
pytorch_pretrained_bert的配置使用
pytorch_pretrained_bert的配置使用pytorch_pretrained_bert
https://github.com/huggingface/transformers
安装加载预训练模型和权重的包:pip install pytorch-pretrained-bert
修改源码
从亚马逊站点下载非常慢,可以将源码中的地址更换为本地文件。
pytorch_pretrained_bert/modeling.py的 40-51行
pytorch_pretrained_bert/tokenization.py的30-41行
Linux(Ubuntu)安装配置
Linux(Ubuntu)安装配置安装分区
挂载点
说明
大小
/
主分区
100G
/home
100G
/efi
与其他系统共用即可
200M
挂载分区到/home12sudo fdisk /dev/vdbmount /dev/sda4 /home
开机自动挂载:
12vi /etc/fstab/dev/sda4 /home ext4 defaults 0 0
验证:
1df -h
配置
安装win10双系统会导致时间差问题
1timedatectl set-local-rtc true
更换镜像源
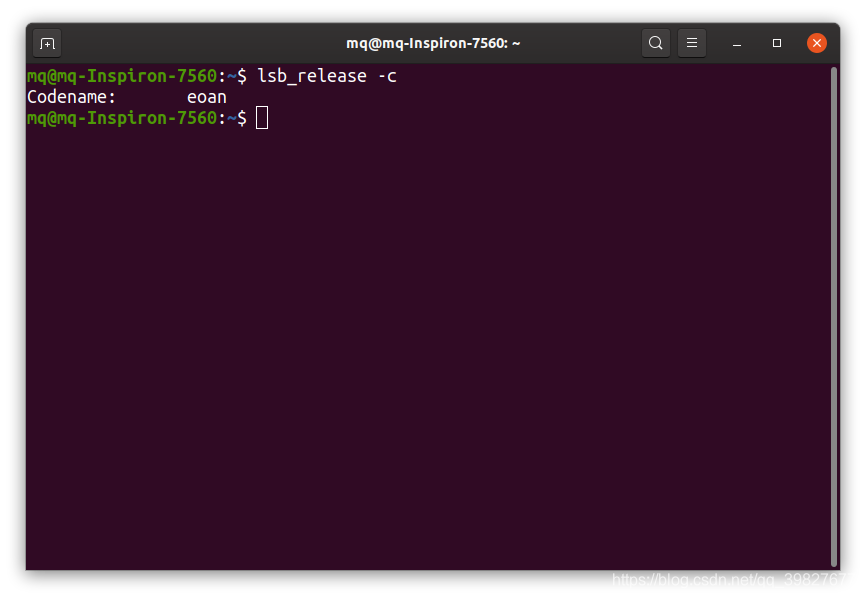
查看系统代号(Ubuntu19.10)lsb_release -c
1.镜像源文件存放在/etc/apt/sources.list下,拷贝一份sources.list文件,以防万一。
1sudo cp -v /etc/apt/sources.list /etc/apt/sources.list.backup
2.使用gedit编辑镜像源文件
1sudo gedit /etc/apt/s ...

智能开关
智能开关演示视频:https://www.bilibili.com/video/BV1qz4y1k7xS/
资料完整教学视频:
第一期:https://www.bilibili.com/video/BV1Ma4y1W7jh/
第二期:https://www.bilibili.com/video/BV1ZK41137YH/
第三期:https://www.bilibili.com/video/BV18Z4y1g7VS/
结构硬件部分 服务器 安卓APP
通信协议:MQTT
清单NodeMCU:ESP8266串口wifi模块 NodeMCU Lua V3物联网开发板 CH340 CP2102(淘宝搜索)舵机:180度电源模块:提供5v,3.3v输出dht11温湿度传感器杜邦线 :公对公 公对母 母对母
esp8266库:https://arduino.esp8266.com/stable/package_esp8266com_index.json
开发工具
Arduino IDE
EMQ X
AndroidStudio
Android APP代码 ...
Is Graph Structure Necessary for Multi-hop Question Answering?
Is Graph Structure Necessary for Multi-hop Question Answering?
