
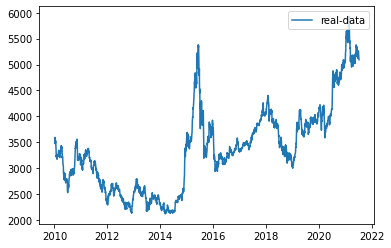
用LSTM预测股票行情
这里采用沪深300指数数据,时间跨度为2010-10-10至今,选择每天最高价格。假设当天最高价依赖当天的前n(如30)天的沪深300的最高价。用LSTM模型来捕捉最高价的时序信息,通过训练模型,使之学会用前n天的最高价,判断当天的最高价(作为训练的标签值)。
导入数据这里使用tushare来下载沪深300指数数据。可以用pip 安装tushare。
123456789import tushare as ts #导入cons = ts.get_apis() #建立连接#获取沪深指数(000300)的信息,包括交易日期(datetime)、开盘价(open)、收盘价(close),#最高价(high)、最低价(low)、成交量(vol)、成交金额(amount)、涨跌幅(p_change)df = ts.bar('000300', conn=cons, asset='INDEX', start_date='2010-01-01', end_date='')#删除有null值的行df = df.dropn ...
RNN——使用字符级RNN对名称进行分类
使用字符级 RNN 对名称进行分类1%matplotlib inline
字符级 RNN 将单词读取为一系列字符,在每一步输出预测和隐藏状态,将其先前的隐藏状态输入到下一时间步。将最终预测作为输出,即单词属于哪个类。
具体来说,我们将训练来自 18 种起源语言的数千个姓氏,并根据拼写预测名称来自哪种语言:示例:
123456789$ python predict.py Hinton(-0.47) Scottish(-1.52) English(-3.57) Irish$ python predict.py Schmidhuber(-0.19) German(-2.48) Czech(-2.68) Dutch
Note: Download the data from here <https://download.pytorch.org/tutorial/data.zip>_ and extract it to the current directory.
Included in the data/names directory are 18 text files ...
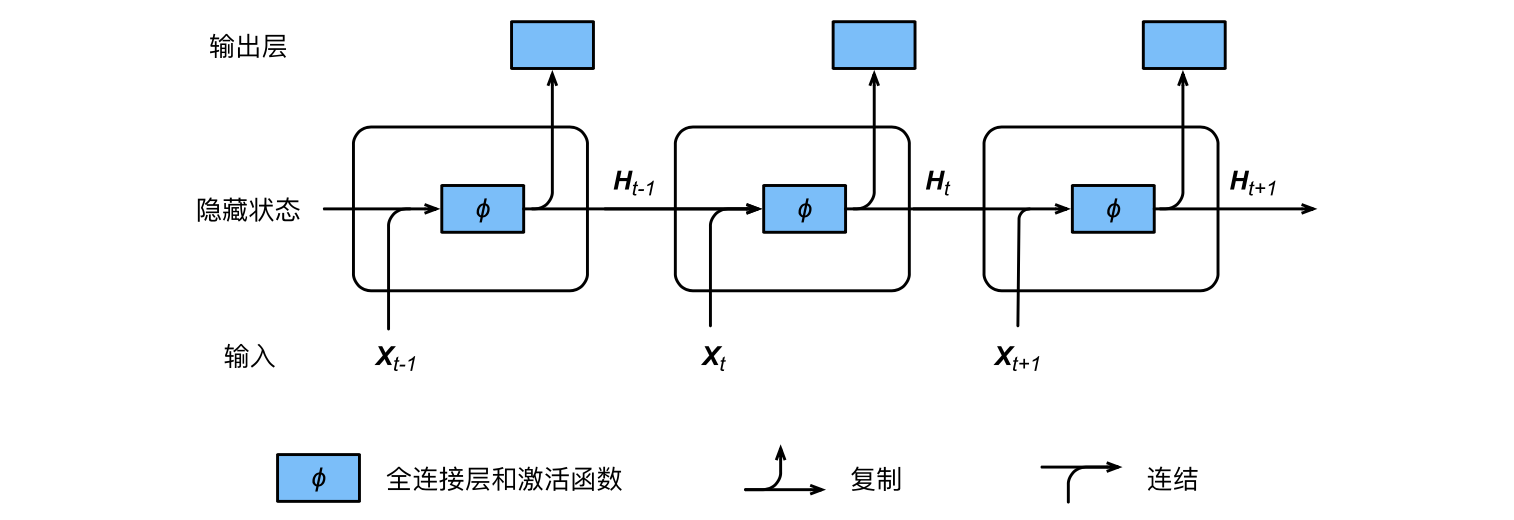
RNN循环神经网络
RNN循环神经网络
序列数据:与先后顺序有关的数据。
对于序列数据,可以使用循环神经网络。
H_t=ϕ(X_tW_{xh}+H_{t−1}W_{hh}+b_h)
O_t=H_tW_{hq}+b_q
$X_t∈R^{n×d}$是序列中时间步$t$小批量输入。
$H_t∈R^{n×h}$是该时间步的隐藏变量。
隐藏层的权重$W{xh}∈R^{d×h}$、$W{hh}∈R^{h×h}$和偏差 $b_h∈R^{1×h}$
输出层的权重$W_{hq}∈R^{h×q}$和偏差$b_q∈R^{1×q}$
时间步$t$的隐藏变量的计算由当前时间步的输入和上一时间步的隐藏变量共同决定。
其中:$XtW{xh}+H{t−1}W{hh}$可以写成矩阵$[Xt,H{t−1}]^T$与$[W{xh},W{hh}]$连接后的乘积。
含隐藏状态的循环神经网络:
在时间步$t$,隐藏状态的计算可以看成是将输入$Xt$和前一时间步隐藏状态$H{t−1}$连结后输入一个激活函数为$ϕ$的全连接层。
该全连接层的输出就是当前时间步的隐藏状态$Ht$ ,且模型参数为Wxh与$W{hh}$ 的连结,偏差为$b_h$ ...

