Multi-Hop Paragraph Retrieval for Open-Domain Question Answering
Multi-Hop Paragraph Retrieval for Open-Domain Question Answering
任务
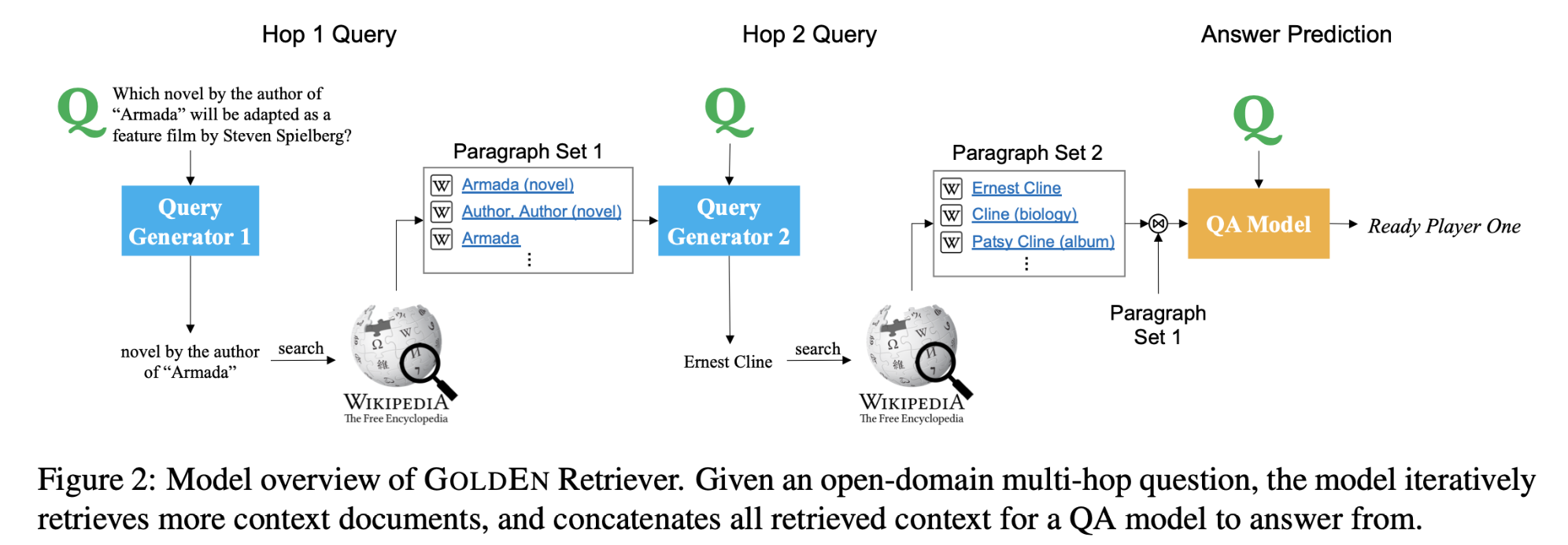
多跳开放域问题回答(QA)任务,需要同时进行文本推理和高效搜索。本文提出了一种检索多个支持段落的方法,这些段落嵌套在一个庞大的,包含回答一个给定问题的必要证据的知识库中。
方法(模型)
本文提出的方法通过形成一个问题和段落的联合向量表示来反复检索支持性段落。检索是通过考虑知识源中段落的上下文句子层面的表示来进行的。
- 任务定义:
$(KS, Q, A)$
Background knowledge source:$KS = {P1, P_2, . . . , P{|KS|}}$
由$li$ 个tokens组成的文本段落:$P_i = (p_1, p_2, . . . , p{l_i})$
m个tokens组成的段落:$Q = (q_1, q_2, . . . , q_m)$
n个tokens组成的答案:$A = (a_1, a_2, . . . , a_n)$
- 目标:
使用背景知识源KS找到对问题Q的答案A。
$A = φ(Q, KS)$
- 方法:
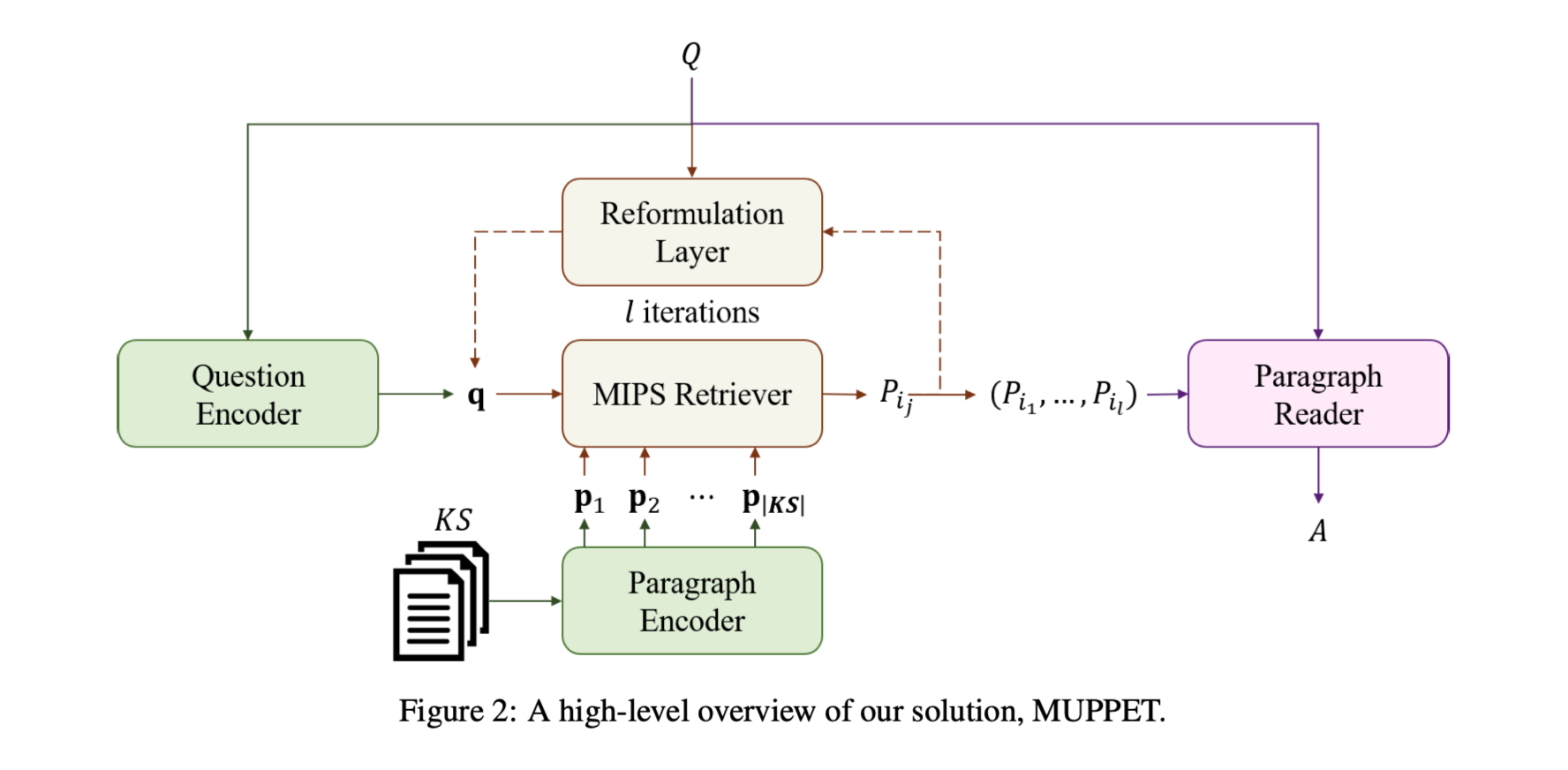
MUPPET (multi-hop paragraph retrieval)
两个组件
paragraph and question encoder
- 段落编码不依赖于问题。
paragraph reader
使用MIPS(maximum inner product search)算法检索最有可能包含答案的段落,然后将的段落传递给阅读器模块,提取问题最有可能的答案。
支持多跳检索:
对于问题$Q$,编码为$q$,转换成搜索空间向量$q^s$,用来检索(使用MIPS算法)top-k相关段落${P^Q 1, P^Q _2, . . . , P^Q k} ⊂ KS$,从检索段落中重构搜索向量,${\tilde q^s 1, \tilde q^s 2, . . . , \tilde q^s_ k}$,再执行一遍检索过程,可检索出下一个top-k相关段落。
模型结构:
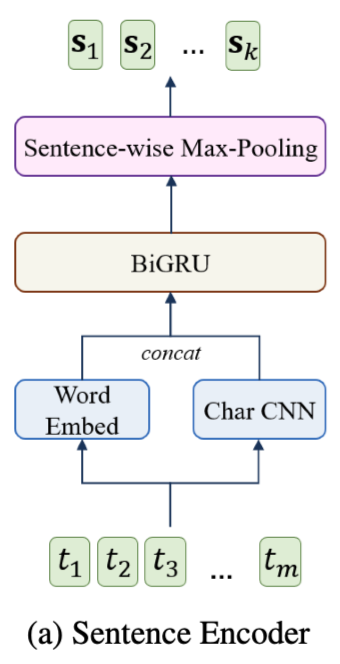
Paragraph and Question Encoder
段落P由k个段落组成
$P=(s_1, s_2, . . . , s_k)$