论文:EMNLP 2020-Is Graph Structure Necessary for Multi-hop Question Answering
任务探讨多步推理问答任务中是否需要图结构的问题。
验证自注意力或者Transformer可能更加擅长处理多步推理问答任务。
方法(模型)
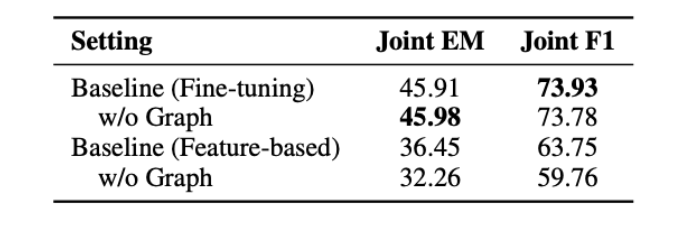
本文的实验使用Distractor设定。
基线模型
使用一个检索模型检出候选段落中的相关段落并输入一个基于图的问答模型,其中图中的所有节点都是由一个额外的NER模型所识别得到的实体构成。
使用一个RoBERTa large模型来计算每个问题与候选段落之间的相关性。
在编码层,将问题和上下文拼接并输入另一个RoBERTa large模型,所得到的输出被输入到一个双向注意力层来得到编码层的输出。
在图融合层(Graph Fusion Block),给定第$t-1$步的上下文表示$C{t-1}$,其中所有token的向量表示都会通过mean-max池化层来得到实体图中的所有节 ...

MemNN
MemNN
Memory Networks:记忆网络
任务传统的RNN和其改进模型虽然具有记忆功能,但是在长期记忆中表现并不好,Memory Networks的目的是实现长期记忆。
方法(模型)MEMORY NETWORKS组成:1个内存模块(m—用索引的数组),4个组件(I,G,O,R—通过学习得到)
组件
$I$:(输入特征映射)—— 将输入转换为内部特征表示。
$G$:(泛化)—— 对于给定新的输入更新旧的内存。称之为泛化是因为在这个阶段网络有机会压缩并泛化其内存以供未来某些需要。
$O$:(输出特征映射)—— 给定新的输入与当前的内存状态,产生新的输出(在特征空间中)。
$R$:(回复)—— 将输出转换为特定格式的回复。比如,文本回复或者一个动作。
流程
输入$x$(可以是单词,句子,图片,音频)
将$x$转为内部特征表示:$I(x)$
更新内存$m_i$:$m_i= G(m_i, I(x), m), ∀i$
计算输出特征:$o = O(I(x), m)$
将输出特征解码,得到最终回复:$r = R(o)$
实现
$G$:最简单的实现是利用下述$H(x$)将输入$I( ...
emqx配置https并使用nginx反向代理
emqx配置https并使用nginx反向代理