python——os.path模块常用方法汇总
os.path模块常用方法汇总123456789101112131415161718192021222324252627282930313233os.path.abspath(path) #返回绝对路径os.path.basename(path) #返回文件名os.path.commonprefix(list) #返回list(多个路径)中,所有path共有的最长的路径。os.path.dirname(path) #返回文件路径os.path.exists(path) #路径存在则返回True,路径损坏返回Falseos.path.lexists #路径存在则返回True,路径损坏也返回Trueos.path.expanduser(path) #把path中包含的"~"和"~user"转换成用户目录os.path.expandvars(path) #根据环境变量的值替换path中包含的”$name”和”${name}”os.path.getatime(path) #返回最后一次进入此path的时间。os.path.g ...
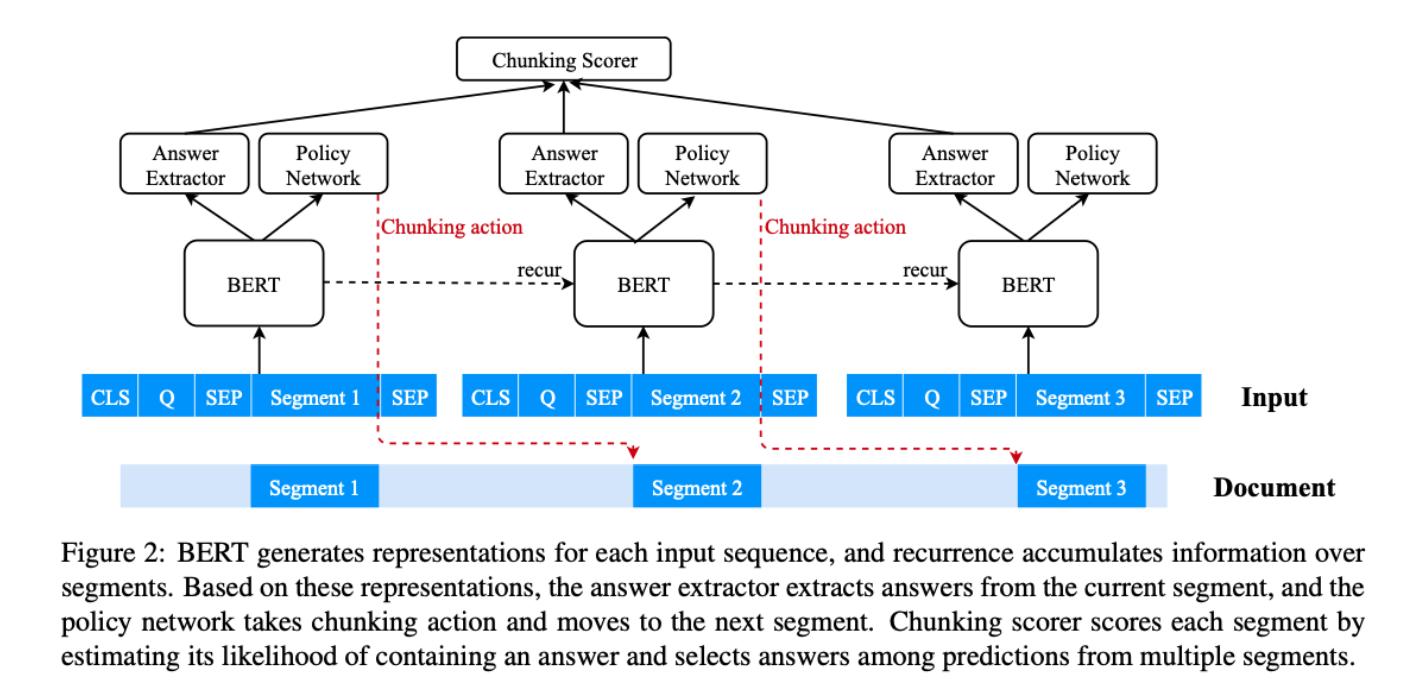
Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension
Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension
论文:https://arxiv.org/abs/2005.08056
代码:https://github.com/HongyuGong/RCM-Question-Answering
任务传统的基于transformer的模型只能接受固定长度(如512)的文本作为其输入。为了处理更长的文本输入,以前的方法通常将它们分割成等距的片段,并根据每个片段独立预测答案,而不考虑其他片段的信息。因此,可能会形成不能覆盖正确答案跨度的片段,或在其周围保留不充分的上下文,大大降低性能。此外,回答需要跨段信息的问题的能力较差。本文提出recurrent chunking机制(RCM)提升长文本机器阅读理解的性能,以防止答案跨度过于接近段的边界和覆盖不完整的答案。
方法(模型)通过强化学习,让模型以更灵活的方式学习分块:模型可以决定它要处理的下一个片段的方向。还采用了递归机制,使信息能够跨段流动。
传统方法:
首先将输入的文本分成等距的片段,然后预测每个单独 ...
