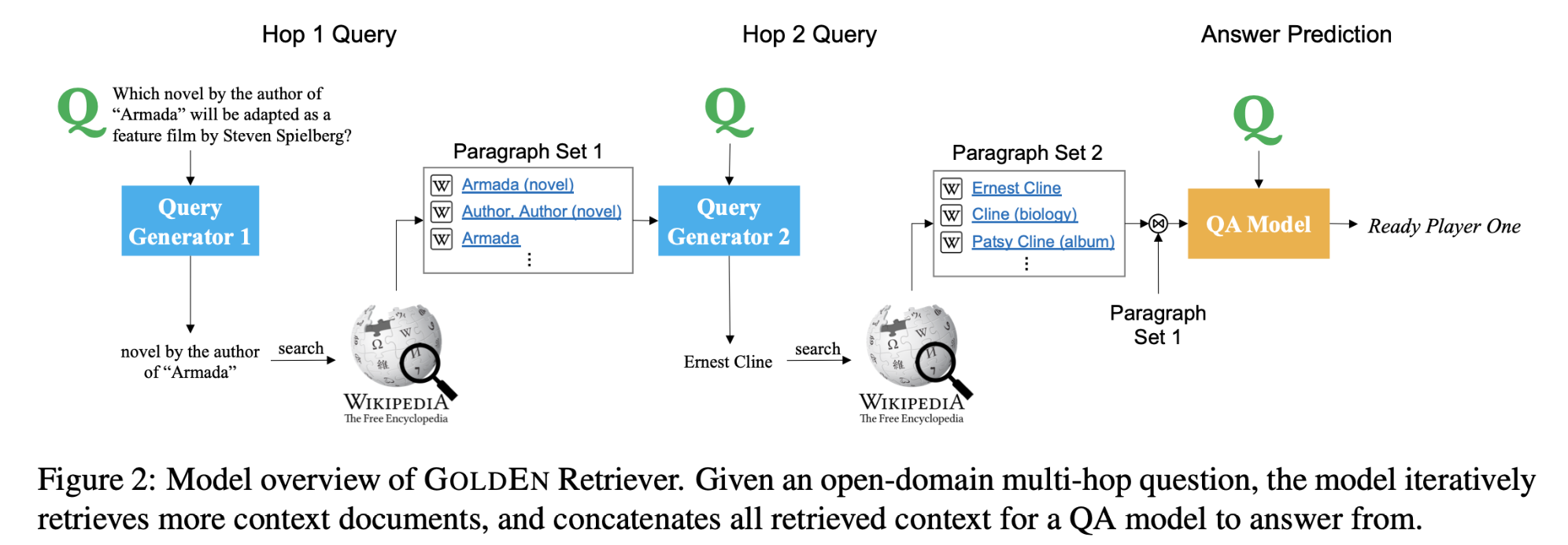
多段式阅读理解要求模型通过推理跨段落信息来推断任意用户生成的问题的答案。以前的工作通常通过直接采用指针网络预测答案的开始和结束位置来生成答案。然而,对于跨度级别的阅读理解是不够的,因为中间的词可能更重要。本文提出了一个统一的网络,包括一个选择器,一个token级动态阅读器,和一个混合验证器(TH-Net)。本文侧重于解决文档级数据而不是单段数据的挑战。
方法(模型)
提出了token级动态阅读器和混合验证器,以避免边界和内容的相似性。
模型结构:
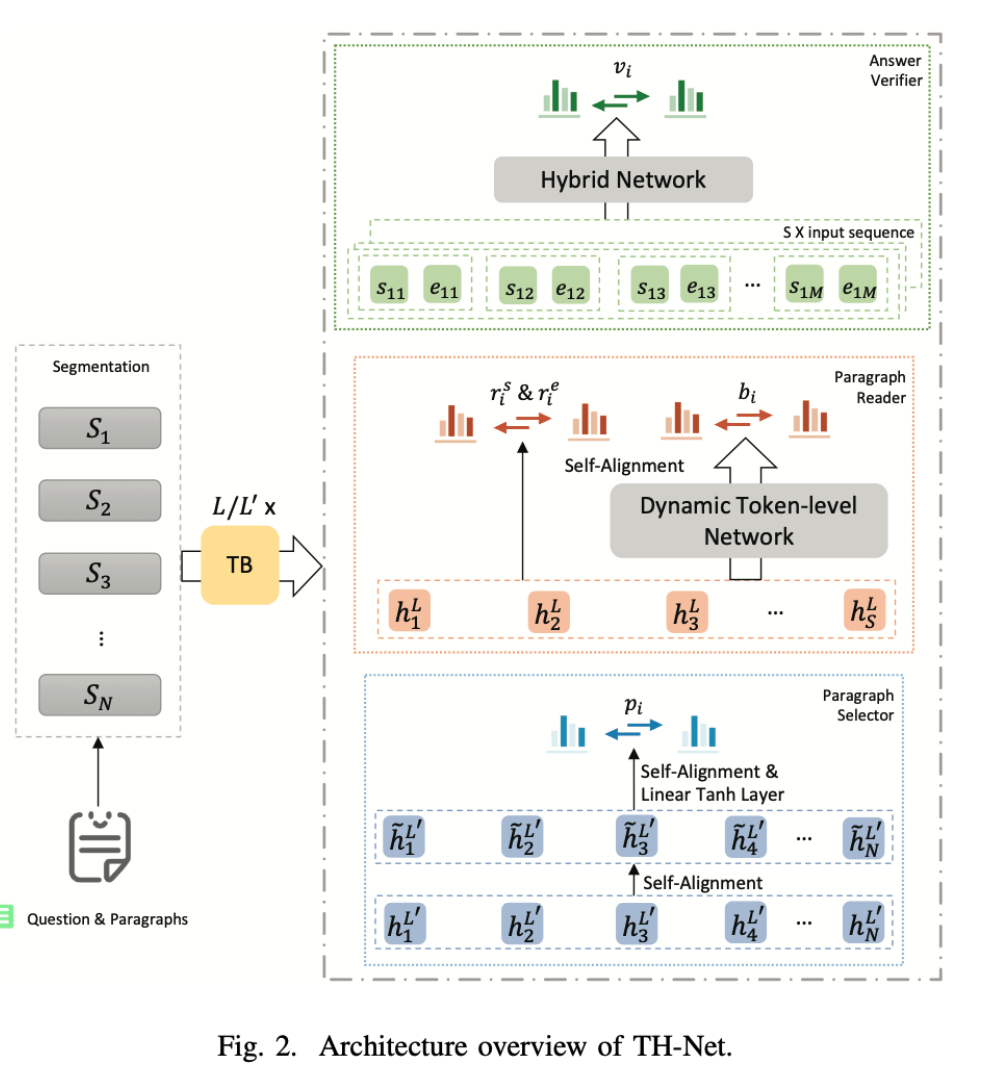
- 采用统一的方法(Unified approach),通过共享相同的上下文嵌入来提高三个组件的整体性能。这三个部分由预训练的LM初始化,并在训练过程中同时进行优化。
- 引入了token级动态阅读器,通过边界和中间标记来决定候选答案的分数。这种策略在段落阅读中被证明是非常有效的,因为它可以更好地解决跨度级阅读器选择的答案代表性不足的问题。
- 在答案验证中,采用了一个混合网络,将候选答案之间的相关语义关系与问题和答案之间的必然关系结合起来。这种机制也提高了验证器的性能。
Segmentation and Encoding
将所有作为输入的段落串联后使用滑窗分段,再进行编码。
输入序列表示:
- < SEP >标记用来分隔问题和段落。
序列$S_i$中第$j^th$个token表示为:
- 分别表示token, position,和segment的embeddings。
- position相同的token可以共享相同的position embedding。
- 同一问题或段落的token可以共享相同的segment embedding。
Paragraph Selector
由于读取并为每个段落生成几个候选答案可能导致OOM问题,因此将第一个$L^{‘}$transformer blocks作为Paragraph Selector的输入。
Token-level Dynamic Paragraph Reader
这一层旨在理解选择器中的S个段落,并为每个段落返回M个候选答案,分数按token级别而不是span级别计算。
token-level dynamic network 结构:

