Asking Complex Questions with Multi-hop Answer-focused Reasoning
Asking Complex Questions with Multi-hop Answer-focused Reasoning
论文:Asking Complex Questions with Multi-hop Answer-focused Reasoning
任务
multihop question generation
大多数先进的方法都集中在涉及单跳关系的简单问题的提问上,本文提出了一种名为多跳问题生成的新任务,通过额外发现和建模给定文档集合和相应答案的多个实体及其语义关系来提出复杂的和语义相关的问题。
示例:

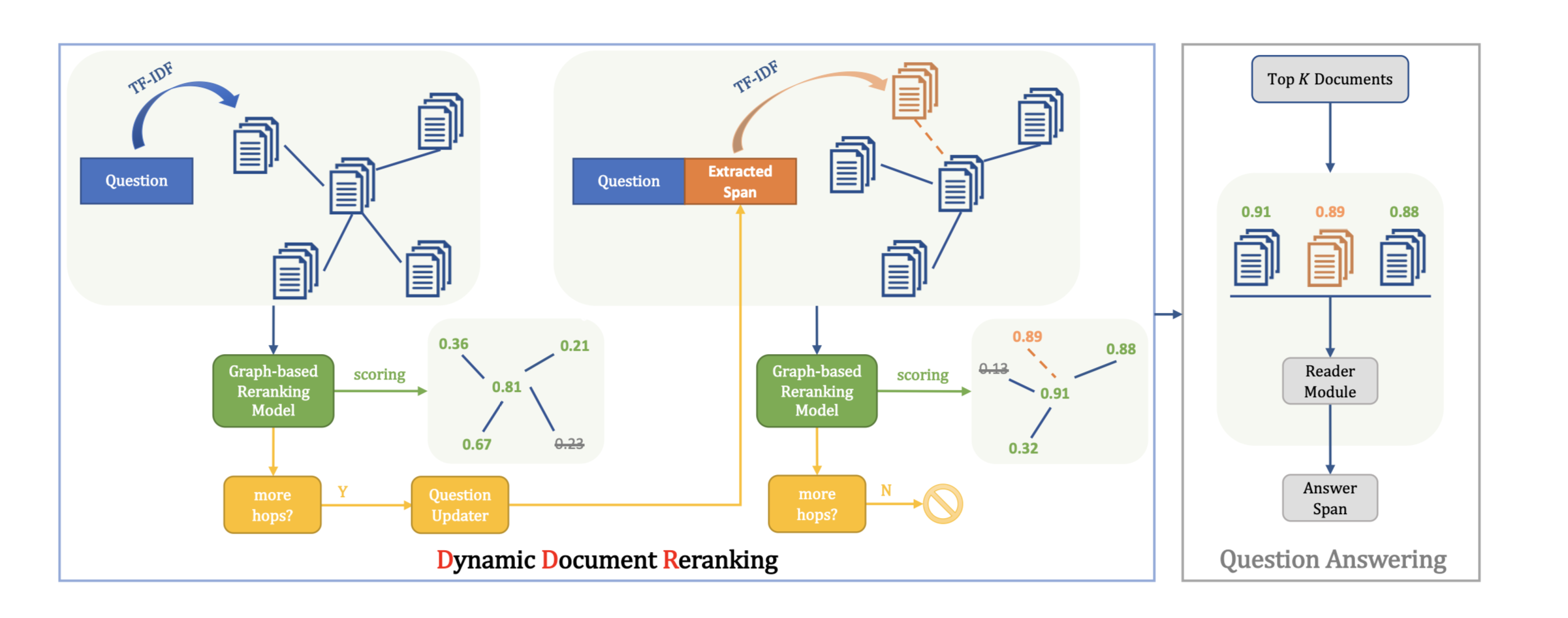
方法(模型)
multi-hop answer-focused reasoning model
本文提出了在以答案为中心的实体图上进行以答案为中心的多跳推理,以包括不同粒度级别的语义信息,包括实体的词级和文档级语义及其语义关系。
通过提取文档中各个实体之间不同类型的语义关系来构建以答案为中心(answer-centric entity graph)的实体图,从而实现多跳推理。
Methods
(i) answer-focused document encoding.
