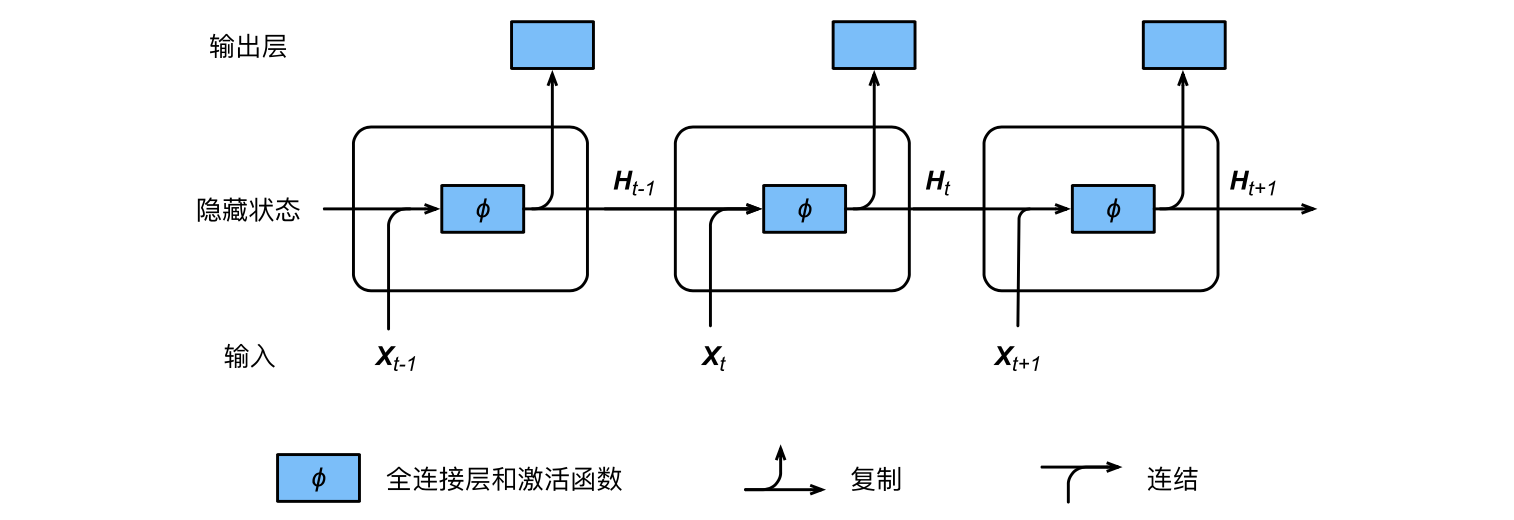
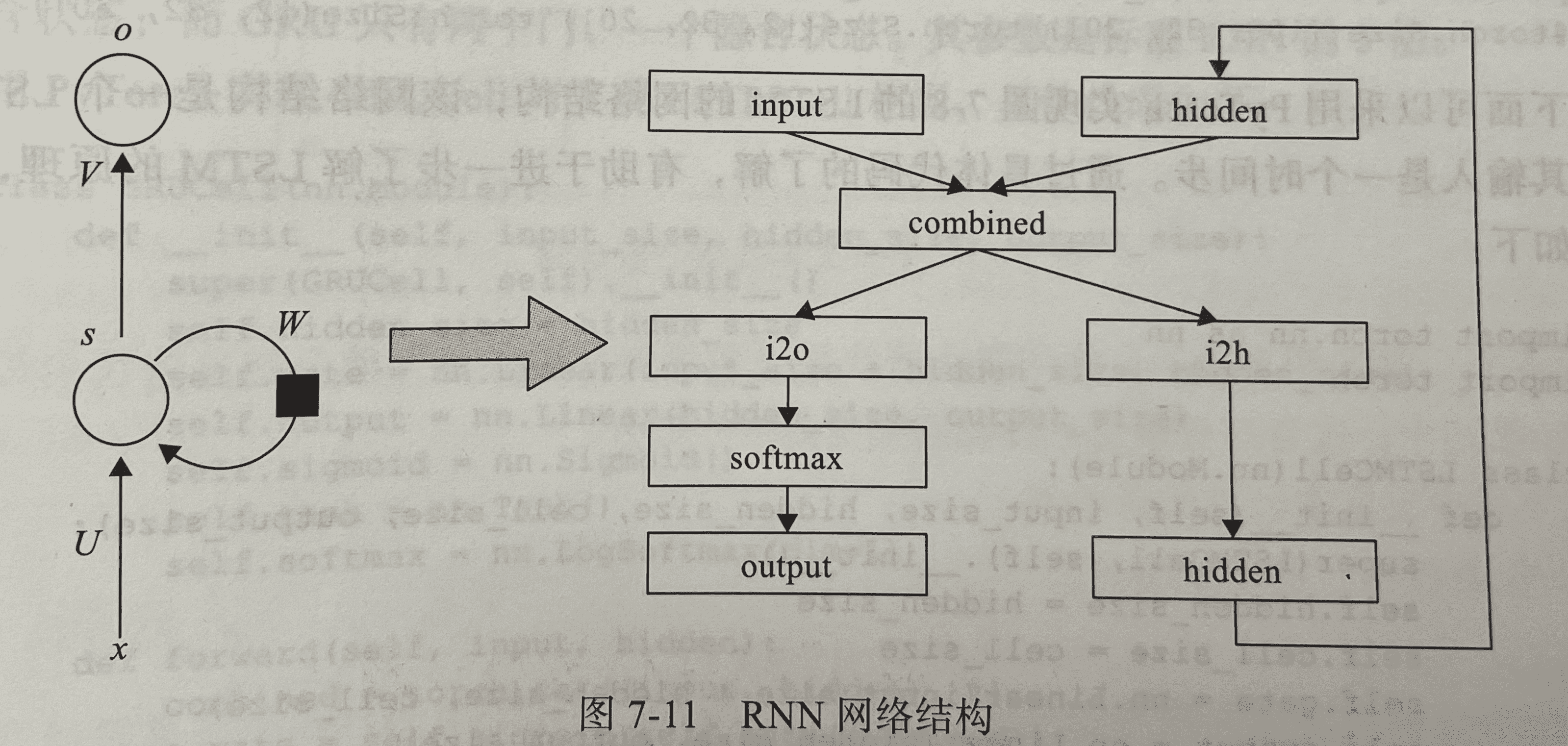
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
| # 以cell方式实现RNN
# %%
import os
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, losses, optimizers, Sequential
# 指定GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
tf.random.set_seed(22)
np.random.seed(22)
# 避免输出无关调试信息
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
batch_size = 128 # 批量大小
total_words = 10000 # 词汇表大小N_vocab
max_review_len = 80 # 句子最大长度s,大于的句子部分将截断,小于的将填充
embedding_len = 100 # 词向量特征长度f
# 加载IMDB数据集,此处的数据采用数字编码,一个数字代表一个单词
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
print('dataset shape')
print(x_train.shape, len(x_train[0]), y_train.shape)
print(x_test.shape, len(x_test[0]), y_test.shape)
# %%
print('dataset x_train[0]: ', x_train[0])
# %%
# 数字编码表
word_index = keras.datasets.imdb.get_word_index()
# for k,v in word_index.items():
# print(k,v)
# %%
# 调整特殊词汇位置
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # unknown
word_index["<UNUSED>"] = 3
# 翻转编码表
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
# dict.get(key, default=None)
# default -- 如果指定键的值不存在时,返回该默认值。
return ' '.join([reverse_word_index.get(i, '?') for i in text])
# 编码-->句子
print(decode_review(x_train[8]))
# %%
# x_train:[b, 80]
# x_test: [b, 80]
# 截断和填充句子,使得等长,此处长句子保留句子后面的部分,短句子在前面填充
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
# 构建数据集,打散,批量,并丢掉最后一个不够batch_size的batch
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batch_size, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batch_size, drop_remainder=True)