下载域名证书,找到.crt或.key,编辑器打开,复制秘钥文本,找在线转pem工具,生成.pem文件。
ssl证书从DNSpod下载 https://console.cloud.tencent.com/cns/detail/dengemo.com/records/0
在线转pem:https://www.myssl.cn/tools/merge-pem-cert.html
选择PEM文件包括证书(CRT/CER)
下载的证书如图:
腾讯云已经有pem,crt,key,因此可以不用转pem
如果下载的证书没有pem,使用在线工具进行转换
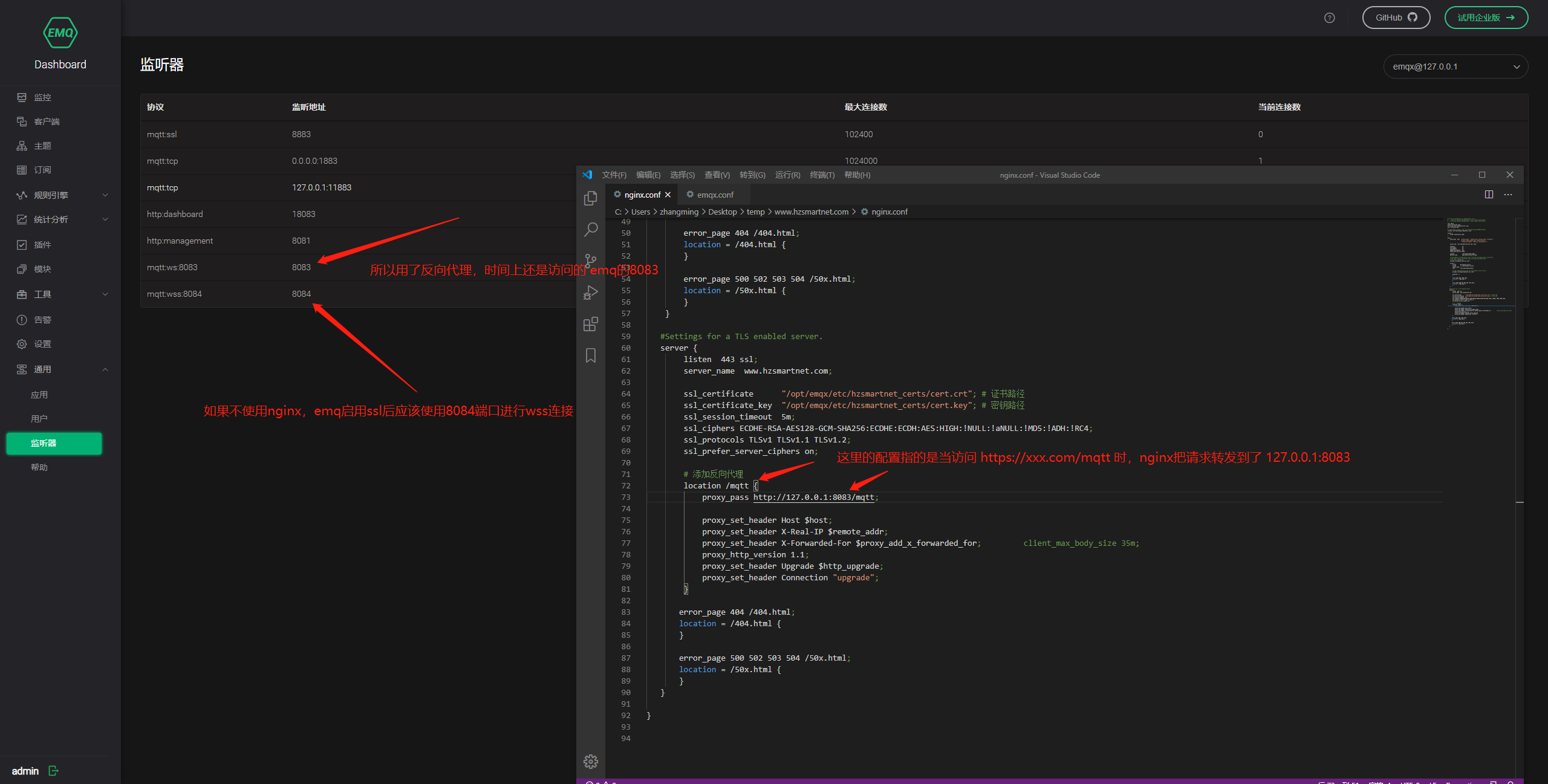
在emq中启动ssl
whereis emqx 可查看安装路径
修改emqx.conf如下部分
123listener.wss.external = 8084listener.wss.external.keyfile = /root/cert/key.pemlistener.wss.external.certfile = /root/cert/dengemo.com_bu ...
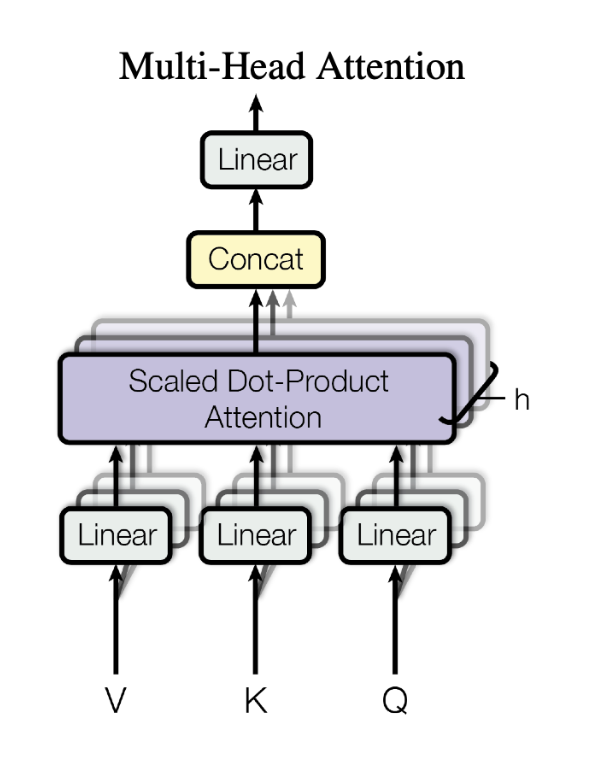
Attention Is All You Need
Attention Is All You Need
应用于NLP的机器翻译问题。
任务
由于RNN的递归结构,导致它无法并行计算,RNN以及他的衍生模型最大的缺点就是计算缓慢。并且缺乏对全局信息的理解。因此提出了完全基于attention的Transformer模型。
方法(模型)Transformer模型是纯attention模型,完全依赖attention机制来描述输入与输出的全局依赖。
模型:
输入:$x=(x1,x2,⋯,xn)$(是一个离散的符号序列)
encoder:将它映射成连续值序,$z=(z1,z2,⋯,zn)$
decoder:对于给定的$z$,生成一个输出符号序列,$y=(y1,y2,⋯,ym)$
优化器:Adam
使用dropout和Label Smoothing防止过拟合
Encoder and Decoder Stacks
Encoder与Decoder堆叠
Encoder
Transformer模型的Encoder由6个基本层堆叠起来,每个基本层包含两个子层。
第一个子层:注意力机制
第二个子层:全连接前向神经网络。
对两个子层都采用了resid ...