(ii) multi-hop answer-centric reasoning.
(iii) aggregation layer, finally providing an answer-focused and enriched contextual representation.
模型结构:

Answer-focused Document Encoding
以答案为中心的文档编码
Document Encoding
级联文本和标题
one-layer bi-directional LSTM作为encoder获得文档表示。
Gated Self-attention Layer
文档表示对上下文表示有局限,利用gated selfattention layer和Bi-GRU学习上下文表示$h_i$。
$v_i$是通过上下文获得的向量:
$W_d, W_v,W^{‘}_v$是可训练的权重。
Answer Gating Mechanism
授权模型学习以答案为中心的文档表示形式。
将上层gate的计算结果通过sigmoid函数过滤,仅将文档的与答案相关的语义信息转发给下游多跳推理 。
$a$:第一个答案词的隐藏状态。
$W_a$:是可训练权重。
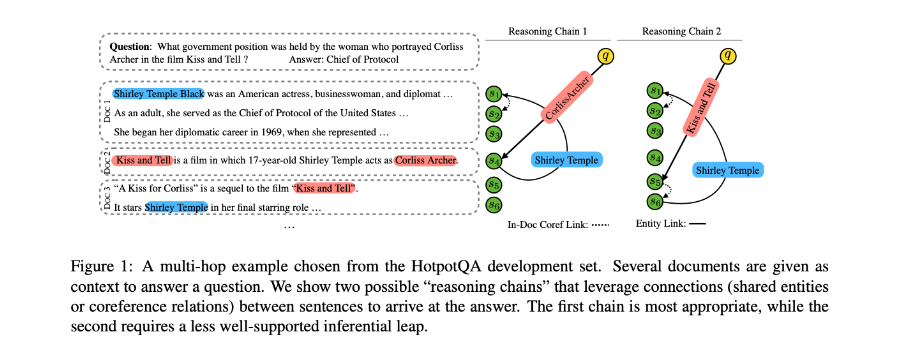
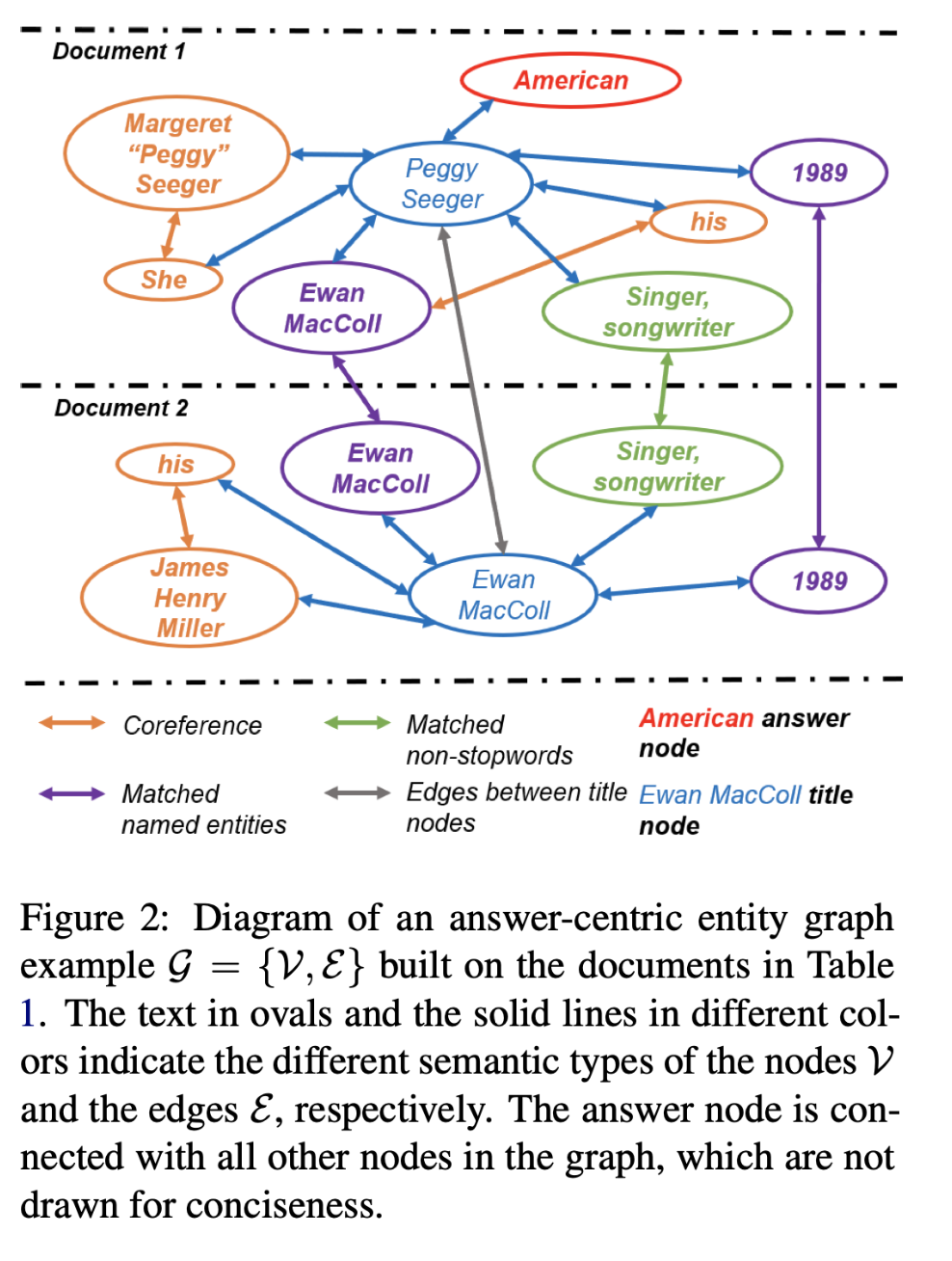
Multi-hop Answer-focused Reasoning Answer-centric Entity Graph Grounding
