Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering
Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering
论文:https://arxiv.org/abs/1911.10470
代码:https://github.com/AkariAsai/learning_to_retrieve_reasoning_paths
学习在维基百科中检索问题的推理路径
- 基于推理路径
任务
从维基百科中提取推理路径实现多轮问答。
多轮问答:
需要结合多篇文档的“知识推理”能得到最终答案。
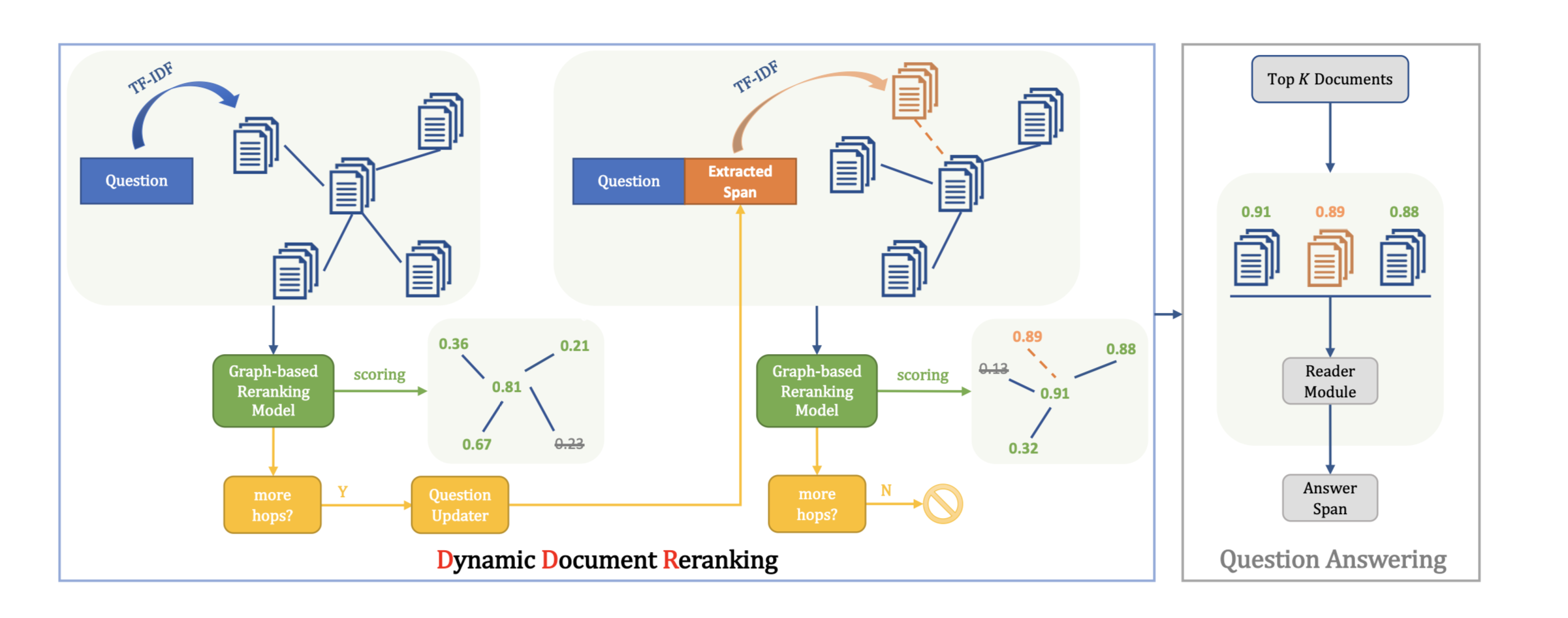
方法(模型)
- 通过维基百科的超链接构建一个维基百科图网络,在不同的文档之间建模。
- 使用一个RNN给推理路径建模,从而找到最佳推理路径。