Dynamic Sampling Strategies for Multi-Task Reading Comprehension.md
Dynamic Sampling Strategies for Multi-Task Reading Comprehension
论文:https://www.aclweb.org/anthology/2020.acl-main.86.pdf
代码:https://github.com/mrqa/MRQA-Shared-Task-2019
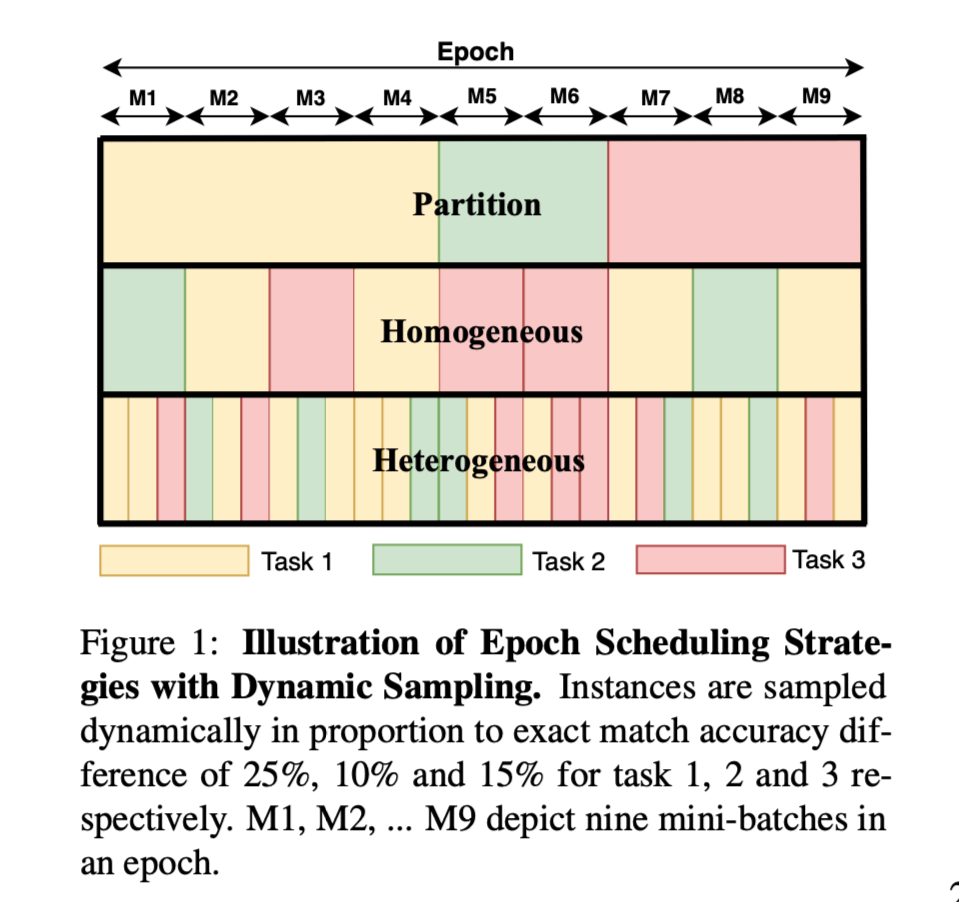
任务根据多任务模型在数据集上的当前表现与单任务表现的比例来选择训练实例,比较哪种实例抽样方法和历时调度策略能提供最佳性能。
catastrophic forgetting:在一个不平衡的训练集中,当训练从该数据集开始时,特定数据集的性能会急剧下降。
多任务训练的两个基本方面:
how many instances are sampled from each task per epoch
how those instances are organized within the epoch
方法(模型)本文引入了一种动态抽样策略,从数据集中选择实例,其概率与当前某些指标(如EM或F1得分)的性能和同一模型在该数据集中的单任务性能之间的差距 ...
Semantic Graphs for Generating Deep Questions
Semantic Graphs for Generating Deep Questions
论文:https://arxiv.org/abs/2004.12704
代码:https://github.com/WING-NUS/SG-Deep-Question-Generation
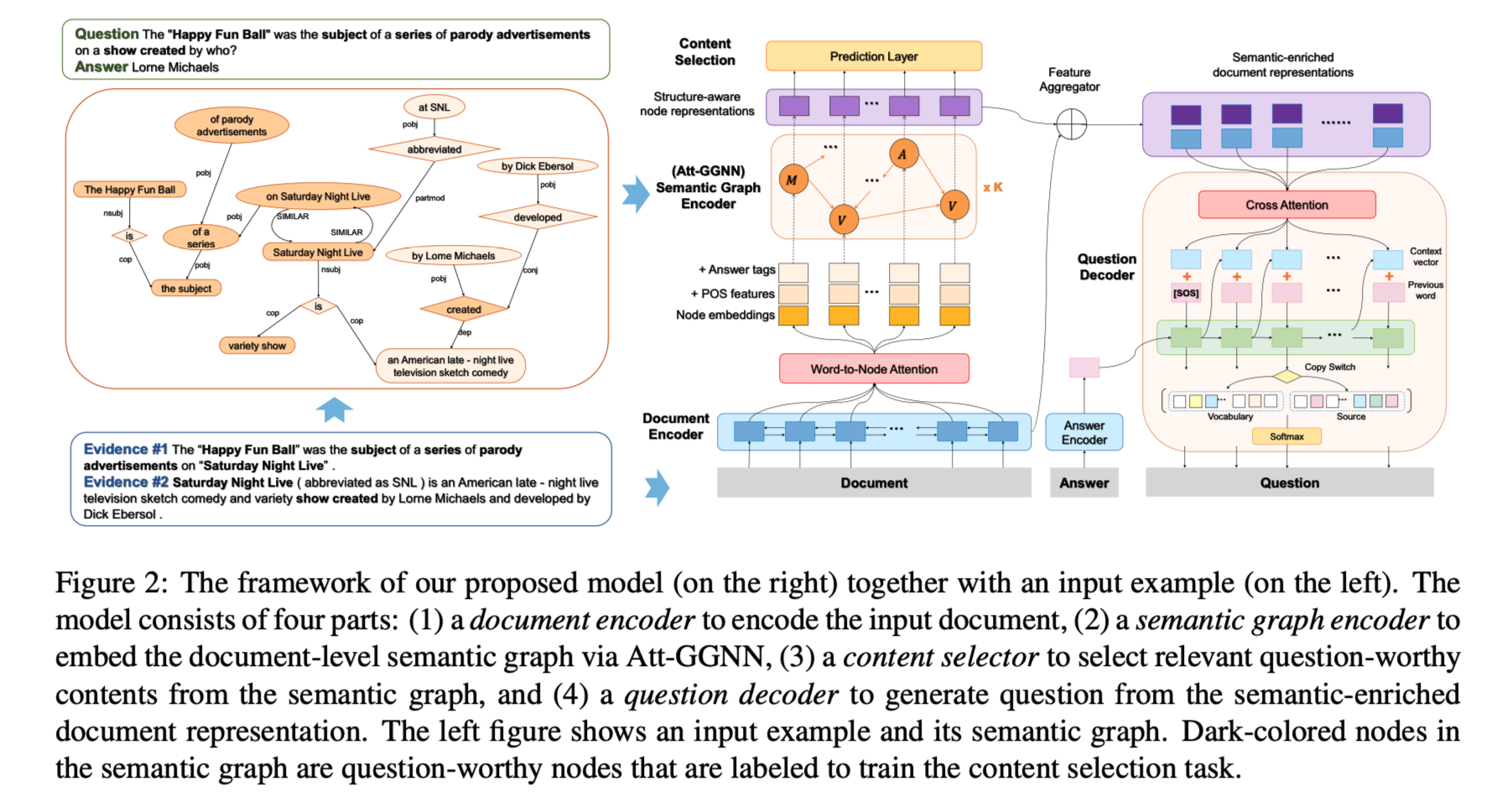
任务本文提出了深度问题生成(DQG)的问题,其目的是生成需要对输入段落的多个信息进行推理的复杂问题。
