Zero-Resource Knowledge-Grounded Dialogue Generation
Zero-Resource Knowledge-Grounded Dialogue Generation
任务
神经网络对话模型需要以知识为基础的对话,而这些对话很难获得。为了克服数据方面的挑战并降低构建知识基础对话系统的成本,本文通过假设训练时不需要context-knowledge-response三要素,在零资源环境下探索这个问题。
贡献:
- 在零资源环境下探索以知识为基础的对话生成;
- 提出了一个double latent variable model,不仅描述了连接context和response的知识,还描述了知识的表达方式;
- 提出了一个variational学习方法;
- 在知识为基础的对话生成的三个基准上对所提方法的有效性进行了经验验证。
方法(模型)
本文提出将连接context 和response的知识以及知识的表达方式表现为潜在变量,并设计了一种variational方法,可以有效地从对话语料和知识语料中估计出一个相互独立的生成模型。
在预训练的语言模型的基础上建立概率模型。不使用生成模型,而是建议用一个检索模型来实例化后验,在这个模型中,知识的搜索空间被限制在几个相关的候选之内。
dialogue corpus:
$C_i$指的是dialogue context
$R_i$指的是response
knowledge base:
$K_j$指的是一段知识,例如数据集中的句子。
模型:
与外部知识关联的K和新的上下文C,根据$p(R∣C, K)$生成响应R。
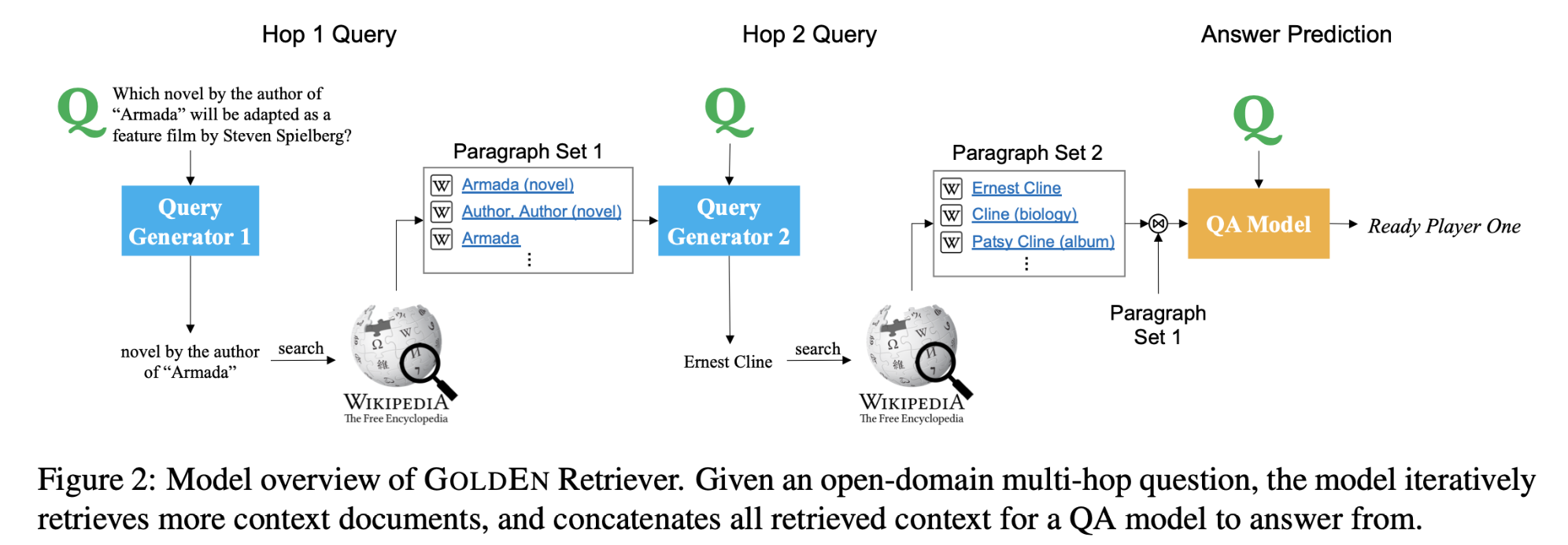
Zero-Resource Learning Framework
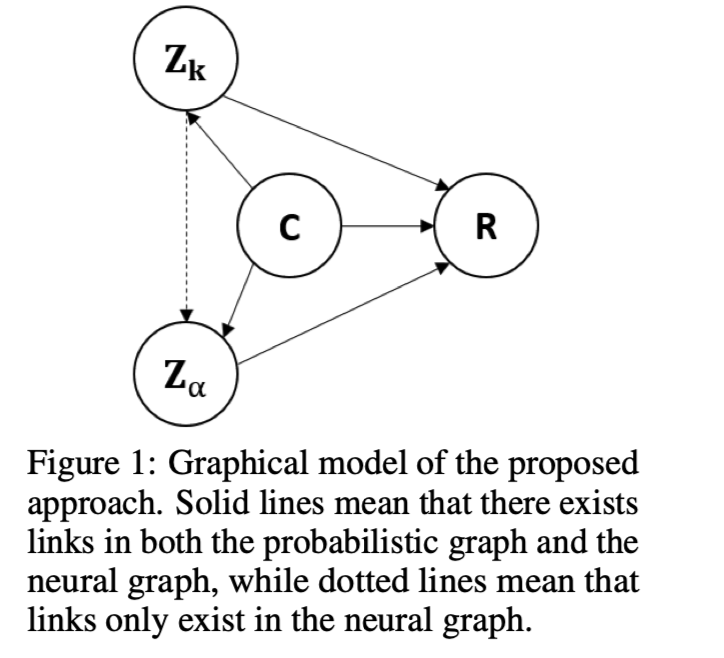
dialogue context C
response R
latent knowledge $Z_k$
grounding rate $Z_α$,表示根据C关于R在$Z_k$中携带了多少知识。
Neural Parameterization
define $q(Z_k)$ with a retrieval model:
S(R)表示对潜在知识的推断,该知识由相关性模型rel(⋅, ⋅)从$K_{kg}$中通过R查询检索到的前l个结果组成。
$F(⋅,⋅,⋅)$是一个三层transformer,将(c,r,$z_k$)映射到匹配分数。
优化算法:

数据集
- Wizard
- TC
- CMU_DoG
性能水平
测试结果:

F1:虽然ZRKGC在基准中没有获取任何训练实例,但它仍然优于MTASK-RF、TMN和ITDD,并在所有测试集上取得了与DRD相当的性能,表明该模型能够有效地学习如何通过variational方法利用外部知识来生成响应。
ZRKGC在Test Seen和Test Unseen上几乎没有差异,该模型不受特定训练数据的影响,因此在不同主题上表现稳定,这揭示了该模型良好的泛化能力是零资源方法的优势。
结论
对三个以知识为基础的对话生成基准的评估结果表明,本文的模型可以达到与依靠以知识为基础的对话进行训练的先进方法相当的性能,并在不同的主题和不同的数据集上表现出良好的泛化能力。