常见报错汇总
常见报错汇总PyTorch报错:
1RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False. If you are running on a CPU-only machine, please use torch.load with map_location=torch.device('cpu') to map your storages to the CPU.
解决:
1torch.load(xxx)改成 torch.load(xxx,map_location='cpu')
TensorFlow报错:
1tensorflow2.0加载model出现AttributeError: ‘str‘ object has no attribute ‘decode‘
解决:
12345把h5py降到2.10.0版本就行了!!!!安装keras自动给下载高版本h5py导致报错!!pip install h5py= ...

机器学习基础
机器学习基础1. 机器学习的基本内容
监督学习
无监督学习
半监督学习
强化学习
2. 常用的正则化方法
正则化是解决过拟合的常用方法。
正则化是什么呢?
在机器学习中很多显式的用来减少测试误差的策略,统称为正则化。
正则化的目的是减少泛化误差而不是训练误差。
2.1权重正则化
L2正则化称为:权重衰减(Weight Deacy)
min_\theta\frac{1}{2m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})^2+\lambda||W||^2
$\lambda$:权值衰减率
2.2 Dropout 正则化
训练过程中按一定的比例,随机忽略或屏蔽一些神经元。
被随机忽略或屏蔽的神经元在反向传播中也不会有任何的权值更新,在传播过程中产生于L2范数相同的收缩权重效果。
加入Dropout之后,输入特征也会随机清除,所以不会给任何一个输入设置太大的权重。
由于网络模型对神经元特定的权重不那么敏感,反而会增加模型的泛化能力。
通常Dropout的丢弃率控制在20%-50%。
太低起不到效果,太高会导致欠拟合。
在较大 ...
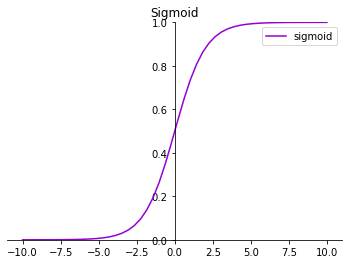
常用激活函数
常用激活函数1234import matplotlib.pyplot as pltimport numpy as npx = np.linspace(-10, 10)fig = plt.figure()
1. sigmoid12345678910111213141516171819y_sigmoid = 1/(1+np.exp(-x))ax = fig.add_subplot(221)plt.xlim(-11, 11)plt.ylim(0, 1)ax = plt.gca() # 获得当前axis坐标轴对象ax.spines['right'].set_color('none') # 去除右边界线ax.spines['top'].set_color('none') # 去除上边界线# 指定data 设置的bottom(也就是指定的x轴)绑定到y轴的0这个点上ax.spines['bottom'].set_position(('data', 0))ax.spines[ ...