方法(模型)为了捕捉文件的全局结构并促进推理,本文提出了一个新的框架,首先为输入的文件构建一个语义层面的图,然后通过引入一个基于注意力的GGNN(Att-GGNN)对语义图进行编码。之后,融合文档层面和图层面的表示,对内容选择和问题解码进行联合训练。
问题定义:
\overline{Q} = arg\ \underset{Q}max P(Q|D, A)
$\overline{Q}$:生成的问题
D:文档
A:答案
模型结构:
三个模块:
semantic graph construction
为输入构建DP(Dependency Parsing) or SRL-based semantic g ...
Hierarchical Graph Network for Multi-hop Question Answering
Hierarchical Graph Network for Multi-hop Question Answering
论文:https://arxiv.org/abs/1911.03631
代码:https://github.com/yuwfan/HGN
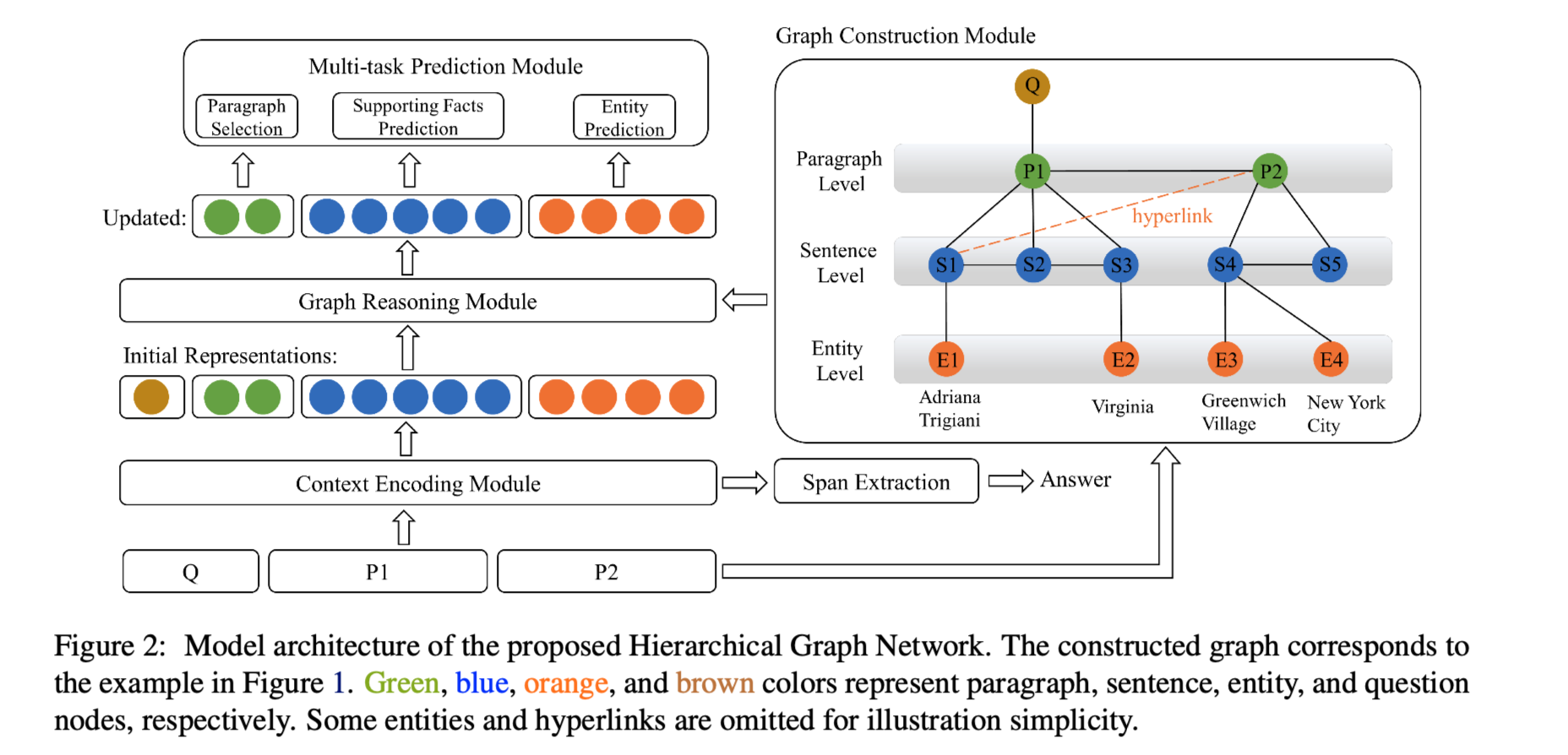
任务 提出了用于多跳问题回答的 Hierarchical Graph Network(HGN)。为了将分散在多个段落的文本中的线索汇总起来,通过构建不同粒度级别的节点(问题、段落、句子和实体)来创建一个层次图。将异质节点被编织成一个完整的图,不同颗粒度的节点被用于不同的子任务(例如,段落选择、支持事实提取和答案预测)。
方法(模型) 为了将分散在多个段落的文本中的线索汇总起来,通过构建不同粒度级别的节点(即问题、段落、句子和实体)来创建一个hierarchical graph,这些节点的表示是由基于BERT的上下文编码器初始化的。
Hierarchical Graph Network四个主要的组件:
Graph Construction Module
构建层次图以连接不同来源的线索。
构建 ...
