
Attention Is All You Need
Attention Is All You Need
应用于NLP的机器翻译问题。
任务
- 由于RNN的递归结构,导致它无法并行计算,RNN以及他的衍生模型最大的缺点就是计算缓慢。并且缺乏对全局信息的理解。因此提出了完全基于attention的Transformer模型。
方法(模型)
Transformer模型是纯attention模型,完全依赖attention机制来描述输入与输出的全局依赖。
模型:
- 输入:$x=(x1,x2,⋯,xn)$(是一个离散的符号序列)
- encoder:将它映射成连续值序,$z=(z1,z2,⋯,zn)$
- decoder:对于给定的$z$,生成一个输出符号序列,$y=(y1,y2,⋯,ym)$
- 优化器:Adam
- 使用dropout和Label Smoothing防止过拟合
Encoder and Decoder Stacks
Encoder与Decoder堆叠
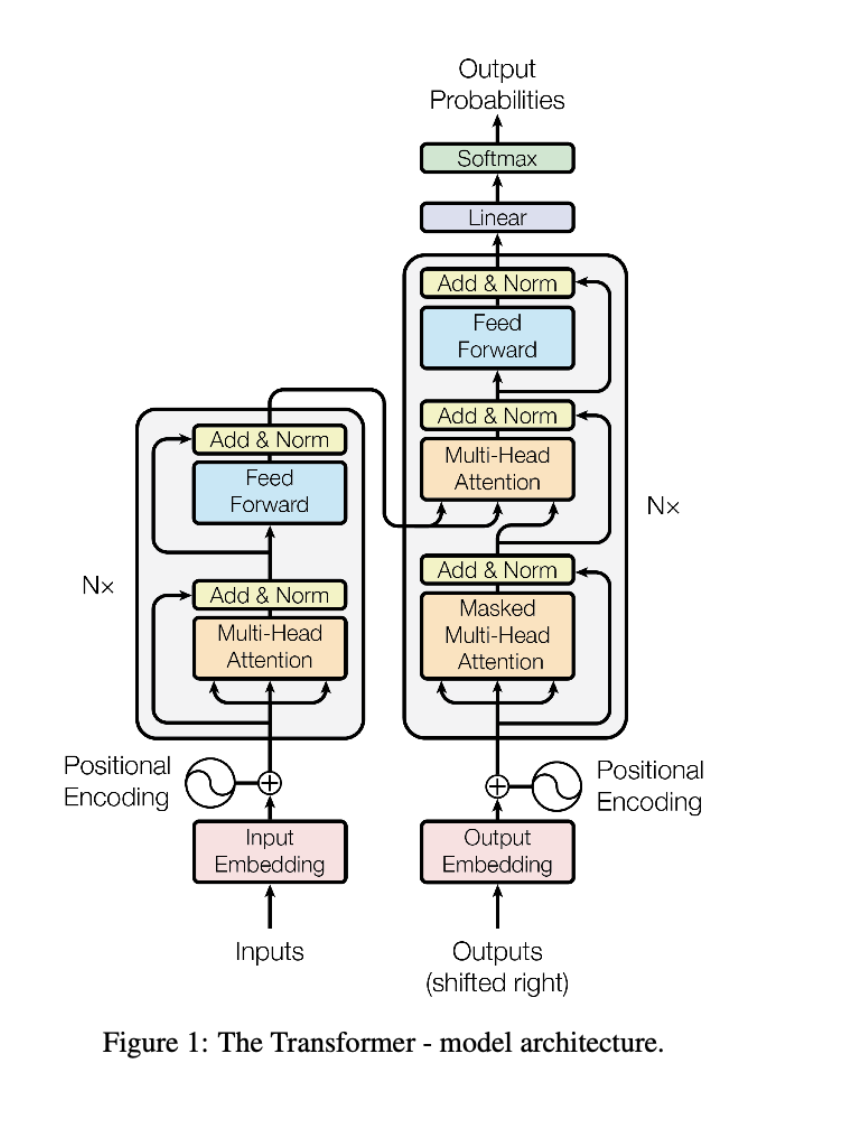
Encoder
- Transformer模型的Encoder由6个基本层堆叠起来,每个基本层包含两个子层。
- 第一个子层:注意力机制
- 第二个子层:全连接前向神经网络。
- 对两个子层都采用了residual connection,并进行了layer normalization。
Decoder
- Decoder由6个基本层堆叠起来,每个基本层包含三个子层。
- 第一个子层:注意力机制
- 第二个子层:全连接前向神经网络。
- 第三个子层:注意力机制
- 对两个子层都采用了residual connection,并进行了layer normalization。
Attention
注意力机制:将一个query和一个key-value pairs,映射到正确的输入。
- query、key、value、output都是向量。
- 输出作为一个值的加权和计算得到,其中分配到每个值的权重由请求的兼容函数关于对应键计算得到。
Scaled Dot-Product Attention

