
HOTPOTQA A Dataset for Diverse, Explainable Multi-hop Question Answering
HOTPOTQA A Dataset for Diverse, Explainable Multi-hop Question Answering
论文:https://arxiv.org/pdf/1809.09600.pdf
一个多样的,可解释的多跳问答数据集。
任务
现有的问答数据集不能训练QA系统进行复杂的推理并提供答案的解释。提出hotpot数据集,提供支持事实使模型能够改进性能并做出可解释的预测。
HOTPOTQA介绍
HOTPOTQA是一个新的数据集,拥有113k个基于Wikipedia的问答对,具有以下四个关键特性:
- 这些问题需要在多个支持文档上找到答案并进行推理。
- 问题是多样的,不局限于任何预先存在的知识库或知识模式。
- 提供推理所需的句子级支持事实,允许QA系统在强监督下推理并解释预测。
- 提出了一种新的factoid comparison questions来测试QA系统提取相关事实和进行必要比较的能力。
数据集
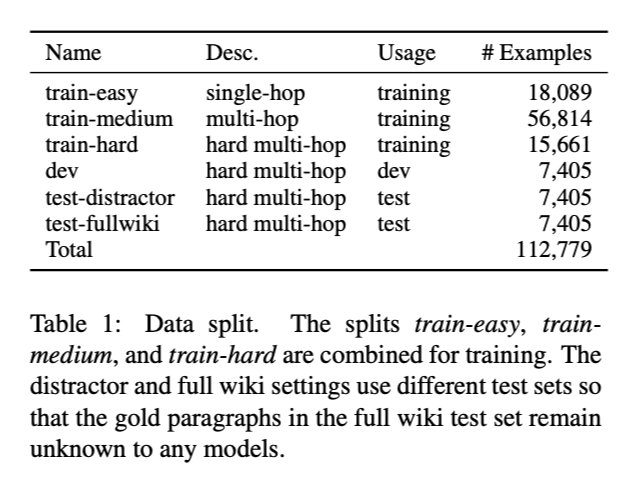
数据集划分
single-hop数据集:The train-easy set contains 18,089 mostly single-hop examples.
将hard examples随机划分为4个子集:
