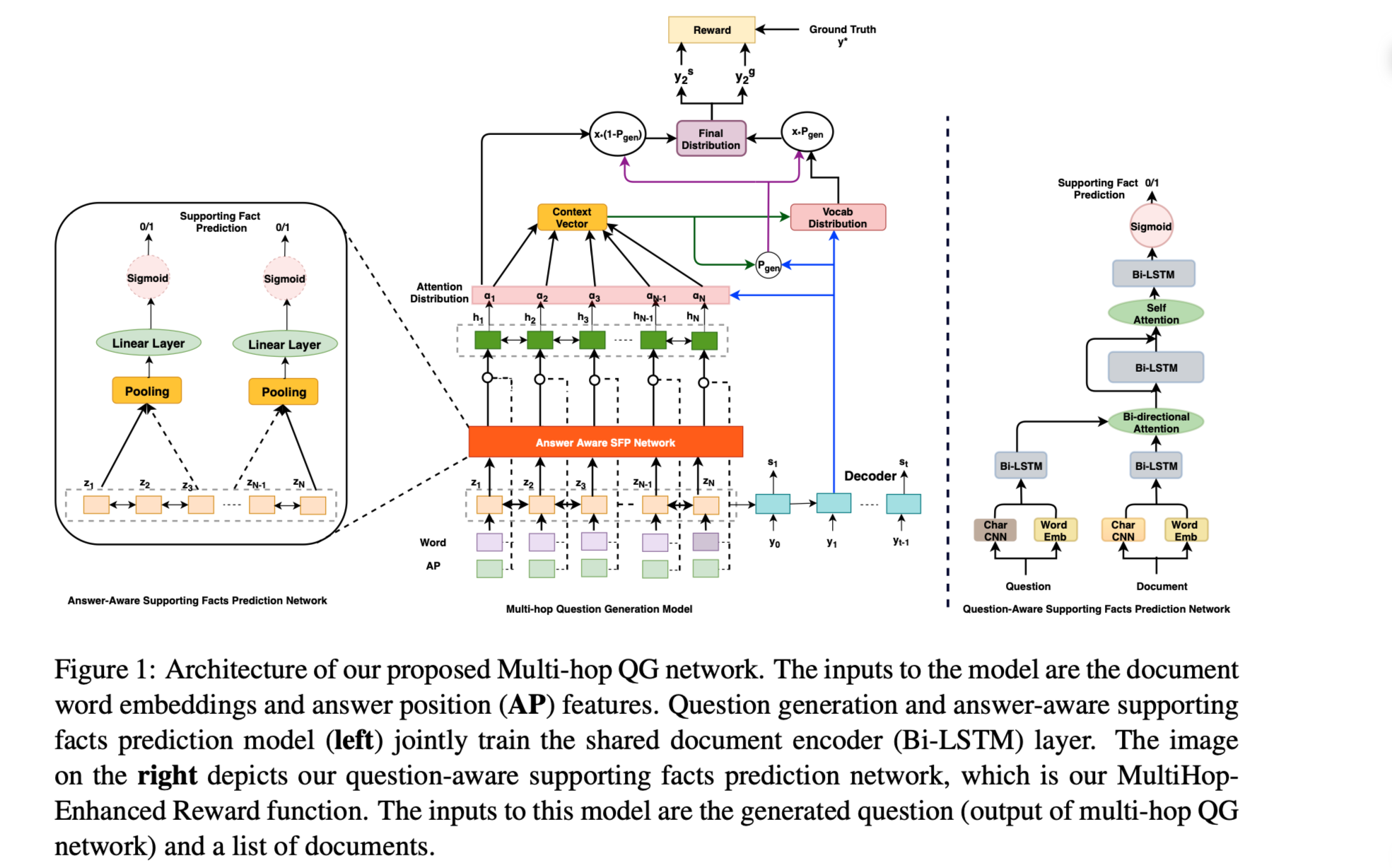
Multi-hop Question Generation with Graph Convolutional Network
Multi-hop Question Generation with Graph Convolutional Network
任务
多跳问题生成(Multi-hop Question Generation,QG)的目的是通过对不同段落中多个分散的证据进行汇总和推理,生成与答案相关的问题。解决两个问题:1.如何有效地识别分散的证据,可以连接答案和问题的推理路径。2.如何推理多个分散的证据来产生事实连贯的问题。
识别分散的证据,可以连接答案和问题的推理路径:

方法(模型)