模型结构:
由一个提取器和阅读器组成
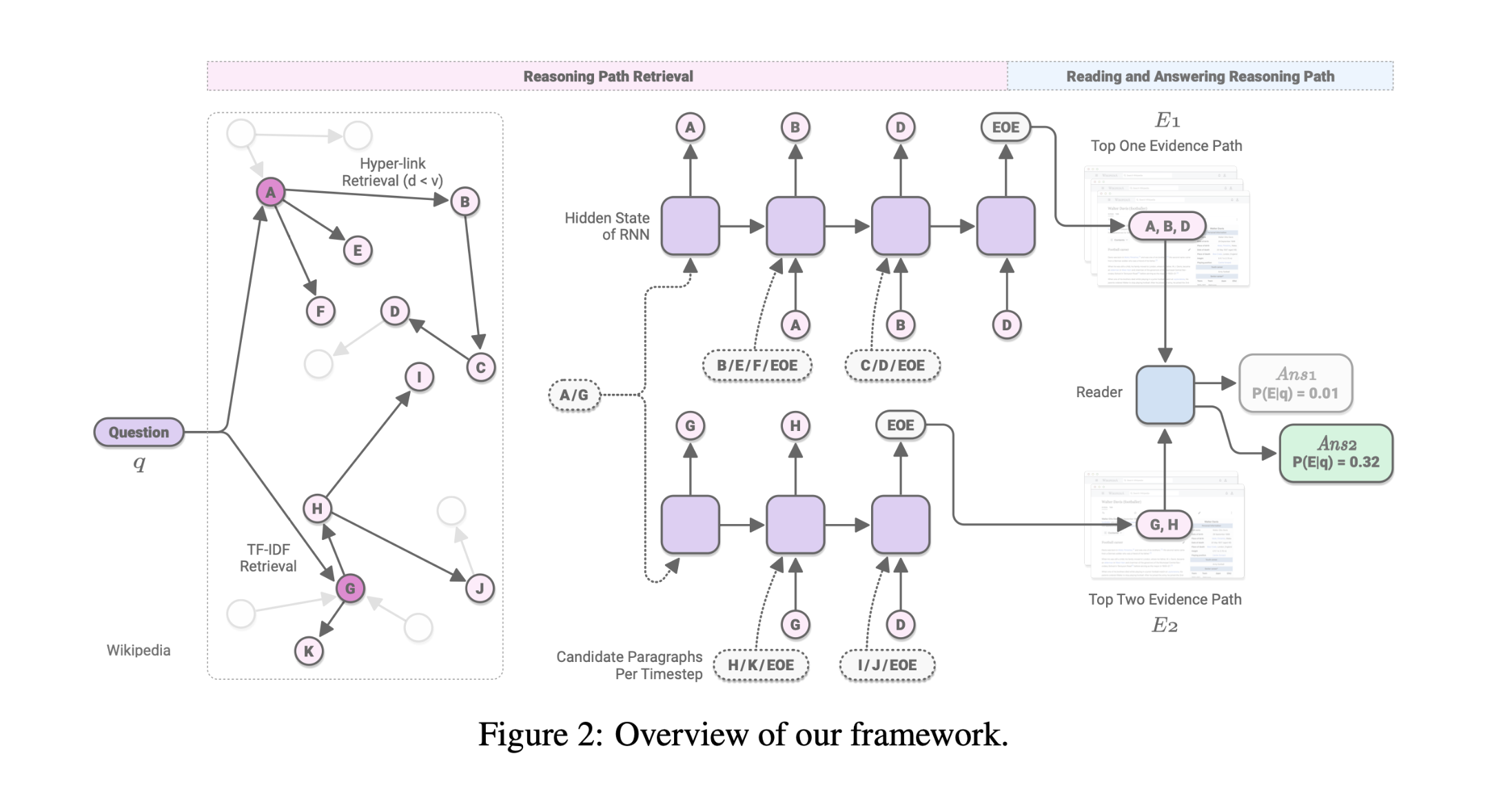
推理路径提取器(Reasoning Path Retrieval):根据维基百科之间的超链接关系得到若干推理路径。
阅读理解答案抽取器(Reading and Answering Reasoning Path):基于这些路径找到最可能的一条路径作为最终的答案。
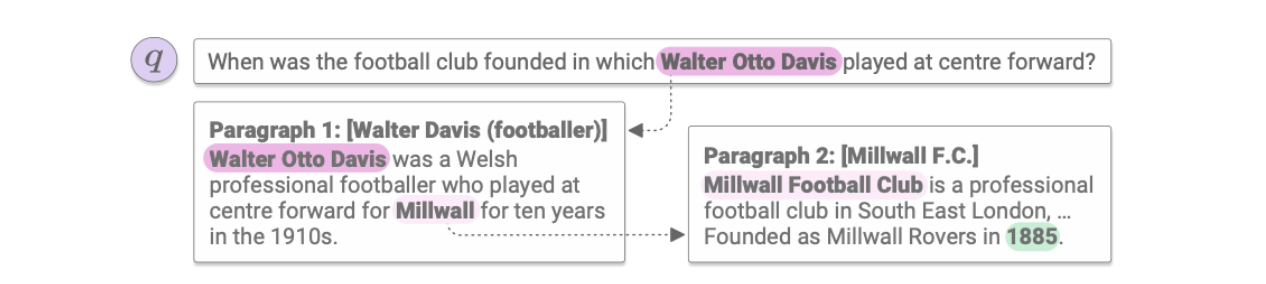
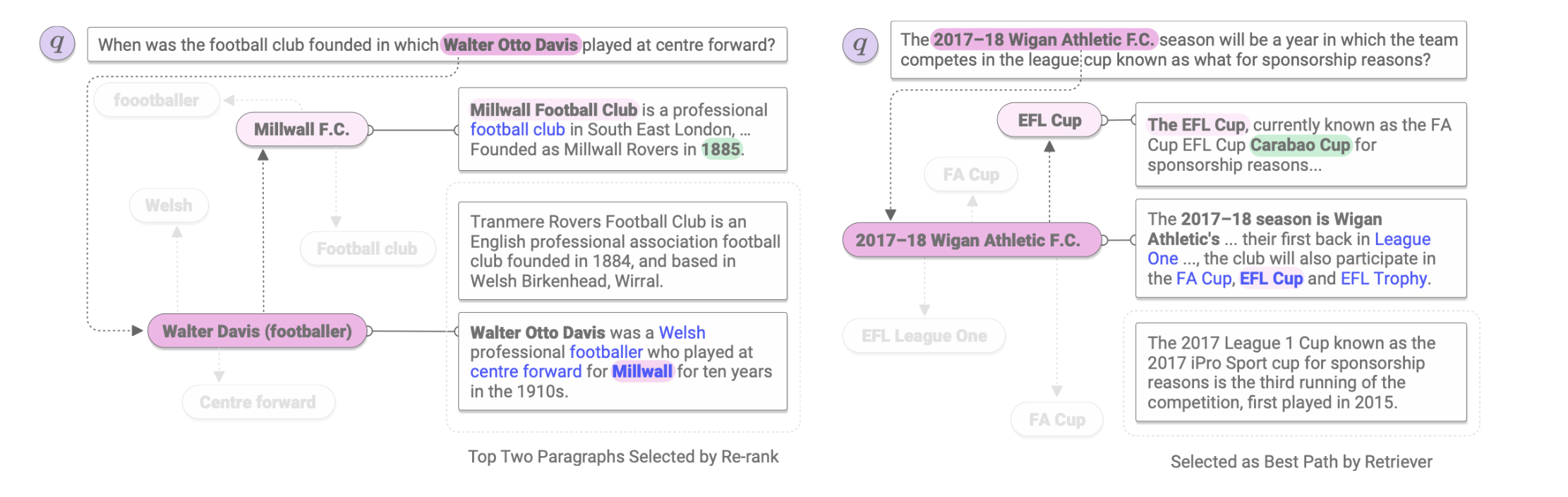
将维基百科文章里的每个段落$p$作为基本单元。给定问题$q$,模型首先找到一条推理路径$E = [pi, . . . , p_k]$,用$S{retr}(q, E)$表示;然后在$E$中找到答案$a$,用$S_{read}(q, E, a)$表示。
推理路径提取