- train-hard, dev, test-distractor, test-fullwiki
two benchmark settings
distractor
8 paragraphs from Wikipedia + 2 gold paragraphs
full wiki
要求模型回答所有Wikipedia文章的第一段给出的问题。
两种设置使用不同数据集的原因:distractor设置中的模型可以使用gold paragraphs,但full wiki设置中不可以使用gold paragraphs。
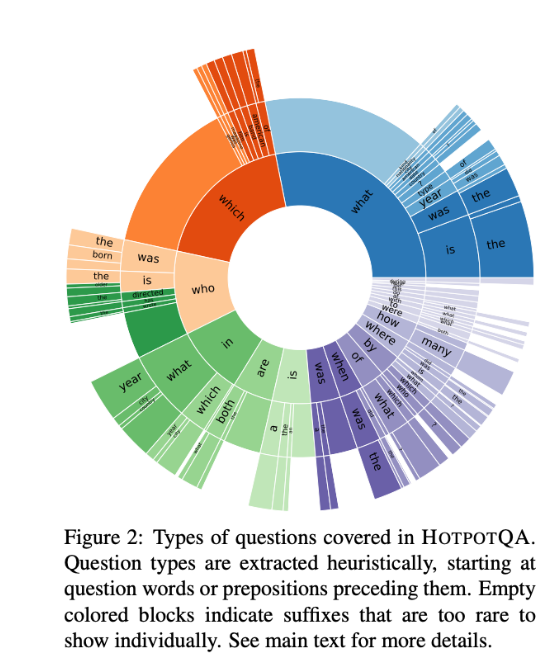
Question Types
Answer Types
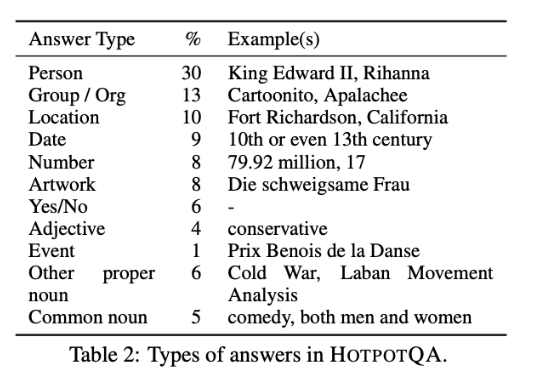
- 68%的回答实体相关。
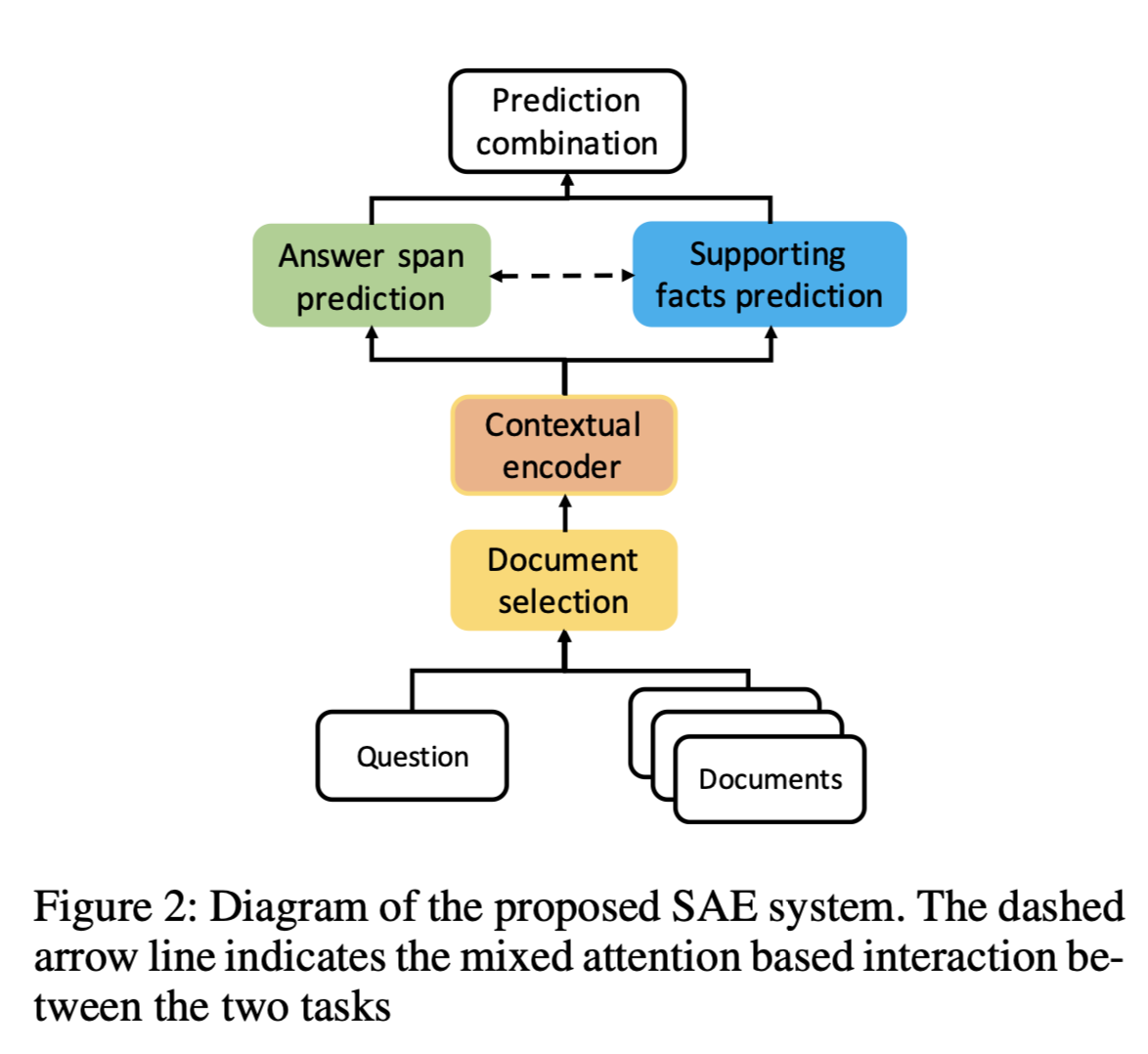
模型结构
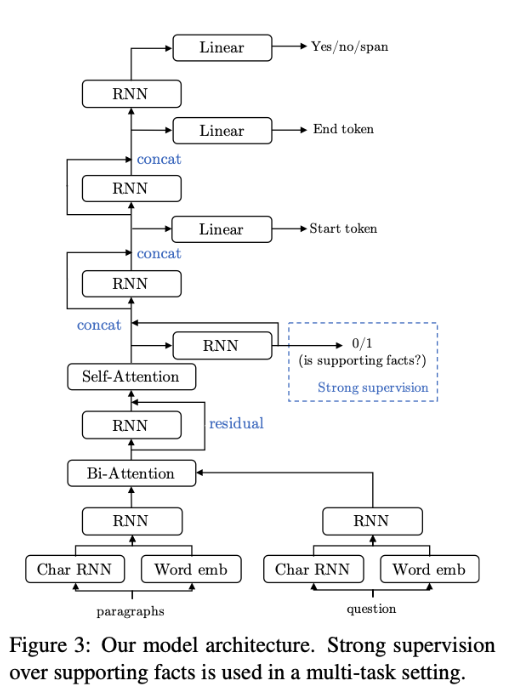
- 对于每个句子,在第一个和最后一个位置连接selfattention layer的输出,并使用binary linear classifier来预测当前句子成为支持事实的概率。
- 将此分类器的二进制交叉熵损失最小化。 在多任务学习环境中,该目标与正常问答目标共同得到优化,并且它们共享相同的low-level representations。