为了解决多跳QG(MulQG)中的额外挑战,本文提出了问题生成的多跳编码融合网络(Multi-Hop Encoding Fusion Network),它通过Graph Convolutional Network在多跳中进行上下文编码,并通过编码器推理门(Encoder Reasoning Gate)进行编码融合。
MulQG将Seq2Seq QG框架从单跳扩展到多跳进行上下文编码。利用图卷积网络(GCN)对答案感知的动态实体图(由答案和输入段落中的实体构建),以聚合与问题相关的潜在证据。在多跳生成过程中,使用不同的注意力机制来模仿人类的推理过程。
模型结构:
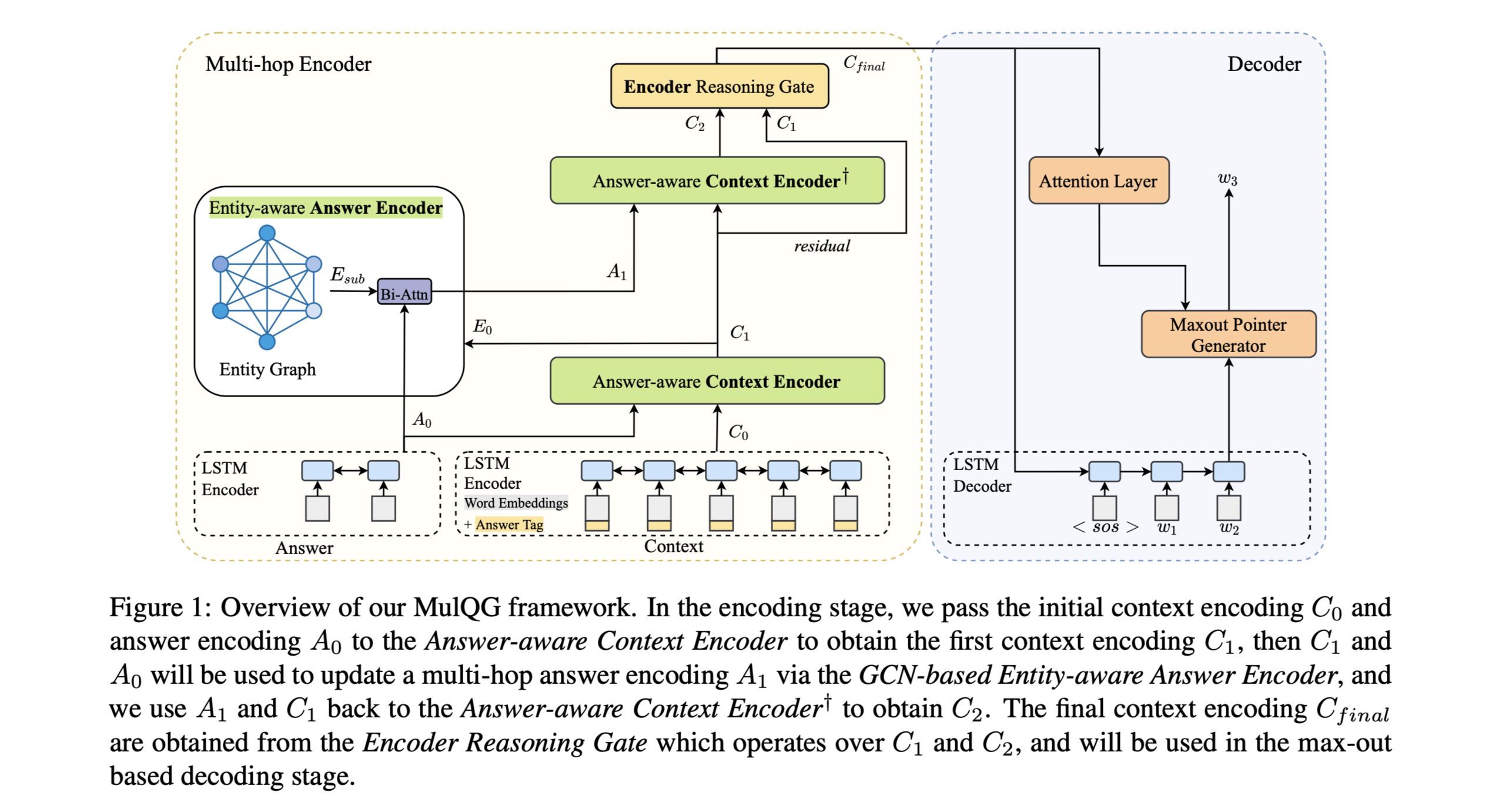
Multi-hop Encoder
包含3个模块:
(1) Answer-aware context encoder
(2) GCN-based entity-aware answer encoder