Reinforced Multi-task Approach for Multi-hop Question Generation
Reinforced Multi-task Approach for Multi-hop Question Generation
论文:https://arxiv.org/abs/2004.02143
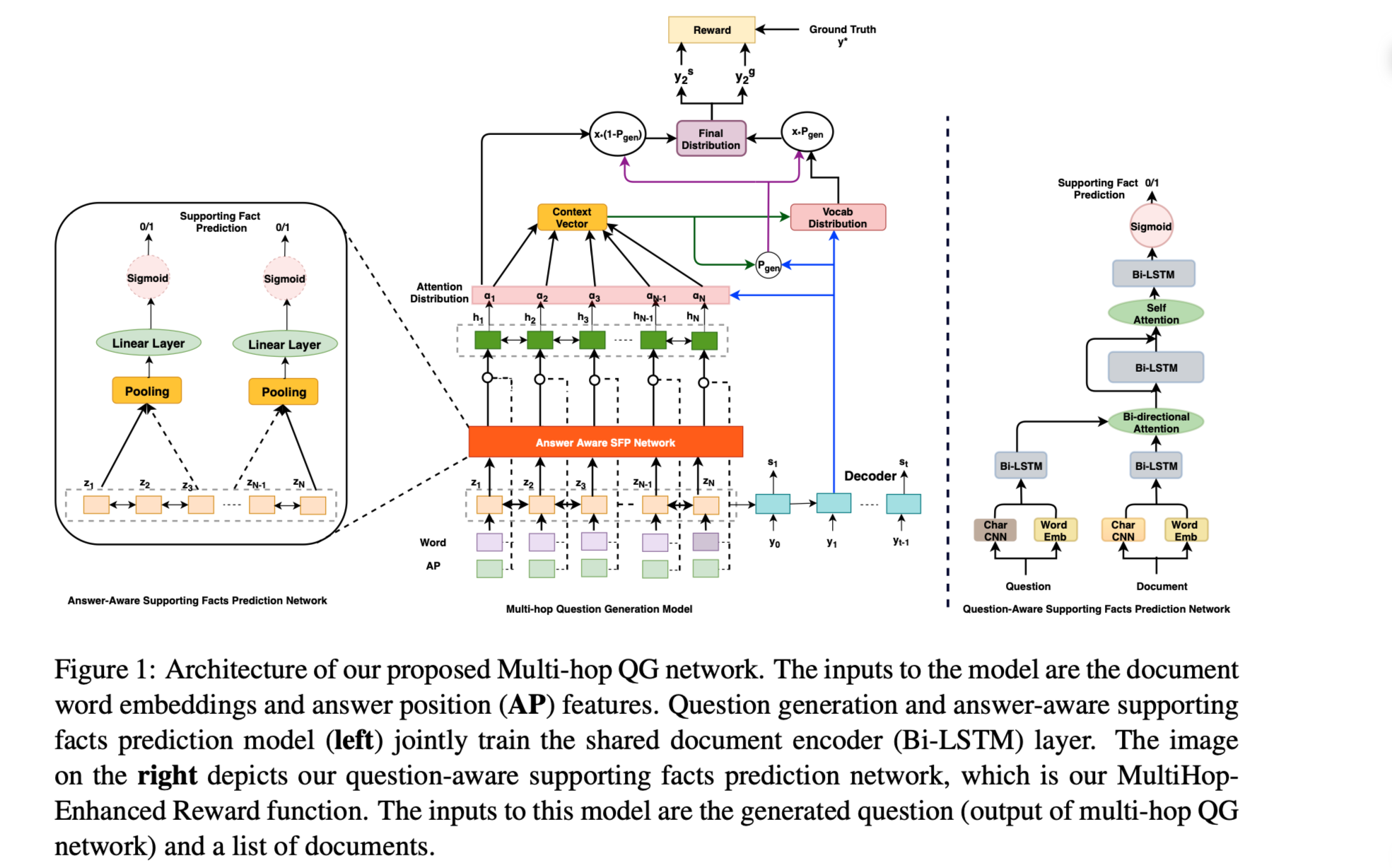
任务问题生成试图解决问题回答的逆向问题,通过给定一个文件和一个答案来生成一个自然语言问题。本文旨在使用多个支持性事实来生成高质量的问题。
方法(模型)采用了多跳问题生成,根据上下文中的支持事实生成相关问题。采用了多任务学习的方式,并辅以answer-aware支持性事实预测的任务来指导问题生成器。
问题生成示例:
处理多跳问题生成的两个阶段:
在第一阶段,学习支持性事实意aware的编码器表示,通过与问题生成的联合训练来预测文档中的支持性事实,随后增强这些支持性事实的利用。
后者的目标被表述为一个问题意识到的支持性事实预测奖励,它与监督序列损失一起被优化。此外,我们观察到多任务框架为问题生成的性能提供了实质性的改进,也避免了在生成的问题中包含噪声句子信息,而强化学习(RL)将完整和复杂的问题带到其他最大似然估计(MLE)优化的QG模型中。
Multi-Hop Question Ge ...
