Answering Complex Open-domain Questions Through Iterative Query Generation
Answering Complex Open-domain Questions Through Iterative Query Generation
论文:Answering Complex Open-domain Questions Through Iterative Query Generation
任务
对于目前的单跳检索和阅读问题回答系统来说,问题很少包含关于缺失实体的可检索线索。回答这样的问题需要进行多跳推理,必须收集关于缺失实体(或事实)的信息才能进行进一步的推理。本文提出了GOLDEN(Gold Entity)Retriever,它在阅读上下文和检索更多支持文档之间进行迭代,以回答开放领域的多跳问题。
方法(模型)
GOLDEN Retriever不使用不透明和计算代价较高的神经检索模型,而是根据问题和可用的上下文生成自然语言搜索查询,在每一步中,该模型也会使用前几跳推理的IR结果生成新的自然语言查询,并利用现成的信息检索系统来查询缺失的实体或证据来回答原问题,而不是纯粹依靠原问题来检索段落。这使得GOLDEN Retriever能够在保持可解释性的同时,有效地扩展开放领域的多跳推理。
- GOLDEN Retriever
在推理的第一跳中,GOLDEN Retriever基于给定的原始问题q,从中生成一个检索支持文档$d1$,然后对后续的每一个推理步骤$(\ k = 2,……,S\ )$,GOLDEN Retriever从问题和可用上下文$\ (q,d_1,……,d{k-1}\ )$中生成一个查询$q_k$,使得模型根据支持事实中揭示的信息生成查询。
模型结构:
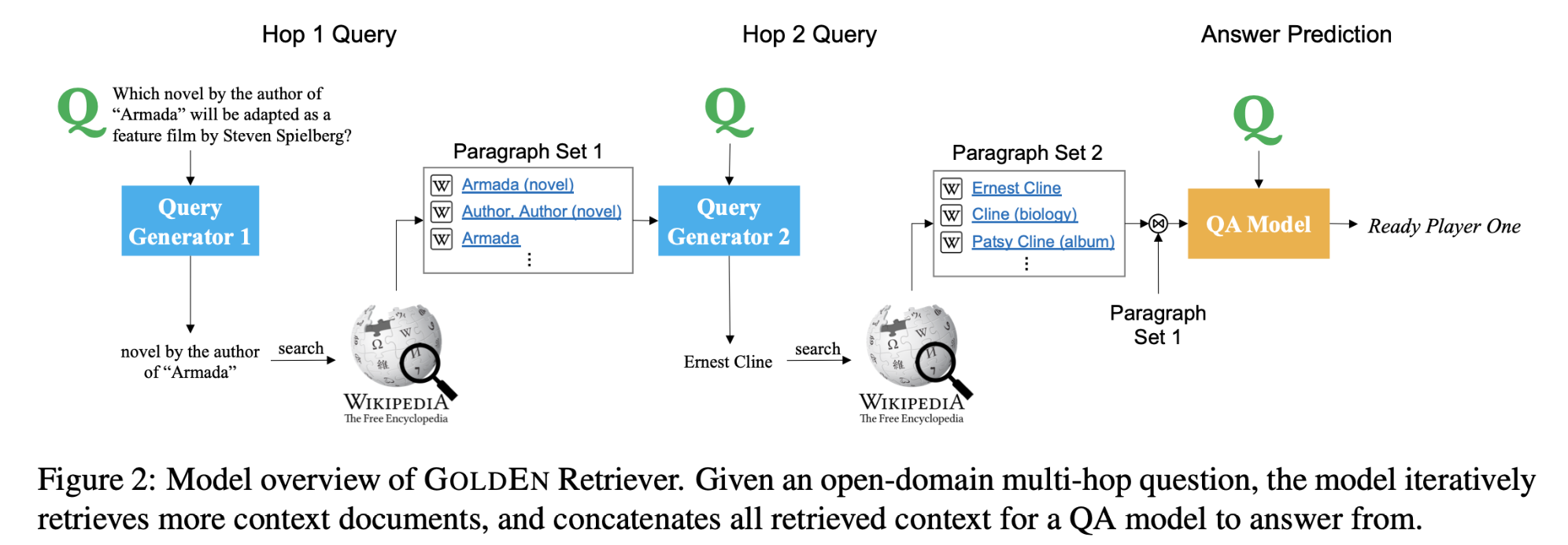
- Query Generation
使用DrQA’s Document Reader model。
从$C_k$中选择一个跨度作为查询: $q_k= G_k(q, C_k)$
$C_k$:retrieval context
gold supporting documents: $d1,….,d{k-1}$
generate a search query: $q_k$
$G_k$ : the query generator
- Deriving Supervision Signal for Query Generation
采用几种启发式方法来生成候选查询:计算当前检索上下文与目的段落的标题/文本之间最长的共同字符串/序列,忽略停顿词,然后取检索上下文中与此重叠对应的连续文本跨度。这样不仅可以利用实体名称,还可以利用文字描述,更好地引出黄金实体。
- Question Answering Component
