Avoiding Reasoning Shortcuts Adversarial Evaluation, Training, and Model Development for Multi-HopQA
Avoiding Reasoning Shortcuts Adversarial Evaluation, Training, and Model Development for Multi-HopQA
任务
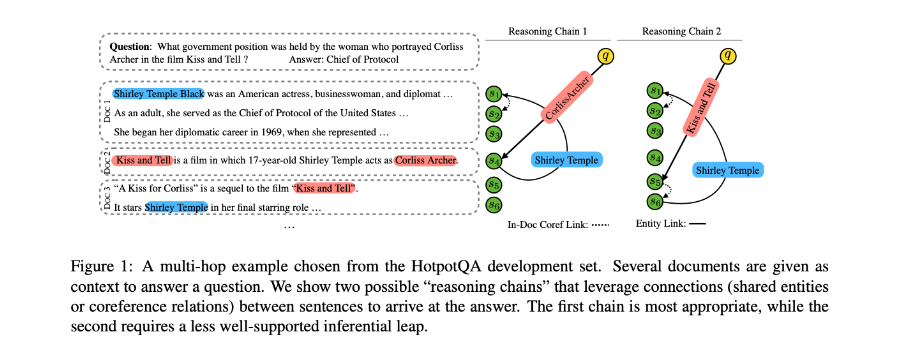
多跳答题需要模型将分散在长上下文中的多个证据连接起来来回答问题。本文在HotpotQA数据集上,通过构建对抗性文档(由于在生成问题时,人工并没有提供干扰文档,因此无法保证支持文档必须在整个上下文推断答案)来证明,通过数据集中部分例子包含的捷径,模型可以直接将问题与上下文中的句子进行词义匹配来定位答案。生成的这些对抗性文档会对捷径产生矛盾的答案,但不会影响原始答案的有效性。
方法(模型)
为探究神经网络模型是否利用推理快捷方式而不是探索所需的推理路径,使用HotpotQA中原始数据以消除这些快捷方式(shortcuts)。
context-question-answer tuple :(C, q, a)