以答案为中心的实体图表示为:$G = {V, E}$
$V$:表示不同级别的实体节点。
E:表示带有不同语义关系的节点之间的边。
将完全匹配的不停词,命名实体,答案和标题视为节点。
上下文表示的不同粒度级别:
- 完全匹配的不停词和实体节点对特定文档上下文中的单词级别和本地表示进行编码。
- 标题节点代表文档级语义。
- 答案节点提供图推理的答案感知表示,并跨文档建模全局表示。
节点之间边的定义:
- 将所有完全匹配的命名实体连接在一起,无论它们在同一文档中还是在不同文档中。
- 将所有文档间和文档内完全匹配的不停词(例如“歌手,词曲作者”)连接起来。
- 将所有共指词相互链接。
- 将标题节点与同一文档中的所有实体节点连接起来。
- 在所有标题节点之间添加密集连接。
- 答案节点连接到图中的所有其他节点,从而形成一个以答案为中心的实体图。
示例:

Multi-hop Reasoning with RGCN
使用GNN-based model进行多跳推理。——RGCN
经过L层推理后,最多可以捕获到L跳关系。
Aggregation Layer
通过使用可训练的layer-wise权重选择性地汇总每个RGCN层的输出和答案感知文档表示生成来计算最终的答案感知上下文表示。
每层的答案节点表示形式和LSTM的最后一个隐藏状态堆叠在一起,以产生更准确的文档级和全局表示形式。
Decoder
将隐藏状态初始化为$s_0 = z$时,将单向LSTM用作解码器以生成问题,在给定先前生成的单词和先前隐藏状态的情况下,更新当前隐藏状态。
解决词汇量不足的问题:
