Reinforced Multi-task Approach for Multi-hop Question Generation
Reinforced Multi-task Approach for Multi-hop Question Generation
任务
问题生成试图解决问题回答的逆向问题,通过给定一个文件和一个答案来生成一个自然语言问题。本文旨在使用多个支持性事实来生成高质量的问题。
方法(模型)
采用了多跳问题生成,根据上下文中的支持事实生成相关问题。采用了多任务学习的方式,并辅以answer-aware支持性事实预测的任务来指导问题生成器。
问题生成示例:

处理多跳问题生成的两个阶段:
在第一阶段,学习支持性事实意aware的编码器表示,通过与问题生成的联合训练来预测文档中的支持性事实,随后增强这些支持性事实的利用。
后者的目标被表述为一个问题意识到的支持性事实预测奖励,它与监督序列损失一起被优化。此外,我们观察到多任务框架为问题生成的性能提供了实质性的改进,也避免了在生成的问题中包含噪声句子信息,而强化学习(RL)将完整和复杂的问题带到其他最大似然估计(MLE)优化的QG模型中。
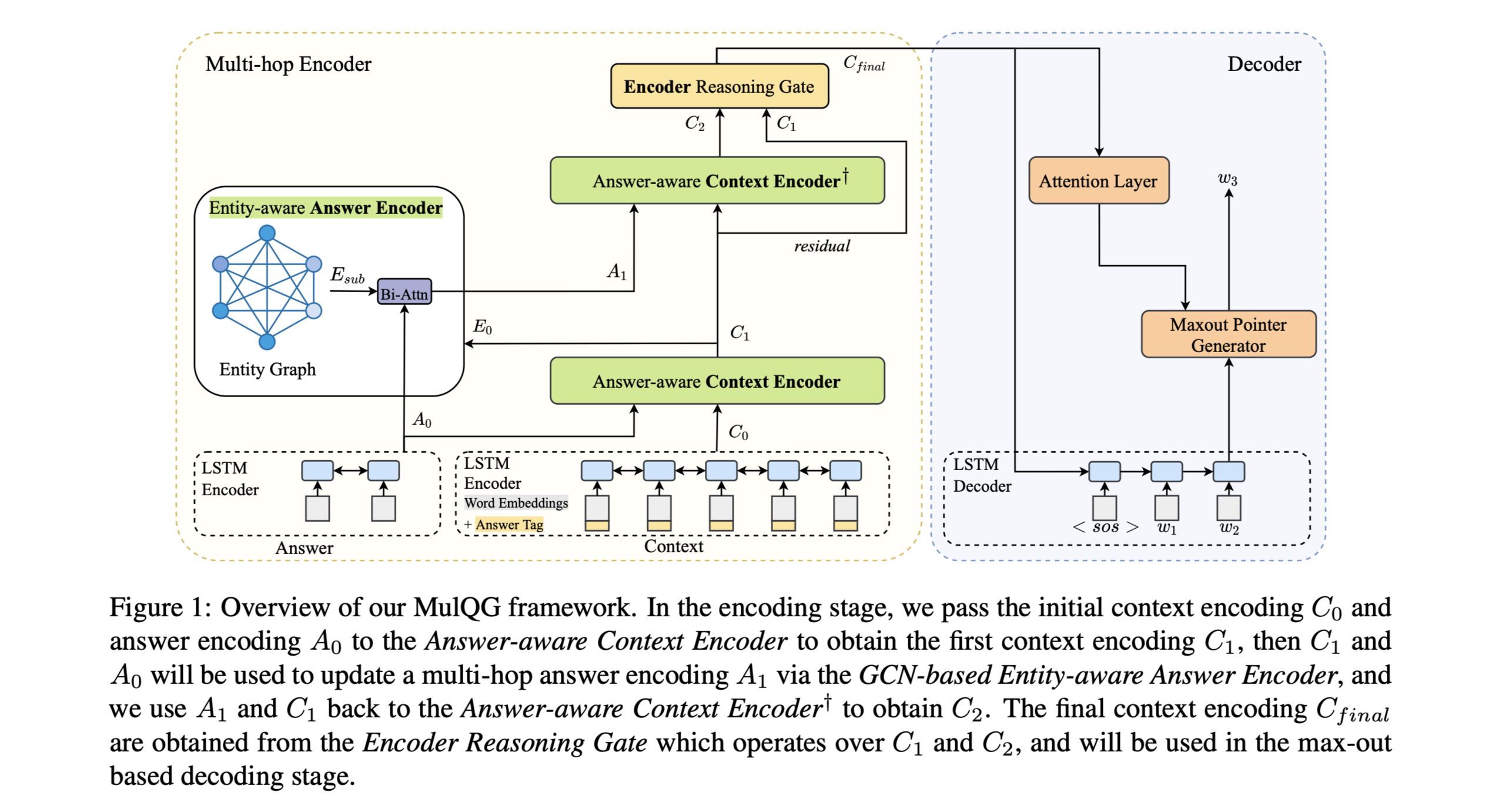
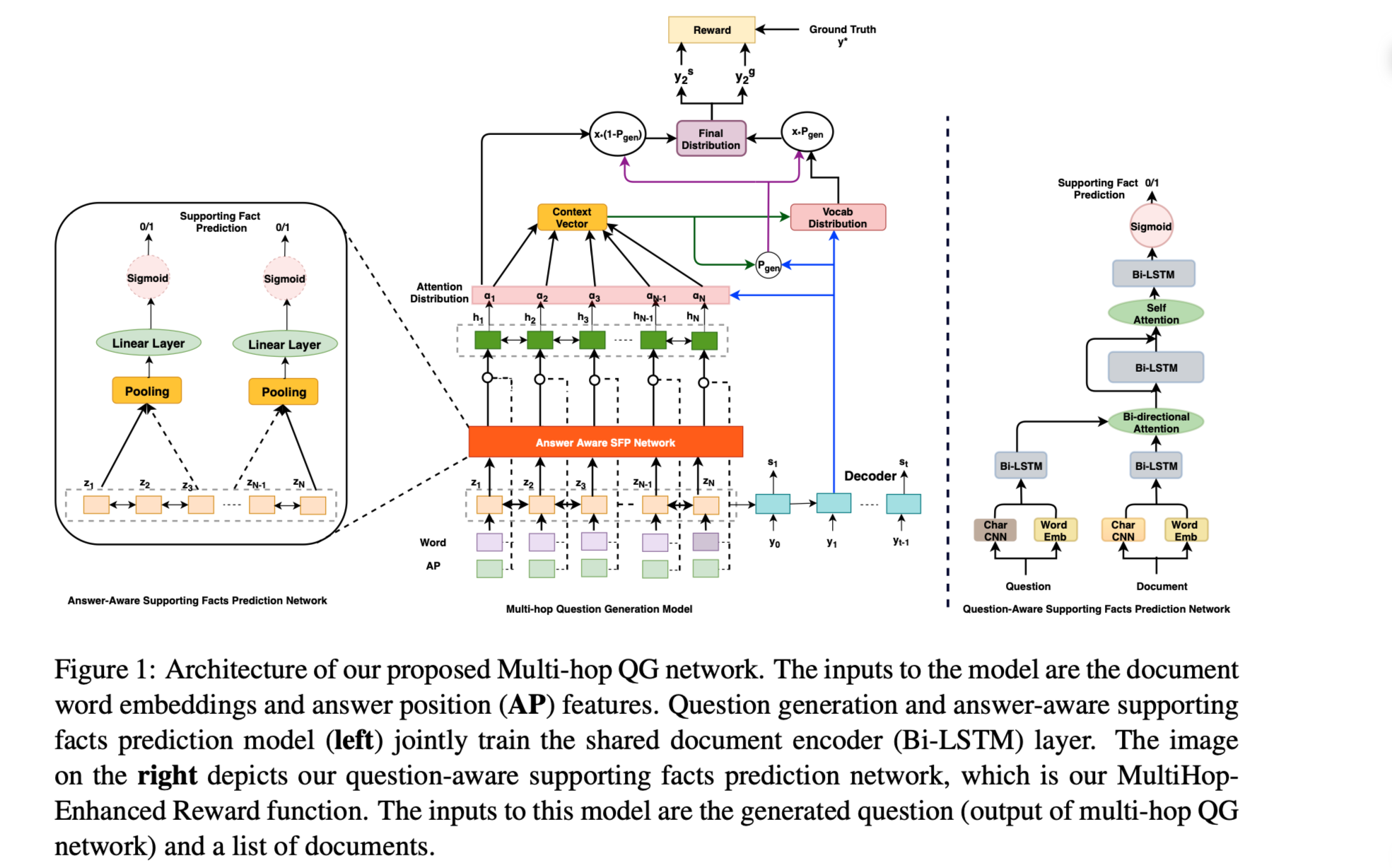
Multi-Hop Question Generation Model
组件:
Document and Answer Encoder