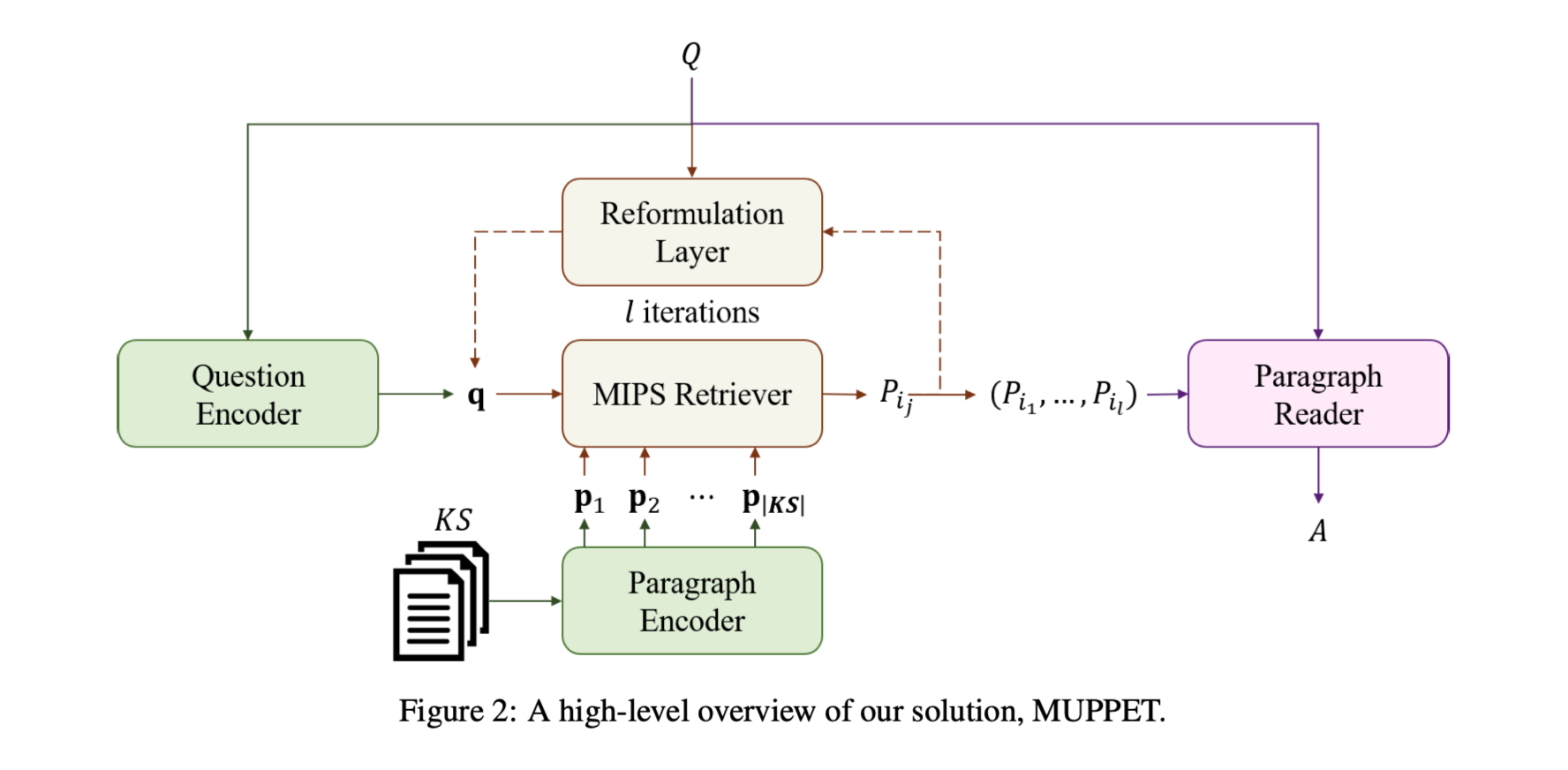
Multi-Hop Paragraph Retrieval for Open-Domain Question Answering
Multi-Hop Paragraph Retrieval for Open-Domain Question Answering
论文:https://arxiv.org/abs/1906.06606
代码:https://github.com/yairf11/MUPPET
任务多跳开放域问题回答(QA)任务,需要同时进行文本推理和高效搜索。本文提出了一种检索多个支持段落的方法,这些段落嵌套在一个庞大的,包含回答一个给定问题的必要证据的知识库中。
方法(模型)本文提出的方法通过形成一个问题和段落的联合向量表示来反复检索支持性段落。检索是通过考虑知识源中段落的上下文句子层面的表示来进行的。
任务定义:
$(KS, Q, A)$
Background knowledge source:$KS = {P1, P_2, . . . , P{|KS|}}$
由$li$ 个tokens组成的文本段落:$P_i = (p_1, p_2, . . . , p{l_i})$
m个tokens组成的段落:$Q = (q_1, q_2, . . . , q_m)$
n个tokens组成的答案:$A ...