(3) Gated encoder reasoning layer.
上下文和答案分割为word-level token,表示为:
$c ={c_1, c_2, …, c_n}$
$a = {a_1, a_2, …, a_m}$
单次使用预训练的GloVe embedding表示,对于上下文中的单词,加入答案标记嵌入。上下文和答案嵌入分别输入两个双向LSTM-RNN,获得其初始上下文表示。
$C_0∈ R^{d×n}$
$A_0 ∈ R^{d×m}$
d是LSTM隐藏层维度。
- GCN-based Entity-aware Answer Encoder
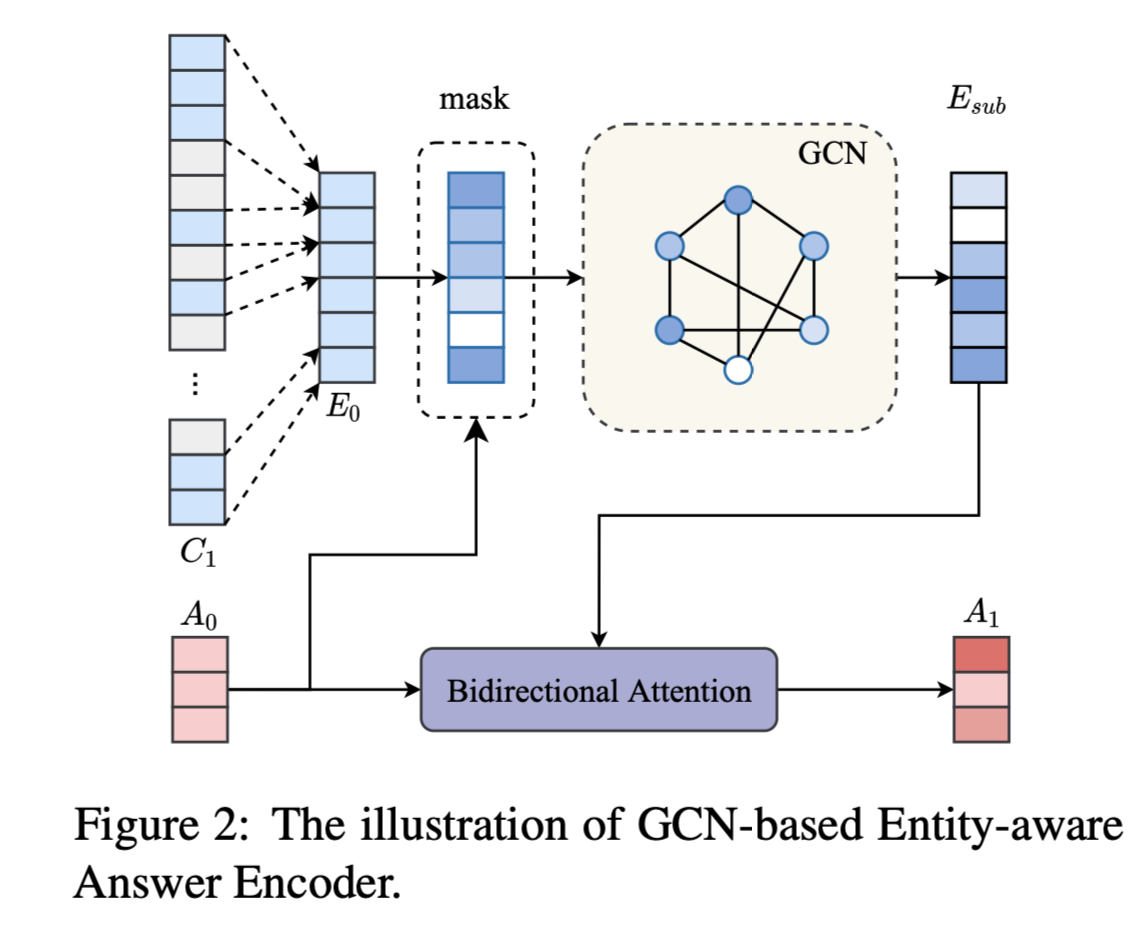
为了获得多跳答案表示,首先从答案感知上下文编码$C_1$计算实体编码,然后我们将GCN应用于在答案感知的子图上传播多跳信息。 最后,通过双向注意力机制获得编码$A_1$的更新答案。