- 使用该分类器,还可以在支持事实预测的任务上评估模型以评估其可解释性 。
性能水平
评估指标
exact match (EM) and F1
计算F1
- 计算EM
- 仅当两个任务都完全匹配时,Joint EM才为1,否则为0。
- 逐个示例评估所有指标,然后对评估集中的示例进行平均。
结论
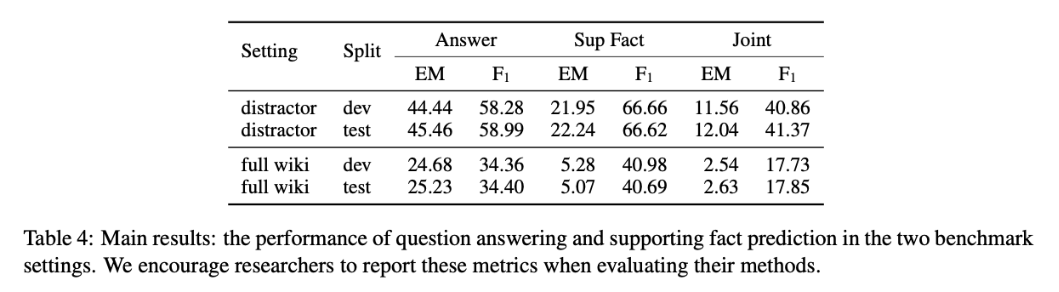
在两种设置下,扩大上下文范围会增加问题回答的难度,所有设置下的模型性能均明显低于人工性能。 与distractor相比full wiki设置中的性能要低得多。
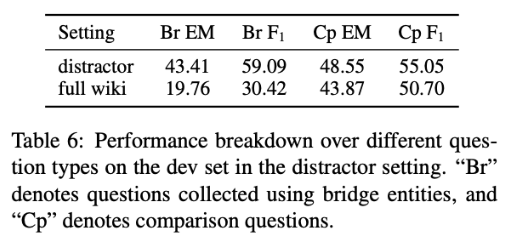
按不同问题类型测试:
- distractor setting下comparison questions的F1得分比bridge entities questions低,表明对这种新颖的问题类型进行更好的建模可能需要更好的神经网络结构。
- full wiki setting下bridge entities questions的性能显著下降,而comparison questions的性能仅略有下降,是因为两个实体通常都出现在比较问题中,从而降低了检索难度 。
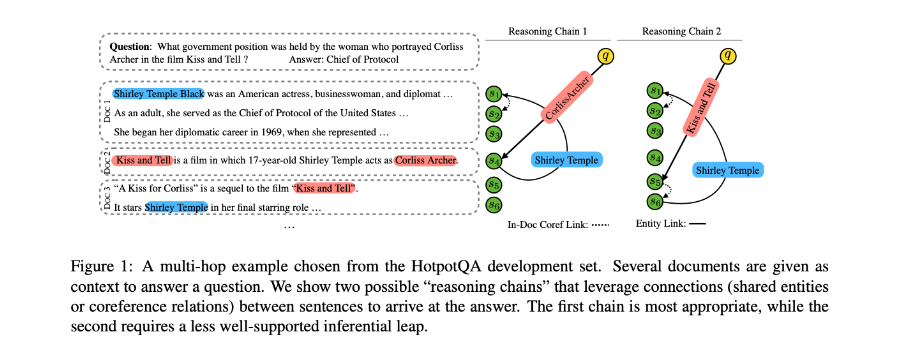
单个样本结构

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 没有胡子的猫Asimok!
相关推荐



评论