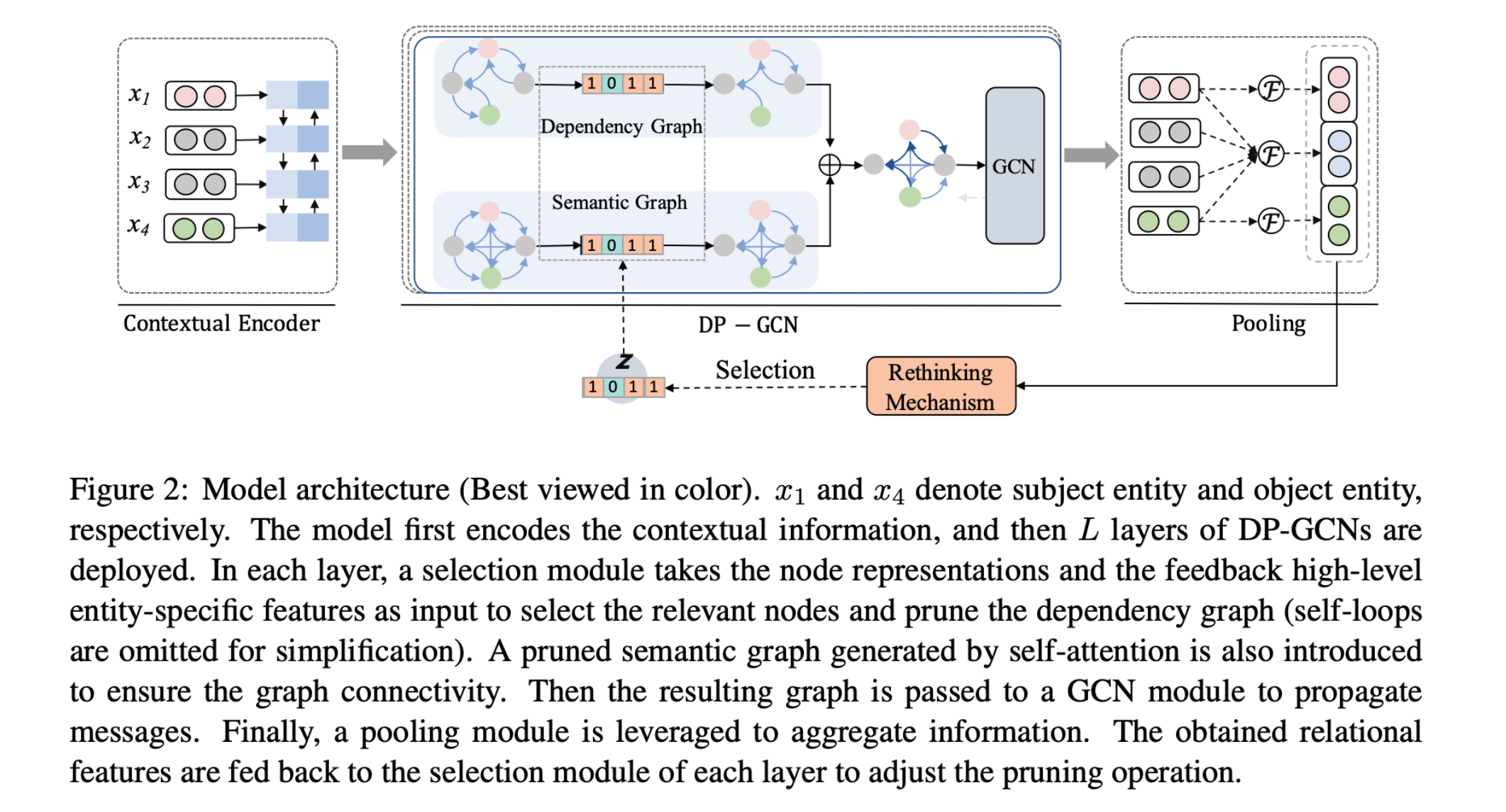
Learning to Prune Dependency Trees with Rethinking for Neural Relation Extraction
Learning to Prune Dependency Trees with Rethinking for Neural Relation Extraction
论文:https://www.aclweb.org/anthology/2020.coling-main.341/
代码:https://github.com/Cartus/AGGCN
任务 预测给定句子中的两个实体之间的关系。
利用输入句子的依赖树模型在捕获目标实体之间的长距离关系方面是有效的。但并不是所有依赖树中的标记都需要表达目标实体对的关系,一些与目标不相关的标记可能会引入噪音。如何有选择地强调目标相关的信息,并从依赖树上删除不相关的内容,仍然是一个开放的问题。
方法(模型)
RE:Relation extraction 旨在检测出现在句子中出现的两个特定实体之间的语义关系(通常分别被称为主题和对象)。
由于自然语言的可变性和模糊性,之前手工制定的修剪规则可能导致有用的信息被遗漏。本文提出了一个动态修剪图卷积网络(DP-GCN)的新架构,它在端到端的方案中 ...