Constructing the Wikipedia graph
直接使用维基百科中的超链接构建有向图$G$。
General formulation with a recurrent retriever
使用RNN建模问题$Q$的推理路径。
给定问题$q$,在时间步$t$时,模型从候选段落集$C_t$中找出$p_i$ ,与$q$拼接计算$p_i$的概率。
遇到$[EOE]$时结束推理,允许它在给定每个问题的情况下捕获具有任意长度的推理路径。
Beam search for candidate paragraphs
为防止计算量过大,使用Beam Search来构建多个检索路径。
Data augmentation
对真实的推理路径$g = [p1, . . . , p{|g|}]$增加一条新的推理路径$g = [pr,p_1, . . . , p{|g|}]$,$p_r$是与$p_1$有联系的TF-IDF分最高的一个段落。
Negative examples for robustness
使用两种负采样策略:
(1)基于TF-IDF
(2)基于超链接
单轮QA只用(1),多轮QA两者都用,负采样数为50。
Loss function
在 $C_t$上使用广泛使用的交叉熵损失和softmax归一化是不理想的,因为同时最大化$g$和增广的$g_r$是矛盾的。因此本文独立评估$P(p_i|h_t)$并使用 binary cross-entropy loss来最大化所有可能路径的概率值。
- $\tilde{p}∈\tilde C_t$是负样本集合。
READING AND ANSWERING GIVEN REASONING PATHS
使用Bert模型计算推理路径和答案概率。
使用Bert模型对应于CLS标识符位的输出判断推理路径包括答案的概率。
Multi-task loss function
数据集