输入:$d_k$维的query、key、$d_v$维的value
MatMul:计算query和各个key的点积
Scale:除以$\sqrt {d_k}$ 归一化
softmax:获得权重
MatMul:和value相乘得到输出
Multi-Head Attention
多头注意力机制
参数不共享
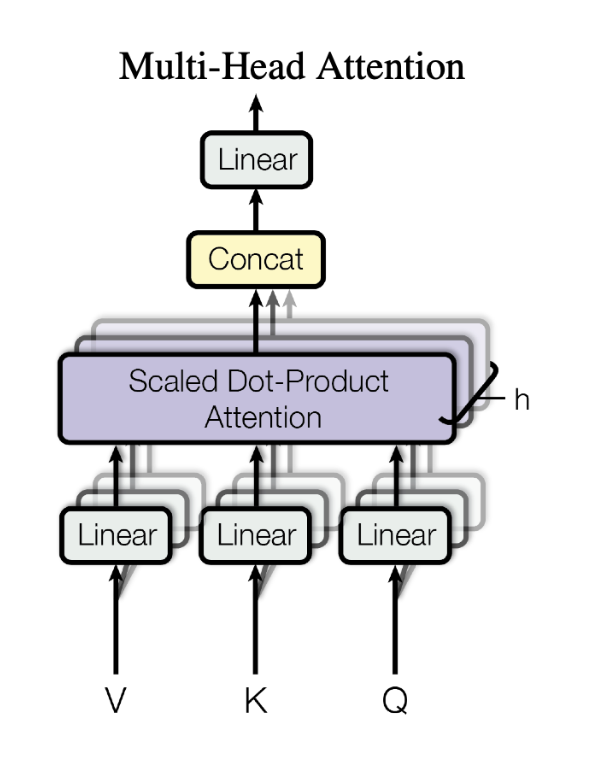
用h个不同的线性变换分别将$d_{model}$维的key、value、query映射成$d_k$维、$d_k$维和$d_v$维
代入注意力机制,产生$h×d_v$维输出,然后拼起来
再用一个线性变换得到最终的输出。
Position-wise Feed-Forward Networks
Position-wise 前向神经网络
- encoder和decoder的每一层都包含一个前向神经网络。
由两个线性变换和ReLU激活函数组成。
Positional Encoding
位置编码
论文中的位置编码是根据下述公式计算得到的。
本文的模型结构没有使用任何递归结构或卷积结构,为了让模型能使用序列的顺序,必须引入某种能表达输入序列每个部分的绝对或相对位置的信息。
位置编码:在送入encoder和decoder之前,先对输入进行编码,编码后的向量维度是$d_{model}$,和embedings具有相同的维度,因此可以相加。
- 通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样 Attention 就可以分辨出不同位置的词了。
- 选择正弦曲线版本是因为它可以使模型推断出比训练过程中遇到的序列长度更长的序列长度。
数据集
WMT 2014 English-German
WMT 2014 English-French
性能水平

- Transformer在英语-德语,英语-法语的翻译任务上都表现出比较好的翻译效果。
- 并且Transformer的训练开销也是最小的。
结论
- 提出的Transformer,是第一个完全基于attention的序列转导模型,用multi-headed self-attention取代了encoder-decoder结构中最常用的循环层。
- 对于翻译任务,Transformer可以比基于循环或卷积层的体系结构训练更快。
扩展了解
机器翻译评价指标:BLEU(Bilingual Evaluation Understudy)
双语评估替补
- 用于评估模型生成的句子(candidate)和实际句子(reference)的差异的指标。
- 取值范围在0到1之间,,如果两个句子完美匹配(perfect match),那么BLEU是1,反之,如果两个句子完美不匹配(perfect mismatch),那么BLEU为0。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 没有胡子的猫Asimok!
相关推荐




评论

