Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension
Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension
任务
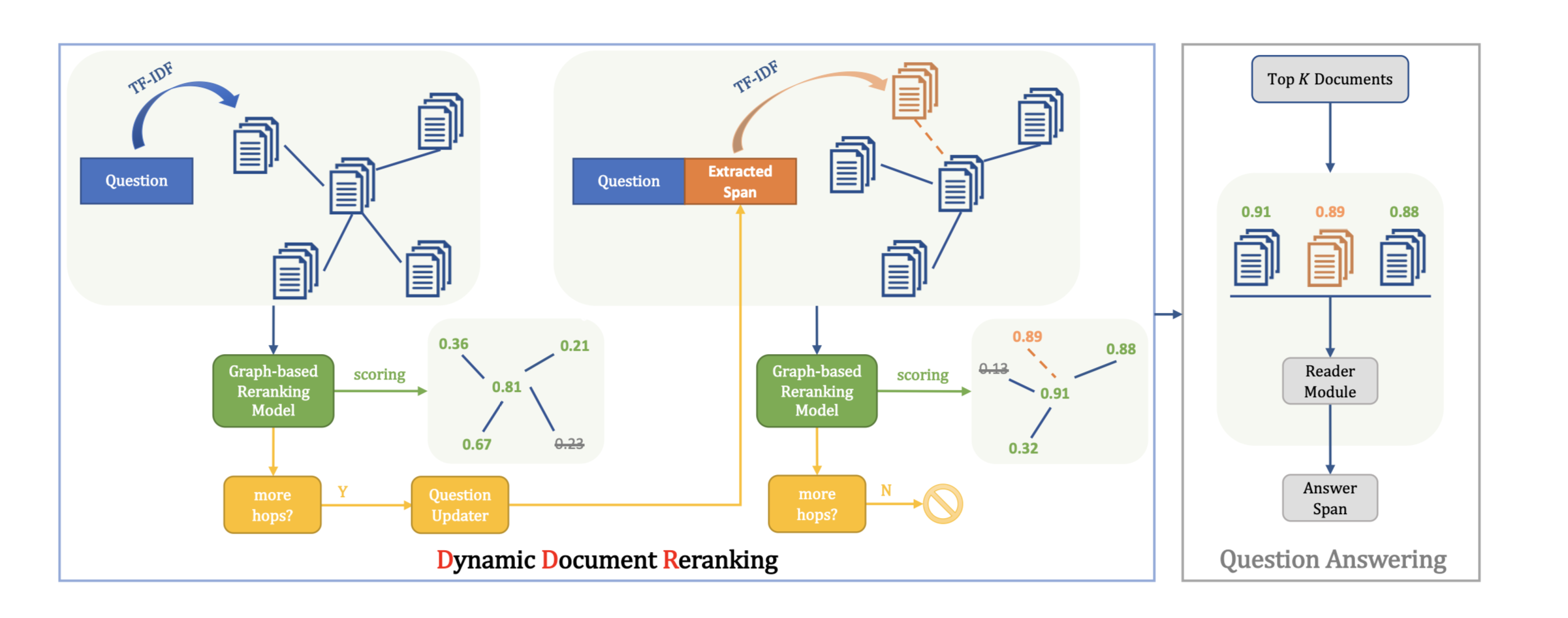
传统的基于transformer的模型只能接受固定长度(如512)的文本作为其输入。为了处理更长的文本输入,以前的方法通常将它们分割成等距的片段,并根据每个片段独立预测答案,而不考虑其他片段的信息。因此,可能会形成不能覆盖正确答案跨度的片段,或在其周围保留不充分的上下文,大大降低性能。此外,回答需要跨段信息的问题的能力较差。本文提出recurrent chunking机制(RCM)提升长文本机器阅读理解的性能,以防止答案跨度过于接近段的边界和覆盖不完整的答案。
方法(模型)
通过强化学习,让模型以更灵活的方式学习分块:模型可以决定它要处理的下一个片段的方向。还采用了递归机制,使信息能够跨段流动。
传统方法:
首先将输入的文本分成等距的片段,然后预测每个单独片段的答案,最后将多个片段的答案集合在一起。
- 传统方法缺陷
- 预先确定的大跨度的分块可能会导致答案不完整,并且当答案在段的边界附近时,与答案在段的中心,周围有更丰富的上下文时相比,模型更容易失败。
- 根据经验观察到,较小跨度的分块对模型性能的贡献很小(有时甚至伤害了)。
recurrent chunking mechanisms (RCM)
模型结构:
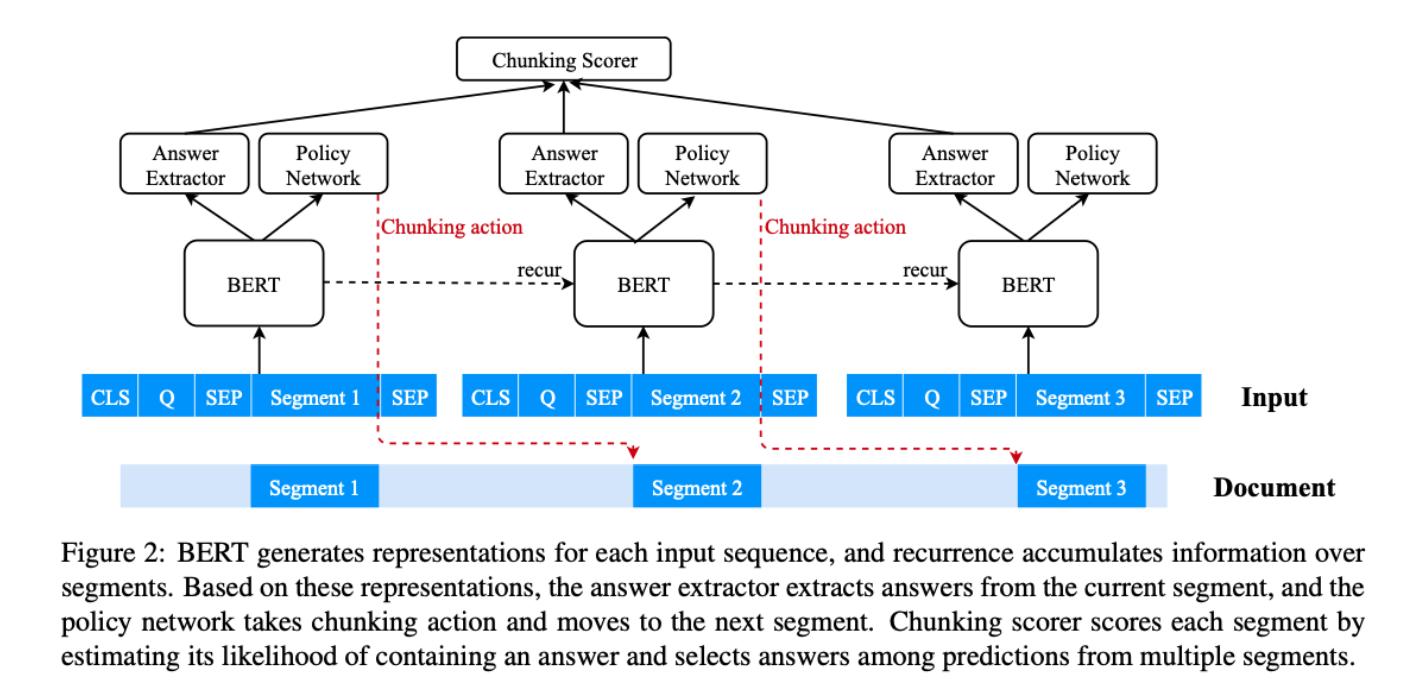
- 特征
