
Dynamic Sampling Strategies for Multi-Task Reading Comprehension.md
Dynamic Sampling Strategies for Multi-Task Reading Comprehension
任务
根据多任务模型在数据集上的当前表现与单任务表现的比例来选择训练实例,比较哪种实例抽样方法和历时调度策略能提供最佳性能。
catastrophic forgetting:在一个不平衡的训练集中,当训练从该数据集开始时,特定数据集的性能会急剧下降。
多任务训练的两个基本方面:
- how many instances are sampled from each task per epoch
- how those instances are organized within the epoch
方法(模型)
本文引入了一种动态抽样策略,从数据集中选择实例,其概率与当前某些指标(如EM或F1得分)的性能和同一模型在该数据集中的单任务性能之间的差距成正比。
Sampling and Scheduling Strategies
本文探讨了多任务学习中实例排序的两个主要方面:
- 从每个数据集中进行实例抽样,以获得用于一个周期的实例集合
- 在周期内对这些实例进行调度,确定它们应该如何排序和分批。
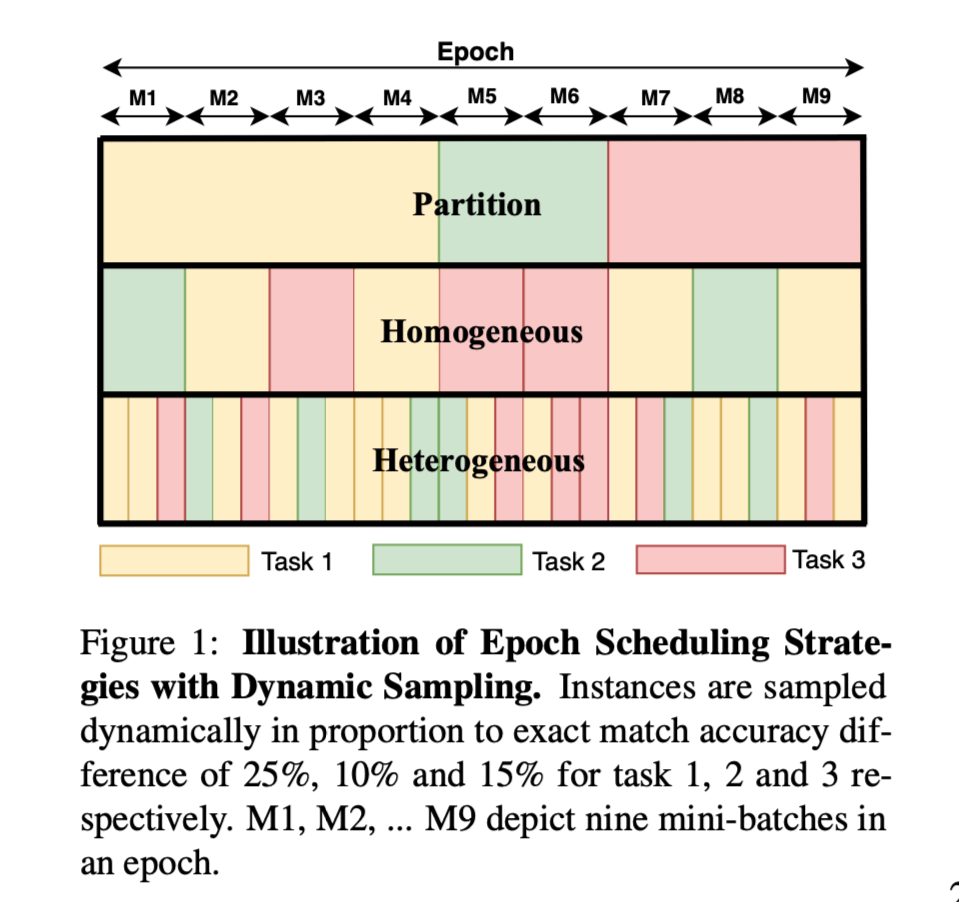
四个抽样方法:
Uniform,By Size,Uniform→Size,Dynamic
Dynamic:首先计算正在训练的模型的单任务验证指标。对于每个任务,计算当前的多任务性能和相应的单任务性能之间的差距,并将这些指标的差异归一化,以创建一个概率分布。然后,对于第一个epoch之后的每一个epoch,从这个分布中按任务取样。如果一个数据集的性能与单任务性能相差甚远,它将被大量抽样,而达到或超过单任务性能的数据集将被少量抽样。
修改用于计算差值的指标的方法,最终决定使用EM+F1差分,性能比EM或F1差分更好,并且明显比损失差分的性能好。
Epoch Scheduling:
- Partitioned:该调度策略按任务划分epoch中的实例。
- Homogeneous Batches:这种调度策略并不强迫实例基于数据集的分区。相反,每个数据集的实例都被分到一起,然后对分批的实例进行打乱。
- Heterogeneous Batches:这种调度策略对所有选定的实例打乱,然后将它们分批进行。每个批次可能有来自许多不同数据集的实例。
- Uniform Batches:这种方法在每个批次中为每个数据集放置一个实例,直到最小的数据集的实例用完。这种策略在其余的数据集上继续进行,直到所有数据集都用完。
数据集
小型数据集:
Quoref,ROPES
中型数据集:
DuoRC,NarrativeQA
大型数据集:
DROP,NewsQA,SQuAD1.1,SQuAD2.0
性能水平
动态抽样,根据各自的度量差对每个任务的实例进行抽样,可以提高性能。在每个epoch内将不同任务的实例交错在一起,形成异质的批次,对于优化多任务性能至关重要。最终模型与其他的多任务阅读理解在ORB基准上的模型性能有很大的提高。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 没有胡子的猫Asimok!
相关推荐




评论