编码文档集并回答以进一步生成问题。
使用Bi-LSTM网络。
Multi-task Learning
方便QG模型自动选择支持事实以产生问题。
Question Decoder
使用pointer-generator机制生成问题。
MultiHop-Enhanced QG
最大限度地提高基于奖励的支持事实预测。
Question-Aware Supporting Fact Prediction 网络用来预测每个候选句子的支持事实概率。
使用binary cross-entropy损失函数。
模型结构:
数据集
- HotPotQA
性能水平&结论
- 性能比较:

在HotpotQA测试集上,本文提出的模型在BLEU评测指标上都取得了最优的性能。在支持事实覆盖(SF coverage)的多跳问题推理中也取得了最优的效果。
- 消融实验:

使用共享编码器提供多任务学习有助于模型 在BLEU-4评测下提高QG性能。
从答案感知支持事实预测任务中获得的支持事实信息进一步提高BLEU-4的QG性能。
通过在两个任务之间共享文档编码器,网络对输入文档可以更好的进行编码。 能够在处理多个文档时有效地过滤不相关的信息并对问题生成进行多跳推理。
- 结论
通过在多跳问题回答数据集HotPotQA上的实验,证明了本文方法的有效性。经验评估表明,本文的模型在自动评估指标(如BLEU、METEOR和ROUGE)和人工评估指标(如生成问题的质量和覆盖率)方面都优于单跳神经问题生成模型。