去除快捷方式后:(C‘, q, a)
由于新生成的文档形成了另一个将问题与假答案联系起来的有效推理链,因此需要替换连接两条证据的bridge实体与另一个实体,以便所生成的答案不再是问题的有效答案。
ADDDOC

Encoding
embedding:x: context q: question
contextualized word representations:h = BiLSTM(x); u = BiLSTM(q)(使用bi-directional LSTM-RNN)
Single-Hop Baseline
模型结构:
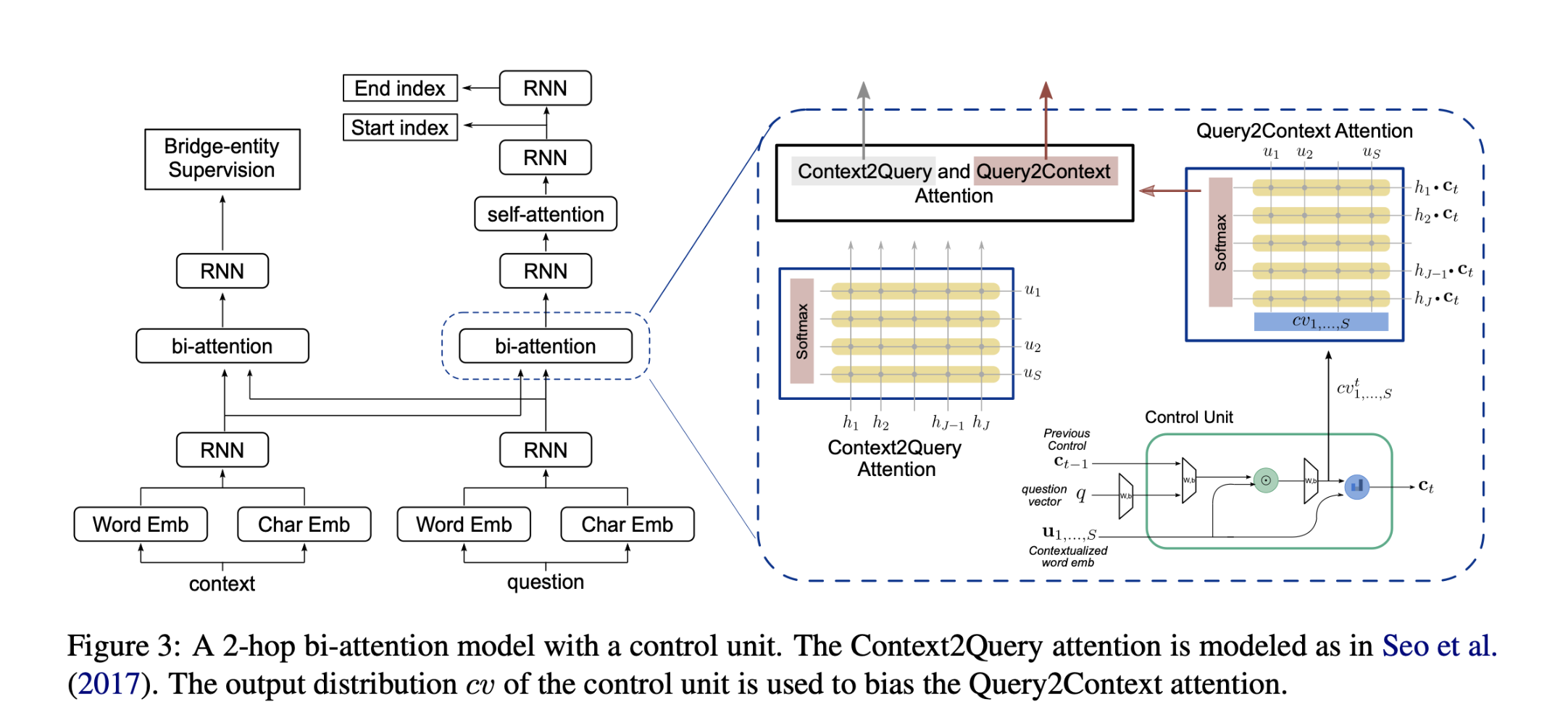
使用bi-attention + self-attention model做contextualized encoding。
得到 question-aware context下文表示后传递给BiLSTM。
Compositional Attention over Question
将控制单元与最新的多跳VQA模型和基于文本的QA上采用的bi-attention mechanism相结合,以对上下文和问题进行综合推理。