print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print('x_test shape:', x_test.shape)
# %%
class MyRNN(keras.Model):
# Cell方式构建多层网络
def __init__(self, units):
# units [b, 64]
super(MyRNN, self).__init__()
# [b, 64],构建Cell初始化状态向量,重复使用
self.state0 = [tf.zeros([batch_size, units])]
self.state1 = [tf.zeros([batch_size, units])]
# 词向量编码 [b, 80] => [b, 80, 100]
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# 构建2个Cell
self.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.5)
self.rnn_cell1 = layers.SimpleRNNCell(units, dropout=0.5)
# 构建分类网络,用于将CELL的输出特征进行分类,2分类
# [b, 80, 100] => [b, 64] => [b, 1]
self.out_layer = Sequential([
layers.Dense(units),
layers.Dropout(rate=0.5),
layers.ReLU(),
layers.Dense(1)])
def call(self, inputs, training=None, mask=None):
# 测试阶段 training=false
x = inputs # [b, 80]
# embedding: [b, 80] => [b, 80, 100]
x = self.embedding(x)
# rnn cell compute,[b, 80, 100] => [b, 64]
# 初始化隐藏层状态
state0 = self.state0
state1 = self.state1
out1 = None
for word in tf.unstack(x, axis=1): # word: [b, 100]
out0, state0 = self.rnn_cell0(word, state0, training)
# 第二层的输入为第一层的输出
out1, state1 = self.rnn_cell1(out0, state1, training)
# 末层最后一个输出作为分类网络的输入: [b, 64] => [b, 1]
x = self.out_layer(out1, training)
# p(y is pos|x)
prob = tf.sigmoid(x)
return prob
def main():
units = 64 # RNN状态向量长度f
epochs = 50 # 训练epochs
model = MyRNN(units)
# 装配
model.compile(optimizer=optimizers.RMSprop(learning_rate=1e-3),
loss=losses.BinaryCrossentropy(),
metrics=['accuracy'])
# 训练和验证
model.fit(db_train, epochs=epochs, validation_data=db_test)
# 测试
model.evaluate(db_test)
if __name__ == '__main__':
main()
|