每个段落由$l$个tokens组成
$si=(t{i1}, t{i2}, . . . , t{i_l})$
$l$:句子长度
编码:
Word Embedding
$t^w$:word-level embedding 通过预训练的Word Embedding获得。
$t^c$:character-level embedding
token t 有$lt$个字符$(t{1}^c, t{2}^c, . . . , t{l_t}^c)$
连接两种嵌入形式:
Recurrent Layer
获得word representations之后,通过BiGRU获得 contextualized word representations。
Sentence-wise max-pooling
使用max-pooling获得sentence representations。
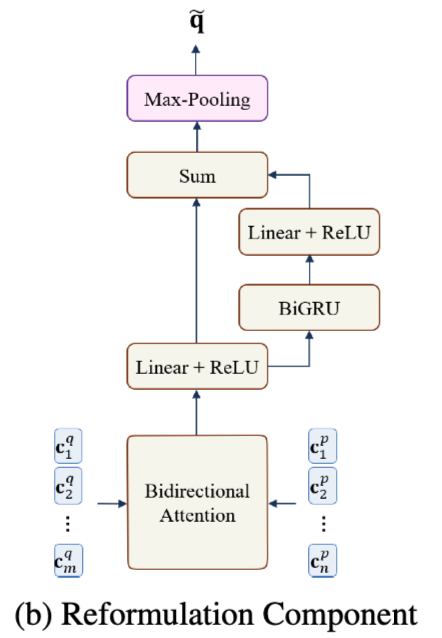
Reformulation Component
使用recurrent layers初始化问题Q和段落P的编码。
$(c^q 1, c^q 2, . . . , c^q_{ n_q})$
$(c^p 1, c^p 2, . . . , c^p_{ n_p})$