Entity Graph Construction:
使用BERT-based命名实体识别构建节点。
处于同一句子或出现在相同段落的节点添加边。
- Encoder Reasoning Gate
在之前上下文context encoder hops的答案感知上下文表示$C_1$和$C_2$上应用门控特征融合模块,保留和遗忘信息,形成最终的上下文表示。
- Maxout Pointer Decoder
decoder:Uni-directional LSTM model(单向)
为了减少迭代的重复。
- Breadth-First Search Loss
cross-entropy loss:Breadth-First Search (BFS) Loss
数据集
HotpotQA
性能水平
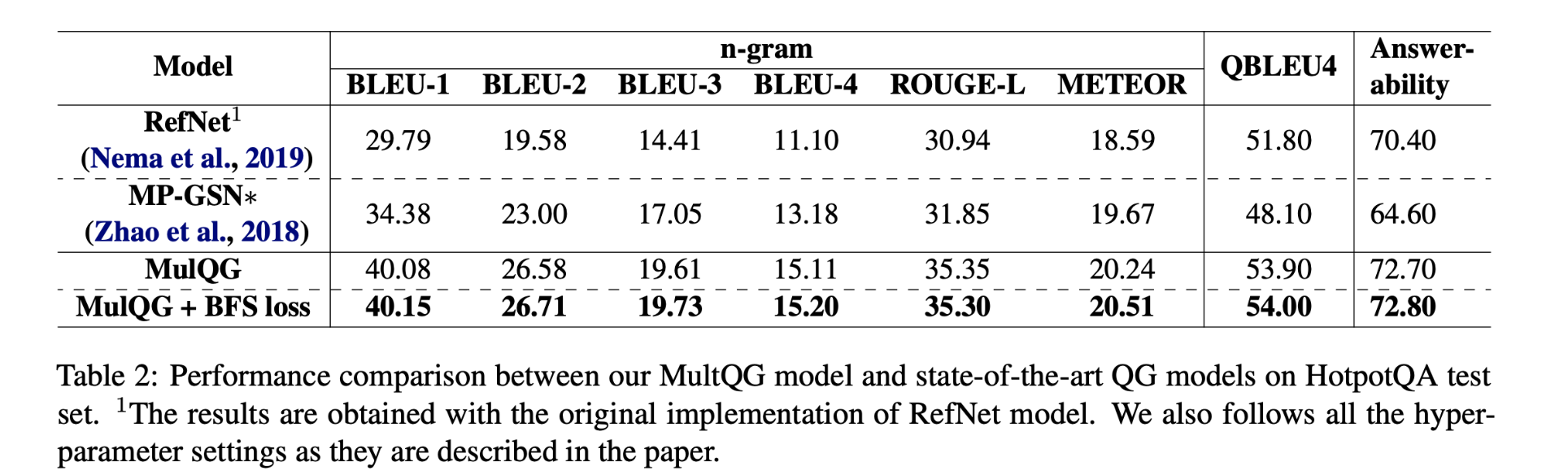