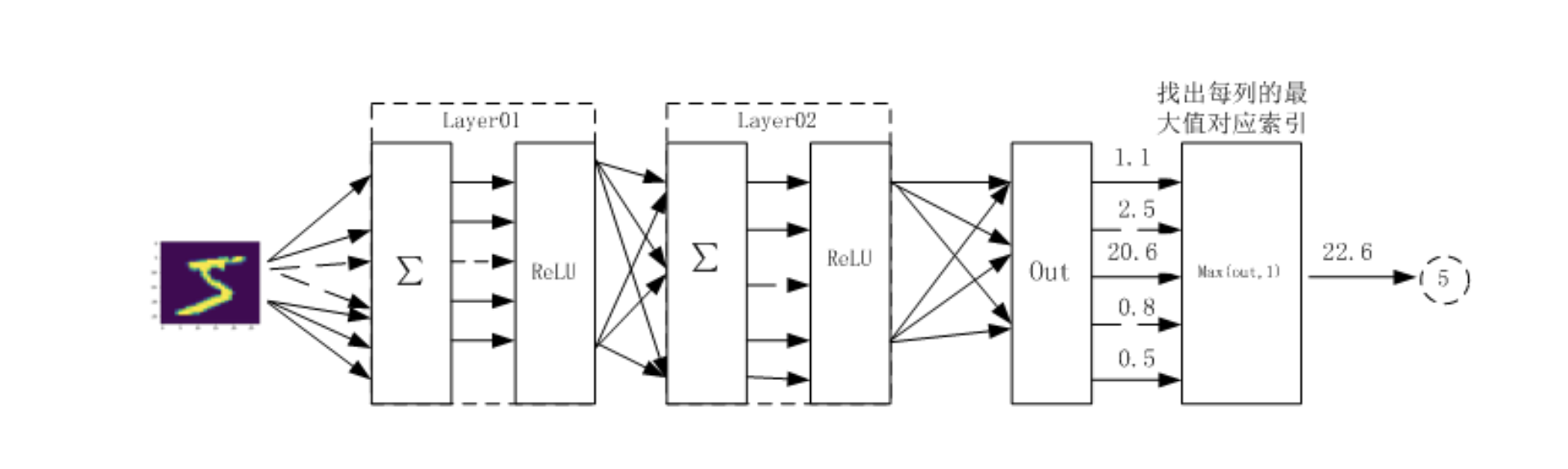
利用神经网络完成对手写数字进行识别
利用神经网络完成对手写数字进行识别
网络结构
两个隐藏层每层激活函数为Relu数据集:mnist
1. 准备数据12345678910111213import osimport numpy as npimport matplotlib.pyplot as pltimport torch# 导入 pytorch 内置的 mnist 数据from torchvision.datasets import mnist# 导入预处理模块import torchvision.transforms as transformsfrom torch.utils.data import DataLoader# 导入nn及优化器import torch.nn.functional as Fimport torch.optim as optimfrom torch import nn
2. 定义一些超参数1234567# 定义一些超参数train_batch_size = 64test_batch_size = 128learning_rate = 0.01num_epoches = 20lr = ...

使用Tensor及Autograd实现机器学习
使用Tensor及Autograd实现机器学习表达式:$y=3x^2+2$
模型:$y=wx^2+b$
损失函数:$Loss=\frac{1}{2}\sum_{i=1}^{100}(wx^2_i+b-y_i)^2$
对损失函数求导:$\frac{\partial Loss}{\partial w}=\sum_{i=1}^{100}(wx^2_i+b-y_i)^2x^2_i$
$\frac{\partial Loss}{\partial b}=\sum_{i=1}^{100}(wx^2_i+b-y_i)^2$
利用梯度下降法学习参数,学习率为:lr
$w_1-=lr*\frac{\partial Loss}{\partial w}$
$b_1-=lr*\frac{\partial Loss}{\partial b}$
1.生成训练数据12import torchfrom matplotlib import pyplot as plt
1234567891011torch.manual_seed(100)dtype = torch.float# 生成x坐标数据,x为tensor,转成100 ...