token-level dynamic network得到答案之间的分数,表明每个词是答案内容的概率。
动态是因为它可以根据边界token自动选择重要的token。
门控机制用于选择最重要的K个单词 。
Hybrid Answer Verifier
该模块通过构建两个模型的混合网络,可以有效地在候选答案中修剪噪音答案。
网络结构:

- 模型I旨在捕捉候选答案之间的语义关系。
- 模型II则寻找候选答案与输入序列之间的包含关系。
Joint Training and Prediction
joint objective function:
在预测最终答案时,首先计算每个输入序列的selector得分,并选择前S段。然后,对于每个段落,生成M个具有边界分数和内容分数的候选答案。内容得分是通过使用动态门机制来计算的,该机制特别考虑了答案跨度中的重要词汇。还通过一个混合验证器对有噪声的候选答案进行修剪。
数据集
- SQuAD-document
- SQuAD-open
- Trivia-wiki
性能水平

提出的TH-Net模型在SQuAD-document 和 SQuADopen上表现出了最佳的性能。
REQA采用了与本文类似的统一架构,但性能略低,证明token-level dynamic reader和hybrid verifier对性能提升有影响。

在Trivia-wiki上模型依然取得了最佳的性能。
结论
本文提出的TH-Net旨在解决多段MRC任务。所提出的方法的优点是可以有效地理解token级的段落,并将答案之间的语义信息与答案和输入序列之间的关系信息结合起来。在三个具有挑战性的数据集上都表现出优秀的性能。