传递给bidirectional attention layer。使用ReLU作为激活函数。最终得到reformulated question representation, $\tilde q$
Reformulation Component图示:
Sentence Encoder 图示:
Paragraph Reader
段落阅读器接输入为问题Q和段落P,并从P中提取最可能的答案跨度。
数据集
- HotpotQA
- SQuAD-Open
性能水平和结论
- HotpotQA数据集:
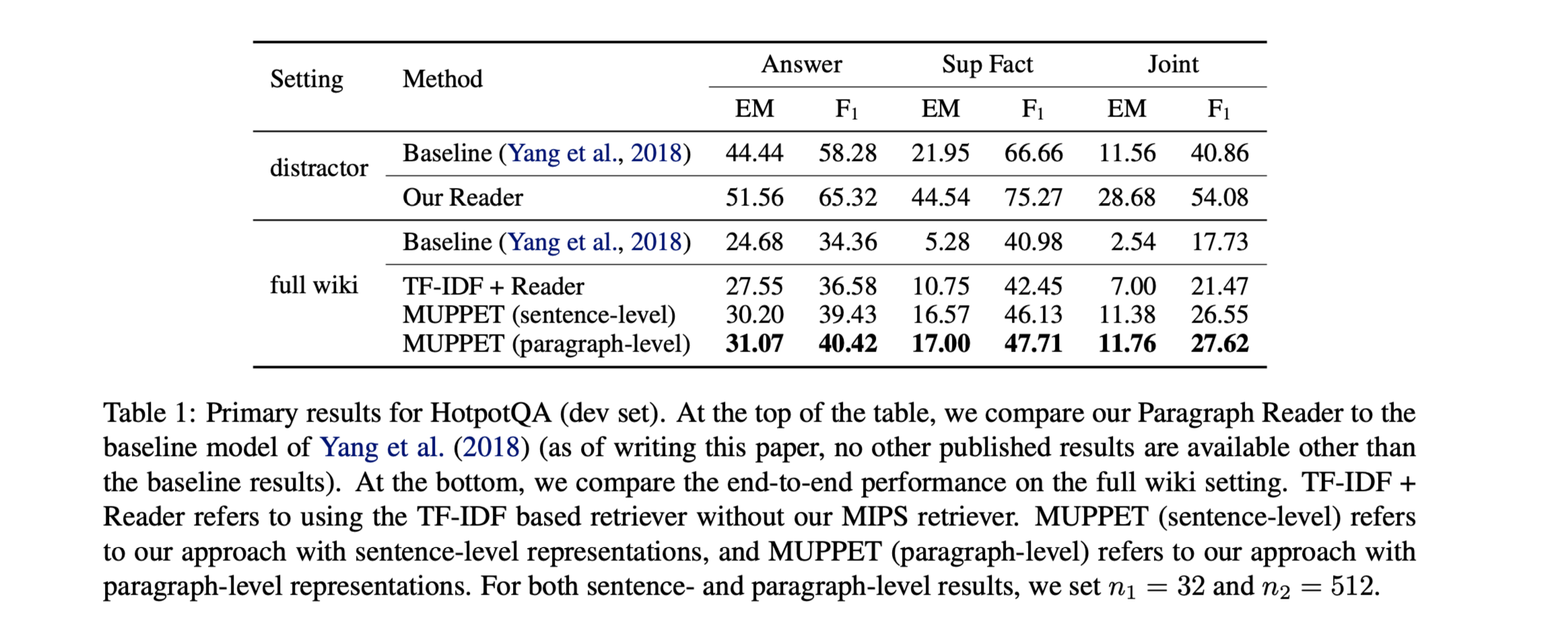
在HotpotQA distractor setting下,Joint EM和F1评分提升最为显著,分别提升了17.12和13.22。
在HotpotQA full wiki setting下,MUPPET在段落级别编码时,性能要优于句子级编码。
- SQuAD-Open数据集:
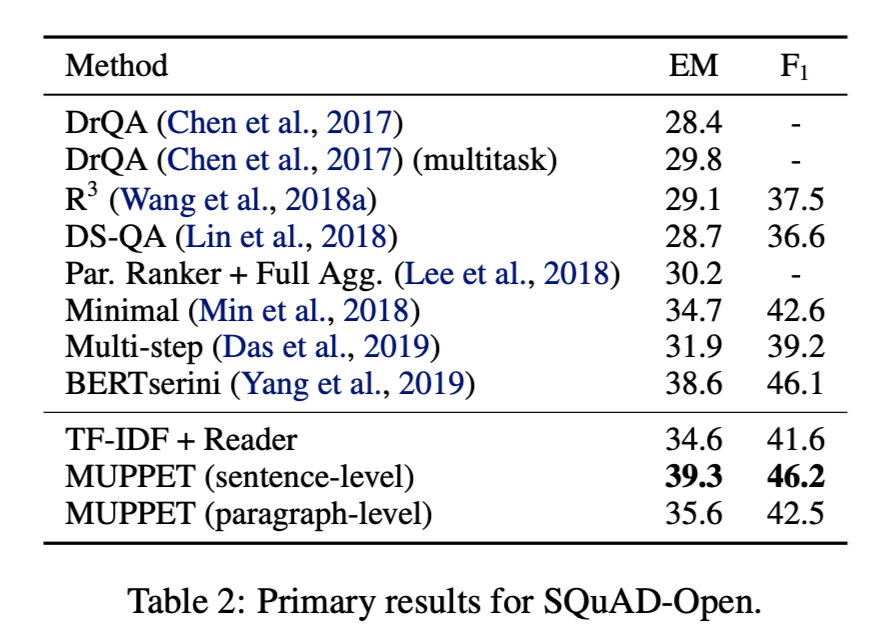
在SQuAD-Open数据集上,句子级别编码的MUPPET取得了最优的性能,表明本文提出的编码器不仅适用于多跳问题,还可以用于单跳问题。
结论:
本文提出的MUPPET,用于多跳段落检索在单跳和多跳QA数据集上都取得了不错的效果。