由于不知道问题的哪一部分对当前的推理步骤是重要的,从而使控制单元无法学习复合推理技能。为解决此问题,查找连接两个支持文档的桥接实体。监督主要模型来预测桥实体跨度,在第一个 biattention layer之后,间接鼓励控制单元在第一跳寻找与此实体相关的问题信息。对于答案同时出现在两个支持文档中的例子,intermediate supervision给出的是第一个支持文档中出现的答案,而第二个支持文档中的答案作为答案预测监督。
数据集
HotpotQA distractor setting
性能水平
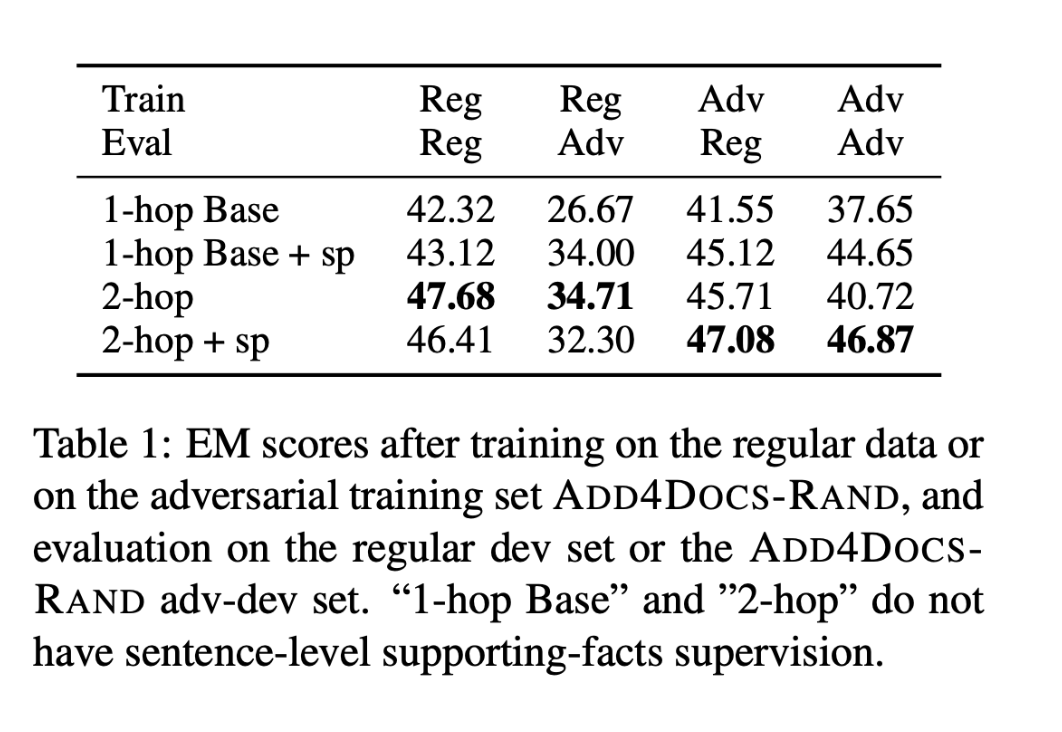
regular training set:前两列
在常规数据上训练的单跳基线在对抗性评价上表现不佳,这说明它确实是在利用推理捷径,而不是实际执行多跳推理来定位答案。添加了支持性事实监督后(第2行),在对抗性评价上有显著的改善。
2-hop模型被额外监督预测句子级支持事实后,在常规评价和对抗性评价中的性能都有所下降。
adversarial training set:后两列
经过对抗式训练后,基线和带有控制单元的2-hop模型在对抗式评价上性能都有显著提升。
消融实验
Adversary Ablation