- HotpotQA
- SQuAD Open
- Natural Question Open
性能水平
HotpotQA验证集测试结果:
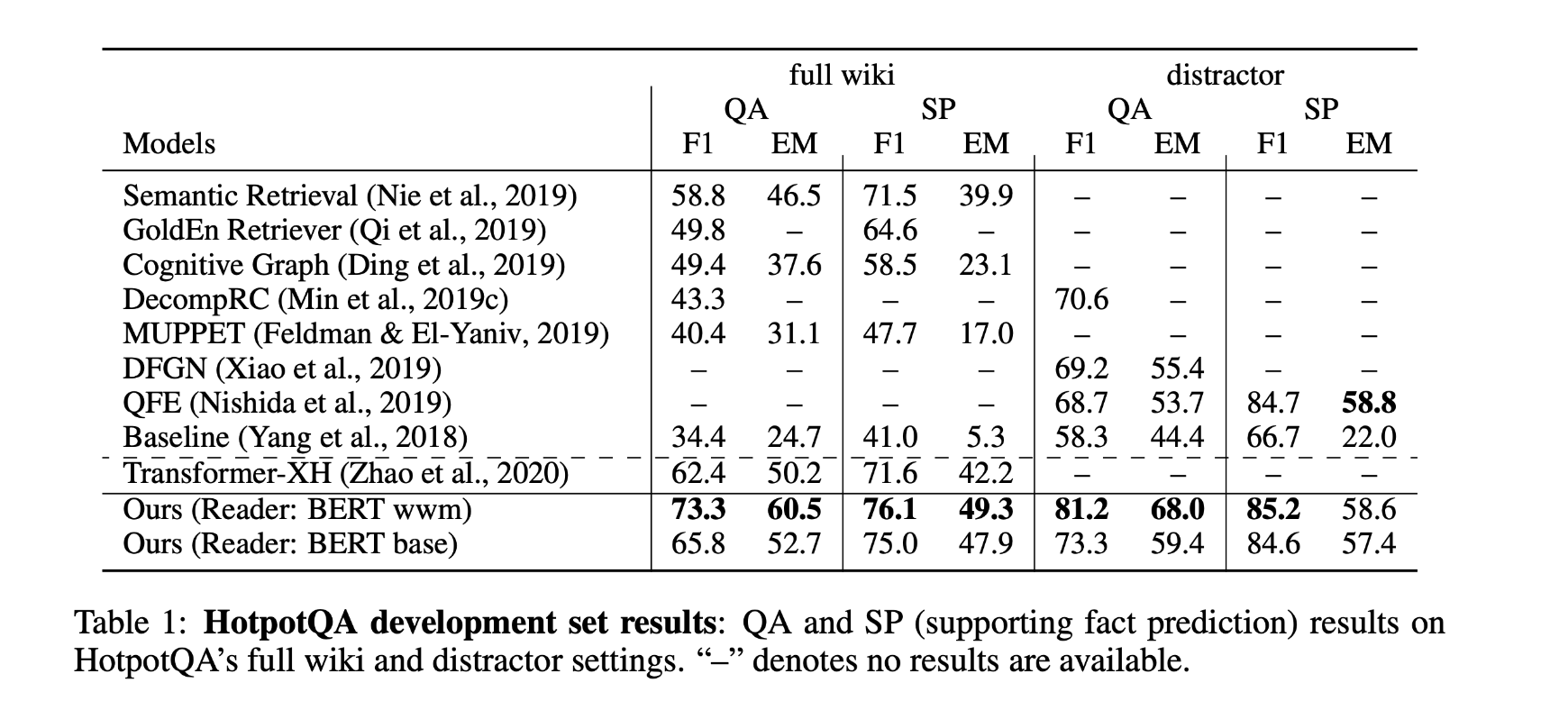
HotpotQA测试集测试结果:

本文提出的模型在hotpot数据集上取得了非常优秀的测试结果。
SQuAD Open测试结果:

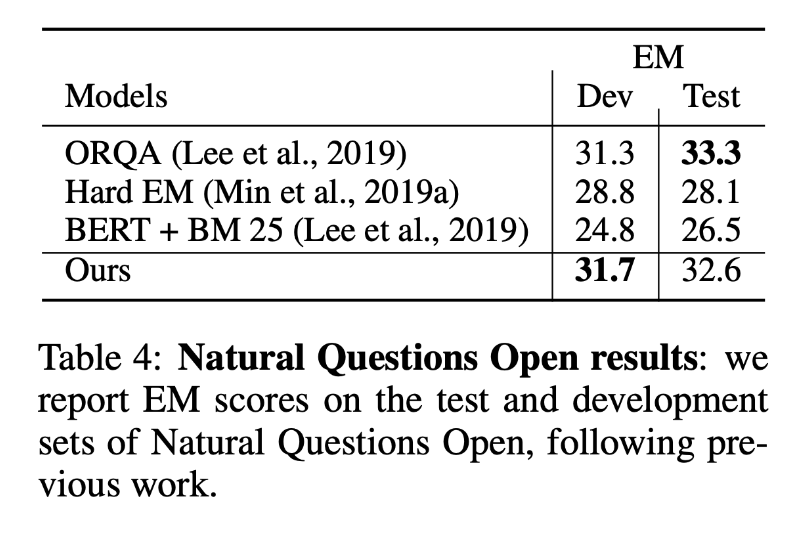
Natural Question Open测试结果:
结论
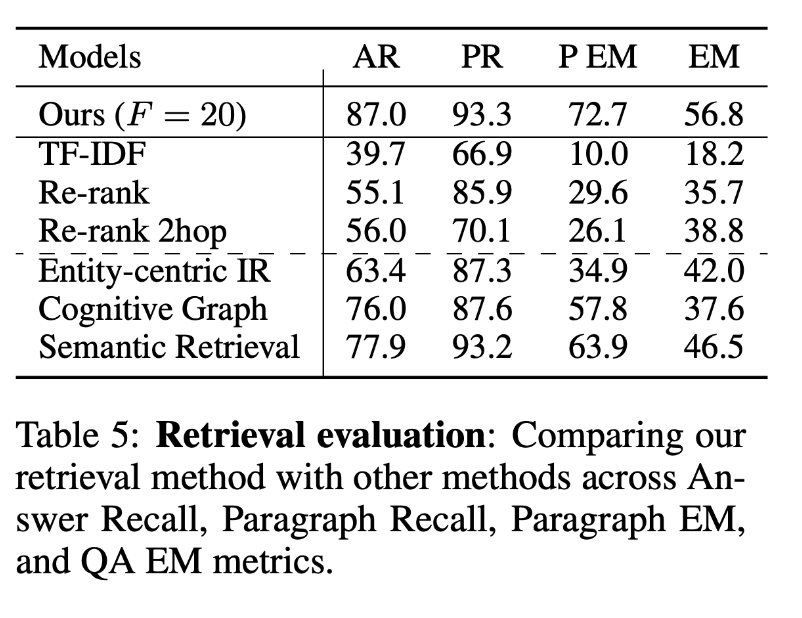
不同的路径抽取方法比较:
消融实验:

可以看到,移除任何一部分对模型的结果影响都比较大。
实体链接:
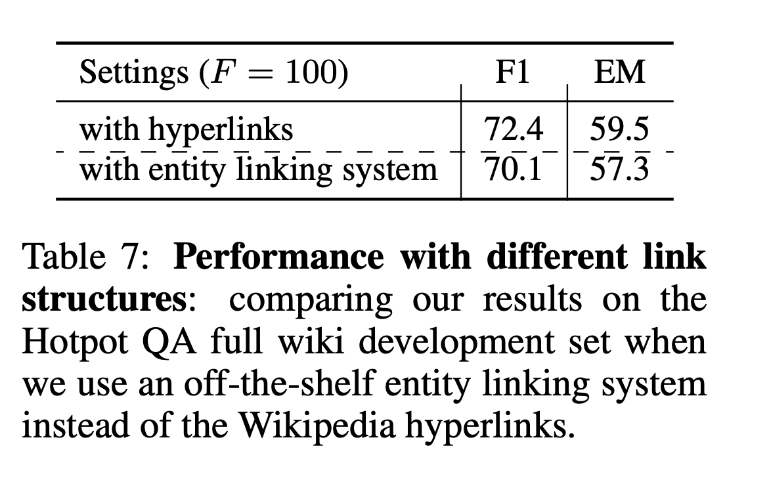
使用超链接和实体链接系统对实验结果影响不大,说明超链接并不是必要因素。
推理路径长度:

推理路径的长度对实验结果有显著的影响,推理路径较短时准确率较低。
本文介绍了一种新的基于图的递归检索方法,该方法在维基百科图上检索推理路径,以回答开放领域多轮问答。使用推理路径提取器构建推理路径,使用阅读理解答案抽取器对推理路径进行重新排序,并将最终答案确定为从最佳推理路径中提取的答案。在多个数据集上都表现出了优秀的性能。
思考
搜索算法beam search(束搜索)
是exhaustive search和greedy search的折中方案。
beam search有一个超参数beam size(束宽),设为$k$ 。第一个时间步长,选取当前条件概率最大的 $k$个词,当做候选输出序列的第一个词。之后的每个时间步长,基于上个步长的输出序列,挑选出所有组合中条件概率最大的$k$ 个,作为该时间步长下的候选输出序列。始终保持$k$个候选。最后从$k$个候选中挑出最优的。