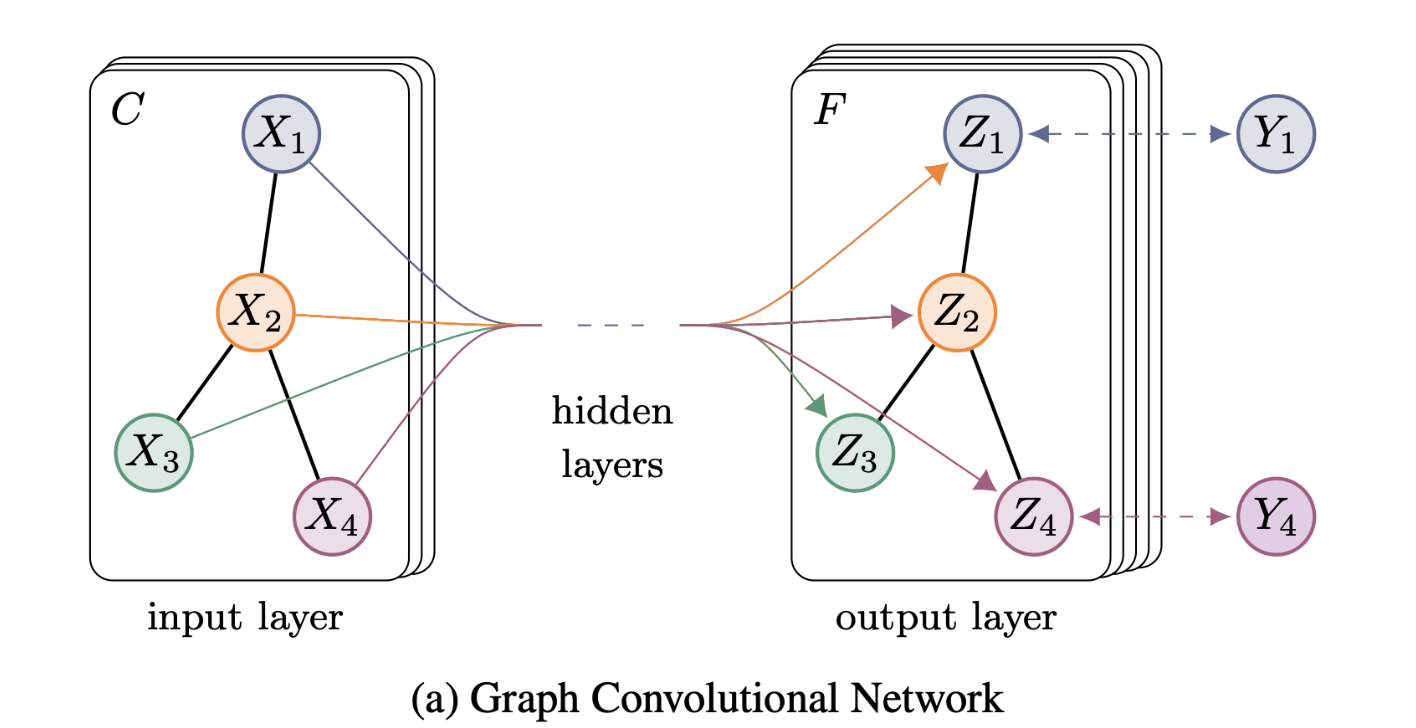
GCN
GCN
GCN:图卷积网络
SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS:基于图卷积网络的半监督分类
任务
在图结构数据中,一部节点已知标签,剩下的节点标签未知,使用已知标签的节点训练卷积神经网络,使用网络模型对无标签的节点进行分类。
方法(模型)
提出了一种可扩展的基于图结构数据的半监督分类方法。
分层传播规则:通过谱图卷积(spectral graph convolutions) 的局部一阶近似,来确定卷积网络结构。
$f(X,A)$
使用神经网络$f(X,A)$对图的结构进行编码,对所有带标签的节点进行有监督训练。
避免显式地对基于图的损失函数进行正则化计算
在图的邻接矩阵上调节$f (⋅)$ ,允许模型从监督损失$\mathcal{L}_{0}$中分开梯度信息,使其能够学习所有节点的表示。
X:输入数据
A:图邻接矩阵
FAST APPROXIMATE CONVOLUTIONS ON GRAPHS
图卷积的前向传播公式:
H^{(l+1)}=σ(\tilde D^{\fr ...
Linux安装nodejs&升级
Linux安装nodejs&升级安装
命令窗口
yum install nodejs
官网(推荐)
官网:https://nodes.org/en/
a. 下载后解压:
1tar -xvf node.tar.xz
b. 创建软连接全局访问:
可执行文件位于/bin目录下
12ln -s 当前路径/npm /usr/bin/npmln -s 当前路径/node /usr/bin/node
c. 测试
12node -vnpm -v
升级npm install n -g
安装稳定版
n stable
验证node -v
npm -v