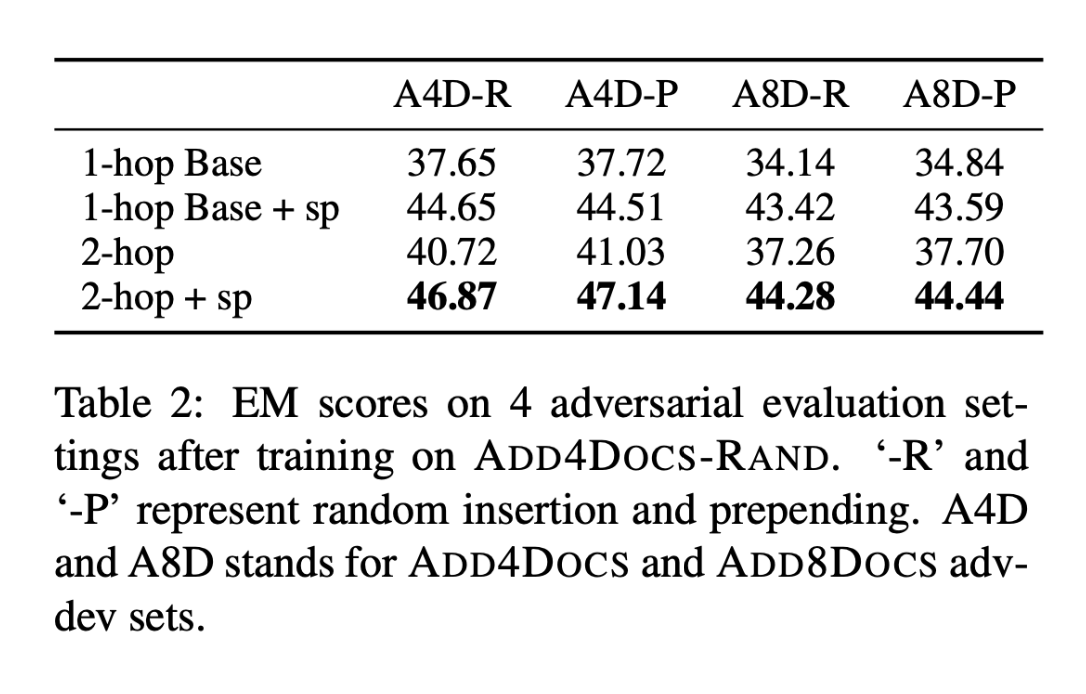
为了测试对抗训练的模型的鲁棒性,具有不同数量的对抗文档和不同对抗策略的dev集上对它们进行评估。当对抗文档被预置到上下文中时,基线和2-hop模型都不会受到影响。当每个有答案的支持文档的对抗性文件数量增加到8个时,4个模型的性能都下降了,但2-hop模型的性能依然优于单跳模型。
Control Unit Ablation
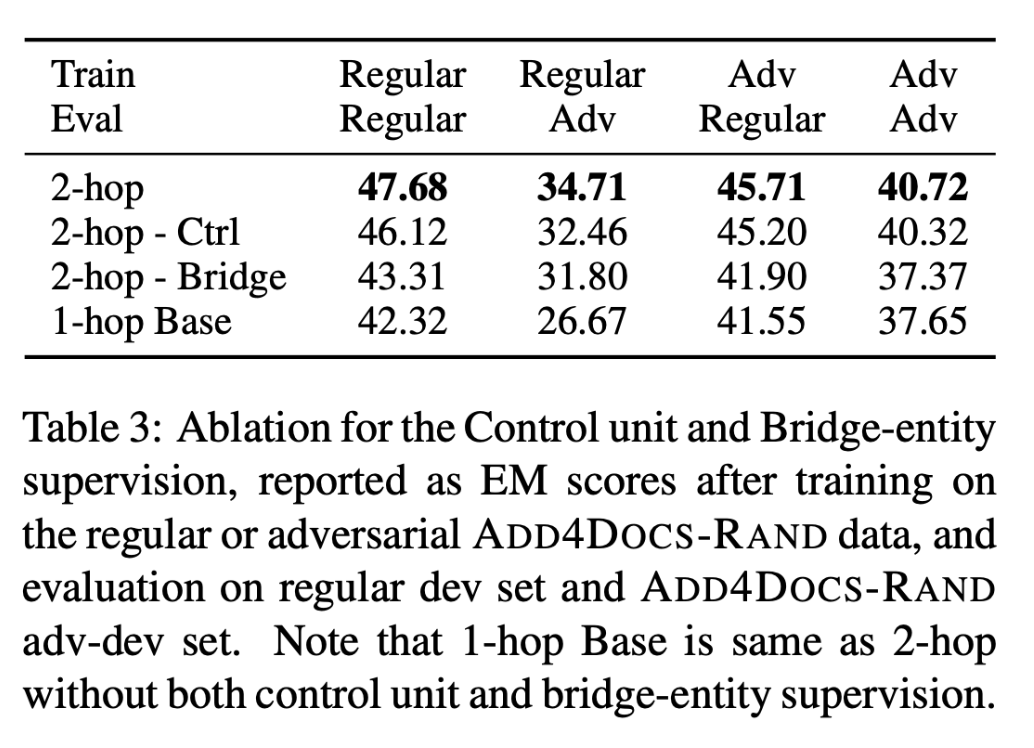
对2-hop模型进行了去掉控制单元的消融研究。前两行在4种不同训练和评估数据组合的设置下,带有控制单元的模型都优于替代模型。即控制单元可以提高模型的多跳推理能力和对对抗性文档的鲁棒性。
结论
在本文的对抗性评估中,强基线模型的性能显著下降,表明它们确实在利用捷径而不是进行多跳推理。经过对抗性训练后,基线的性能有所提高,但在对抗性评价上仍然受到限制。因此,使用一个在不同推理跳数上动态关注问题的控制单元来引导模型的多跳推理。结果表明,这个在常规数据上训练的2跳模型比基线模型对对抗者更加稳健。经过对抗训练后,这个2跳模型不仅比在常规数据上训练的对应模型实现了改进,而且还优于对抗训练的1跳基线模型。