- 可以让meachine reader通过强化学习来学习如何在阅读冗长的文件时智能地选择步幅大小,有助于防止从片段中提取不完整的答案,并在答案周围保留足够的语境
- 应用递归机制,让信息在各段之间流动。该模型可以访问当前片段以外的全局上下文信息。
使用BERT生成向量表示,使用max pooling实现答案融合。
基线模型对每个文档段进行独立的答案预测,由于缺乏文档级别的信息,可能会导致不同段的答案得分无法比较。本文使用一个递归层来传播不同片段的信息,并使用分块评分器模型(chunking scorer model)来估计一个片段包含答案的概率。
两个递归机制:
- gated recurrence
- Long Short Term Memory (LSTM)
数据集
CoQA
QuAC
- TriviaQA
性能水平&结论
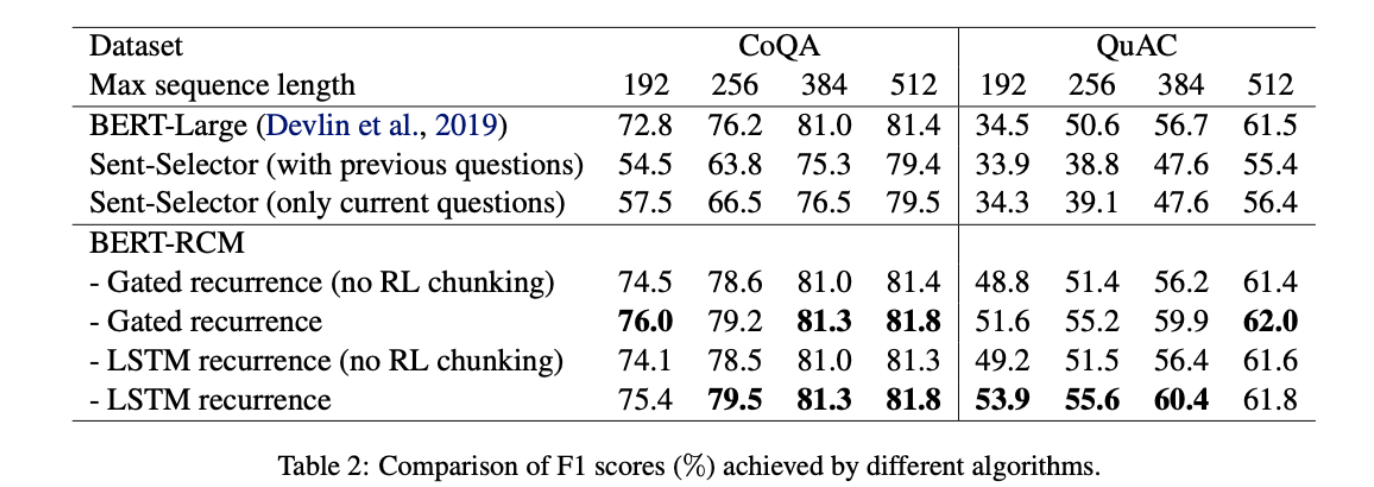
BERT-Large模型的性能随着最大序列长度的减小,性能急剧下降。当最大输入长度从512下降到192时,CoQA数据集的F1分数下降了8.6%,QuAC数据集的F1分数下降了27.0%。
具有recurrent机制的BERT-RCM性能优于BERT-Large和BERT-Sent-Selector。
RCM模型对最大序列长度不太敏感,而LSTM的性能与gated recurrence性能接近。
不同stride size的性能比较:

过小的stride size不会提升模型准确率反而会降低模型性能。
效果展示:

在三个MRC数据集CoQA、QuAC和TriviaQA上的实验证明了本文提出的递归分块机制的有效性,可以获得更有可能包含完整答案的片段,同时为更好的预测提供围绕真实答案的足够上下文。