在encoder的每个步骤中,计算概率,从而决定基于注意力矩阵从输入文档中复制单词,或通过具有softmax功能的输出层从词汇表生成单词。
数据集
HOTPOTQA
丢弃“comparison”类型的问题,并且仅收集文档集中标有“supporting facts”的文本。 由于缺乏对原始testing dataset的访问权限,将training set和development set结合在一起,并将它们随机分为training set,development set,testing dataset。
性能水平
实验结果:
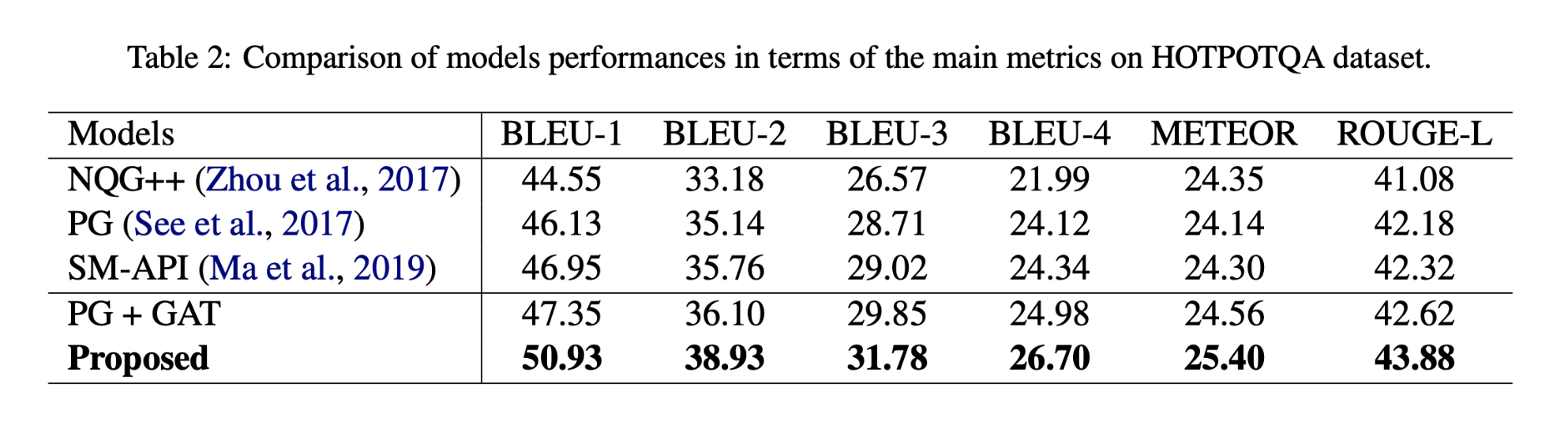
本文提出的以多跳回答为重点的推理模型比基线获得更高的分数,因为它在利用以回答为中心的实体图上的基础上使用不同的回答感知上下文实体表示形式和实体之间的语义关系的粒度级别,从而对解码器产生了精确而丰富的语义。

DecompRC模型使用本文模型生成的问题,取得了除人工提出的问题外最佳效果。
DecompRC在不同生成问题上的性能直观地反映了生成问题的质量和模型的多跳推理能力。
结论
以答案为中心的多跳推理模型的设计是利用它们之间的各种语义关系来发现和捕获与答案有关的实体。
本文通过发现和建模文档中的多个实体及其语义关系,对给定文档集合和相应答案的复杂问题进行询问。 为了解决该问题,本文通过利用以自然语言文本构建的以答案为中心的实体图中的语义信息的不同粒度级别,提出了针对答案的多跳推理。 实验结果证明在机器评估和人工评估方面都取得优秀的结果。