Multi-hop Reading Comprehension through Question Decomposition and Rescoring
Multi-hop Reading Comprehension through Question Decomposition and Rescoring
论文:https://arxiv.org/abs/1906.02916
代码:https://github.com/shmsw25/DecompRC
任务多跳阅读理解(RC)需要在几个段落中进行推理和汇总。本文提出了将一个组合式问题分解为更简单的子问题的多跳阅读理解系统,似的这些分解的子问题可以由现成的单跳阅读模型来回答。由于这种分解的注释代价很高,本文将子问题的生成重塑为一个跨度预测问题,来生成类似于人类提出的问题。
多跳问题分解为单跳子问题示例:
方法(模型)本文提出了一种重新评分的方法,从不同的可能的分解中获得答案,并对每个分解的答案重新评分,以决定最终的答案,而不是一开始就决定分解的答案。
DECOMPRC模型实现方法:
首先,DECOMPRC根据跨度预测,将原始的多跳问题按照几个推理类型平行地分解成几个单跳的子问题。
然后,对于每个推理类型,DECOMPRC利用单跳阅读理解模型来回答每个子问题,并根据推理类型来组合 ...

Dynamically Fused Graph Network for Multi-hop Reasoning
Dynamically Fused Graph Network for Multi-hop Reasoning
论文:https://arxiv.org/abs/1905.06933
代码:https://github.com/woshiyyya/DFGN-pytorch
任务处理基于文本的问题回答(TBQA),现有的大多数方法都侧重于在一个段落中寻找问题的答案。但是许多复杂的问题需要从两个或更多的文档中分散的文本中寻找多个支持证据。本文提出了动态融合图网络(DFGN),来回答需要从多个分散的证据推理的问题。
方法(模型)DFGN包含一个动态融合层,它从给定查询中提到的实体开始,沿着从文本中动态构建的实体图进行探索,并逐渐从给定文档中找到相关的支持实体。
工作方式:
两个挑战:
并非每个文档都包含相关信息,因此基于多跳文本的质量检查要求从多个段落中过滤掉噪音并提取有用的信息。
以前的多跳Qa工作通常会将文档信息汇聚到实体图形,然后在实体图的实体上直接选择答案。 但是,在更真实的情况下,答案甚至可能不会驻留在提取的实体图的实体中 。
解决:
对于第一个挑战,DFGN根据 ...
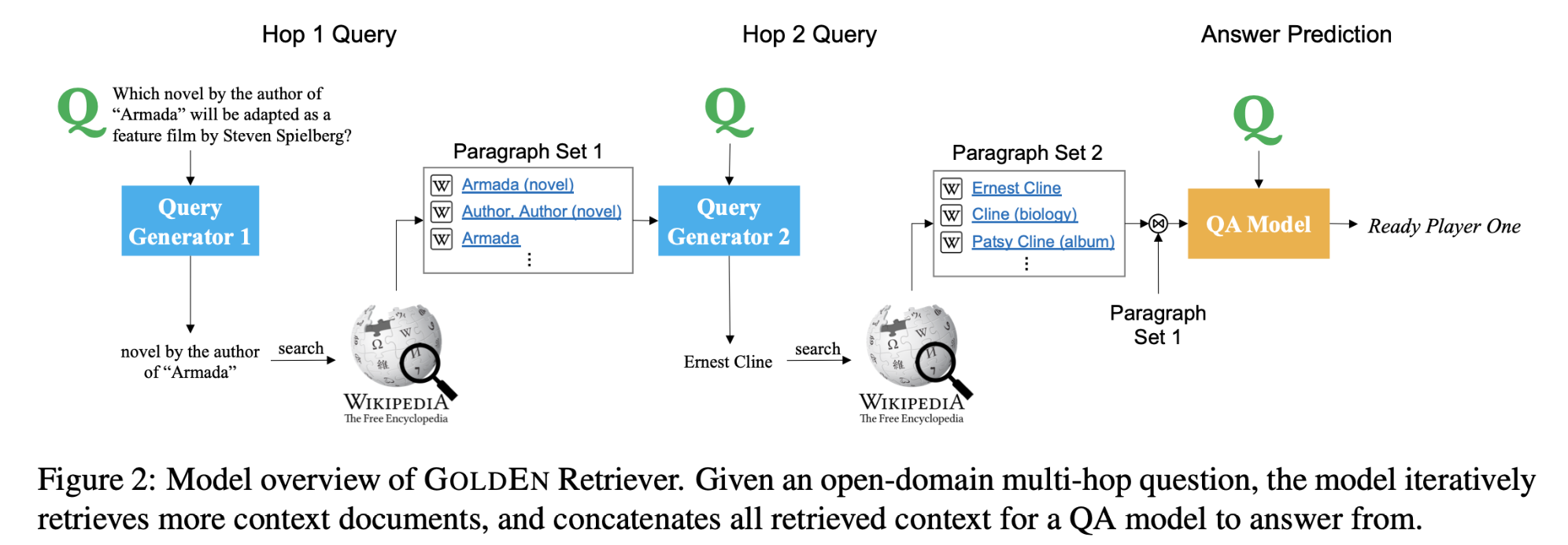
Answering Complex Open-domain Questions Through Iterative Query Generation
Answering Complex Open-domain Questions Through Iterative Query Generation
论文:Answering Complex Open-domain Questions Through Iterative Query Generation
代码:https://github.com/qipeng/golden-retriever
任务对于目前的单跳检索和阅读问题回答系统来说,问题很少包含关于缺失实体的可检索线索。回答这样的问题需要进行多跳推理,必须收集关于缺失实体(或事实)的信息才能进行进一步的推理。本文提出了GOLDEN(Gold Entity)Retriever,它在阅读上下文和检索更多支持文档之间进行迭代,以回答开放领域的多跳问题。
方法(模型)GOLDEN Retriever不使用不透明和计算代价较高的神经检索模型,而是根据问题和可用的上下文生成自然语言搜索查询,在每一步中,该模型也会使用前几跳推理的IR结果生成新的自然语言查询,并利用现成的信息检索系统来查询缺失的实体或证据来回答原问题,而不是纯粹依靠原问 ...