之前的模型将所有上下文段落连缀成一个长字符串,以预测答案的跨度开始和结束偏移,这对这些段落呈现给模型的顺序有潜在的敏感性。本文用共享编码器RNN参数分别处理,以获得每个段落的段落顺序不敏感的表示。跨度偏移分数从每个段落中独立预测,最后用全局 softmax 操作进行聚合和归一化,以产生跨度的概率。
将原模型中的所有注意力机制都替换成了并联问题和上下文的自注意力层。为了区分上下文段落表征和问题表征在这个自注意机制中的区别,在输入层用一个0/1的特征来表示问题和上下文标记。
QA模型结构:
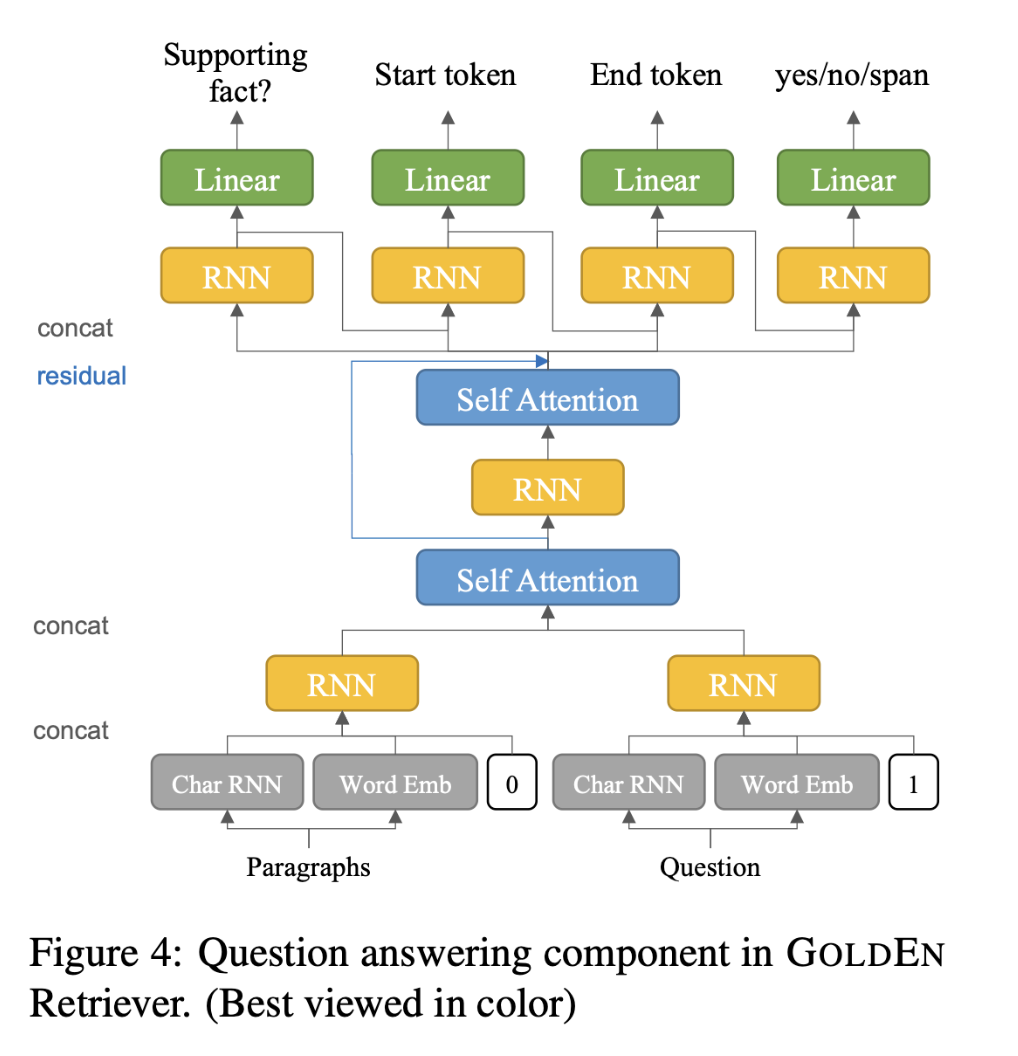
数据集
HOTPOTQA: fullwiki setting
性能水平
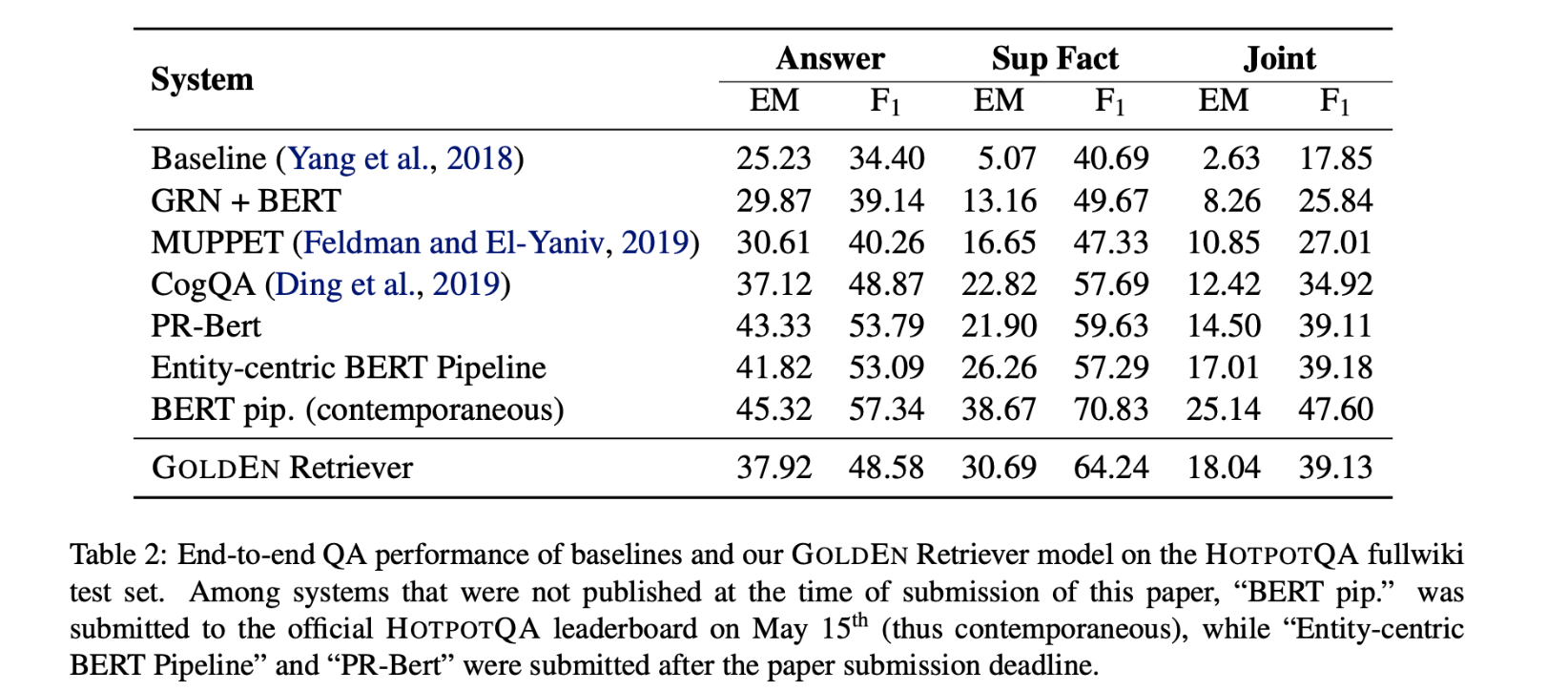
与CogQA相比,GOLDEN Retriever 在维基百科中找到正确支持事实的效果更好,证明尽管没有使用BERT等预训练语言模型,但它的表现优于之前发表的最佳模型。
GOLDEN Retriever几乎将召回率翻倍,通过单跳基线模型,为QA组件提供了一个更好的上下文文档来预测答案。
结论
本文提出了GOLDEN Retriever,这是一个可扩展的多跳推理的开放域多跳问题回答系统。通过迭代推理和检索,GOLDEN Retriever极大地提高了黄金支持事实的召回率,从而为问题回答模型提供了一个更好的上下文文档集来产生答案,并展示了具有竞争力的性能,达到了最先进的水平。为每一步推理生成自然语言查询,与之前的神经检索方法相比,GOLDEN Retriever对人类的解释能力也更强,并能更好地理解和验证模型行为。