本文提出的MulQG模型效果远好于基线模型,表明多跳过程可以显着提高编码表示的质量,从而提高了多跳问题生成性能。
BFS loss也可以通过鼓励学习答案感知的动态实体图更好地提高系统性能。
结论
消融实验
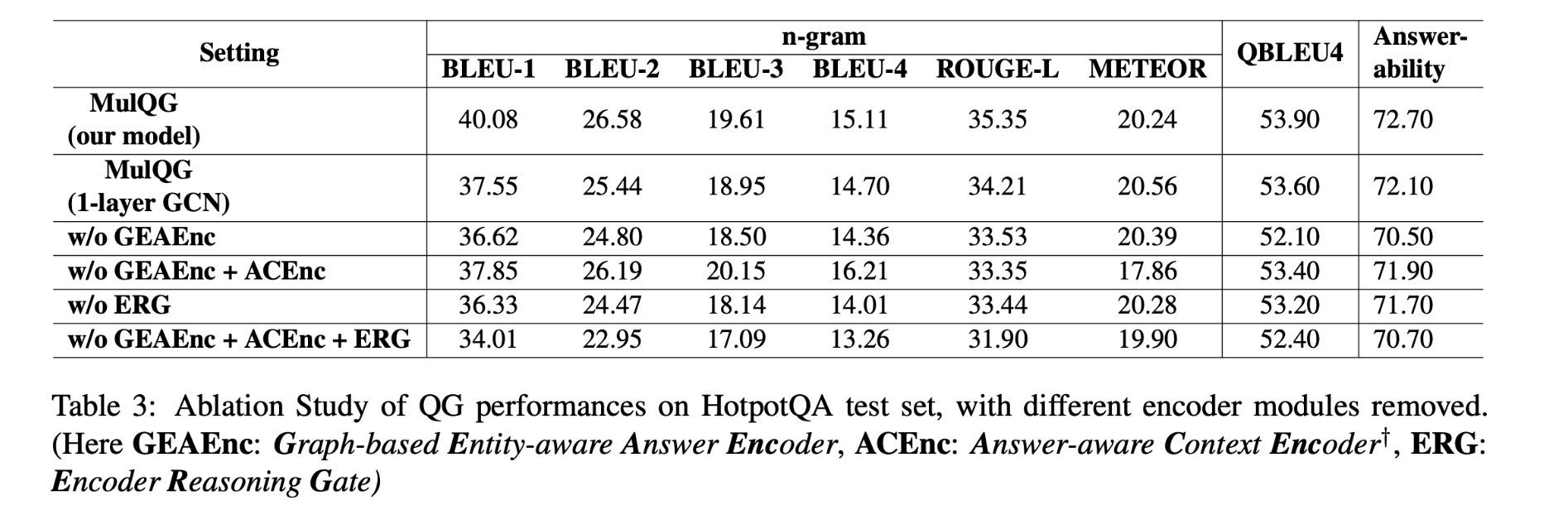
基于GCN的实体感知答案编码器模块和门控上下文推理模块都对模型很重要(GCN-based entity-aware answer encoder module and Gated Context Reasoning module)。
模型效果:

从评估来看,本文提出的模型能够生成高完整性的流畅问题,并且在多跳评估中比最强的基线高出20.8%,人工评价结果进一步验证了我们提出的模型更容易生成多跳问题,并且在流畅性、可回答性和完整性得分方面具有较高的质量。